Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Split and Rephrase: Better Evaluation and a Str...
Search
katsutan
November 12, 2018
Technology
180
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Split and Rephrase: Better Evaluation and a Stronger Baseline
文献紹介
katsutan
November 12, 2018
More Decks by katsutan
See All by katsutan
What does BERT learn about the structure of language?
katsutan
0
260
Simple and Effective Paraphrastic Similarity from Parallel Translations
katsutan
0
230
Simple task-specific bilingual word embeddings
katsutan
0
230
Retrofitting Contextualized Word Embeddings with Paraphrases
katsutan
0
290
Character Eyes: Seeing Language through Character-Level Taggers
katsutan
1
240
Improving Word Embeddings Using Kernel PCA
katsutan
0
250
Better Word Embeddings by Disentangling Contextual n-Gram Information
katsutan
0
350
Rotational Unit of Memory: A Novel Representation Unit for RNNs with Scalable Applications
katsutan
0
290
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings
katsutan
0
320
Other Decks in Technology
See All in Technology
Baseline対応のDOMの型定義を作った
uhyo
3
670
デジタル・デザイン:次の50年を描く「進化する青写真」
y150saya
0
800
SRE Lounge Hiroshimaへの招待
grimoh
0
150
グローバルチームと挑むプロダクト開発
sansantech
PRO
1
150
AI駆動開発におけるQAエンジニアの役割事例 〜AI駆動開発の現場から〜
kobayashiyorimitsu
0
300
どうして今サーバーサイドKotlinを選択したのか
nealle
0
190
Docker Desktop不要の時代が来る? WSL標準の「wslc」で Linuxコンテナを動かしてみた.
ueponx
0
660
