mov 1,%xg3 mov 2,%xg4 stw %xg3,[%sp+2255] stw %xg4,[%sp+2259] mov 3,%xg5 mov 4,%xg6 stw %xg5,[%sp+2263] stw %xg6,[%sp+2267] mov 1,%g1 mov 2,%g3 stw %g1,[%sp+2239] stw %g3,[%sp+2243] mov 3,%xg7 mov 4,%xg8 stw %xg7,[%sp+2247] stw %xg8,[%sp+2251] add %g1,3,%g2 add %g3,4,%g4 stw %g2,[%o0] stw %g4,[%o1] sub %sp,-240,%sp retl IntPair a = {1,2}; IntPair b = {3,4}; IntPair tx = a; IntPair ty = b; {1,2} + {3,4} このようなアセンブリが与えられた時 スタック操作が含まれると、生存変数解析が全く効かない? (Fortranとoptimizerを共有している弊害?) mov 1,%g1 mov 2,%g3 add %g1,3,%g2 add %g3,4,%g4 stw %g2,[%o0] stw %g4,[%o1] mov 4,%g2 mov 6,%g4 stw %g2,[%o0] stw %g4,[%o1] あとでアクセスされないスタック操作を削除 ピープホール最適化 ここまで行ってほしい
{kind=link}
{kind=link}
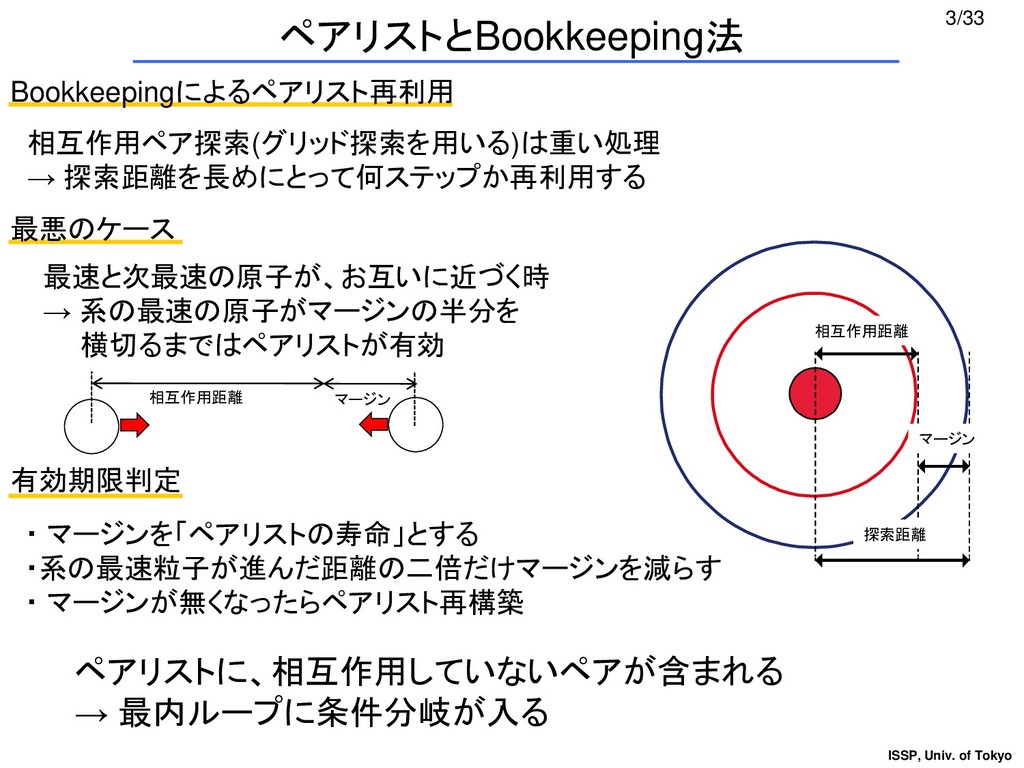{kind=link}
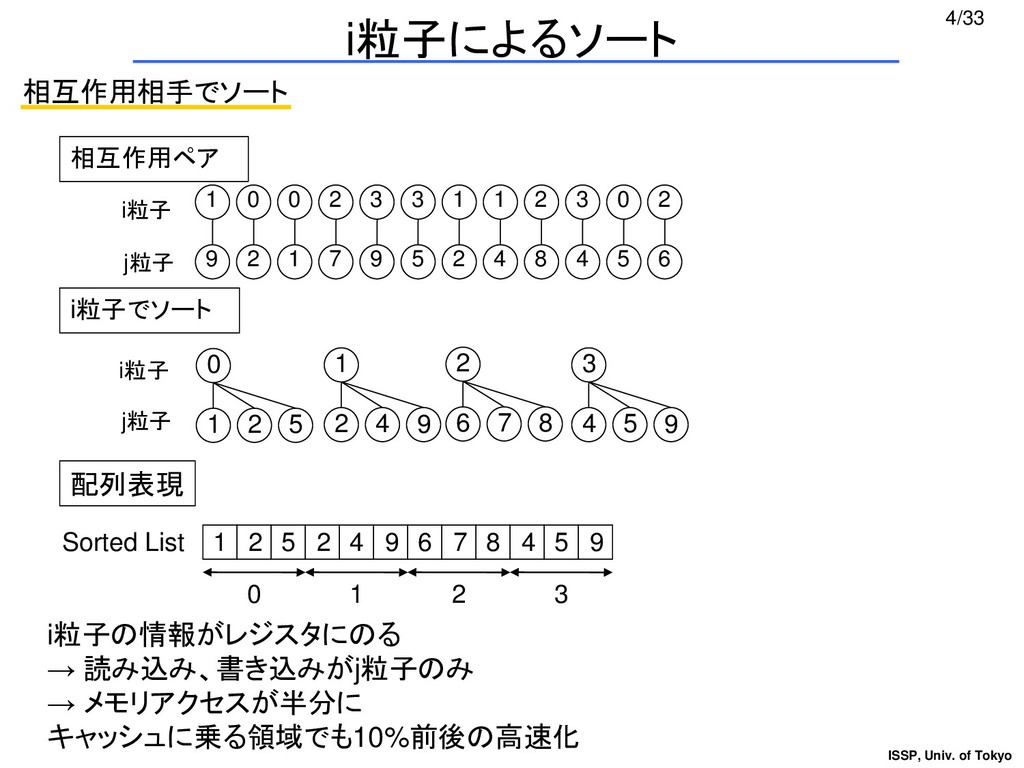{kind=link}
{kind=link}
{kind=link}
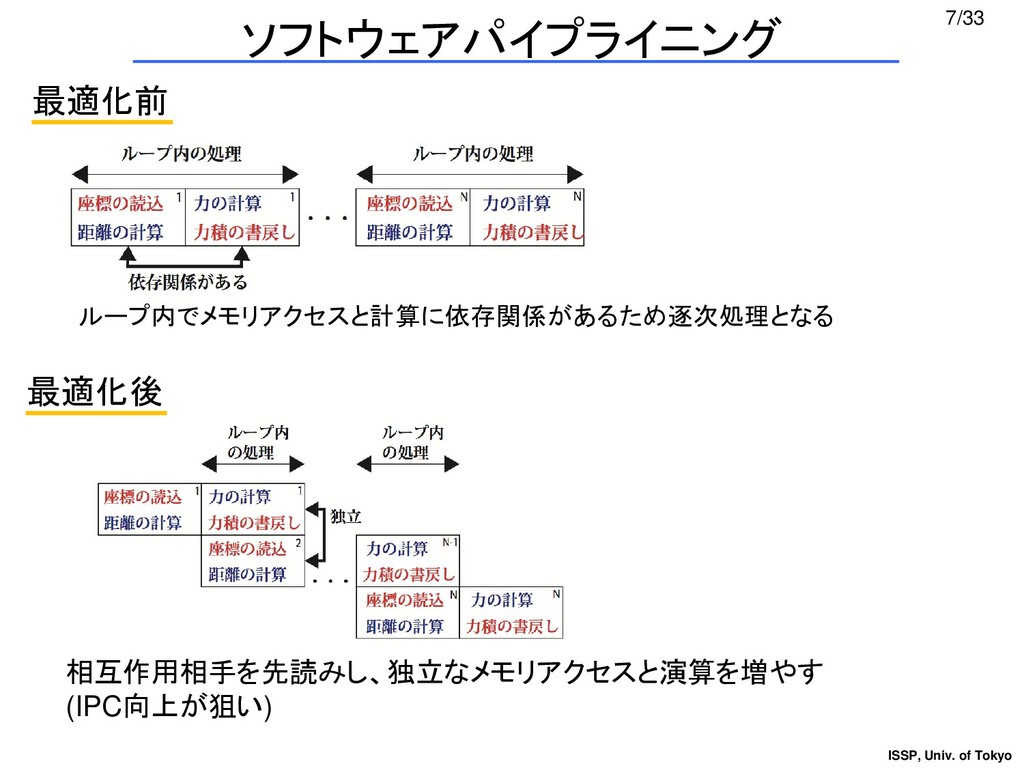{kind=link}
