Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ハイパースレッディングの 並列化効率への影響 / Hyperthreading and Par...
Search
kaityo256
PRO
May 23, 2013
Programming
66
5
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ハイパースレッディングの 並列化効率への影響 / Hyperthreading and Parallel Efficiency
ハイパースレッディングの有無が実アプリ(分子動力学法)に与えるの影響を1024ノード規模で調べた結果。
測定日は2011年6月と古いので注意。
kaityo256
PRO
May 23, 2013
More Decks by kaityo256
See All by kaityo256
勾配ブースティングと決定木の話 / gradient boosting and decision trees
kaityo256
PRO
7
1.6k
GNU Makeの使い方 / How to use GNU Make
kaityo256
PRO
16
5.8k
この講義について / 00-setup
kaityo256
PRO
2
450
GitHubによるWebアプリケーションのデプロイ / 07-github-deploy
kaityo256
PRO
2
360
演習:Gitの基本操作 / 04-git-basic
kaityo256
PRO
1
580
演習:Gitの応用操作 / 05-git-advanced
kaityo256
PRO
1
350
演習:GitHubの基本操作 / 06-github-basic
kaityo256
PRO
1
410
バージョン管理とは / 01-a-vcs
kaityo256
PRO
2
390
Gitの仕組みと用語 / 01-b-term
kaityo256
PRO
1
480
Other Decks in Programming
See All in Programming
AIエージェントで 変わるAndroid開発環境
takahirom
2
660
Haskell/Servantを通してWebミドルウェアを捉え直す
pizzacat83
1
580
act2-costs.pdf
sumedhbala
0
110
ソフトウェア設計に溶けるインフラ ― AWS CDK のインフラ認識論
konokenj
2
500
信頼性について考えてみる(SRE NEXT 2026 miniLT)
hayama17
0
190
The Bowling Game - From Imperative to Functional Programming - Part 1