飲食店もAIで。レジ締めやハンディシステムをつくってる話 / Using AI for restaurant management
vtryo
0
240
AIで政治は変わるのか? — 中高生と考えたAI時代の民主主義(東海高校サタデープログラム)
eitarosuda
0
380
Mastraエージェント、どのクラウドにデプロイする?
minorun365
PRO
2
150
【FinOps】データドリブンな意思決定を目指して
z63d
3
600
完全自律ロボットを作りたくて、先に開発を自律させた話(ROS Japan UG #63 LT)
rryz09
0
110
Featured
See All Featured
How STYLIGHT went responsive
nonsquared
100
6.2k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
580
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
170
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
310
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.5k
Into the Great Unknown - MozCon
thekraken
41
2.6k
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
170
Prompt Engineering for Job Search
mfonobong
0
360
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
380
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
550
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
Transcript
Split and Rephrase: Better Evaluation and a Stronger Baseline Roee
Aharoni & Yoav Goldberg Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Short Papers), pages 719–724 Melbourne, Australia, July 15 - 20, 2018. 長岡技術科学大学 自然言語処理研究室 勝田 哲弘
Abstract Split and Rephrase • 複数の文が含まれている文から意味を保持したまま、分割と言い換えを行う 新たな分割データセット、モデルの提案 2
Introduction “Split-and-Rephrase” by Narayan et al. (2017) • データセット、評価方法、ベースラインの設定 •
BlEU ◦ 48.9 for the best text-to-text system. ◦ 78.7 for the best RDF-aware one. text-to-textモデルに注目 3
