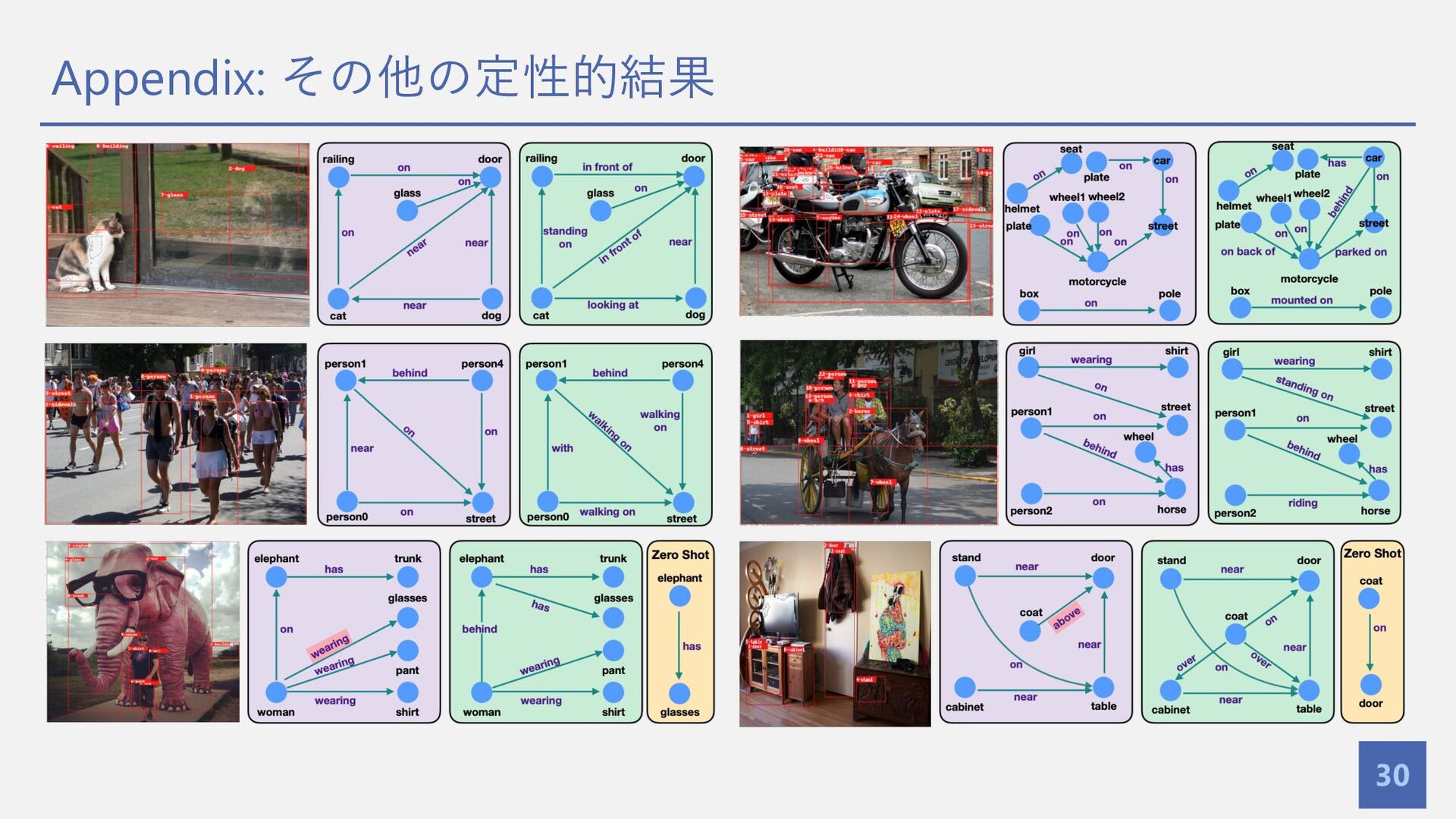
Behjat Siddiquie4, Chris Broaddus4, Jayan Eledath4, Gerard Medioni4, Leonid