Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal club] Surrogate Gap Minimization Impro...
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Semantic Machine Intelligence Lab., Keio Univ.
PRO
August 01, 2022
Technology
2.8k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal club] Surrogate Gap Minimization Improves Sharpness-Aware Training
慶應義塾⼤学 杉浦孔明研究室 B4 和田唯我 / Yuiga Wada
Semantic Machine Intelligence Lab., Keio Univ.
PRO
August 01, 2022
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
76
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
85
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
96
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
個人開発で育てる「大規模設計の苗床」 - AI時代の1人開発から始める業務への知識接続 / The Seedbed for Large-Scale Design - From AI-Era Solo Projects to Professional Knowledge
bitkey
PRO
1
300
OPENLOGI Company Profile for engineer
hr01
1
74k
しくみを学んで使いこなそう GitHub Copilot app
torumakabe
2
300
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
4
2.4k
マルチアカウント環境でSecurity Hubの運用、その後どうなった? / SRE NEXT 2026 miniLT会
genda
0
110
タスクの複雑さでモデルを選ぶ ── Thompson Samplingで動かす“トークン/コスト最適化
satohy0323
0
600
AI時代のYAGNI:「爆速で無駄になった機能」からの学び / 20260720 Naoki Takahashi
shift_evolve
PRO
3
450
『モデル + ハーネス』で読み解く AIエージェント入門
oracle4engineer
PRO
1
110
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
430
Genie Ontologyは銀の弾丸かを考える / Is Genie Ontology a Silver Bullet?
nttcom
0
420
人とエージェントが高め合う協業設計
kintotechdev
0
450
「守りたい体験」を渡すだけで E2E を生成させられるようになった話
hinac0
2
910
Featured
See All Featured
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.3k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.3k
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Facilitating Awesome Meetings
lara
57
7k
