Guodong Zhang1,2, Aleksandar Botev3, James Martens3 (1University of Toronto, 2Vector Institute, 3DeepMind) 慶應義塾⼤学 杉浦孔明研究室 B4 和⽥唯我 Guodong Zhang et al., “Deep Learning without Shortcuts: Shaping the Kernel with Tailored Rectifiers”, in ICLR(2022) ICLR 2022
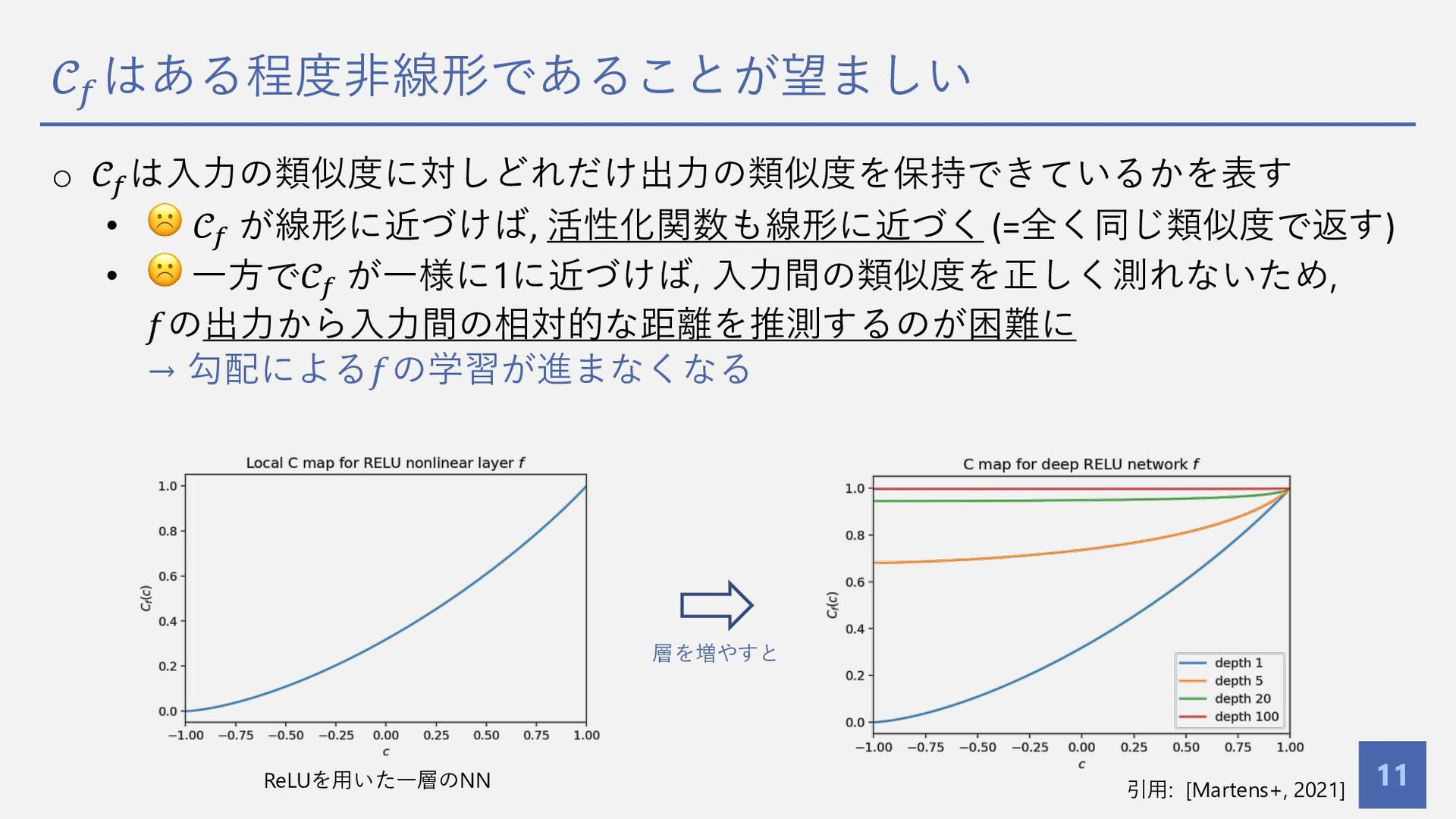
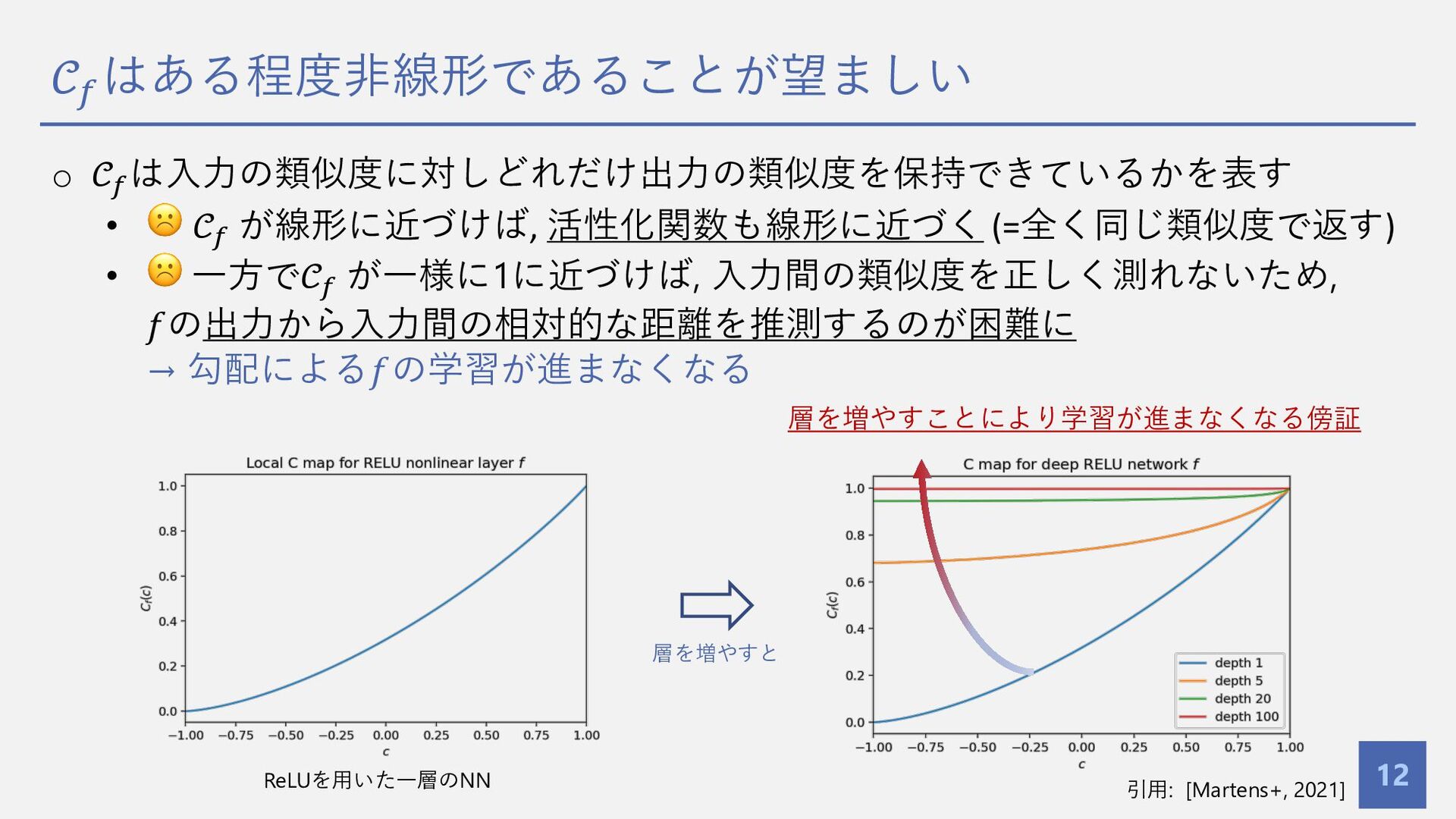
10 • 𝐿層のネットワーク 𝑓 に対し, 各層順に合成した以下の関数について, • これらをそれぞれ global Q map , global C map と呼ぶ. o 𝒞% ∶ global C map • ⼊⼒の類似度 𝑐 に対しどれだけ出⼒の類似度を保持できているかを表す • 勾配による学習に直結する重要な指標
{kind=link}
{kind=link}
![背景: 残差接続には解釈の⽭盾や⽋点が存在 3 o 解釈の⽭盾 • 残差接続は⽐較的浅い層のアンサンブルとみなすことができる[Veit+, NeurIPS16] • 「深層」学習](https://files.speakerdeck.com/presentations/501f6c49c99a4379b5fe89314715b695/slide_2.jpg){kind=link}
![既存研究: 汎⽤性と速度に課題が存在 4 o Edge of Chaos (EOC) [Schoenholz+, ICLR17]](https://files.speakerdeck.com/presentations/501f6c49c99a4379b5fe89314715b695/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![定量的結果: TATにより層を増やしても精度が安定するように 20 • OptimizerにはSGDとK-FAC[Martens+, PMLR15] • K-FAC: ⾃然勾配法(⽢利先⽣が考案)の近似によるOptimizer •](https://files.speakerdeck.com/presentations/501f6c49c99a4379b5fe89314715b695/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}