Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal Club]Interfacing Foundation Models’ Em...
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
January 12, 2024
Technology
240
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal Club]Interfacing Foundation Models’ Embeddings
Semantic Machine Intelligence Lab., Keio Univ.
PRO
January 12, 2024
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
81
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
98
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
【公開用】AI_Dev_Ex2026_AI_登壇資料
matsuritechnologies
PRO
1
470
データエンジニアリングとドメイン駆動設計
masuda220
PRO
14
2.5k
Type-safe IaC for Dart
coborinai
0
180
AICoEでAIネイティブ組織への進化
yukiogawa
0
210
AI時代のPlaywright活用(システムテストを自動化する ー 実行エンジンにPla ywrightを選んだ理由)
ynisqa1988
2
930
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
仕様駆動開発、導入半年。「本当に速くなってるの?」にデータで答える / AICon2026_hirakawa
rakus_dev
0
320
AIツールを導入しても生産性はあがらない? カオナビが直面した 3つの壁と乗り越え方。/ Overcoming 3 Barriers to AI-Driven Productivity at kaonavi
kaonavi
0
160
2年前に削除したPHPクラスが、 ある日突然決済をエラーにした
ykagano
1
750
AI時代の開発生産性を捉え直す — 経営と現場をつなぐ「開発組織のオブザーバビリティ」— / AI Dev Ex Conference 2026
tkyowa
1
1.3k
reFACToring
moznion
0
170
GoでCコンパイラを作った話
repunit
0
150
Featured
See All Featured
Evolving SEO for Evolving Search Engines
ryanjones
0
240
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
640
GraphQLとの向き合い方2022年版
quramy
50
15k
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
3
360
Measuring & Analyzing Core Web Vitals
bluesmoon
9
900
Test your architecture with Archunit
thirion
1
2.3k
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
Optimizing for Happiness