Sigal1,2,3 (1University of British Columbia, 2Vector Institute for AI , 3Canada CIFAR AI Chair, 4Amazon) 慶應義塾⼤学 杉浦孔明研究室 B4 和⽥唯我 Mohammed Suhail et al., “Energy-based learning for scene graph generation”, in CVPR(2021) CVPR 2021
{kind=link}
{kind=link}
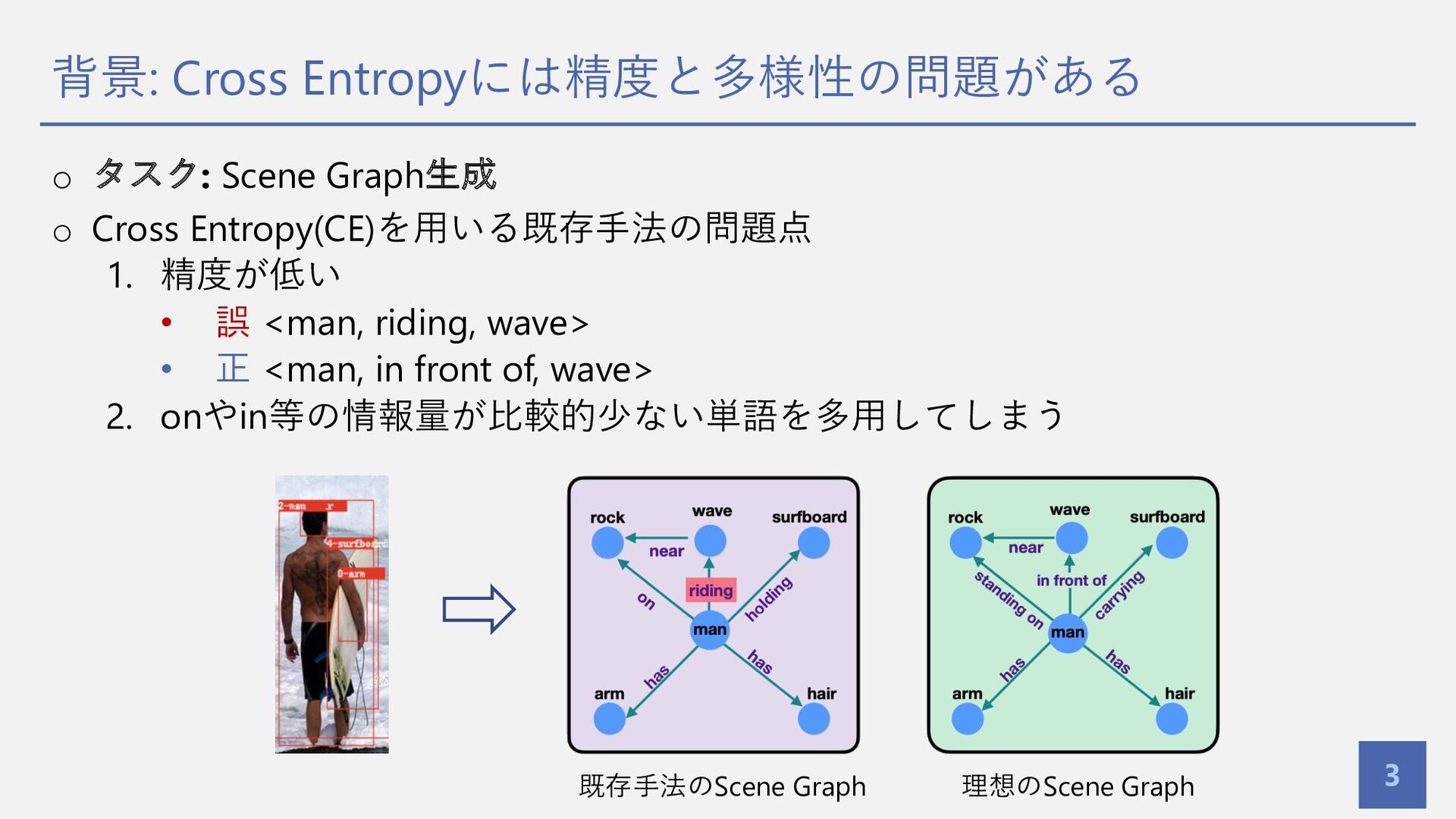{kind=link}
{kind=link}
{kind=link}
{kind=link}
