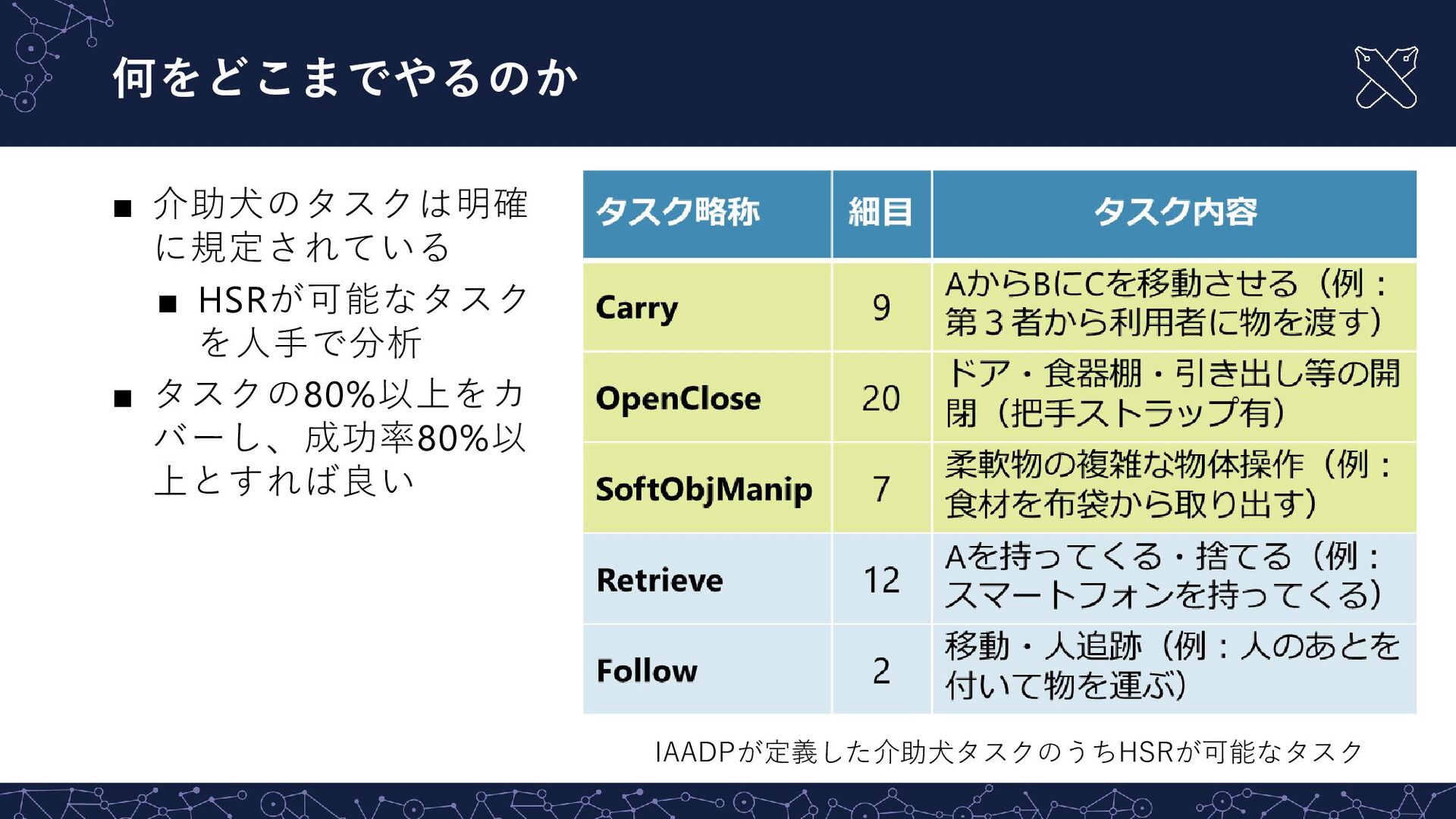
+ 2022/4]) a photo of a beer bottle satellite imagery of roundabout a photo of a marimba a meme Text Text feat. Image feat. Image ※UNITER[Chen+ 20]やBLIP [Li+ 22]等もロボティクス で用いられる https://vimeo.com/692375454
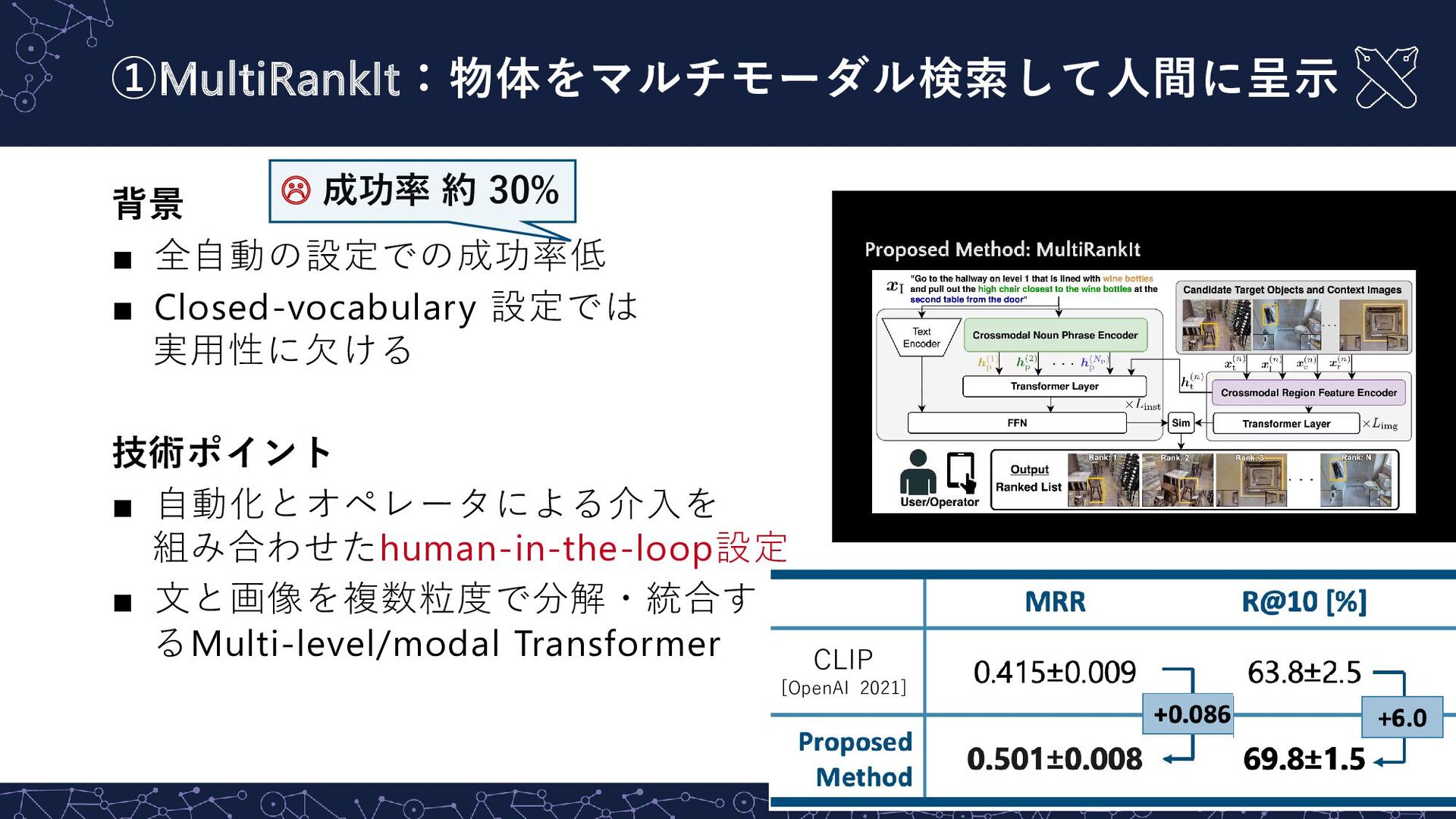
a wagon and bring me the towel directly across from the sink” Rank: 1 Rank: 2 Rank: 3 Rank: 4 Rank: 5 Rank: 6 … Rank: 1 Rank: 2 Rank: 3 Rank: 4 Rank: 5 Rank: 6 … Instruction: “Go to the hallway on level 1 that is lined with wine bottles and pull out the high chair closest to the wine bottles at the second table from the door”