mojombo
378
71k
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
150
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
200
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
Transcript
Xueyan Zou1, Linjie Li2, Jianfeng Wang2, Jianwei Yang2, Mingyu Ding3,
Zhengyuan Yang2, Feng Li4, Hao Zhang4, Shilong Liu5, Arul Aravinthan1, Yong Lee1, Lijuan Wang2, 1UW-Madison, 2Microsoft, 3UC Berkeley, 4HKUST, 5Tsinghua University Interfacing Foundation Models’ Embeddings Zou, Xueyan, et al. "Interfacing Foundation Models' Embeddings." arXiv preprint arXiv:2312.07532, 2023. 慶應義塾大学 飯岡雄偉
概要:視覚言語間の相互入力/出力を可能に ▪ X-Decoder [Zou+, CVPR23],SEEM [Zou+, NeurIPS23]の後続モデル ▪ 背景 ◦
基盤モデルの訓練はコストが大きい & モダリティやタスクの制限がある ▪ 提案手法:FIND ◦ Configを書き換えるだけで様々なモダリティやタスクを統一的に扱うモデル ➢ 柔軟性があり,多様な基盤モデルへ応用可能 ▪ 結論 ◦ 新たなベンチマークFIND-Bench,SegmentationおよびImage Retrievalにおい て、既存手法と同等以上の性能 2