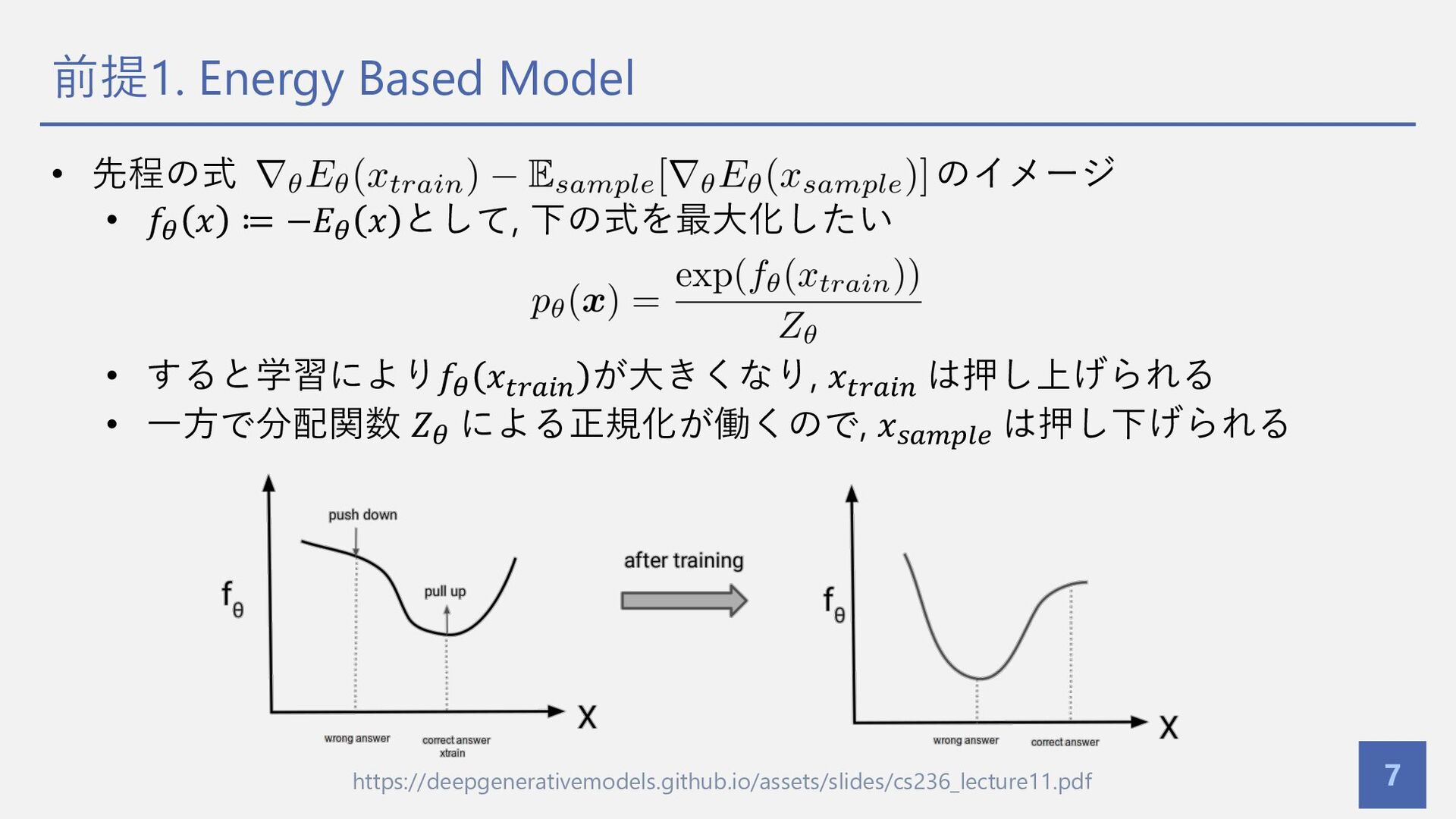{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
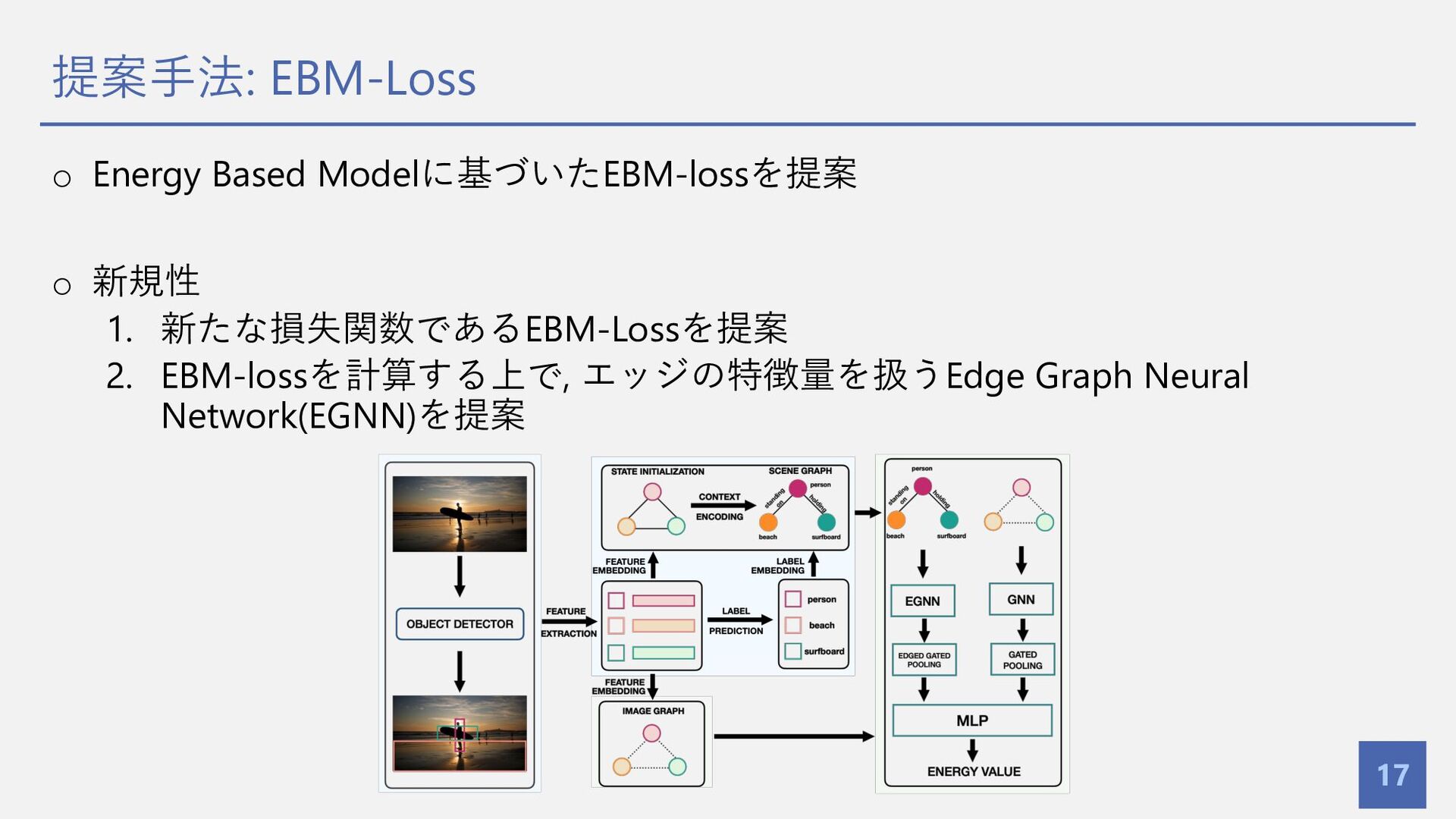