Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal Club]A Unified Approach to Interpretin...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Semantic Machine Intelligence Lab., Keio Univ.
PRO
July 28, 2022
Technology
430
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal Club]A Unified Approach to Interpreting Model Predictions
Semantic Machine Intelligence Lab., Keio Univ.
PRO
July 28, 2022
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
84
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
98
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
テックカンファレンス三大ステークホルダーの文化人類学 ─ 違いを認め合う関係性作り
bash0c7
1
170
「守りたい体験」を渡すだけで E2E を生成させられるようになった話
hinac0
2
1k
AI Coding Agent時代のcdk-nagガードレール 〜組織ルールを強制CIで守り抜く設計の挑戦〜
mhrtech
3
510
AIが当たり前の組織で エンジニアはどう育つか
nishihira
1
970
AICoEでAIネイティブ組織への進化
yukiogawa
0
220
設計レビューとAIハーネスで向き合う AIが生み出した新しいボトルネックの対処法 / Design Reviews and AI Harnesses Against New Bottlenecks Created by AI
nstock
4
430
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
370
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
2
610
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
160
AI Native なプロダクト組織の立ち上げ方 : 生産性 100 倍への挑戦
mikesorae
0
1.3k
2年前に削除したPHPクラスが、 ある日突然決済をエラーにした
ykagano
1
780
生成AI×AWS CDK×AWS FISで"振り返れる"ミニGameDayをつくろう
yoshimi0227
2
530
Featured
See All Featured
Done Done
chrislema
186
16k
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
280
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
470
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
It's Worth the Effort
3n
188
29k
Building an army of robots
kneath
306
46k
Joys of Absence: A Defence of Solitary Play
codingconduct
1
420
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
420