背景:大規模基盤モデルの制限 ▪ 出力のモダリティが単一なものが多く,制限がある 3 BLIP-2 [Li+, ICML23] VQA → Text
DALL·E 3 [Betker+, 2023] Image generation → Image
関連研究:基盤モデルをマルチモーダルに拡張 ▪ Prompt engineering:SoM [Yang+, 2023] ◦ ☺入出力のマルチモーダル化 ◦ 基盤モデルが扱うタスクそのものを拡張できて
いない 4 ▪ Adaptive tuning ◦ VisionLLM [Wang+, 2023] ◦ ☺出力形式の拡張 ◦ 基盤モデルそのものの拡張
関連研究:X-Decoder, SEEMにおける基盤モデル ▪ X-Decoder [Zou+, CVPR23] ◦ マルチモーダル/タスクの基盤モデル ◦ 統一されたdecoderで複数タスクを扱う
◦ 入力は画像と言語のみ 5 ▪ SEEM [Zou+, NeurIPS23] ◦ 言語での接地にとどまらず,画像内物体 を指定して入力できる ➢ 入力の柔軟性を向上 ◦ Segmentationタスクのみを扱う
問題設定:モダリティにとらわれない入出力の実現 6 ▪ 視覚と言語が混ざった入力においても,これまでと同様にimage/text retrieval やsegmentationを行う
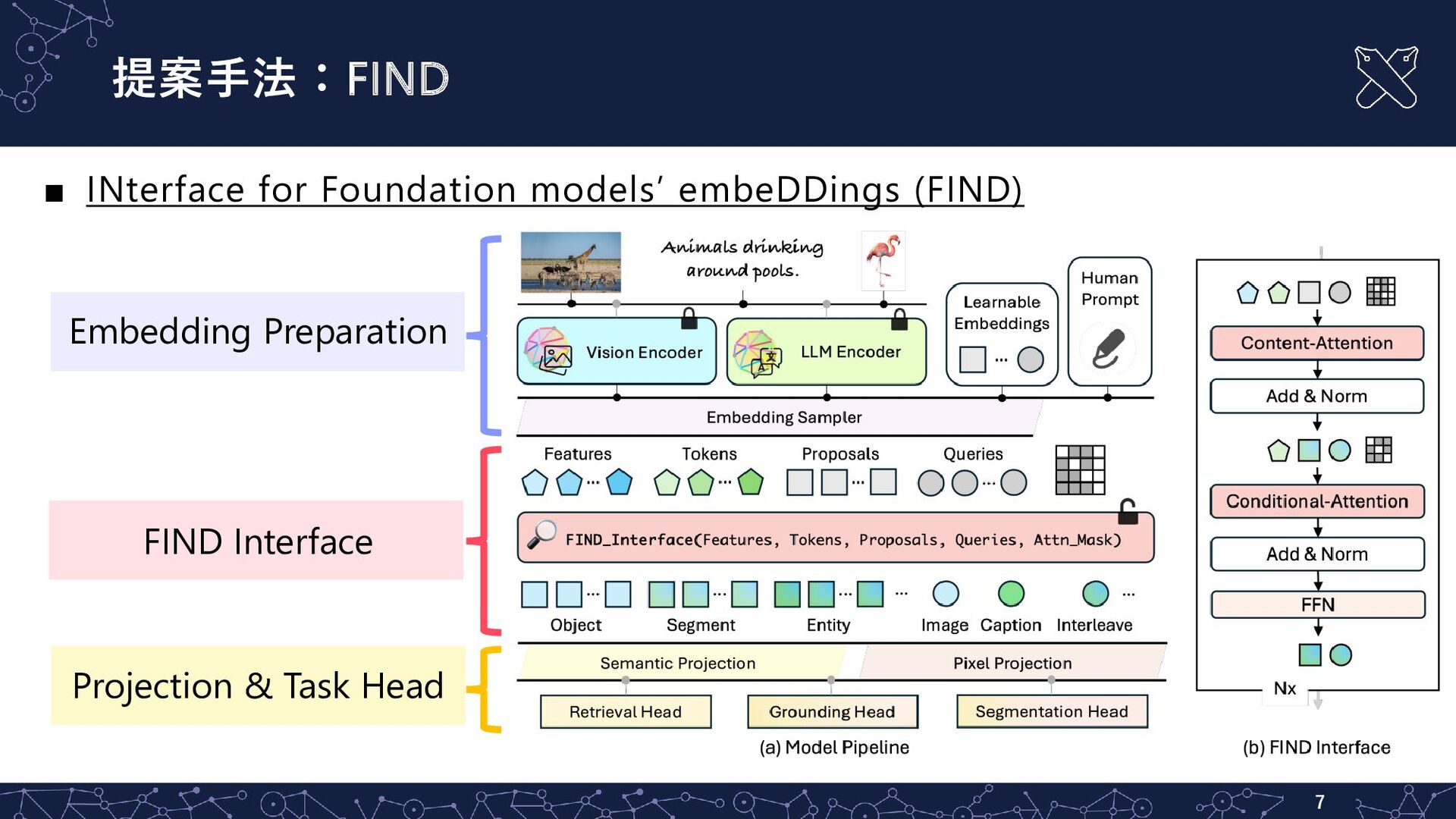
提案手法:FIND ▪ INterface for Foundation models’ embeDDings (FIND) 7 Embedding
Preparation FIND Interface Projection & Task Head