{kind=link}
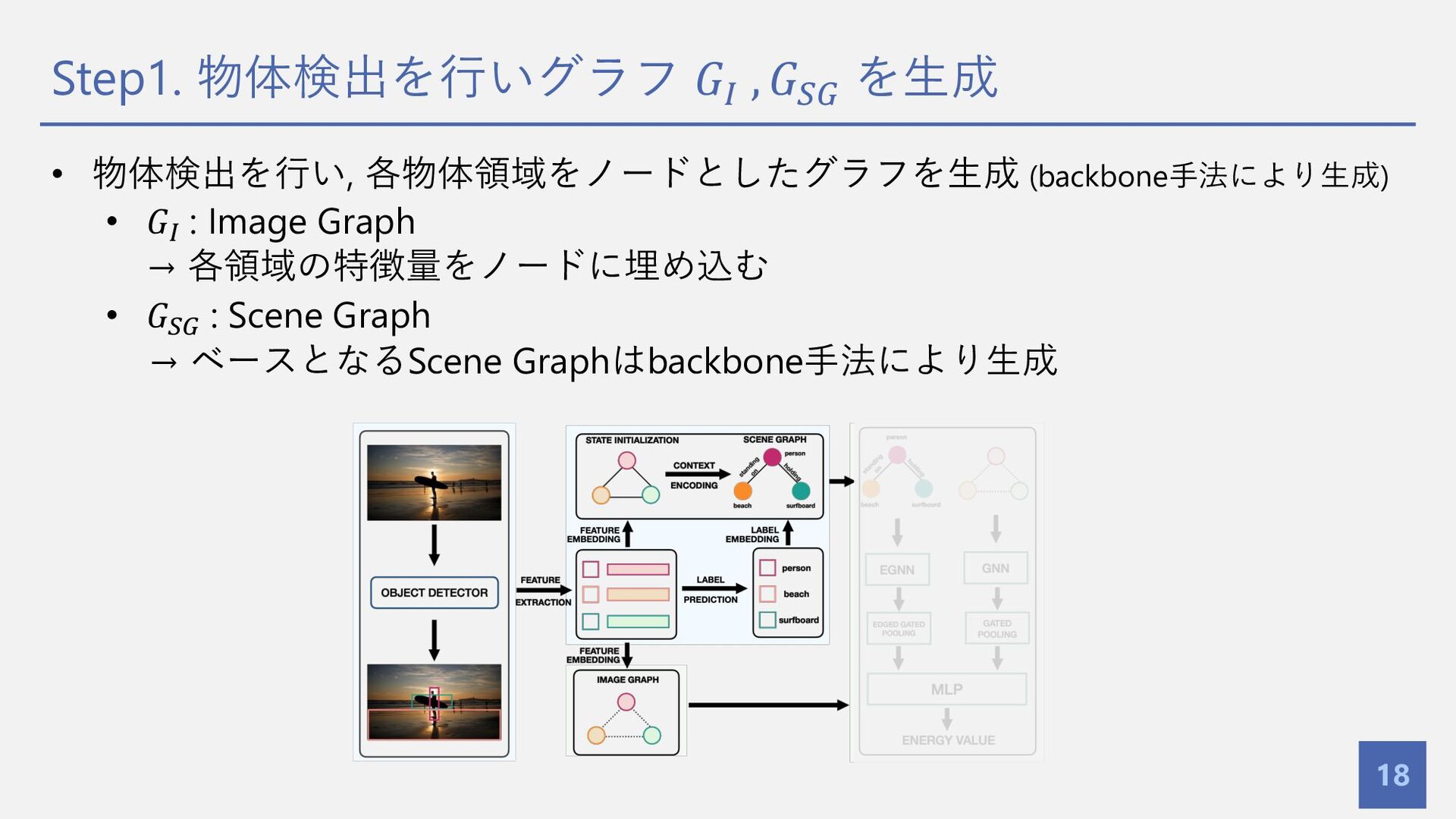{kind=link}
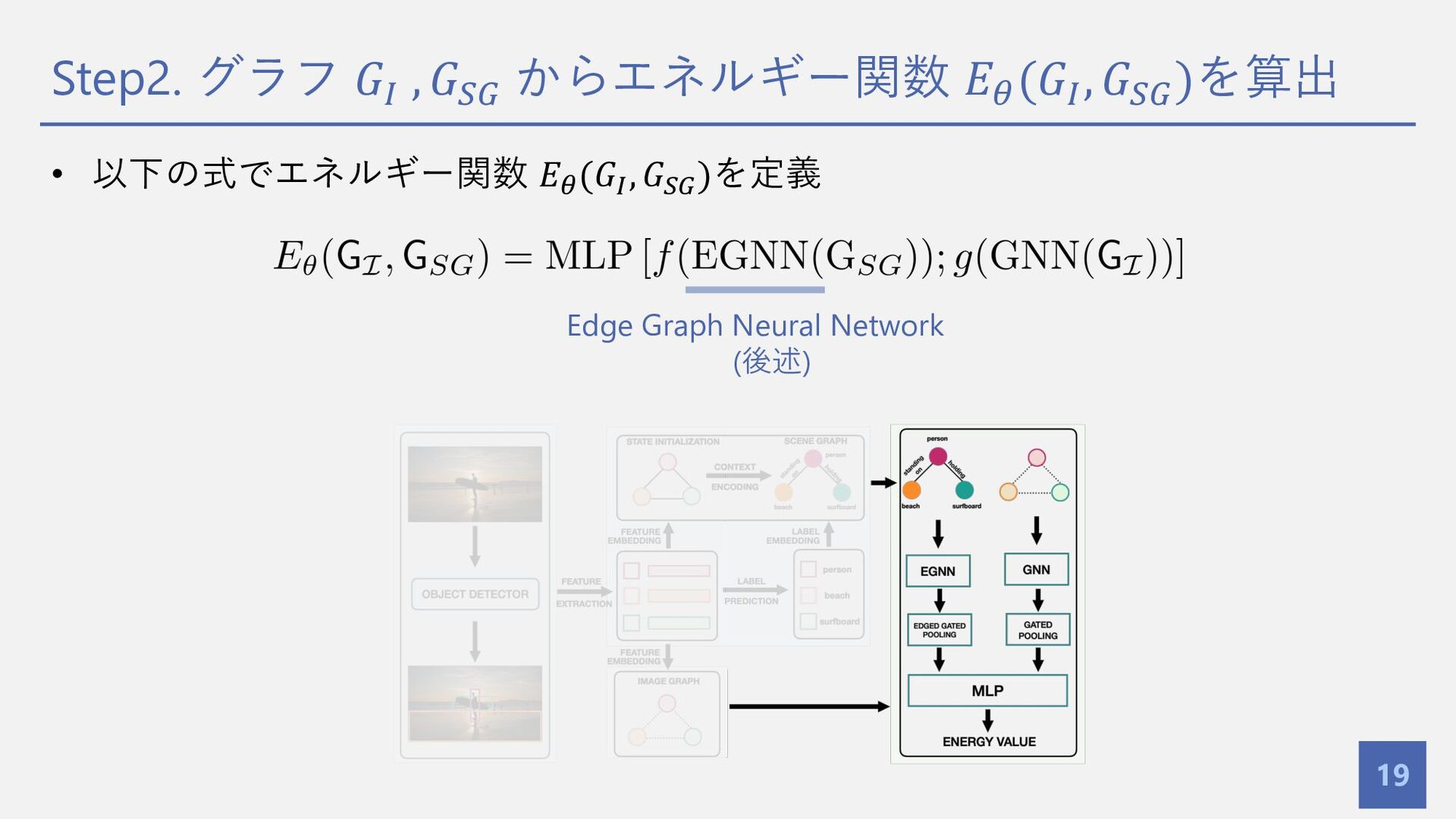{kind=link}