The SEO Collaboration Effect
kristinabergwall1
1
510
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.9k
Transcript
A Unified Approach to Interpreting Model Predictions Scott Lundberg, Su-In
Lee (Paul G. Allen School of Computer Science University) NeurIPS 2017 慶應義塾大学 杉浦孔明研究室 飯岡雄偉
概要 : SHAP (SHapley Additive exPlanations) ◼ モデルの説明可能性・解釈性を向上 局所的な線形モデルへ
◼ Shapley値によってモデルの性能に対する貢献度を求める ◼ モデルの構造にかかわらず実装が可能 ◼ 人間の評価に近い性能を実現 2
背景 : 性能と説明可能性のトレードオフ ◼ 昨今の学習モデルは性能向上のために複雑化 ➢ どの特徴量が性能に寄与したのかをユーザが理解できない ➢ 「AI利活用原則案(総務省, 2018)」にも説明可能性への留意が言及されている
信用できないなぁ あなたは◦◦病です なんとなく そんな気がします 3
既存研究 : 説明可能性が不十分 4 ◼ LIME [Rebeiro+ 16] 複雑なモデルを局所的に線形モデルへ
変換 機械表現で学習したモデルを,可読表現 で説明 各特徴量が独立しているとみなすため に不十分 ◼ DeepLIFT[Shrinkumar+ 17] 深層学習モデルの説明に使用 入力を微小に変化させたときの出力の変化 によって注目度を決定 勾配の代わりに基準点からの差分を用いる 変化後”猫”と認識しなくなる ⇒正しい判断根拠がない
提案手法 : SHAP (SHapley Additive exPlanations) 5 ◼ LIMEと同様に機械表現での学習モデルを可読表現で説明する