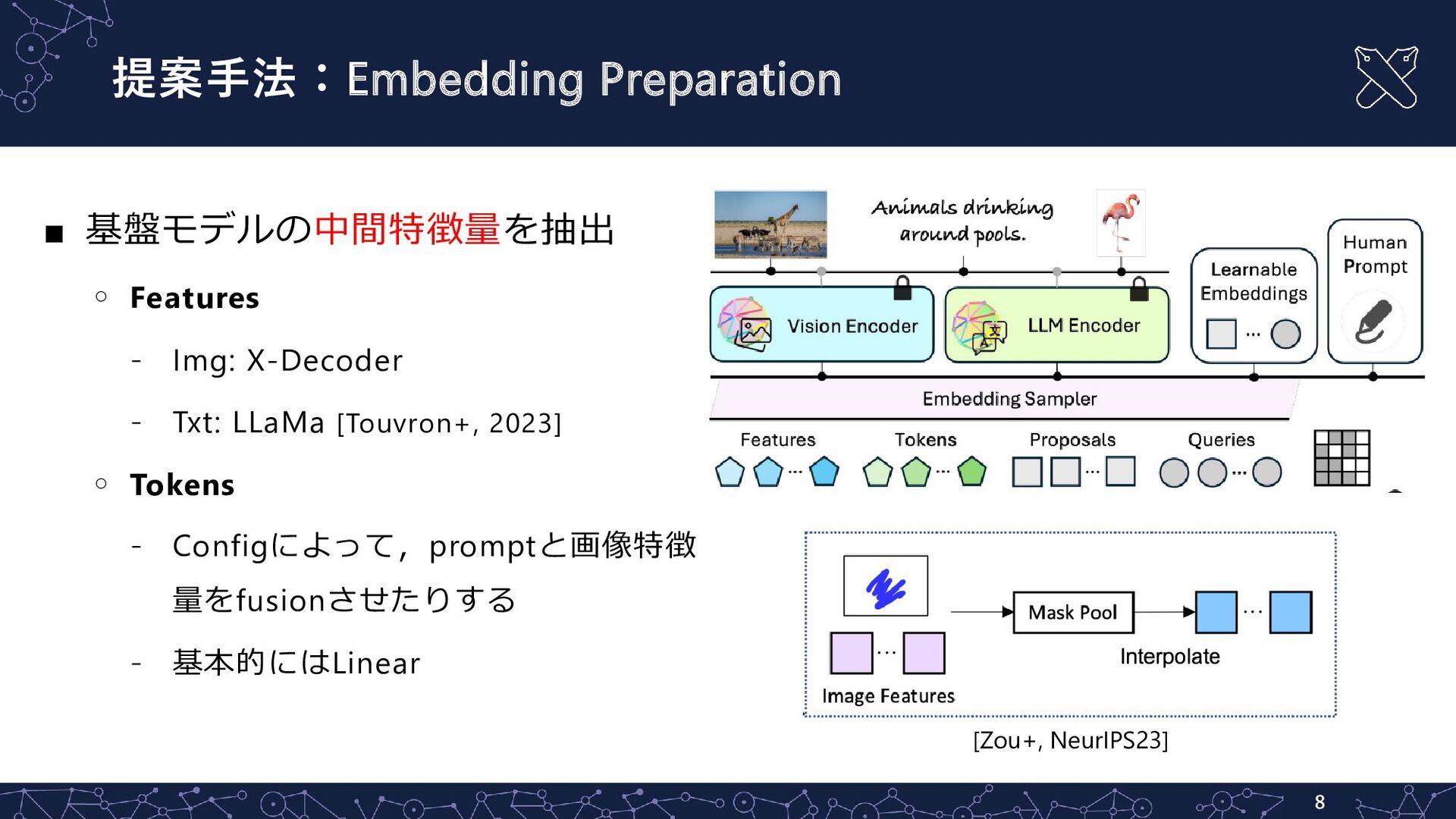
提案手法:Embedding Preparation ▪ 基盤モデルの中間特徴量を抽出 ◦ Features - Img: X-Decoder -
Txt: LLaMa [Touvron+, 2023] ◦ Tokens - Configによって,promptと画像特徴 量をfusionさせたりする - 基本的にはLinear 8 [Zou+, NeurIPS23]
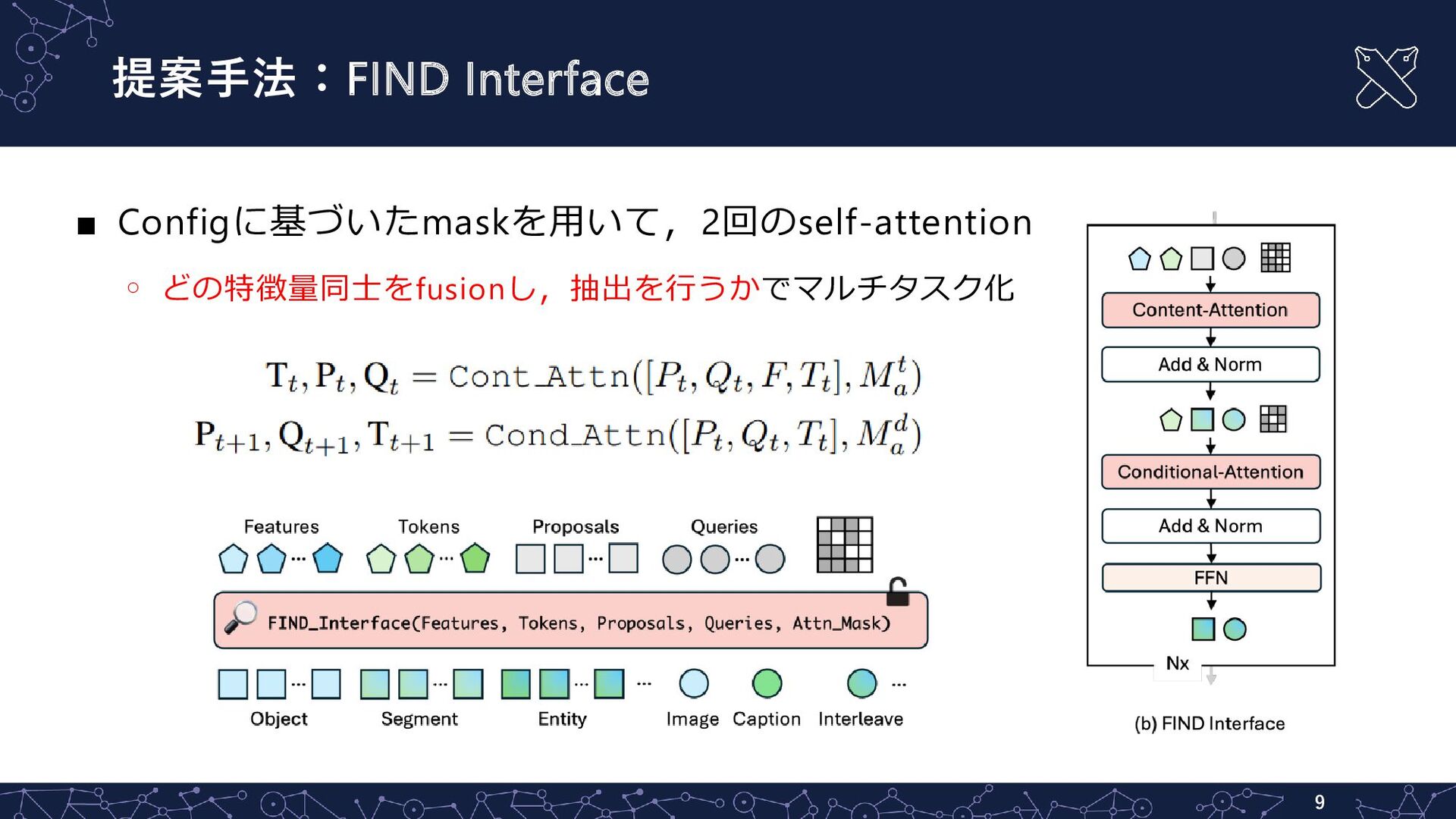
提案手法:FIND Interface ▪ Configに基づいたmaskを用いて,2回のself-attention ◦ どの特徴量同士をfusionし,抽出を行うかでマルチタスク化 9
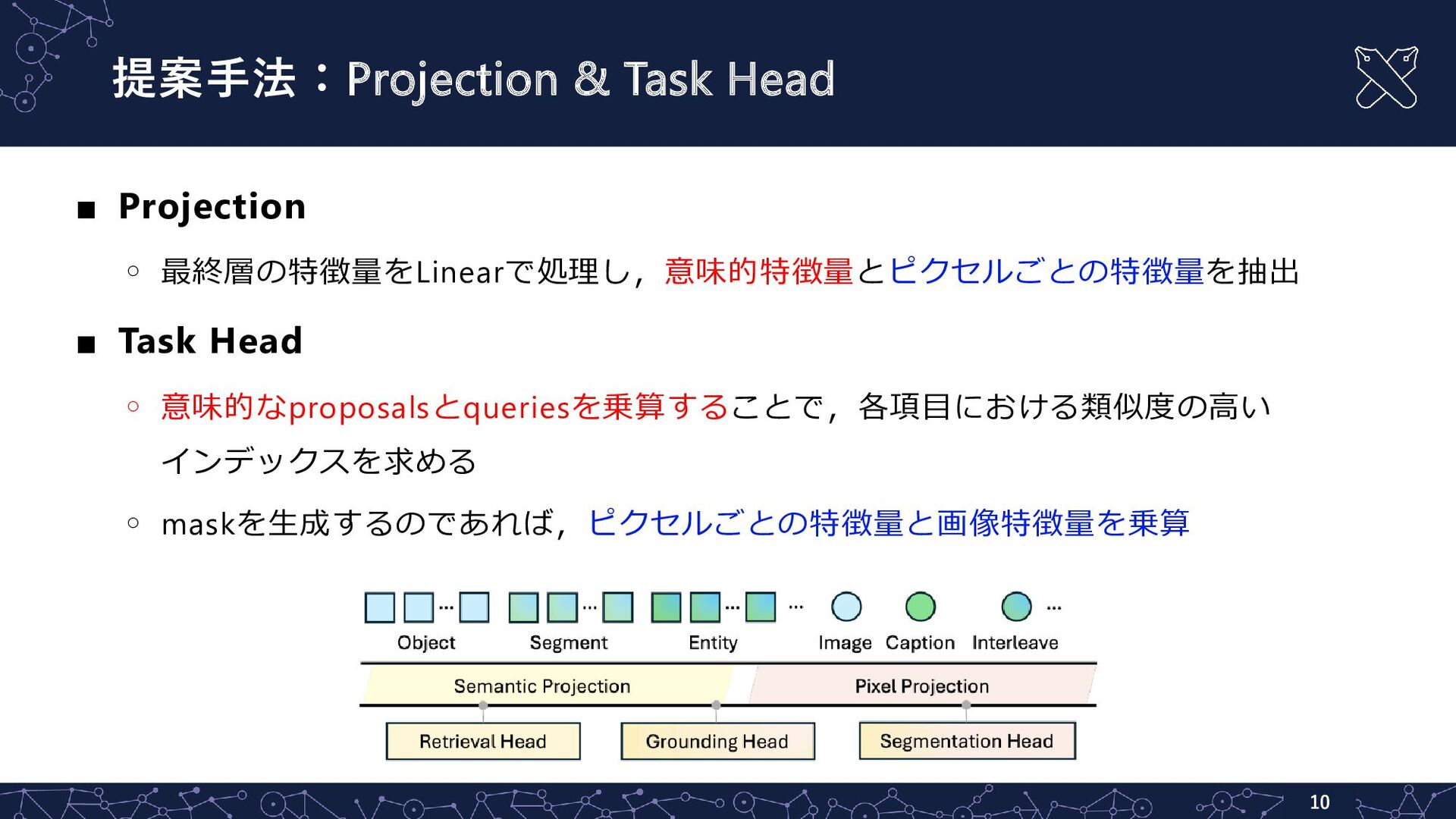
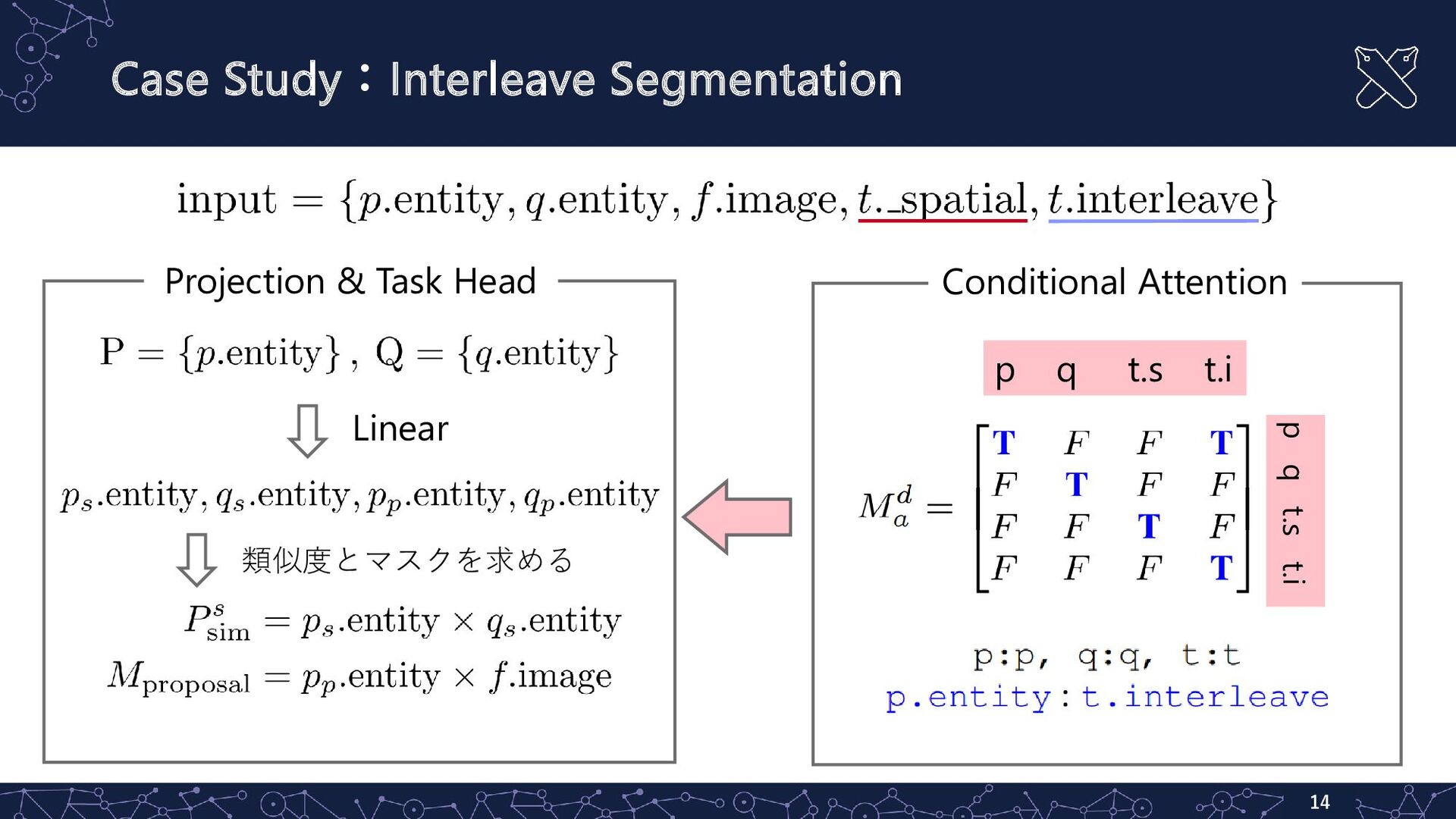
提案手法:Projection & Task Head ▪ Projection ◦ 最終層の特徴量をLinearで処理し,意味的特徴量とピクセルごとの特徴量を抽出 ▪ Task
Head ◦ 意味的なproposalsとqueriesを乗算することで,各項目における類似度の高い インデックスを求める ◦ maskを生成するのであれば,ピクセルごとの特徴量と画像特徴量を乗算 10
Case Study:Interleave Segmentation 11 Promptに対応する画像特徴量 言語特徴量の恒等写像
Case Study:Interleave Segmentation 12 p q f t.s t.i p
q f t.s t.i Content Attention