{kind=link}
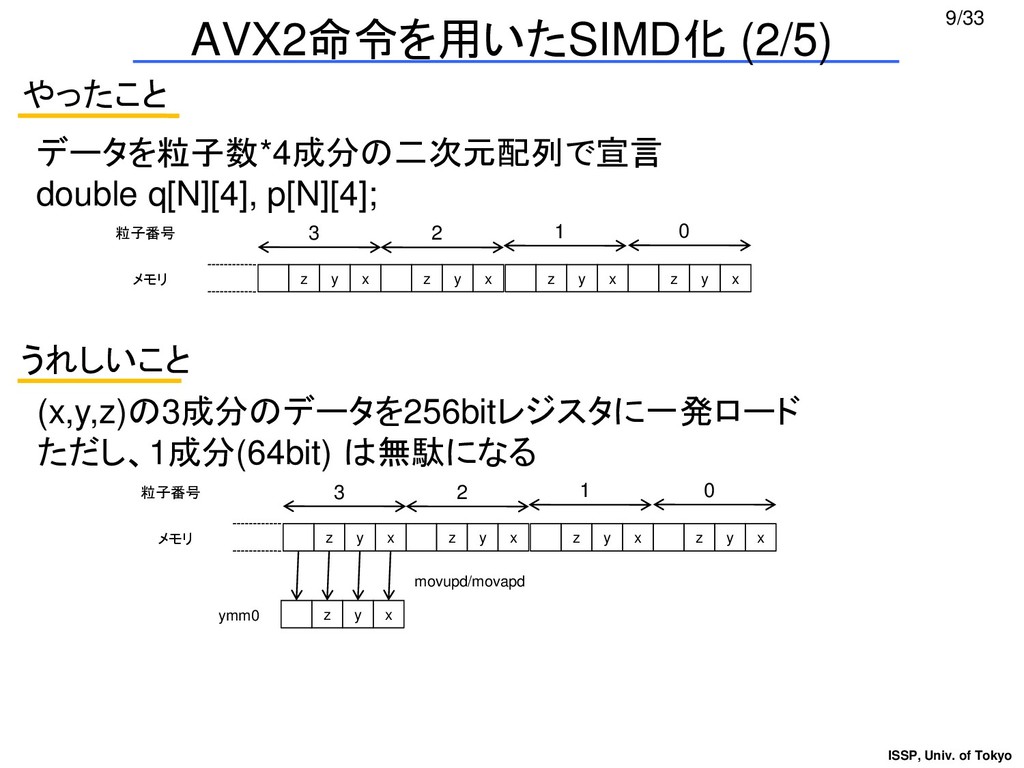{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ISSP, Univ. of Tokyo 14/33 SIMD化前 実行時間 [s] ナイーブな実装 i粒子でソート](https://files.speakerdeck.com/presentations/e6d6df533cda4a2f8ea17a2258329b69/slide_13.jpg){kind=link}
![ISSP, Univ. of Tokyo 15/33 データ構造の変更 double q[N][4], p[N][4]; double](https://files.speakerdeck.com/presentations/e6d6df533cda4a2f8ea17a2258329b69/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