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![画像と言語を扱うマルチモーダル基盤モデル: CLIP[Radford+ 21] ▪ 画像とテキストの組(4億組)の特徴量同士が近くなるように学習 ▪ 多数の応用(例:DALL·E 2 [Aditya (OpenAI)](https://files.speakerdeck.com/presentations/db4fbfacfb3e4530a7161d541af811bb/slide_5.jpg){kind=link}
![CLIPを物体操作・探索に利用 - - 7 物体操作 CLIPort [Shridhar+ CoRL21], PerAct [Shridhar+](https://files.speakerdeck.com/presentations/db4fbfacfb3e4530a7161d541af811bb/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![ロボット用基盤モデル構築の試み - - 11 RT-1[Brohan+50人の著者, 22] ▪ ロボット13台x17ヶ月の膨大な 学習データ ▪](https://files.speakerdeck.com/presentations/db4fbfacfb3e4530a7161d541af811bb/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![移動指示・物体探索指示に関するデータセット: シミュレーションと実世界 実世界 ▪ Room2Room [Anderson+ CVPR18], REVERIE[Qi+ CVPR20] ▪](https://files.speakerdeck.com/presentations/db4fbfacfb3e4530a7161d541af811bb/slide_19.jpg){kind=link}
![②マルチモーダル言語処理における転移学習手法 [Otsuki+ IROS23] 背景 ▪ ロボットを使ったマルチモーダ ルコーパス構築はコストが高い 技術ポイント ▪ 転移元と転移先のプロトタイプ](https://files.speakerdeck.com/presentations/db4fbfacfb3e4530a7161d541af811bb/slide_20.jpg){kind=link}
![ベースライン手法(拡張前の手法)を超える性能 Method Acc. [%]↑ 転移先のデータのみ 73.0±1.87 MCDDA+ [Saito+, CVPR18] 74.9±3.94](https://files.speakerdeck.com/presentations/db4fbfacfb3e4530a7161d541af811bb/slide_21.jpg){kind=link}