説明モデルは局所的な線形モデル ◼ 入力された各特徴量は独立ではないことが多い ⚫ e.g. 蒙古タンメンが人気の理由はなにか. ⇒ 辛さ?おいしさ?⇒この2つには関係性がある ➢ それぞれの順番と組み合わせを考慮したShapley値を貢献度として利用
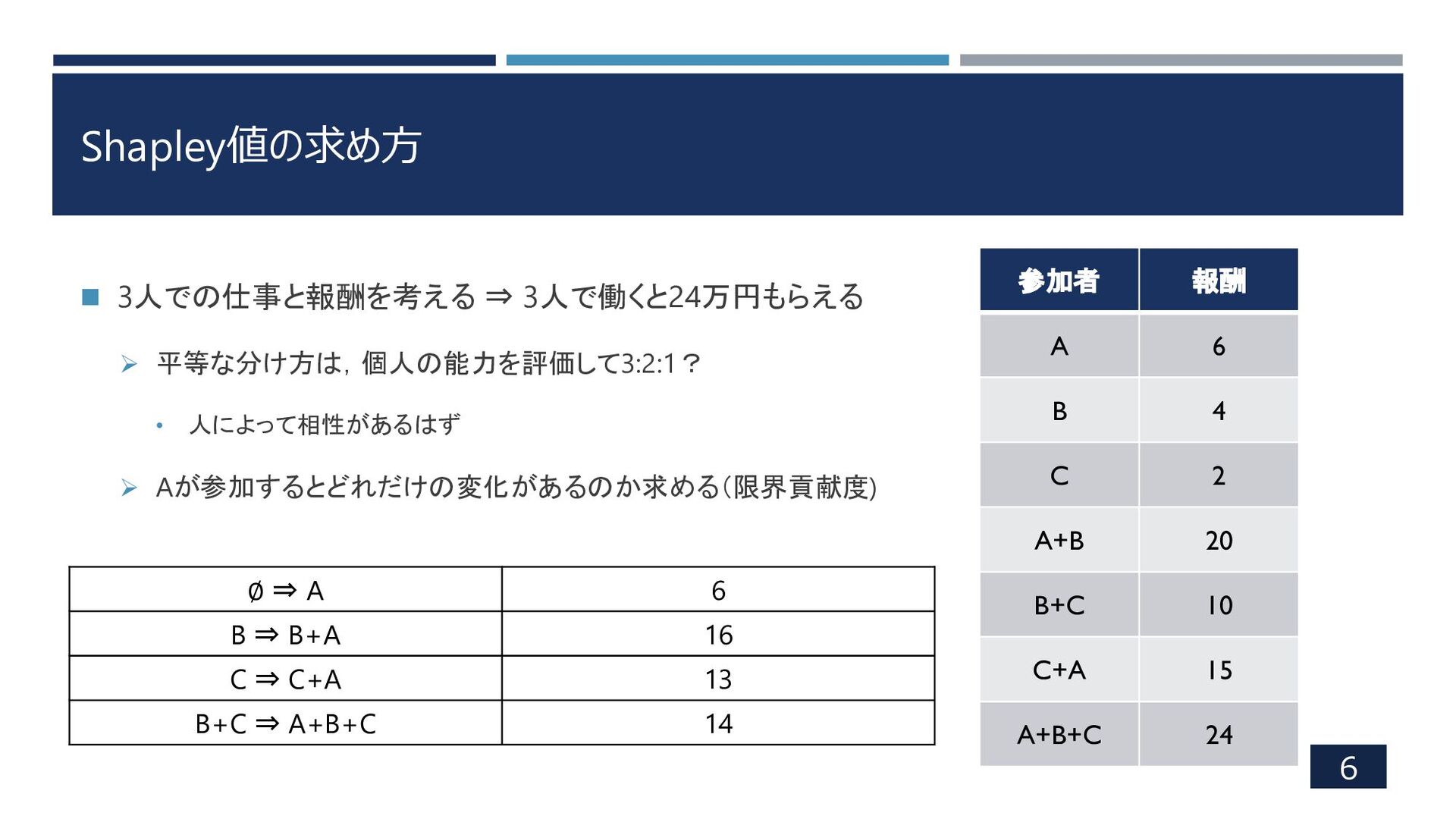
Shapley値の求め方 6 ◼ 3人での仕事と報酬を考える ⇒ 3人で働くと24万円もらえる ➢ 平等な分け方は,個人の能力を評価して3:2:1? • 人によって相性があるはず
➢ Aが参加するとどれだけの変化があるのか求める(限界貢献度) 参加者 報酬 A 6 B 4 C 2 A+B 20 B+C 10 C+A 15 A+B+C 24 ∅ ⇒ A 6 B ⇒ B+A 16 C ⇒ C+A 13 B+C ⇒ A+B+C 14
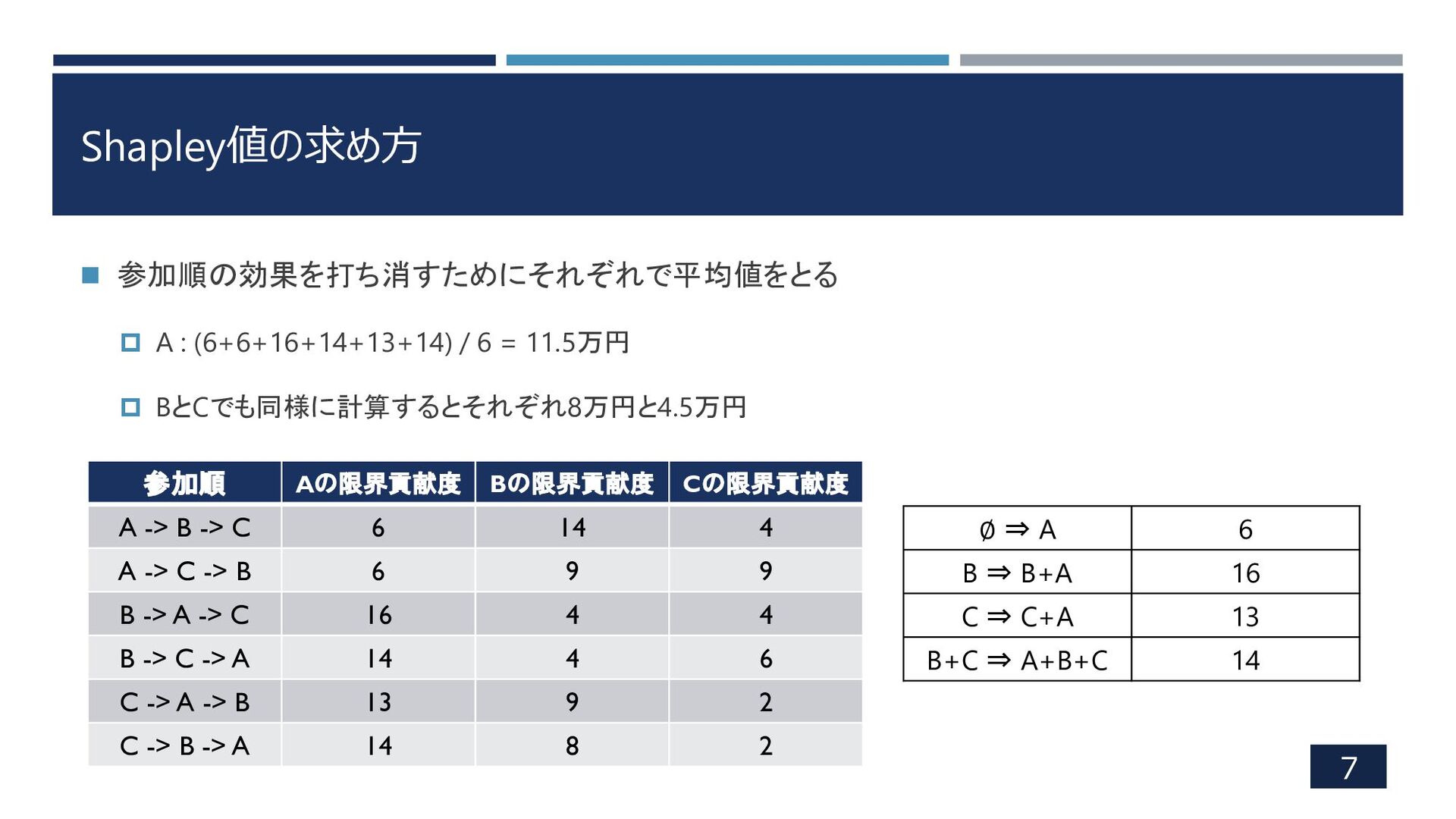
Shapley値の求め方 7 ◼ 参加順の効果を打ち消すためにそれぞれで平均値をとる A : (6+6+16+14+13+14) / 6
= 11.5万円 BとCでも同様に計算するとそれぞれ8万円と4.5万円 ∅ ⇒ A 6 B ⇒ B+A 16 C ⇒ C+A 13 B+C ⇒ A+B+C 14 参加順 Aの限界貢献度 Bの限界貢献度 Cの限界貢献度 A -> B -> C 6 14 4 A -> C -> B 6 9 9 B -> A -> C 16 4 4 B -> C -> A 14 4 6 C -> A -> B 13 9 2 C -> B -> A 14 8 2
3つの要請 : SHAPの原理 8 ① 説明対象モデル𝑓と説明モデル𝑔(線形)の値は等しい • 入力𝑥をバイナリデータである𝑥′にマッピングし,可読表現へ ➢ 言語や画像の𝑖番目の要素が存在するか否か