![ISSP, Univ. of Tokyo 18/33 SoAとAoS gather/scatterを手で書けば、SoAとAoSの速度はどちらも大差ないが ここでもう少しデータ構造を工夫してみる double q[N][4],](https://files.speakerdeck.com/presentations/e6d6df533cda4a2f8ea17a2258329b69/slide_17.jpg){kind=link}
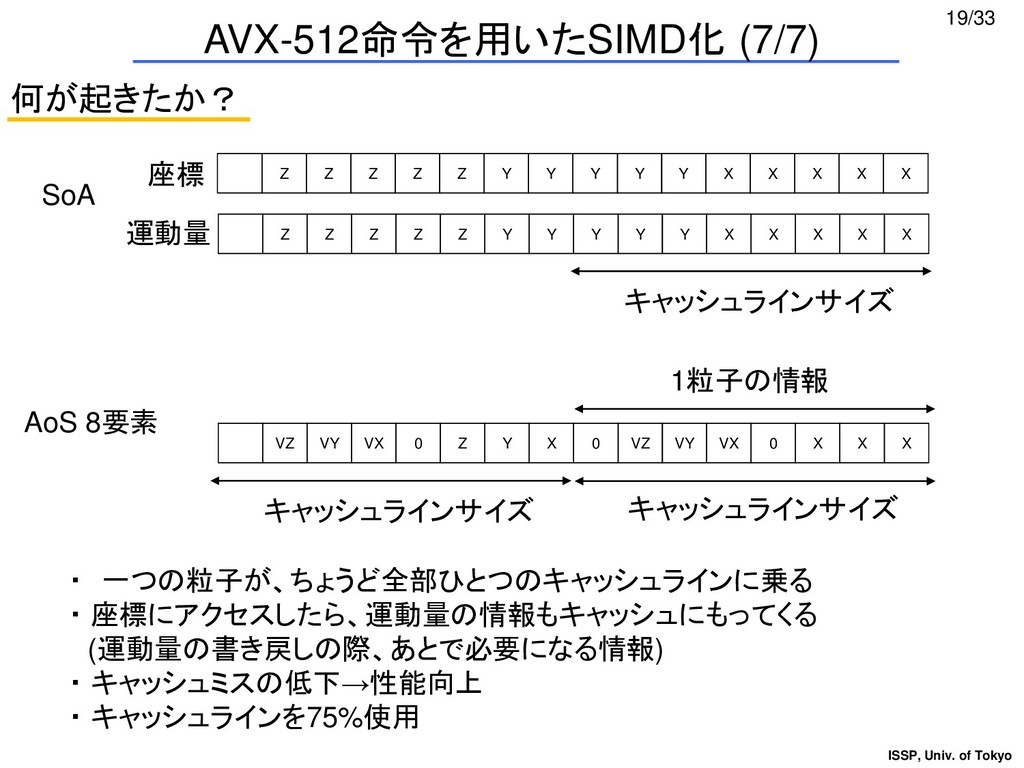{kind=link}
{kind=link}
{kind=link}
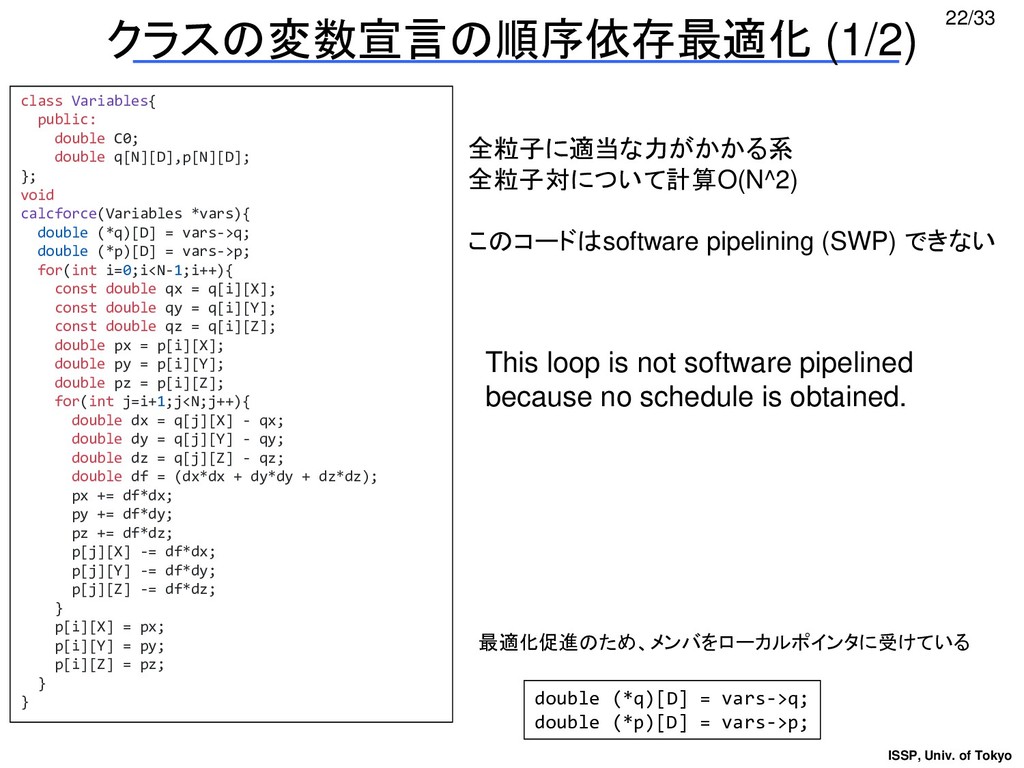{kind=link}