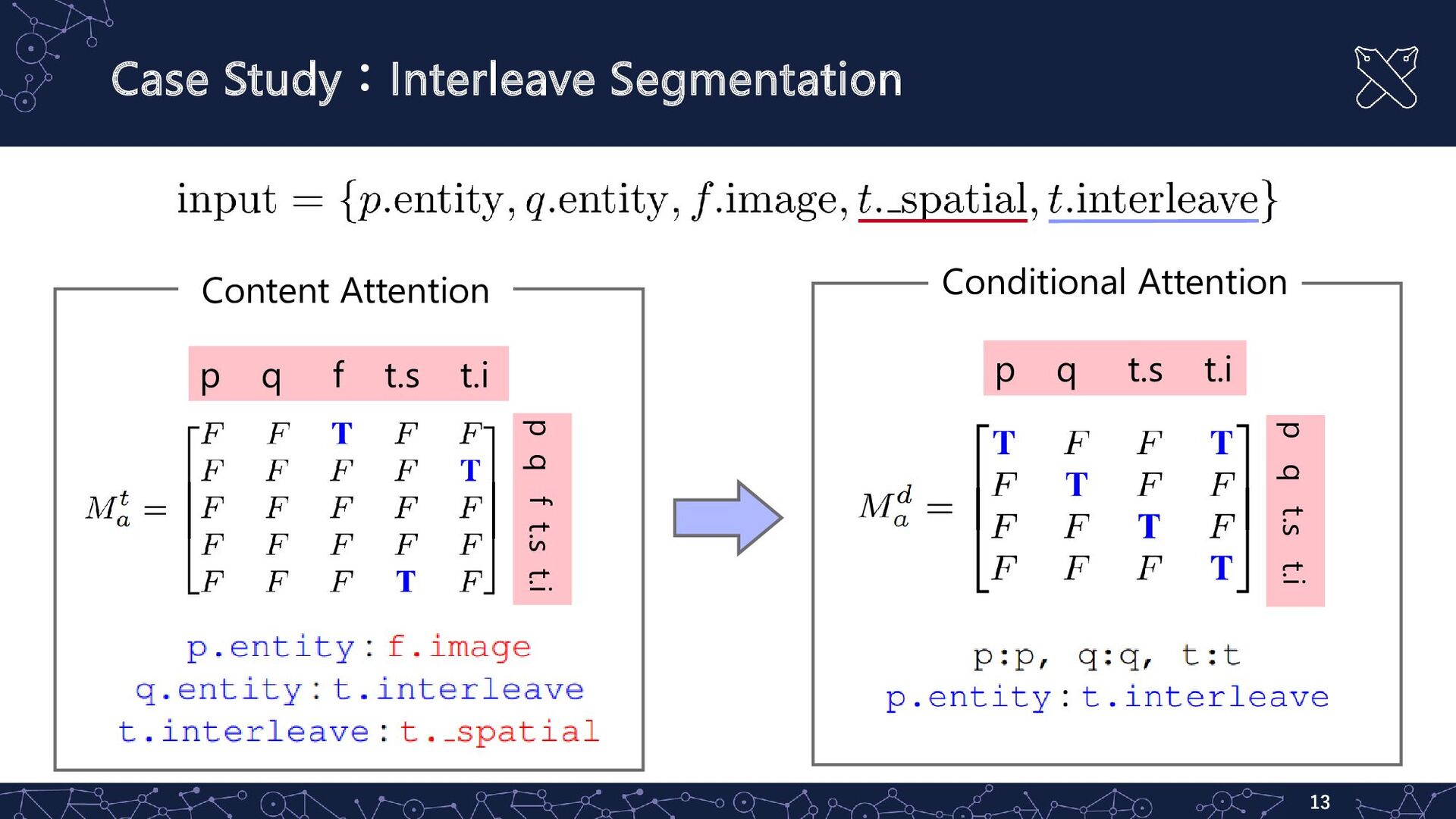
Case Study:Interleave Segmentation 13 p q f t.s t.i p
q f t.s t.i Content Attention p q t.s t.i p q t.s t.i Conditional Attention
Case Study:Interleave Segmentation 14 p q t.s t.i p q
t.s t.i Linear 類似度とマスクを求める Projection & Task Head Conditional Attention
実験設定:新たなベンチマークFIND-Bench ▪ データセット ◦ COCO系統のデータセットをGPT-4やLLaVa [Liu+, NeurIPS23]によるcaptionで拡張 15
実験設定:新たなベンチマークFIND-Bench ▪ 対象タスク ◦ Generic segmentation = panoptic segmentation ◦
Grounded segmentation = referring expression segmentation ◦ Interactive segmentation - 画像中のなかのユーザがプロンプト指定した物体についてセグメンテーション ◦ Image-Text retrieval ◦ Interleave segmentation - 画像と言語,プロンプトの混ざった入力によるセグメンテーション ◦ Interleave retrieval : 言語+画像 言語/画像の検索 16
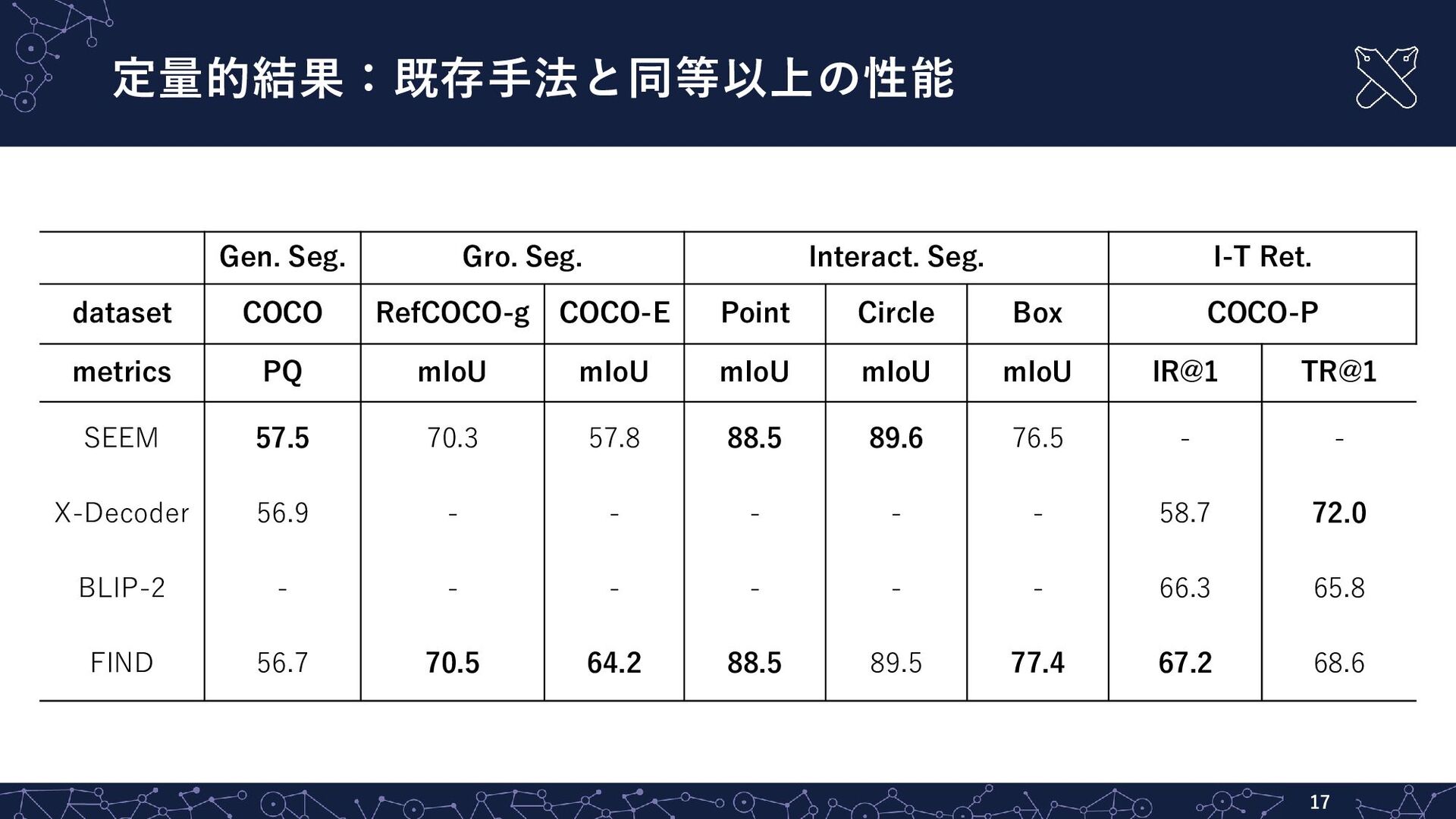
定量的結果:既存手法と同等以上の性能 17 Gen. Seg. Gro. Seg. Interact. Seg. I-T Ret.