• 可読特徴に対する重要度を𝜙𝑖 で表す ➢ SHAPではこの𝜙𝑖 がshapley値となる ② 存在しない説明要因の貢献度をゼロにする
3つの要請 : SHAPの原理 9 ③ 異なるモデル𝑓と𝑓′において,可読特徴𝑧𝑖 ′の有無による値の変化量が大きいモデルのほ うが𝑧𝑖 ′の貢献度は大きくなる 𝑧𝑖
′ = 0 •𝑧′は可読特徴𝑥′における非ゼロ成分の部分集合
➢ Shapley値に𝜙𝑖 が一致する ⇒ 貢献度を表現 • 分母は並べ方の総数,分子は𝑧𝑖 ′以外の並べ方を示す ➢ 説明モデルから対象モデルの写像と,莫大な計算量が問題点
SHAPの主定理 10
➢ 𝑓𝑥 (𝑧′)では,説明モデルでの変数𝑧′のゼロ要素が対象モデルで意味を持つ可能性がある • e.g. 画像特徴量であれば0は意味を持ってしまう ➢ よって,非ゼロの要素𝑧𝑆 を条件に持つ期待値を求めるようにする •
ゼロ要素はランダムなデータ分布に従って値が割り振られる SHAPの主定理 : 問題点への対処 11
➢ 莫大な計算量を避けるため,shapley値を近似する モデルに依存しない : Kernel SHAP モデルに依存する :
Linear SHAP (各特徴量は独立しているととらえる) • Linear SHAP : 線形モデルに対して近似 ⇒ SHAPの主定理 : 問題点への対処 12 この関数がshapley値の近似を表す (証明は省略) https://drive.google.com/file/d/1GGOPytSR2ZeX8Yl0epVZoYTsAePuA5VP/view?usp=sharing
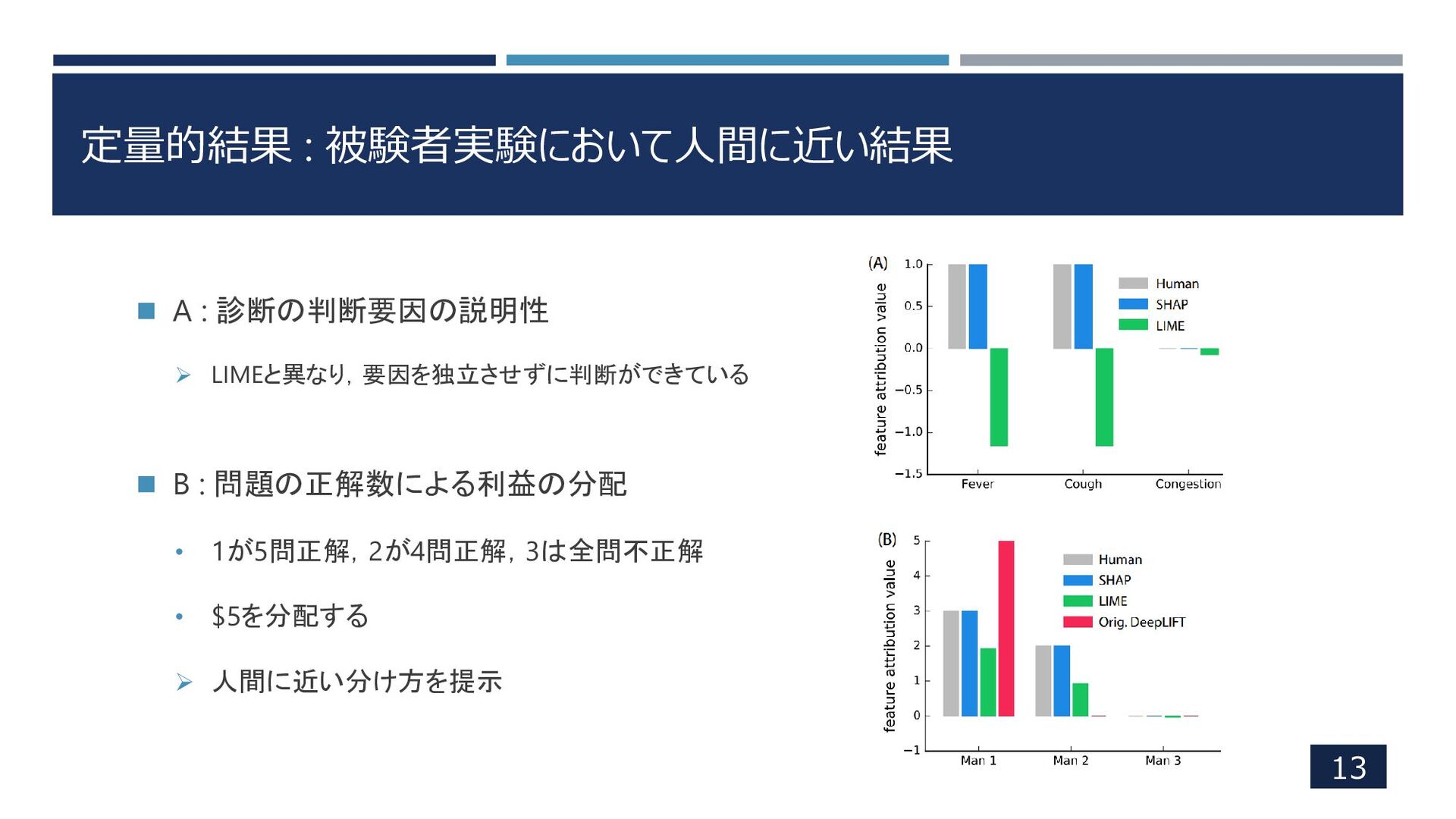
定量的結果 : 被験者実験において人間に近い結果 13 ◼ A : 診断の判断要因の説明性 ➢ LIMEと異なり,要因を独立させずに判断ができている
◼ B : 問題の正解数による利益の分配 • 1が5問正解,2が4問正解,3は全問不正解 • $5を分配する ➢ 人間に近い分け方を提示
