Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
多変量解析(数量化Ⅰ~Ⅳ類)
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
katsutan
March 30, 2017
Technology
400
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
多変量解析(数量化Ⅰ~Ⅳ類)
長岡技術科学大学 自然言語処理研究室 B3ゼミ発表9
katsutan
March 30, 2017
More Decks by katsutan
See All by katsutan
What does BERT learn about the structure of language?
katsutan
0
270
Simple and Effective Paraphrastic Similarity from Parallel Translations
katsutan
0
230
Simple task-specific bilingual word embeddings
katsutan
0
230
Retrofitting Contextualized Word Embeddings with Paraphrases
katsutan
0
290
Character Eyes: Seeing Language through Character-Level Taggers
katsutan
1
250
Improving Word Embeddings Using Kernel PCA
katsutan
0
250
Better Word Embeddings by Disentangling Contextual n-Gram Information
katsutan
0
350
Rotational Unit of Memory: A Novel Representation Unit for RNNs with Scalable Applications
katsutan
0
290
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings
katsutan
0
320
Other Decks in Technology
See All in Technology
複数プロダクトで進めるAI機能実装 ── 実践から得たリアルな学びとロードマップ実現への挑戦 / AICon2026_yanari
rakus_dev
1
270
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
280
ファミコンでPHPを動かす / PHP on the Famicom
tomzoh
2
600
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
470
仕様駆動開発、導入半年。「本当に速くなってるの?」にデータで答える / AICon2026_hirakawa
rakus_dev
0
310
発表と総括 / Presentations and Summary
ks91
PRO
0
190
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
200
設計レビューとAIハーネスで向き合う AIが生み出した新しいボトルネックの対処法 / Design Reviews and AI Harnesses Against New Bottlenecks Created by AI
nstock
4
420
Network Firewallやっていき!
news_it_enj
0
260
それでも、技術なブログを書く理由 #kichijojipm / Why I Still Write Tech Blogs Even Now
shinkufencer
0
200
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
1
410
副作用のある Lambda でも Lambda Power Tuning は使えるのか / lambda-power-tuning-side-effects
koukihosaka
1
140
Featured
See All Featured
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
Crafting Experiences
bethany
1
230
The Illustrated Children's Guide to Kubernetes
chrisshort
51
53k
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1.1k
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
How Software Deployment tools have changed in the past 20 years