philipschwarz
PRO
0
330
1年で人数1.5倍、PR数5.5倍増。 品質とアウトカムはどうなったか、 何が効いたか
ike002jp
0
140
フィードバックで育てるAI開発
kotaminato
1
120
コーディングルールの鮮度を保ちたい for SRE NEXT 2026 / keep-fresh-go-internal-conventions-sre-next-2026
handlename
0
140
「正の参照」と 「負の導出」で組む ハーネスエンジニアリング
cottpan
1
140
Terraform標準の組織で AWS CDKをどう使うか
mu7889yoon
0
200
【SRE NEXT 2026 Lunch Session】一人目専任SREの立ち上げを加速する ― AIと進めたオンボーディングで2分を0.04秒にした話
pkshadeck
PRO
0
2.7k
Featured
See All Featured
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
370
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
Fashionably flexible responsive web design (full day workshop)
malarkey
408
67k
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
630
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
530
Chasing Engaging Ingredients in Design
codingconduct
0
240
GitHub's CSS Performance
jonrohan
1033
470k
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
340
For a Future-Friendly Web
brad_frost
183
10k
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
Transcript
1/13 ハイパースレッディングの 並列化効率への影響 東京大学物性研究所 渡辺宙志 2013年5月23日
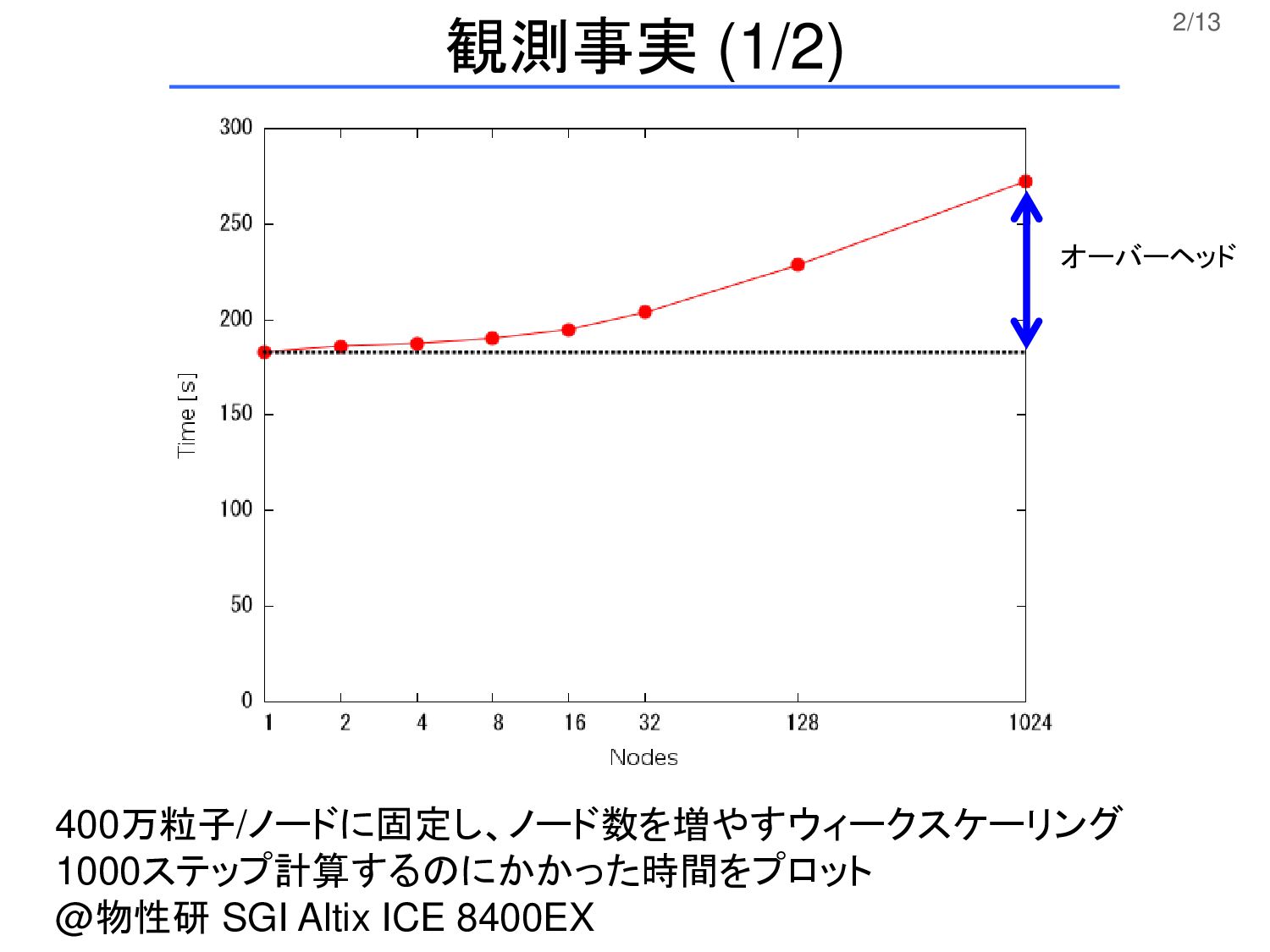
2/13 400万粒子/ノードに固定し、ノード数を増やすウィークスケーリング 1000ステップ計算するのにかかった時間をプロット @物性研 SGI Altix ICE 8400EX 観測事実 (1/2)