Introduction • より困難なデータセットの提案 ◦ 既存のデータセットには問題がある ◦ new split : Githubで公開
• より優れたモデルを構築 ◦ copy mechanismの拡張 4
Preliminary Experiments Task Definition • Complex sentence: Cが与えられたときに全ての情報を含む ように平易文を生成 ◦
Simple sentence: • 各文をRDF triplesと関連付ける 5
Preliminary Experiments Experimental Details • vanilla sequence-to-sequence models with attention
(Bahdanau et al., 2015) ◦ OPENNMT-PY toolkit (Klein et al., 2017) ◦ LSTM cell size (128, 256 and 512, respectively) 6
Results RDFを用いるベースラインより優れている Narayan et al. (2017)のモデルは 過剰に分割を行っている 7
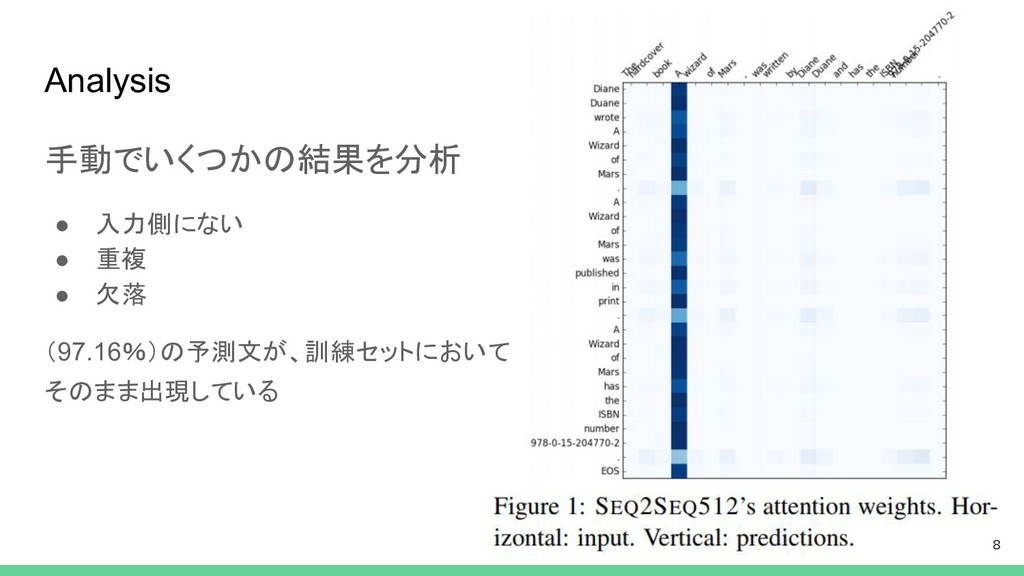
Analysis 手動でいくつかの結果を分析 • 入力側にない • 重複 • 欠落 (97.16%)の予測文が、訓練セットにおいて そのまま出現している
8
Analysis 9
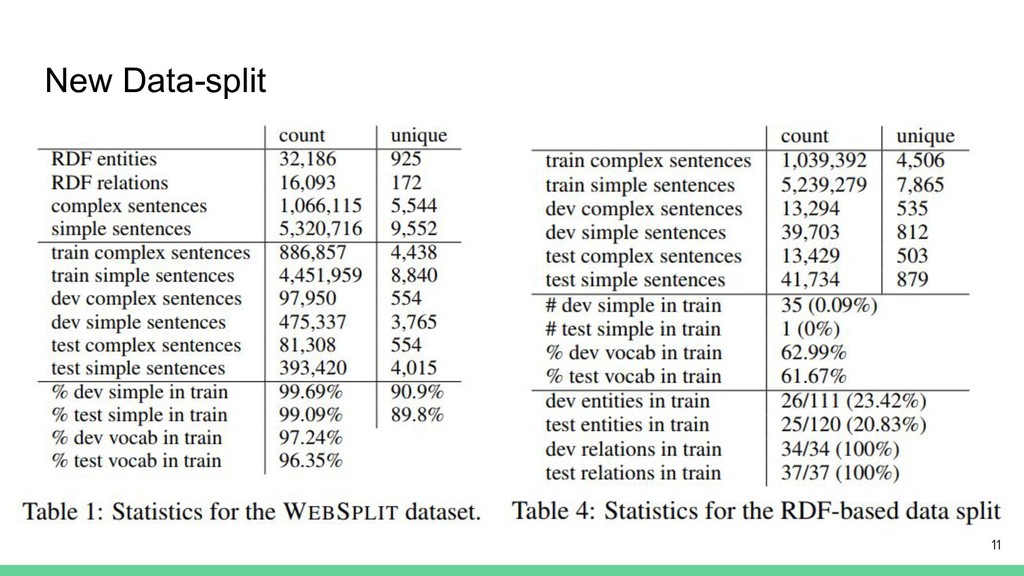
New Data-split 今のデータセットは問題を一般化するために適していない、より良 いデータセットの構築を行う RDFを使用し、以下の条件でランダムに文を分割する(5,554 sentences) • 全てのRDF relationを学習データに含める •
全てのRDF triplesは分割した1文で表現される 10
New Data-split 11
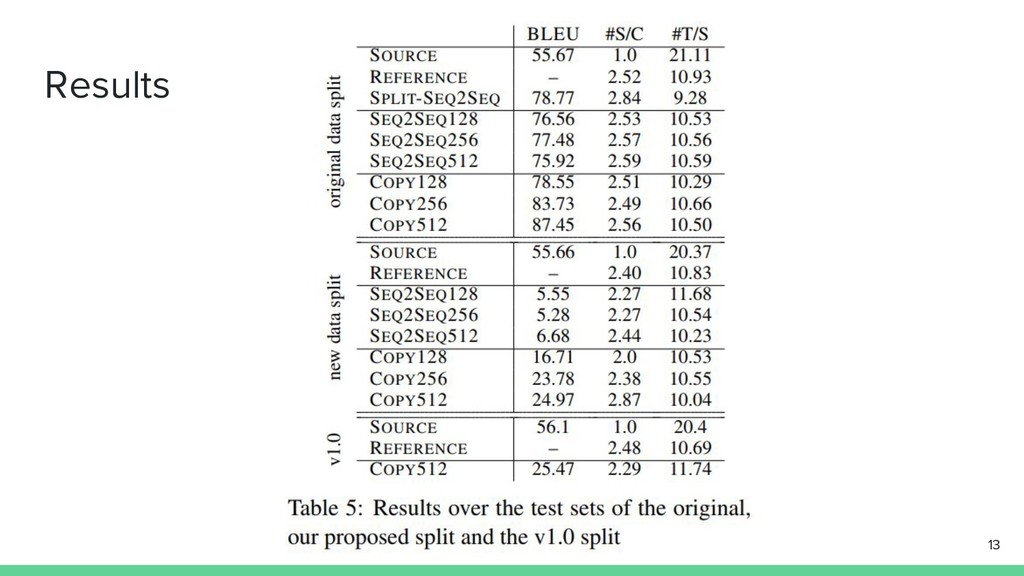
Experiments and Results 新しいデータセットによる評価 • new data split • v1.0
モデルの拡張: Copy • copy-enhanced models of varying LSTM widths ◦ (128, 256 and 512) 12
Results 13
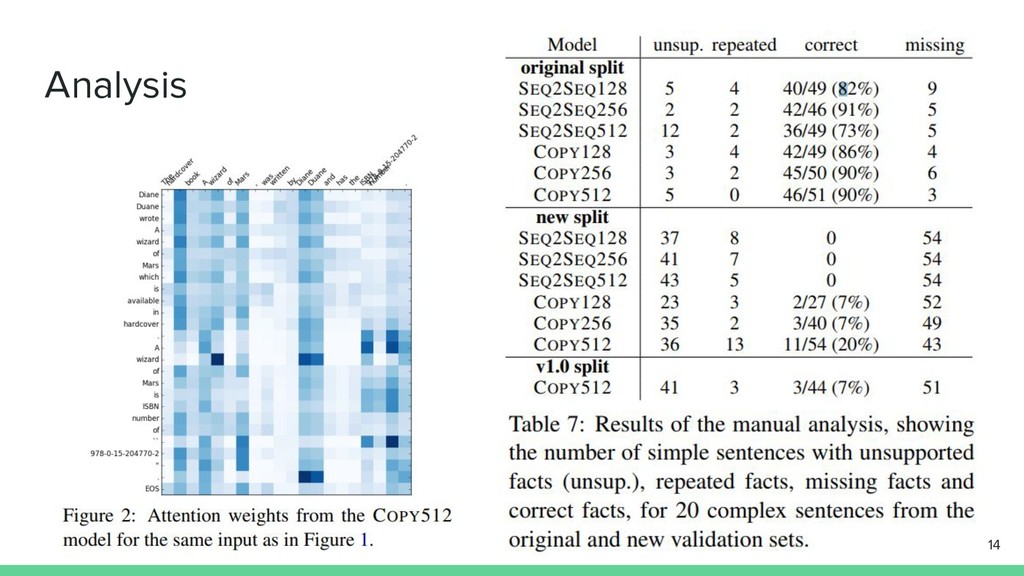
Analysis 14
Analysis SEQ2SEQ512では学習データから文を生成する傾向が強くなる 15
Conclusions • SEQ2SEQモデルがsplit-and-rephraseを学習していなくても 高いスコアを得ていることを確認した • 新たに構築したデータセットでは不当に高くなる問題を改善 • どちらのモデルに対してもcopy-mechanismがパフォーマンス を向上させる 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}