dataset COCO RefCOCO-g COCO-E Point Circle Box COCO-P metrics PQ mIoU mIoU mIoU mIoU mIoU IR@1 TR@1 SEEM 57.5 70.3 57.8 88.5 89.6 76.5 - - X-Decoder 56.9 - - - - - 58.7 72.0 BLIP-2 - - - - - - 66.3 65.8 FIND 56.7 70.5 64.2 88.5 89.5 77.4 67.2 68.6
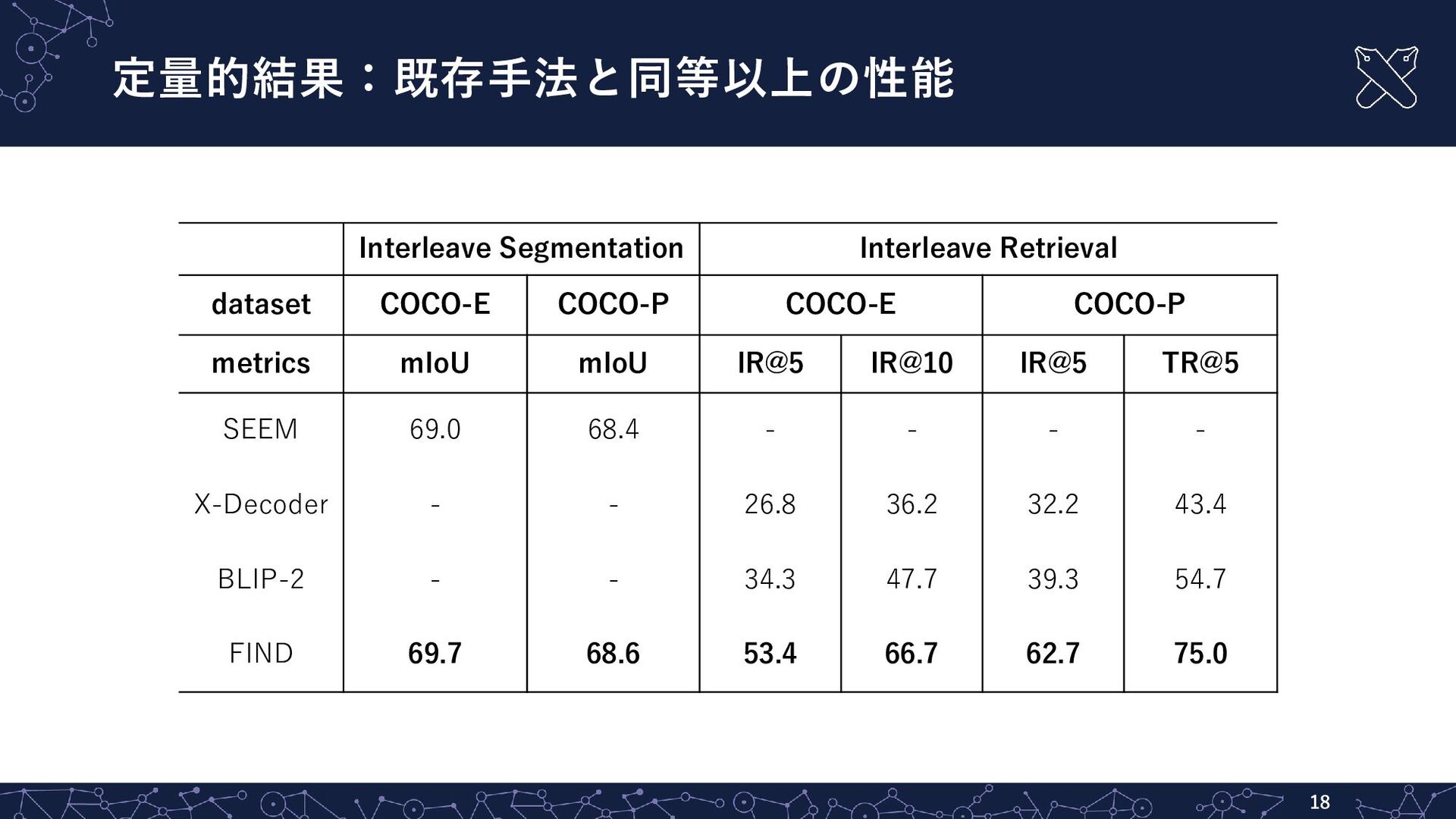
定量的結果:既存手法と同等以上の性能 18 Interleave Segmentation Interleave Retrieval dataset COCO-E COCO-P COCO-E
COCO-P metrics mIoU mIoU IR@5 IR@10 IR@5 TR@5 SEEM 69.0 68.4 - - - - X-Decoder - - 26.8 36.2 32.2 43.4 BLIP-2 - - 34.3 47.7 39.3 54.7 FIND 69.7 68.6 53.4 66.7 62.7 75.0
定性的結果:言語と画像の混ざった入力にも対応 ▪ aa 19
実際にやってみた ▪ Talk2Car [Deruyttere+, EMNLP19] 20
まとめ:FIND ▪ X-Decoder [Zou+, CVPR23],SEEM [Zou+, NeurIPS23]の後続モデル ▪ 背景 ◦
基盤モデルの訓練はコストが大きい & モダリティやタスクの制限がある ▪ 提案手法:FIND ◦ Configを書き換えるだけで様々なモダリティやタスクを統一的に扱うモデル ➢ 柔軟性があり,多様な基盤モデルへ応用可能 ▪ 結論 ◦ 新たなベンチマークFIND-Bench,SegmentationおよびImage Retrievalにおいて、既存 手法と同等以上の性能 21
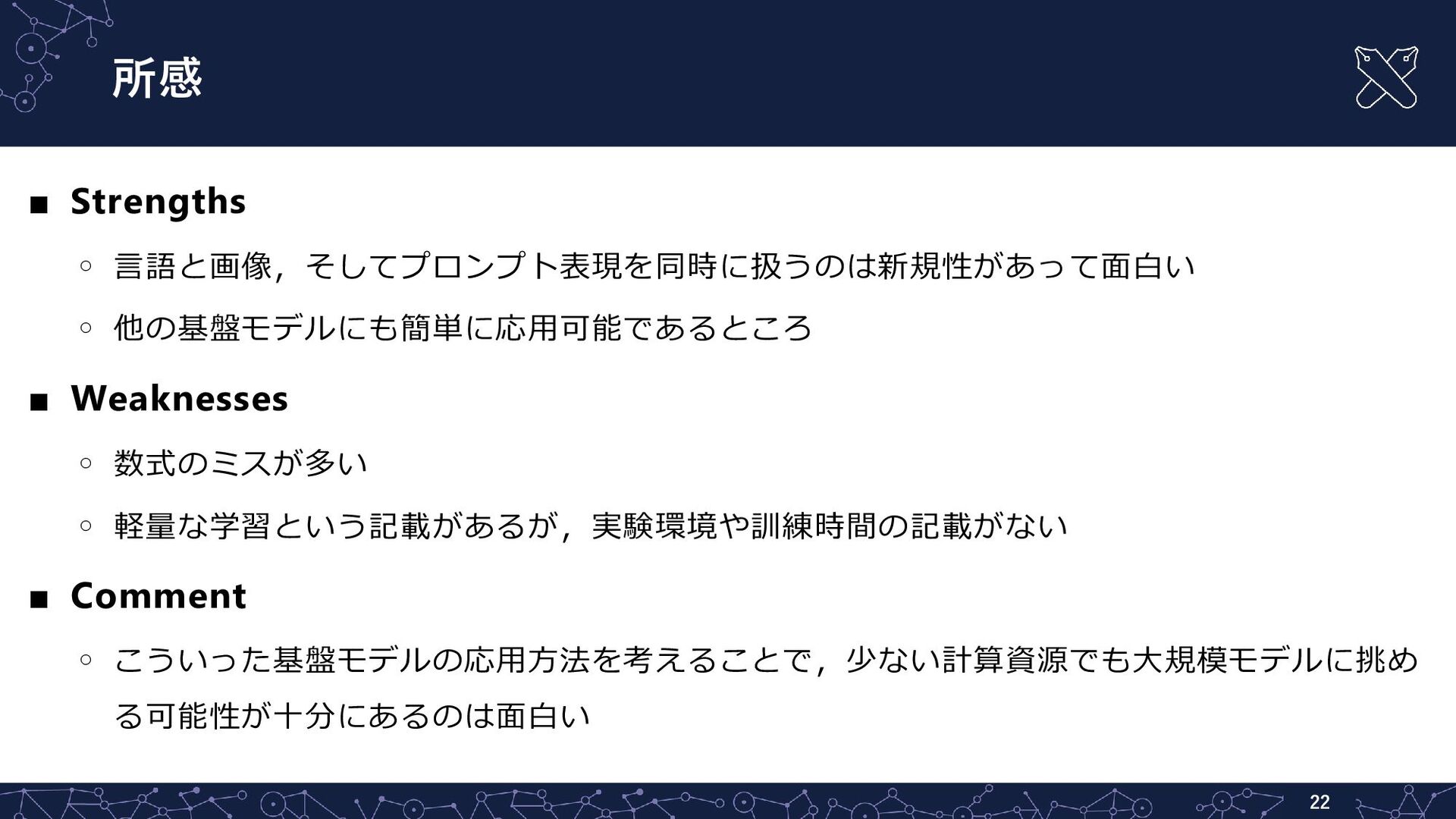
所感 ▪ Strengths ◦ 言語と画像,そしてプロンプト表現を同時に扱うのは新規性があって面白い ◦ 他の基盤モデルにも簡単に応用可能であるところ ▪ Weaknesses ◦
数式のミスが多い ◦ 軽量な学習という記載があるが,実験環境や訓練時間の記載がない ▪ Comment ◦ こういった基盤モデルの応用方法を考えることで,少ない計算資源でも大規模モデルに挑め る可能性が十分にあるのは面白い 22
Appendix:データセット構築の疑似コード 23
{kind=link}
![概要:視覚言語間の相互入力/出力を可能に ▪ X-Decoder [Zou+, CVPR23],SEEM [Zou+, NeurIPS23]の後続モデル ▪ 背景 ◦](https://files.speakerdeck.com/presentations/98f1597ce6664f77b33a14e7bd58bf45/slide_1.jpg){kind=link}