geshan
0
34k
Optimizing for Happiness
mojombo
378
71k
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.7k
4 Signs Your Business is Dying
shpigford
187
22k
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Transcript
多変量解析(数量化Ⅰ~Ⅳ類) 長岡技術科学大学 自然言語処理研究室 学部3年 勝田 哲弘 1 2017/3/31
データ • 4種の尺度 • 名義尺度 ▫ 数値自体に意味がない • 順序尺度 ▫
大小には意味がある 2 質的データ 名義尺度 名義的に数値化 男を1、女を2 順序尺度 順序に意味がある 好き1、それほどではな い2、嫌い3 量的データ 間隔尺度 数の間隔に意味がある 部屋の温度計 比例尺度 数値の差や比に意味がある 身長、体重、時間
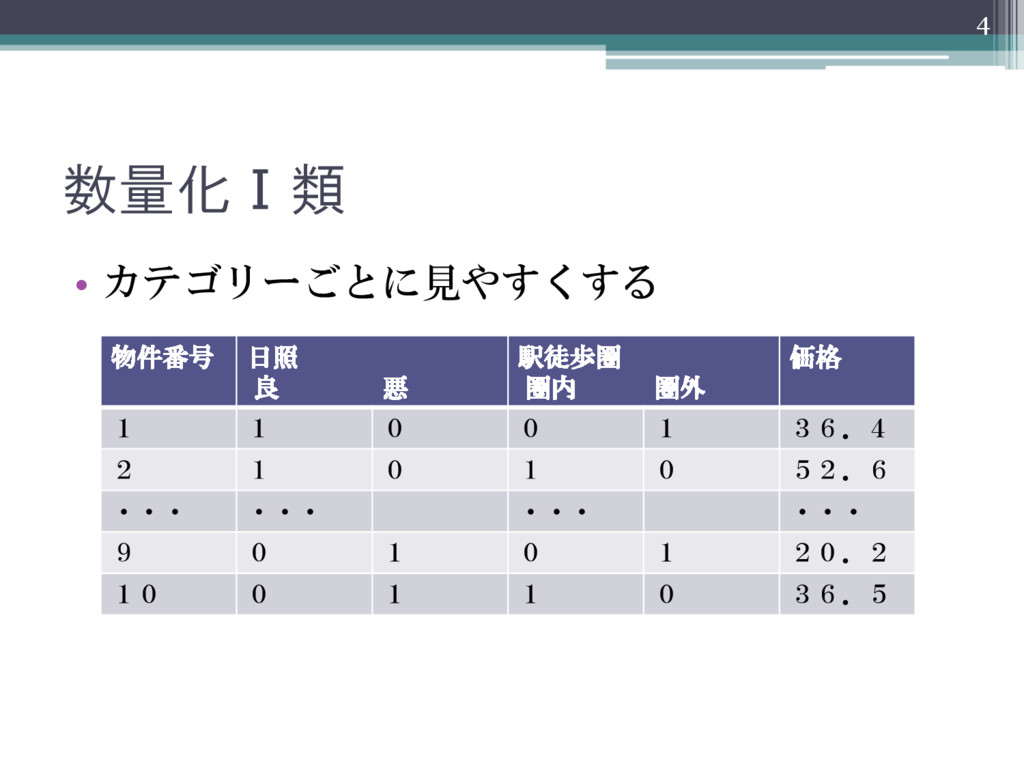
数量化Ⅰ類 • 数値データを外的基準として質的データを数量 化 3 物件番号 日照 駅徒歩圏 価格 1
良 圏外 36.4 2 良 圏内 52.6 ・・・ ・・・ ・・・ ・・・ 9 悪 圏外 20.2 10 悪 圏内 36.5
数量化Ⅰ類 • カテゴリーごとに見やすくする 4 物件番号 日照 良 悪 駅徒歩圏 圏内
圏外 価格 1 1 0 0 1 36.4 2 1 0 1 0 52.6 ・・・ ・・・ ・・・ ・・・ 9 0 1 0 1 20.2 10 0 1 1 0 36.5
数量化Ⅰ類 • カテゴリーウェイト ▫ 各カテゴリーの関係を表す重み • サンプルスコア 1 1 +
2 2 + 1 1 + 2 2 5 アイテム 日照 駅徒歩圏 カテゴリー 良い 悪い 圏内 圏外 ウェイト 1 2 1 2 物件k 1 2 1 2
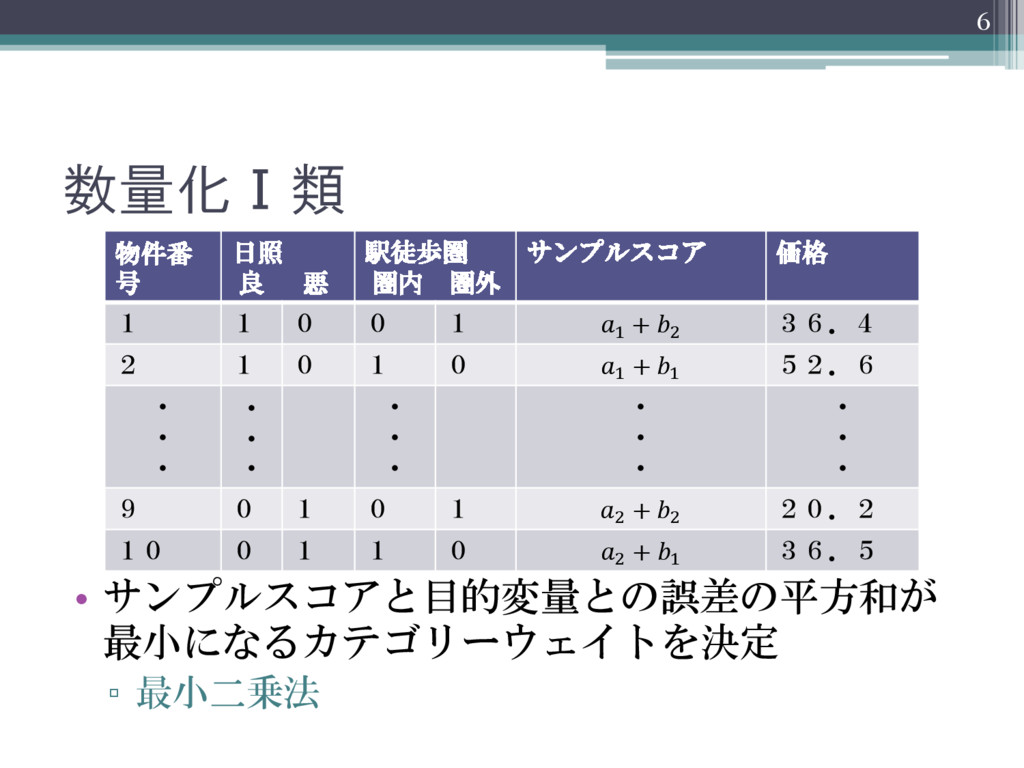
数量化Ⅰ類 • サンプルスコアと目的変量との誤差の平方和が 最小になるカテゴリーウェイトを決定 ▫ 最小二乗法 6 物件番 号 日照
良 悪 駅徒歩圏 圏内 圏外 サンプルスコア 価格 1 1 0 0 1 1 + 2 36.4 2 1 0 1 0 1 + 1 52.6 ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ 9 0 1 0 1 2 + 2 20.2 10 0 1 1 0 2 + 1 36.5