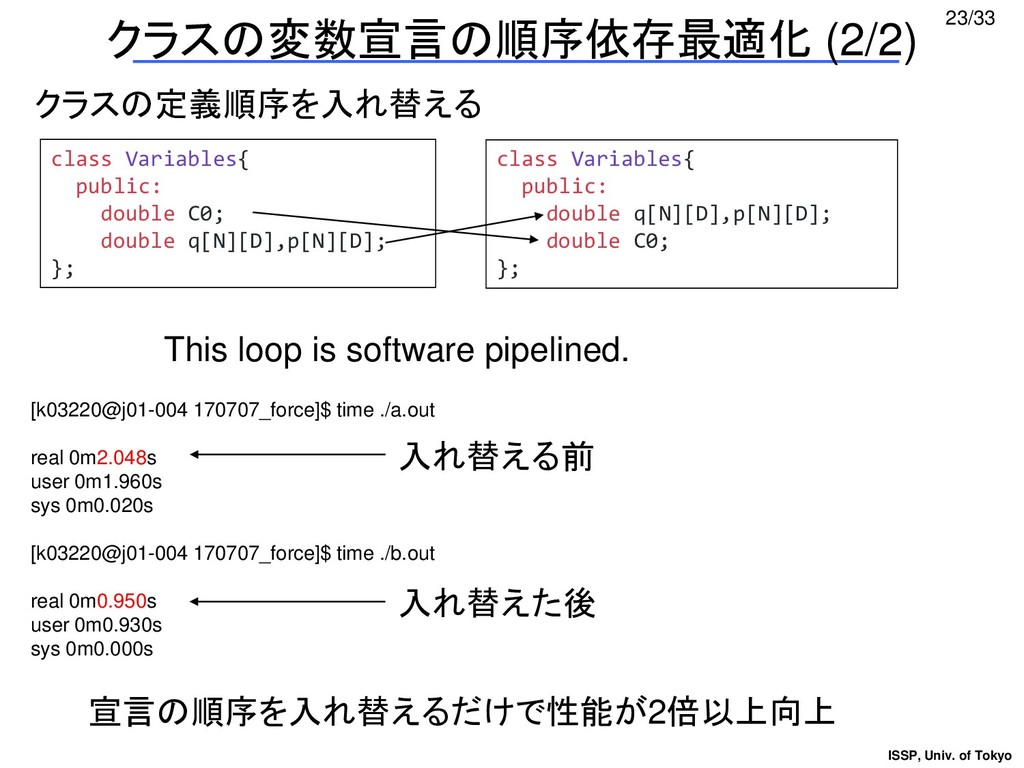{kind=link}
{kind=link}
![ISSP, Univ. of Tokyo 25/33 STLコンテナの最適化 (2/3) void calcforce(pos q[N],](https://files.speakerdeck.com/presentations/e6d6df533cda4a2f8ea17a2258329b69/slide_24.jpg){kind=link}
![ISSP, Univ. of Tokyo 26/33 STLコンテナの最適化 (3/3) void calcforce(pos q[N],](https://files.speakerdeck.com/presentations/e6d6df533cda4a2f8ea17a2258329b69/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}