![背景:大規模基盤モデルの制限 ▪ 出力のモダリティが単一なものが多く,制限がある 3 BLIP-2 [Li+, ICML23] VQA → Text](https://files.speakerdeck.com/presentations/98f1597ce6664f77b33a14e7bd58bf45/slide_2.jpg){kind=link}
![関連研究:基盤モデルをマルチモーダルに拡張 ▪ Prompt engineering:SoM [Yang+, 2023] ◦ ☺入出力のマルチモーダル化 ◦ 基盤モデルが扱うタスクそのものを拡張できて](https://files.speakerdeck.com/presentations/98f1597ce6664f77b33a14e7bd58bf45/slide_3.jpg){kind=link}
![関連研究:X-Decoder, SEEMにおける基盤モデル ▪ X-Decoder [Zou+, CVPR23] ◦ マルチモーダル/タスクの基盤モデル ◦ 統一されたdecoderで複数タスクを扱う](https://files.speakerdeck.com/presentations/98f1597ce6664f77b33a14e7bd58bf45/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![実験設定:新たなベンチマークFIND-Bench ▪ データセット ◦ COCO系統のデータセットをGPT-4やLLaVa [Liu+, NeurIPS23]によるcaptionで拡張 15](https://files.speakerdeck.com/presentations/98f1597ce6664f77b33a14e7bd58bf45/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![実際にやってみた ▪ Talk2Car [Deruyttere+, EMNLP19] 20](https://files.speakerdeck.com/presentations/98f1597ce6664f77b33a14e7bd58bf45/slide_19.jpg){kind=link}
![まとめ:FIND ▪ X-Decoder [Zou+, CVPR23],SEEM [Zou+, NeurIPS23]の後続モデル ▪ 背景 ◦](https://files.speakerdeck.com/presentations/98f1597ce6664f77b33a14e7bd58bf45/slide_20.jpg){kind=link}
{kind=link}
{kind=link}