オーバーヘッド
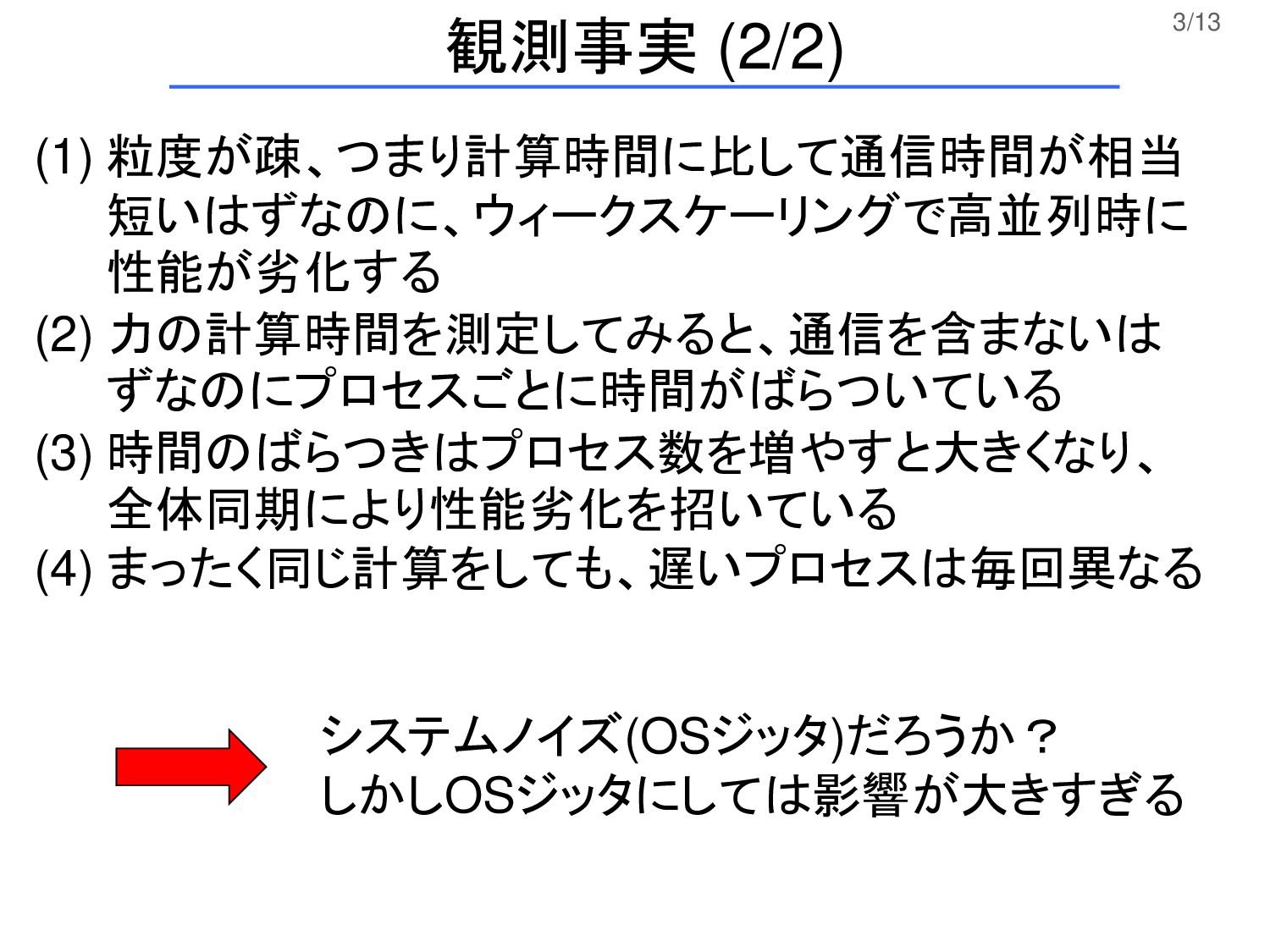
3/13 観測事実 (2/2) (1) 粒度が疎、つまり計算時間に比して通信時間が相当 短いはずなのに、ウィークスケーリングで高並列時に 性能が劣化する (2) 力の計算時間を測定してみると、通信を含まないは ずなのにプロセスごとに時間がばらついている
(3) 時間のばらつきはプロセス数を増やすと大きくなり、 全体同期により性能劣化を招いている (4) まったく同じ計算をしても、遅いプロセスは毎回異なる システムノイズ(OSジッタ)だろうか? しかしOSジッタにしては影響が大きすぎる
4/13 調べたいこと (1) プロセスの実行時間の揺らぎを精密に調べる (2) ハイパースレッディング(HT) の並列性能への影響を 調べる
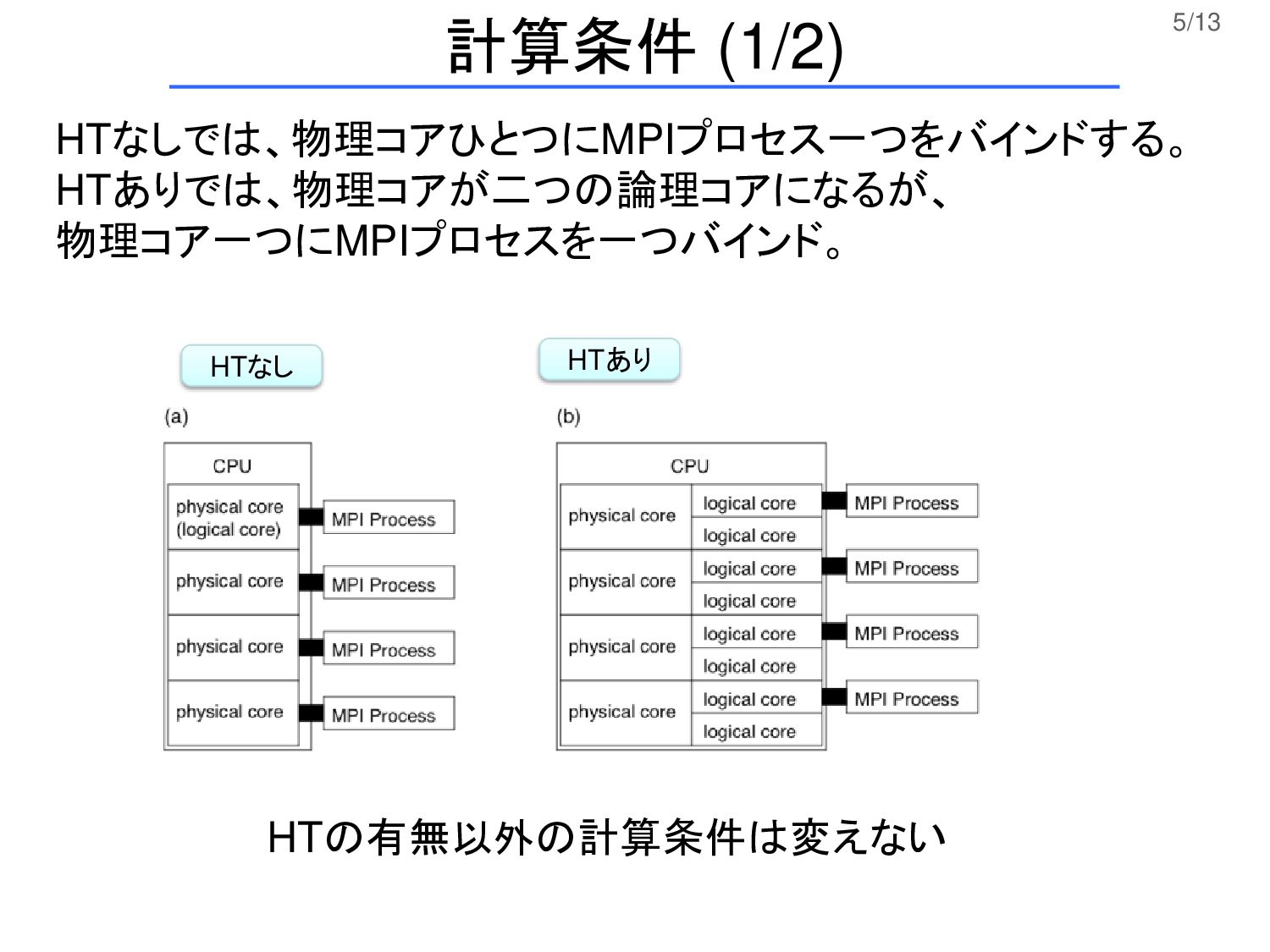
5/13 HTなし HTあり HTなしでは、物理コアひとつにMPIプロセス一つをバインドする。 HTありでは、物理コアが二つの論理コアになるが、 物理コア一つにMPIプロセスを一つバインド。 計算条件 (1/2) HTの有無以外の計算条件は変えない
6/13 計算条件 (2/2) 東京大学物性研究所 システムB SGI Altix ICE 8400EX CPU:
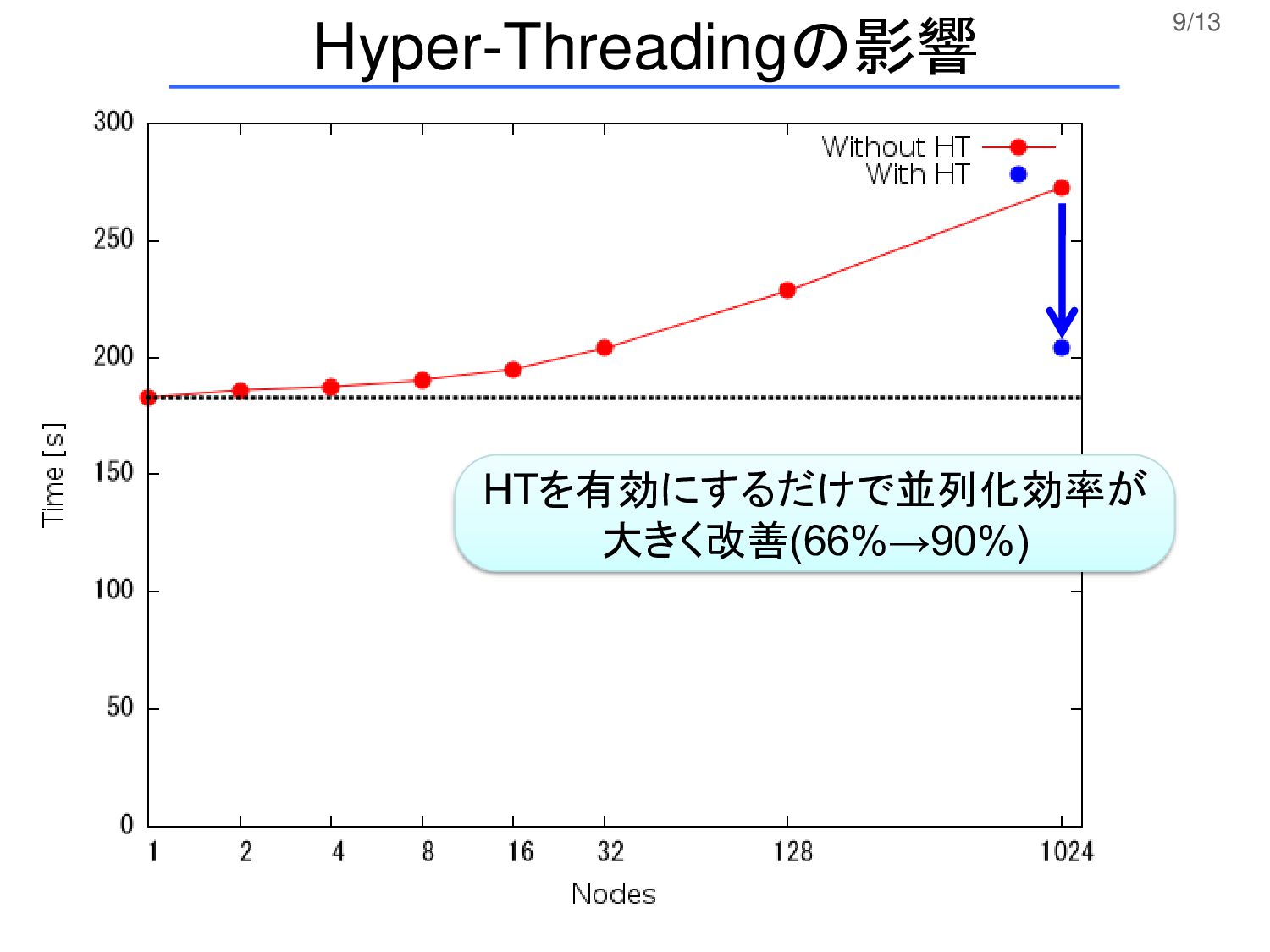
Intel Xeon X5570 2.93GHz 4コア/CPU、2CPU/ノード 計算資源: 計算条件: カットオフ2.5σのLennard-Jones粒子系 時間ステップ 0.001、数密度: 0.5 粒子数: 50万粒子/コア、 400万粒子/ノード Flat-MPIによる領域分割 計算コード:http://mdacp.sourceforge.net/ 測定日:2011年6月 ※ HT無効の計算は1ノードから1024ノードまで数点を、 HTを有効にした計算は、1024ノード、8192コアの一点のみを計算
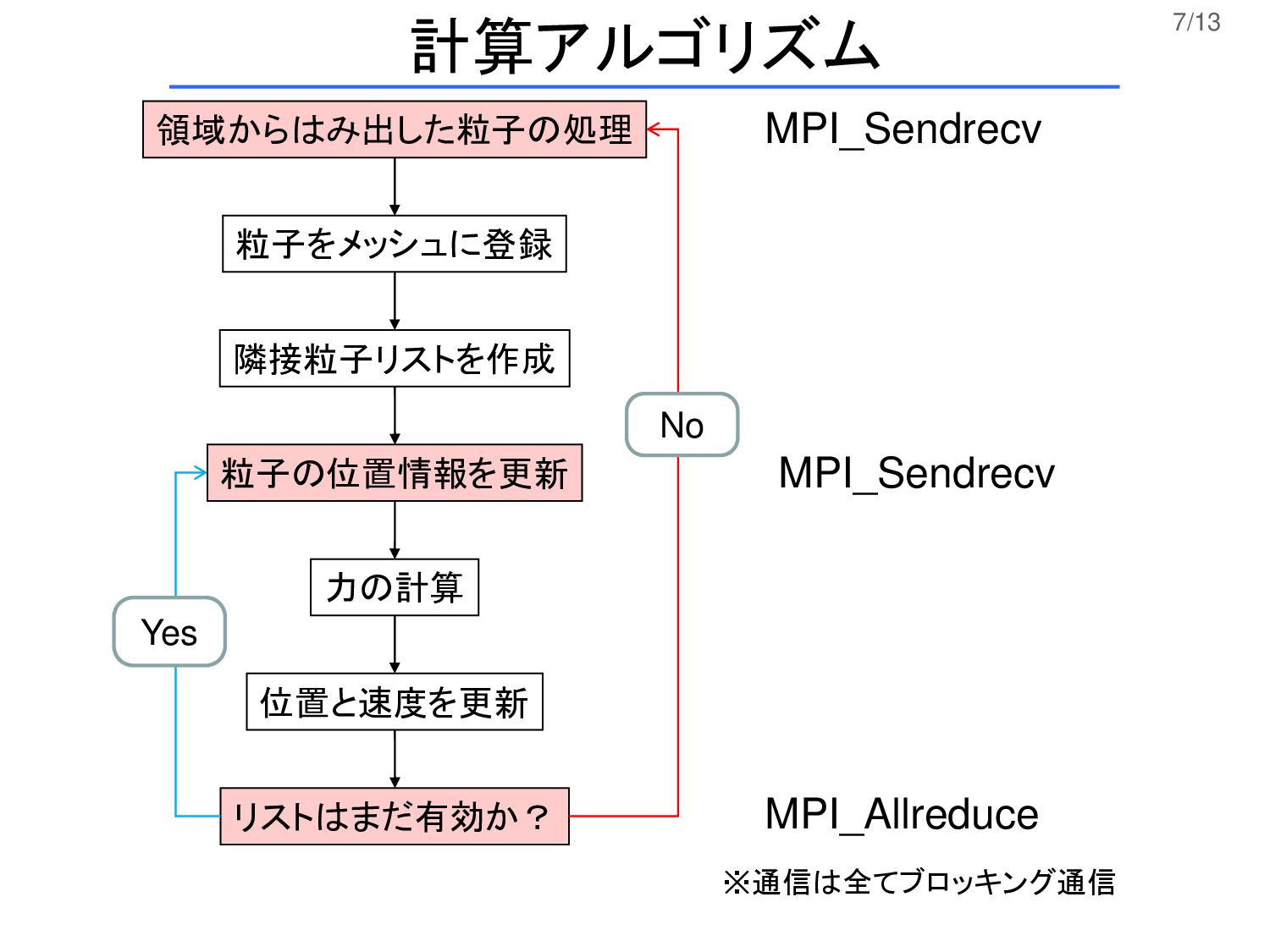
7/13 粒子をメッシュに登録 隣接粒子リストを作成 力の計算 位置と速度を更新 リストはまだ有効か? No Yes 領域からはみ出した粒子の処理 粒子の位置情報を更新
MPI_Sendrecv MPI_Sendrecv MPI_Allreduce 計算アルゴリズム ※通信は全てブロッキング通信
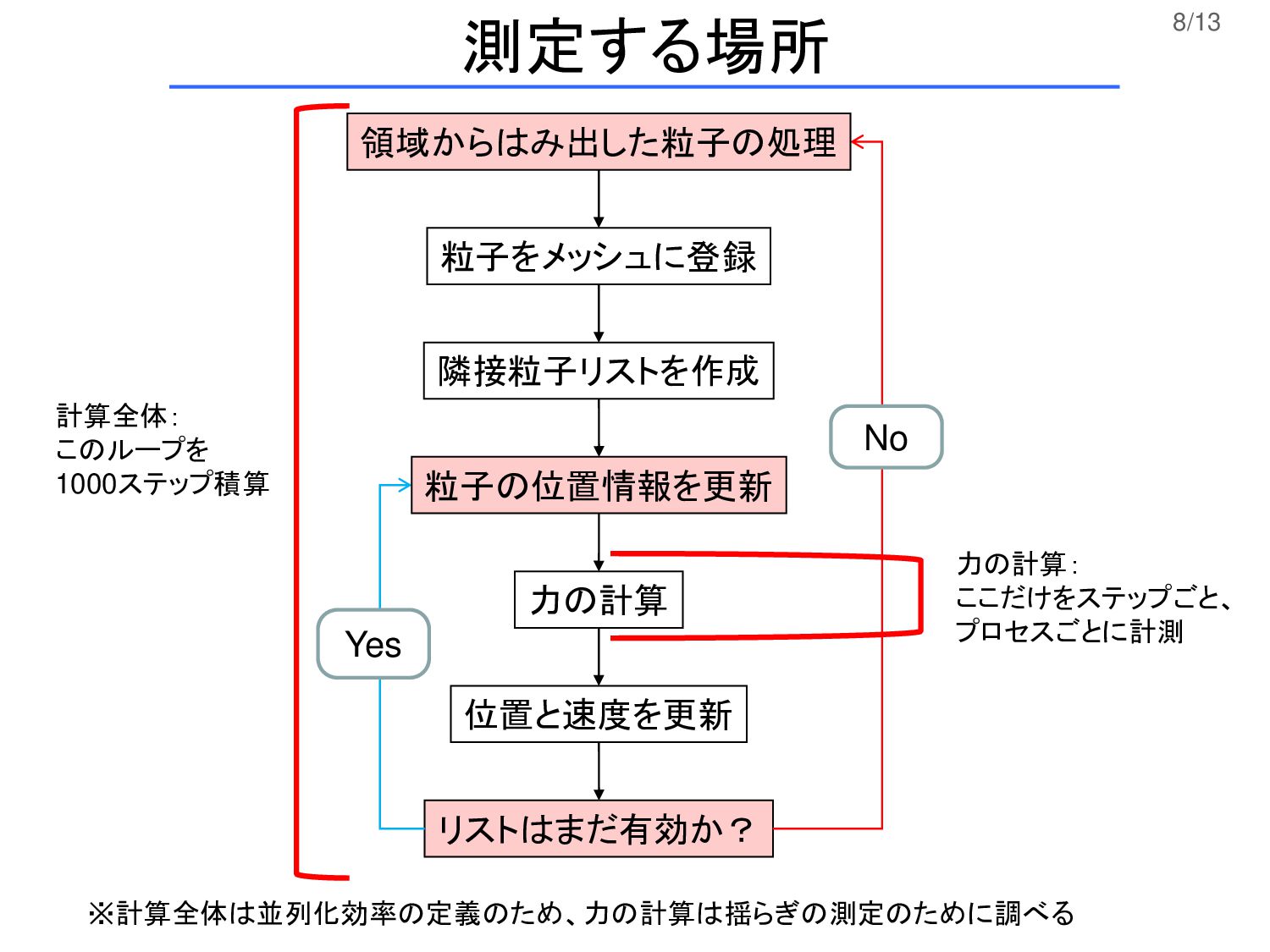
8/13 粒子をメッシュに登録 隣接粒子リストを作成 力の計算 位置と速度を更新 リストはまだ有効か? No Yes 領域からはみ出した粒子の処理 粒子の位置情報を更新