{kind=link}
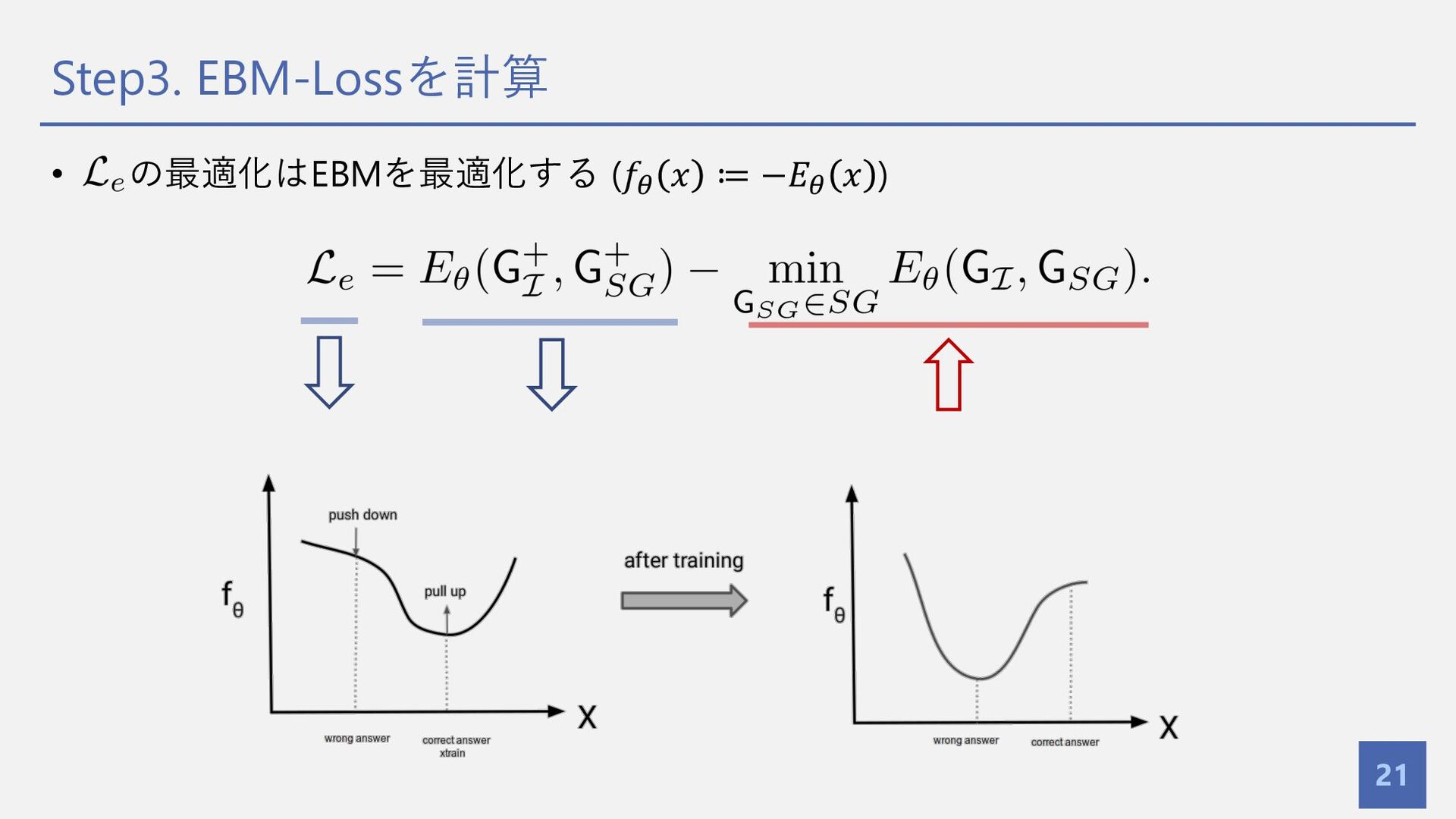{kind=link}
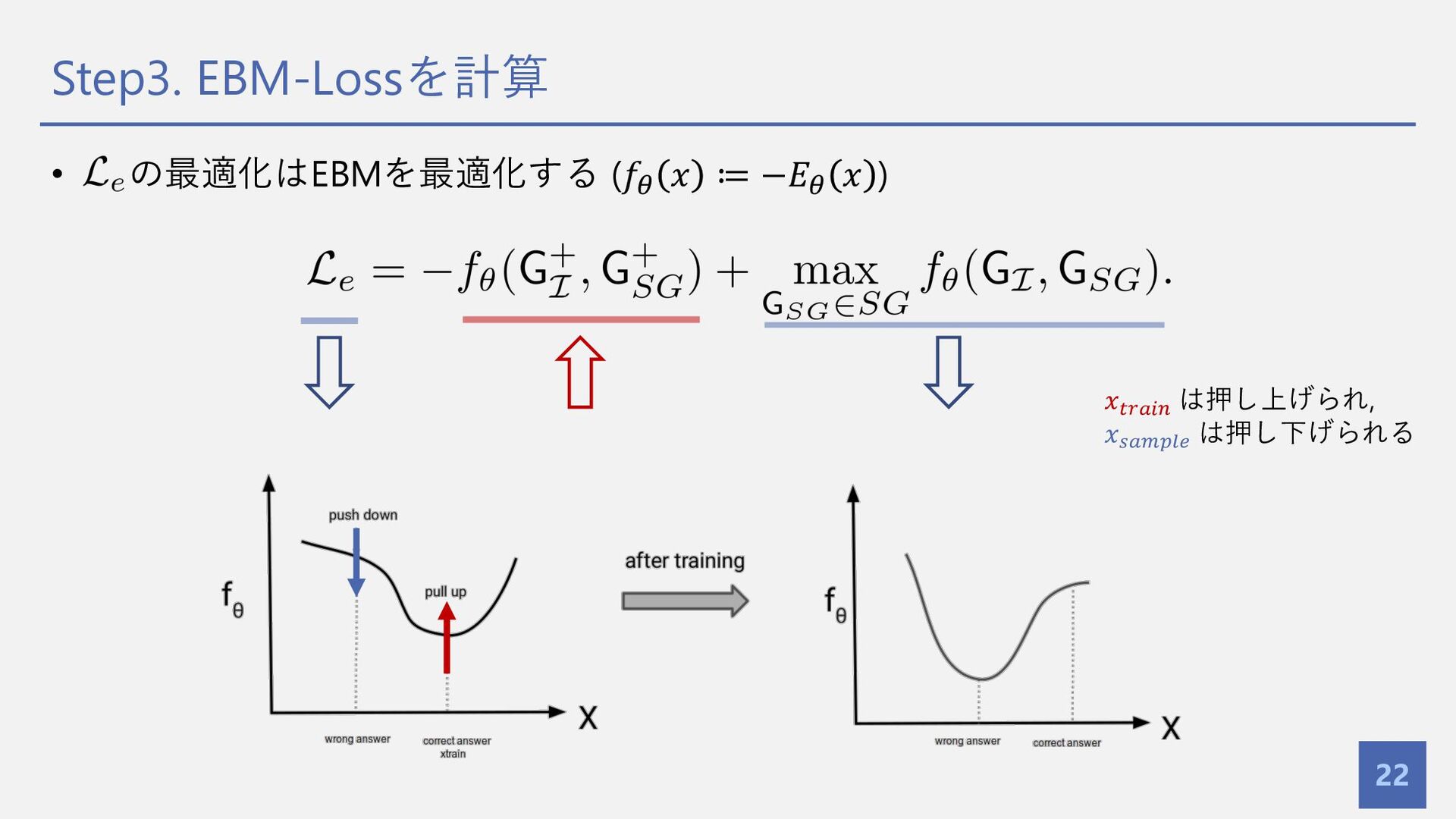{kind=link}