定性的結果 : 既存手法と比較して良好な性能 14 ◼ MNISTによる実験 • 数字の予測の際にpositiveな要因を赤く, negativeな要因を青く表示 •
New DeepLiftはDeepLIFTにおける勾配に shapley値を利用 ➢ SHAPの考えを用いた2手法において,より はっきりと要因を理解している
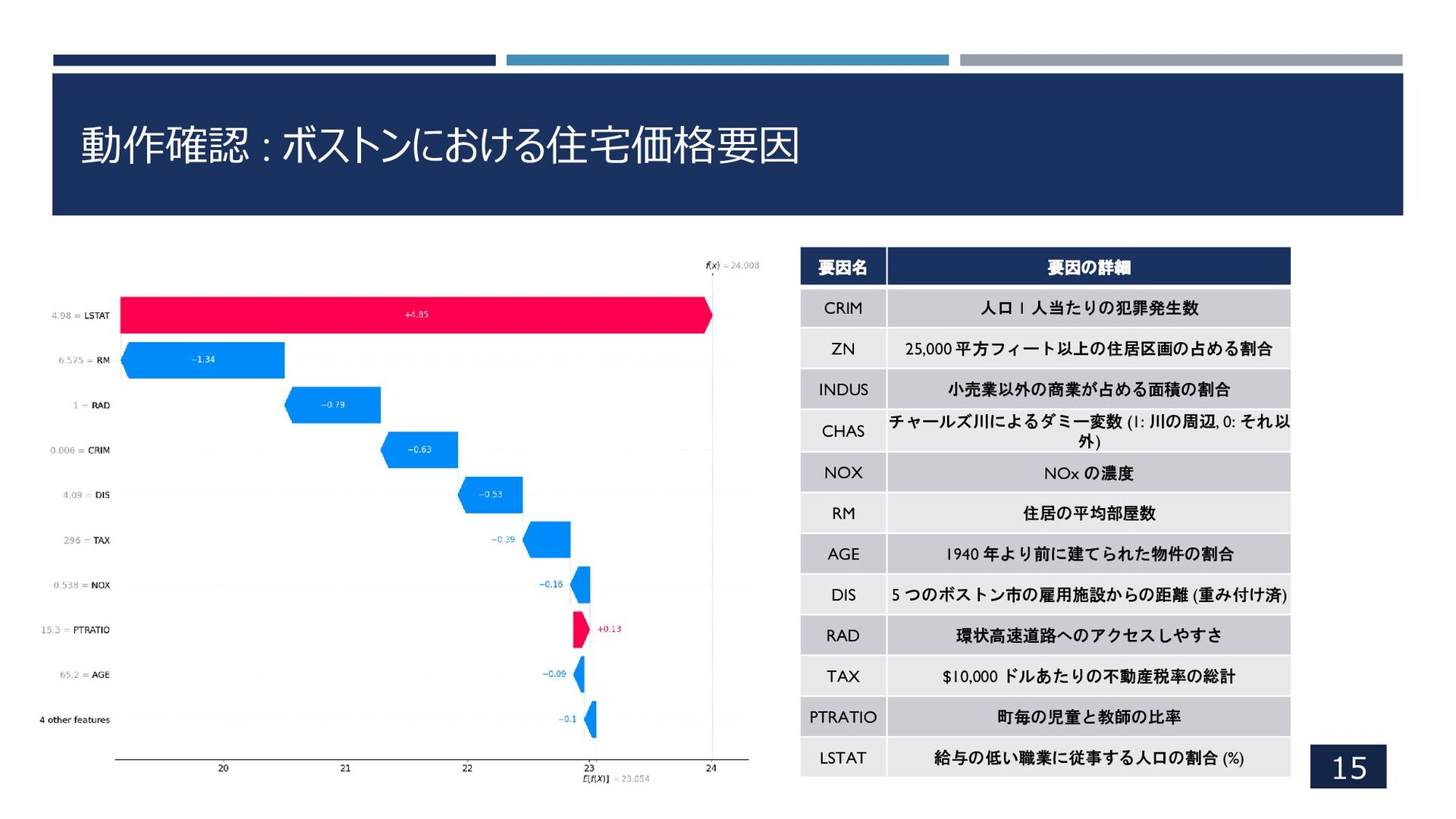
動作確認 : ボストンにおける住宅価格要因 15 要因名 要因の詳細 CRIM 人口 1 人当たりの犯罪発生数
ZN 25,000 平方フィート以上の住居区画の占める割合 INDUS 小売業以外の商業が占める面積の割合 CHAS チャールズ川によるダミー変数 (1: 川の周辺, 0: それ以 外) NOX NOx の濃度 RM 住居の平均部屋数 AGE 1940 年より前に建てられた物件の割合 DIS 5 つのボストン市の雇用施設からの距離 (重み付け済) RAD 環状高速道路へのアクセスしやすさ TAX $10,000 ドルあたりの不動産税率の総計 PTRATIO 町毎の児童と教師の比率 LSTAT 給与の低い職業に従事する人口の割合 (%)
まとめ 16 ◼ モデルの説明可能性・解釈性を向上 局所的な線形モデルへ ◼ Shapley値によってモデルの性能に対する貢献度を求める ◼ モデルの構造にかかわらず実装が可能
◼ 人間の評価に近い性能を実現
{kind=link}
{kind=link}
{kind=link}
![既存研究 : 説明可能性が不十分 4 ◼ LIME [Rebeiro+ 16] 複雑なモデルを局所的に線形モデルへ](https://files.speakerdeck.com/presentations/c0a053848582441598dc0f1c8637fe4a/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}