測定する場所 計算全体: このループを 1000ステップ積算 力の計算: ここだけをステップごと、 プロセスごとに計測 ※計算全体は並列化効率の定義のため、力の計算は揺らぎの測定のために調べる
9/13 Hyper-Threadingの影響 HTを有効にするだけで並列化効率が 大きく改善(66%→90%)
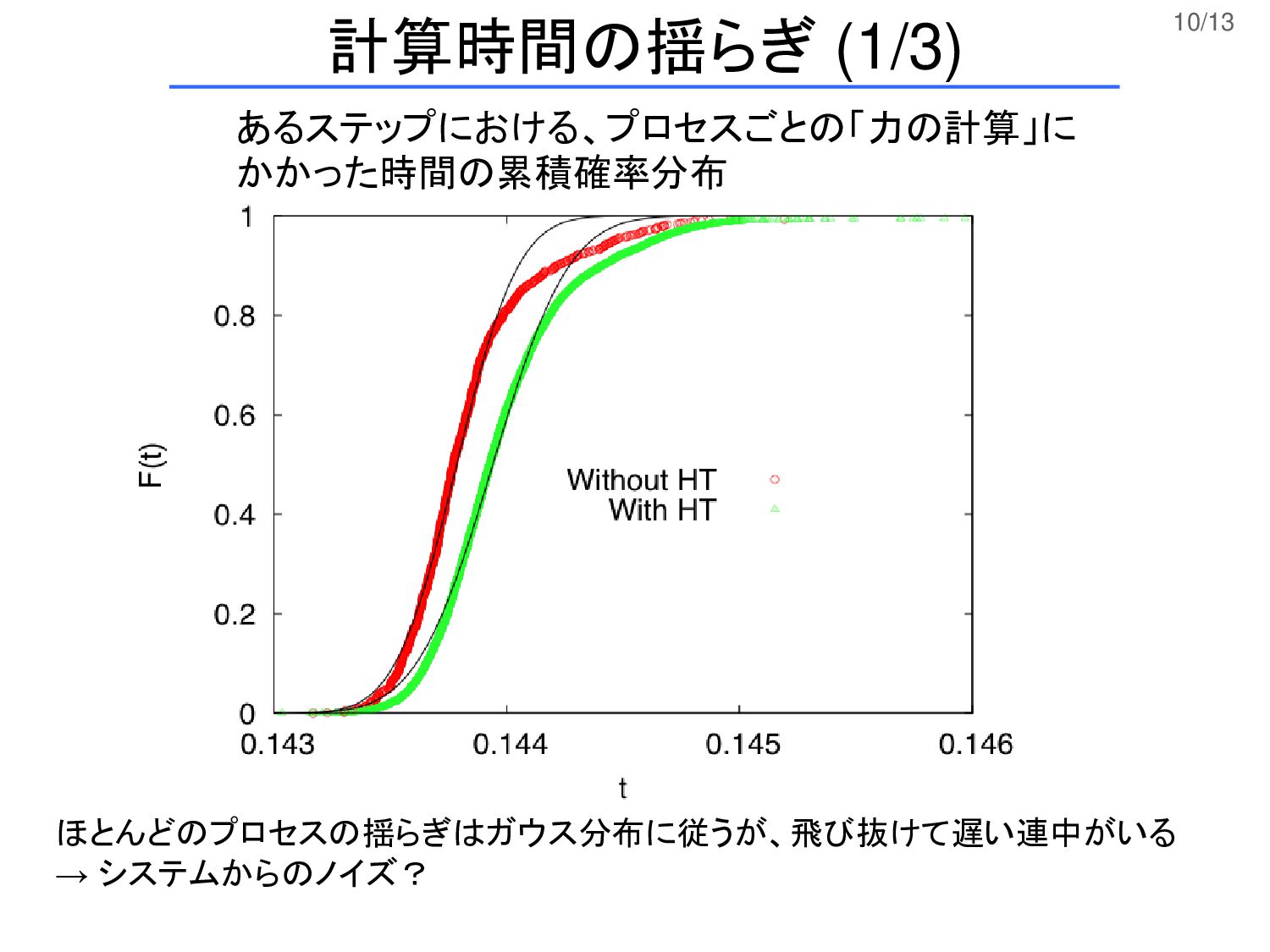
10/13 あるステップにおける、プロセスごとの「力の計算」に かかった時間の累積確率分布 ほとんどのプロセスの揺らぎはガウス分布に従うが、飛び抜けて遅い連中がいる → システムからのノイズ? 計算時間の揺らぎ (1/3)
11/13 誤差関数でフィットしてみる 特徴的な時間「τ」 ガウス分布の標準偏差に相当 HTなし:平均時間 143.785 [ms] 標準偏差 0.29 [ms]
HTあり:平均時間 143.940 [ms] 標準偏差 0.36 [ms] 一番遅かったプロセス: HTなし: 221.543 [ms] HTあり: 164.009 [ms] 平均からのずれが256σ 統計情報からはHTなしの方が優れている(平均も揺らぎも小さい)が・・・ 一番遅いプロセスの実行時間がHTにより大きく改善された 計算時間の揺らぎ (2/3)
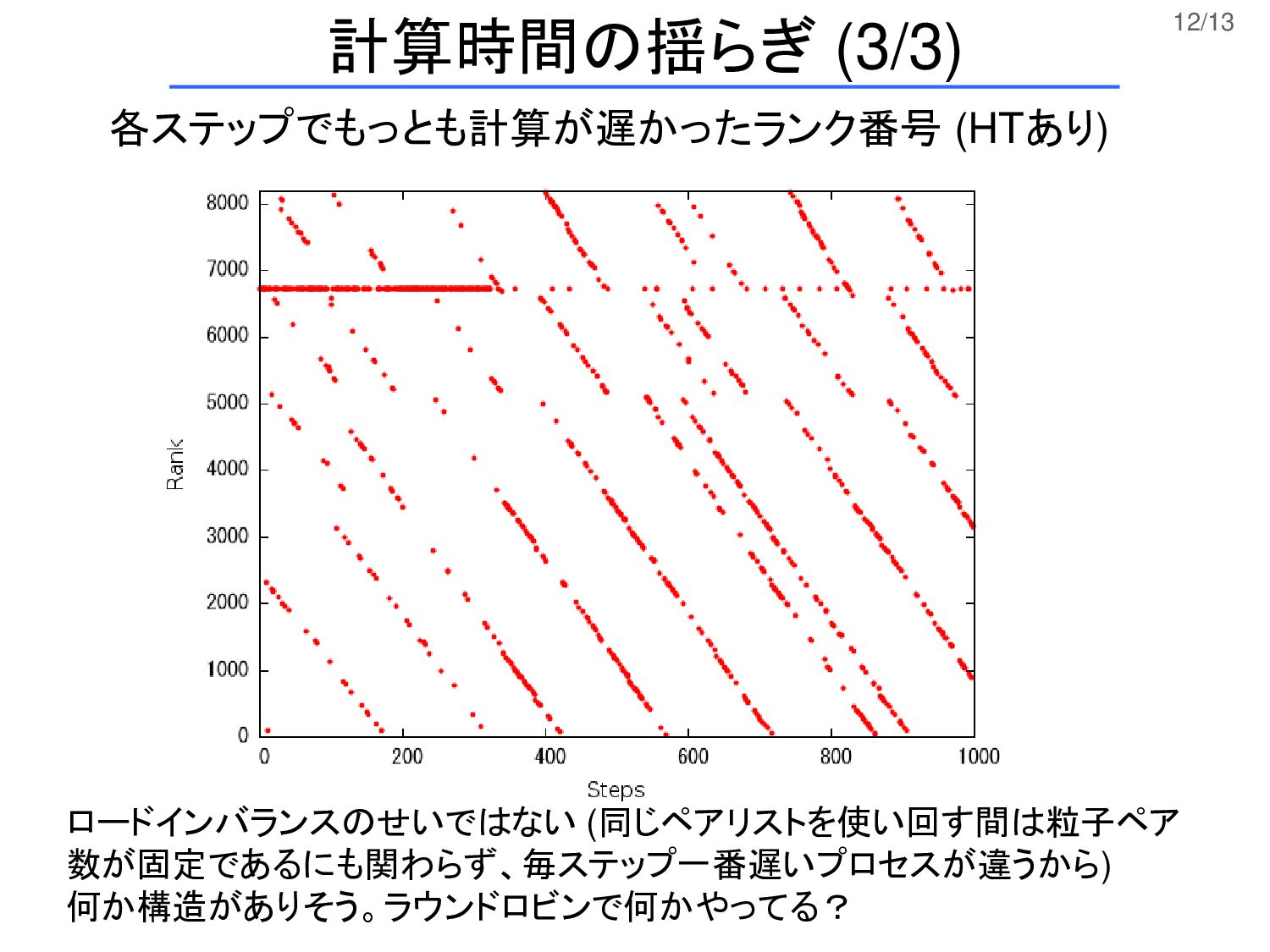
12/13 計算時間の揺らぎ (3/3) 各ステップでもっとも計算が遅かったランク番号 (HTあり) ロードインバランスのせいではない (同じペアリストを使い回す間は粒子ペア 数が固定であるにも関わらず、毎ステップ一番遅いプロセスが違うから) 何か構造がありそう。ラウンドロビンで何かやってる?
13/13 まとめのようなもの (1) Hyper-Threading Technologyを有効にすることで 並列化効率が大きく向上→HTによるスムーズなス レッドの切り替えが要因? (2) 揺らぐ時間は80ミリ秒といったオーダー →
OSジッタとしては大きすぎる (3) 通信を含まないはずの領域を測定しているのに、計 算時間が大きく揺らぐ →通信の後処理が割り込んでいる?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![11/13 誤差関数でフィットしてみる 特徴的な時間「τ」 ガウス分布の標準偏差に相当 HTなし:平均時間 143.785 [ms] 標準偏差 0.29 [ms]](https://files.speakerdeck.com/presentations/dda9cad1f81a4018934b382b3214a638/slide_10.jpg){kind=link}
{kind=link}
{kind=link}