{kind=link}
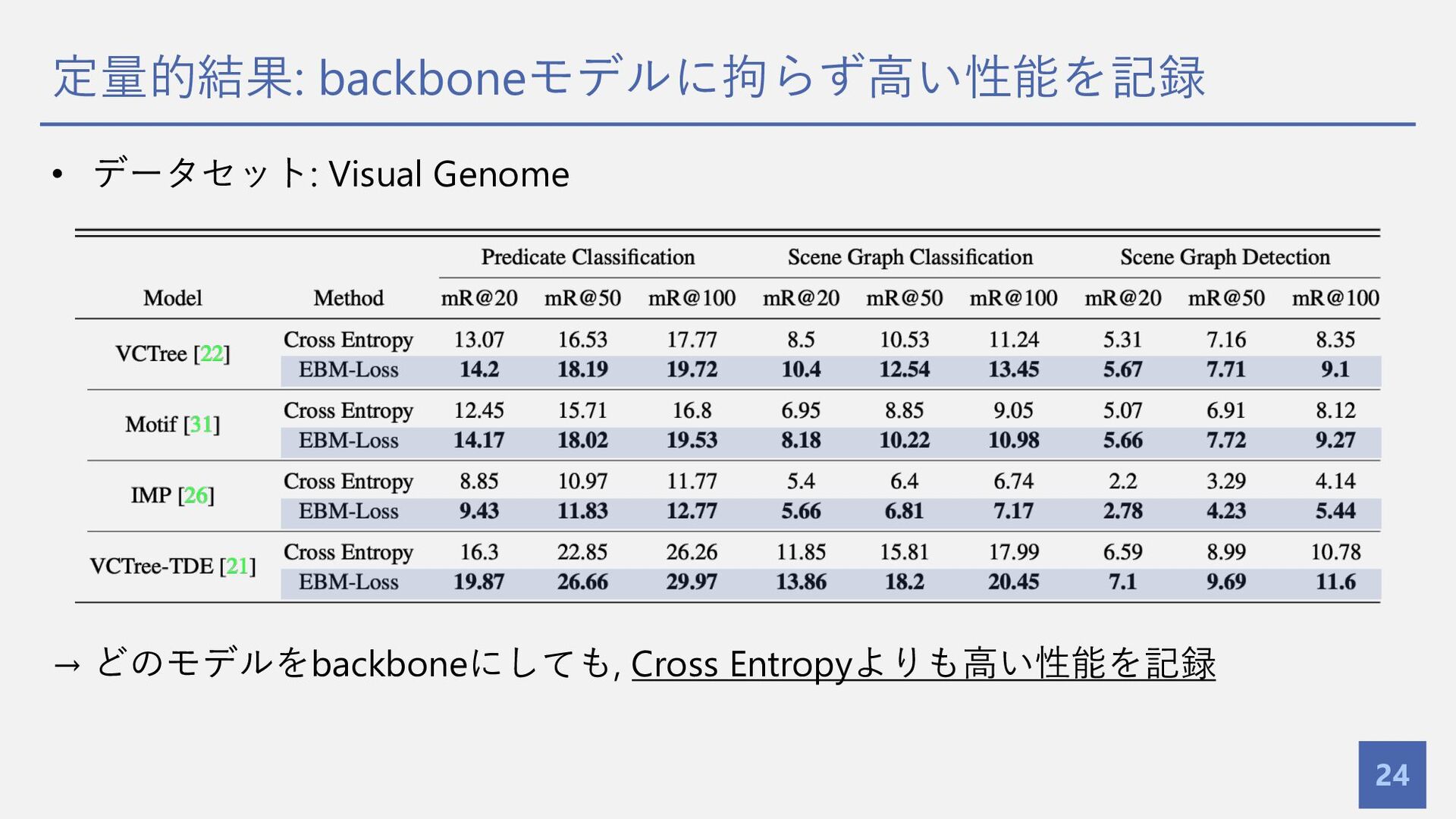{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}