数量化Ⅱ類 • 質的データを外的基準として質的データを数量 化 7 名前 会話 家事 所得 結婚離婚
A 1 2 1 結婚 B 2 1 1 結婚 C 1 1 2 結婚 D 1 2 2 離婚 会話 家事 所得 1:多い 1:する 1:まあ満足 2:少ない 2:しない 2:不満
数量化Ⅱ類 • サンプルスコアを計算し、カテゴリーウェイト を決定 ▫ 相関比を最大に • 相関比 2 =
: 全変動 : 群間変動 8
数量化Ⅱ類 • : 全変動 = (1 − )2+(2 − )2+
⋯ + ( − )2 z:サンプルスコア • : 群間変動 = ( − )2+ ( − )2 n:群の個体数 P,Q:結婚、離婚 9
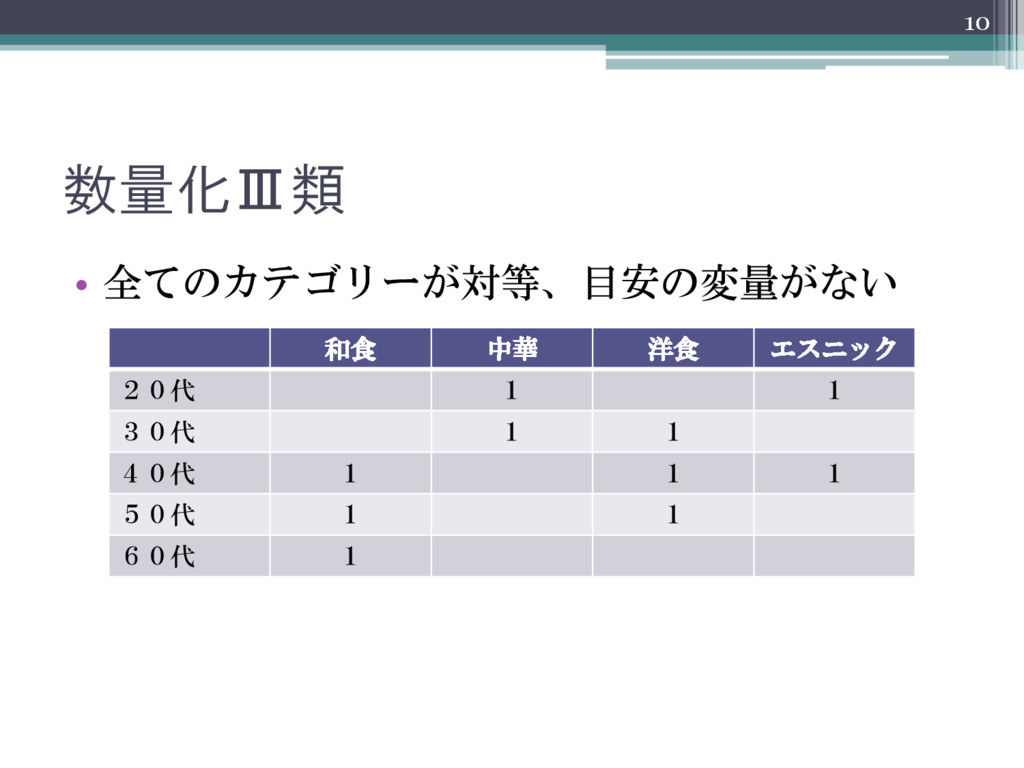
数量化Ⅲ類 • 全てのカテゴリーが対等、目安の変量がない 10 和食 中華 洋食 エスニック 20代 1
1 30代 1 1 40代 1 1 1 50代 1 1 60代 1
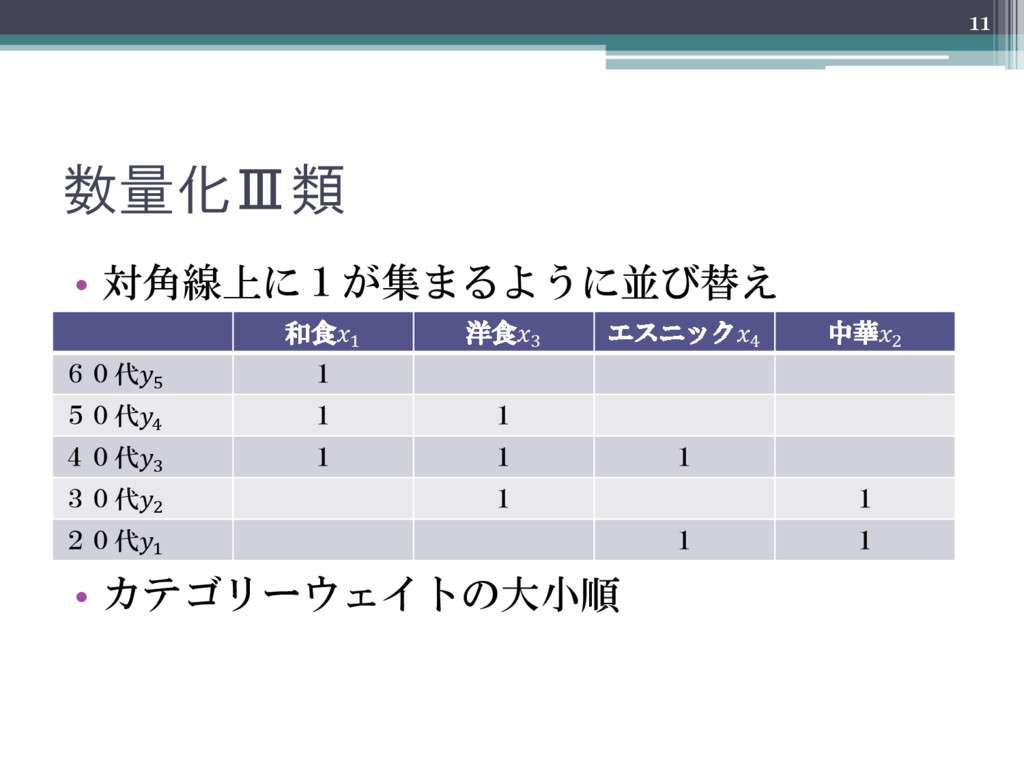
数量化Ⅲ類 • 対角線上に1が集まるように並び替え • カテゴリーウェイトの大小順 11 和食1 洋食3 エスニック4 中華2
60代5 1 50代4 1 1 40代3 1 1 1 30代2 1 1 20代1 1 1
数量化Ⅲ類 • 相関係数R R = 1 − 3 − +
1 − 4 − + ⋯ + 4 − 3 − 3 1 − 2 + ⋯ + 2 4 − 2 2 1 − 2 + ⋯ + 5 − 2 • 相関係数を最大とするように数量化 12
数量化Ⅳ類 • 数量化Ⅲ類と同様に数量化の基準がない資料が 対象 • 親近度 13 5 8 4
5 7 5 7 7 8 3 6 7
数量化Ⅳ類 • 親近度の重みを付けた距離の平方和Q = 5(2 − 1 )2+8(3 − 1
)2+4(4 − 1 )2 + ⋯ +3(1 − 4 )2+6(2 − 4 )2+7(3 − 4 )2 • Qの最小化で1 , 2 , 3 , 4 を求める 14
条件付け • 数量化Ⅰ類 ▫ どれか1つのカテゴリーウェイトを0にする • 数量化Ⅱ類 ▫ サンプルスコアの分散を1にする •
数量化Ⅲ類 ▫ 平均値をそれぞれ0、分散をそれぞれ1にする • 数量化Ⅳ類 ▫ 平均値を0、変動を1にする 15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}