{kind=link}
![Switching Head-tail Funnel UNITERを構築し 推論速度を実用レベルとした[Korekata+ IROS23] 24 技術ポイント ▪ 単一モデルで対象物体/配置目標](https://files.speakerdeck.com/presentations/db4fbfacfb3e4530a7161d541af811bb/slide_23.jpg){kind=link}
![④移動指示の理解:CrossMap Transformer [Magassouba, Sugiura+ RAL & IROS2021] 【タスク】移動指示の理解 【技術ポイント】 ▪](https://files.speakerdeck.com/presentations/db4fbfacfb3e4530a7161d541af811bb/slide_24.jpg){kind=link}
![⑤モビリティ向け移動指示理解 [畑中+ 23] 【タスク】 「バイクが止まっている所の横に 停めて」等の移動指示言語理解 【技術ポイント】 ▪ 夜間画像のセグメンテーション マスク信頼度を推定](https://files.speakerdeck.com/presentations/db4fbfacfb3e4530a7161d541af811bb/slide_25.jpg){kind=link}
{kind=link}
![PonNet:衝突危険性の予測および視覚的説明生成 [Magassouba+ Advanced Robotics 2021] 背景: 動作実行前に帰結を予測し(physical reasoning)、ユーザに 説明できれば便利 技術ポイント:](https://files.speakerdeck.com/presentations/db4fbfacfb3e4530a7161d541af811bb/slide_27.jpg){kind=link}
{kind=link}
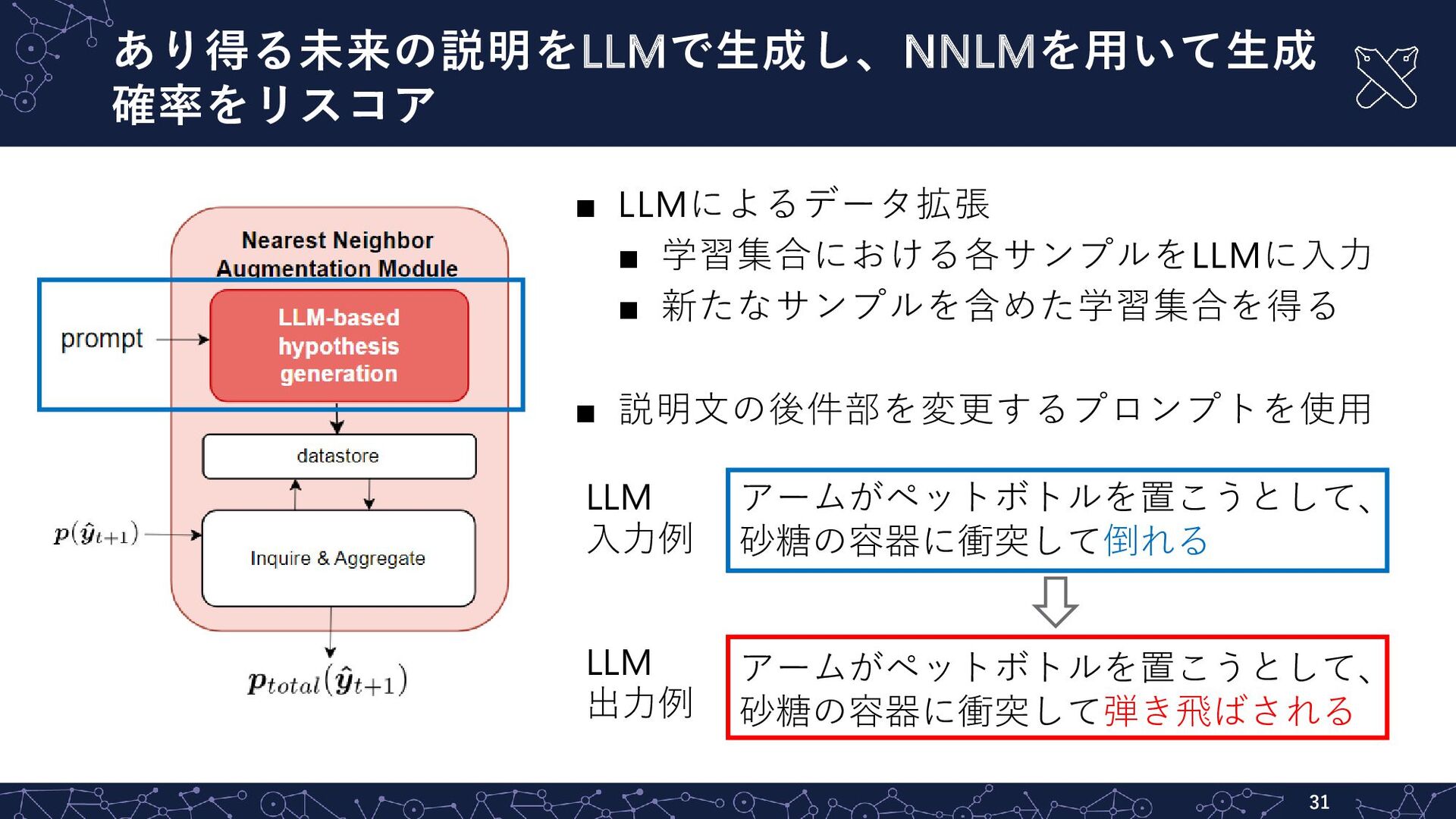
![将来のリスクに対する言語的説明生成:Future captioning [Kambara+ ICIP22][平野+ 23] - - 30 【タスク】 行動前にユーザに実行可否を判断](https://files.speakerdeck.com/presentations/db4fbfacfb3e4530a7161d541af811bb/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
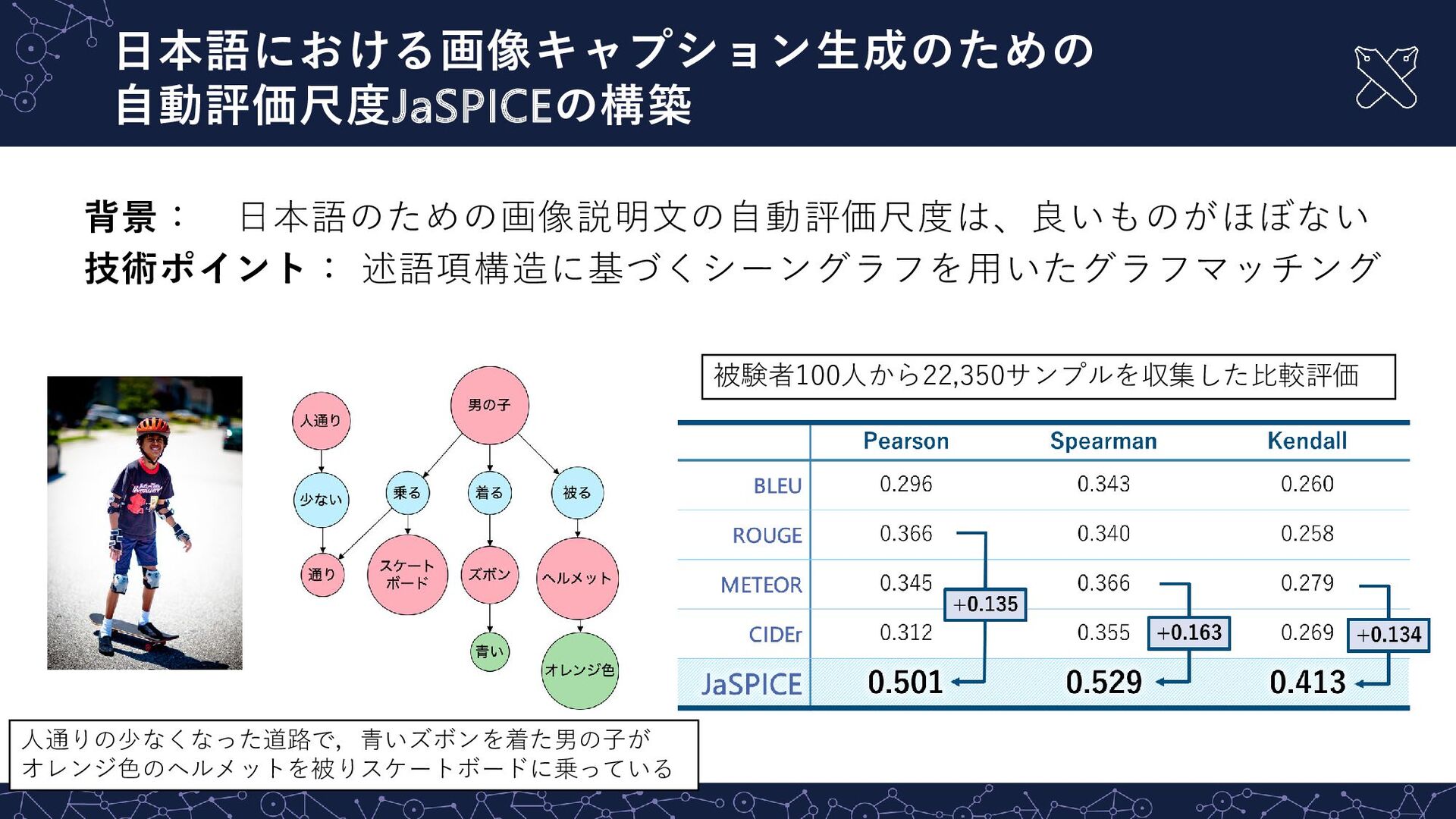{kind=link}
{kind=link}
{kind=link}
{kind=link}