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
Building Flexible Design Systems
yeseniaperezcruz
330
40k
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
Statistics for Hackers
jakevdp
799
230k
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
Transcript
Surrogate Gap Minimization Improves Sharpness-Aware Training Juntang Zhuang1, Boqing Gong2,
Liangzhe Yuan2, Yin Cui2, Hartwig Adam2, Nicha C Dvornek1, sekhar tatikonda1, James s Duncan1, Ting Liu2 (1Yale University, 2Google Research) 慶應義塾⼤学 杉浦孔明研究室 和⽥唯我 Juntang Zhuang , et al., “Surrogate gap minimization improves sharpness-aware training”, in ICLR(2022) ICLR 2022
和田唯我 / Yuiga Wada
概要 2 ü 最適化⼿法GSAM(Gap Guided Sharpness-Aware Minimization)を提案 ü Surrogate gapの導⼊によりSAMを改良
ü Surrogate gapがHessianの最⼤固有値と相関を持つことを理論的に証明 ü 様々なモデル・データセットでSAMを超える性能を達成
既存⼿法: SAM(Sharpness-Aware Minimization) 3 o 最適化⼿法 SAM(Sharpness-Aware Minimization) [Foret+, ICLR21]
• ⽬的関数 𝑓 𝑤 だけでなく, その近傍までを最⼩化 ⇒ フラットな損失点を得ることができると主張
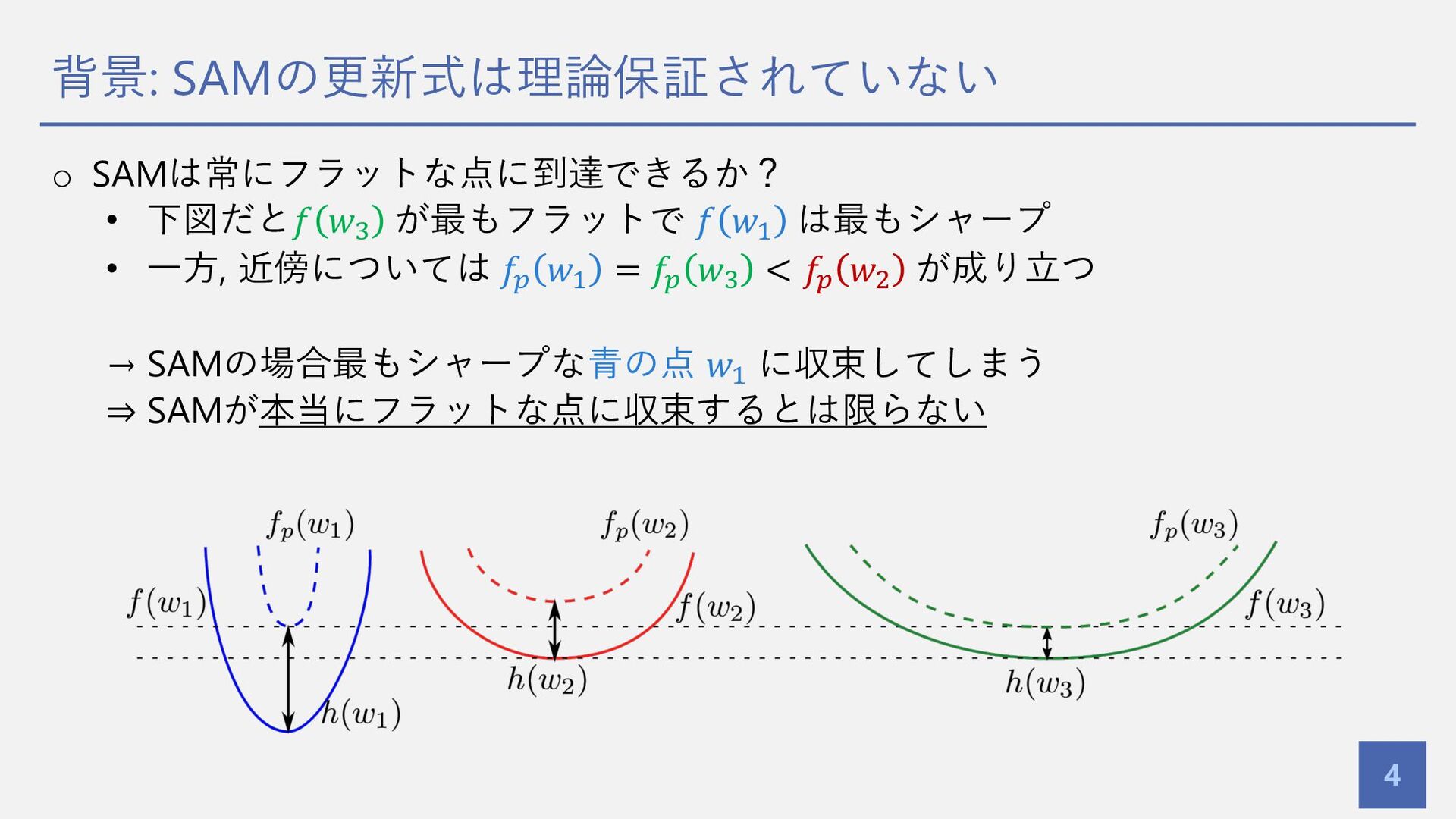
背景: SAMの更新式は理論保証されていない 4 o SAMは常にフラットな点に到達できるか? • 下図だと𝑓 𝑤! が最もフラットで 𝑓
𝑤" は最もシャープ • ⼀⽅, 近傍については 𝑓# 𝑤" = 𝑓# 𝑤! < 𝑓# 𝑤$ が成り⽴つ → SAMの場合最もシャープな⻘の点 𝑤" に収束してしまう ⇒ SAMが本当にフラットな点に収束するとは限らない
提案⼿法: Gap Guided Sharpness-Aware Minimization (GSAM) 5 o Gap Guided
Sharpness-Aware Minimization (GSAM) • Surrogate gapを補助関数としてSAMを改良 o Surrogate gap • 以下の式で定義. すなわち, 近傍と⽬的関数 𝑓 𝑤 の差分(gap) • Surrogate gap ℎ 𝑤 はHessianの最⼤固有値と相関を持ち, 平坦な損失平⾯へと到達可 (次⾴にて証明)
補題1: Surrogate gapは⾮負数を取る 6 o Surrogate gap ℎ 𝑤 を局所解
𝑤 の周りでTaylor展開すると (Dual Norm Problem を解くとこの解が得られる) ⇒
補題2: Surrogate gapはHessianの最⼤固有値と相関を持つ 7 o Surrogate gap ℎ 𝑤 を局所解
𝑤 の周りでTaylor展開すると 局所解において ∇𝑓 ≈ 0なので 第⼆項を最⼤化するとき, 𝑓# はHessian 𝐻 の最⼤固有値 𝜎%&' 𝐻 を⽤いて よって, → 補題1, 2より Surrogate gapの最⼩化は平坦な損失平⾯へと到達可
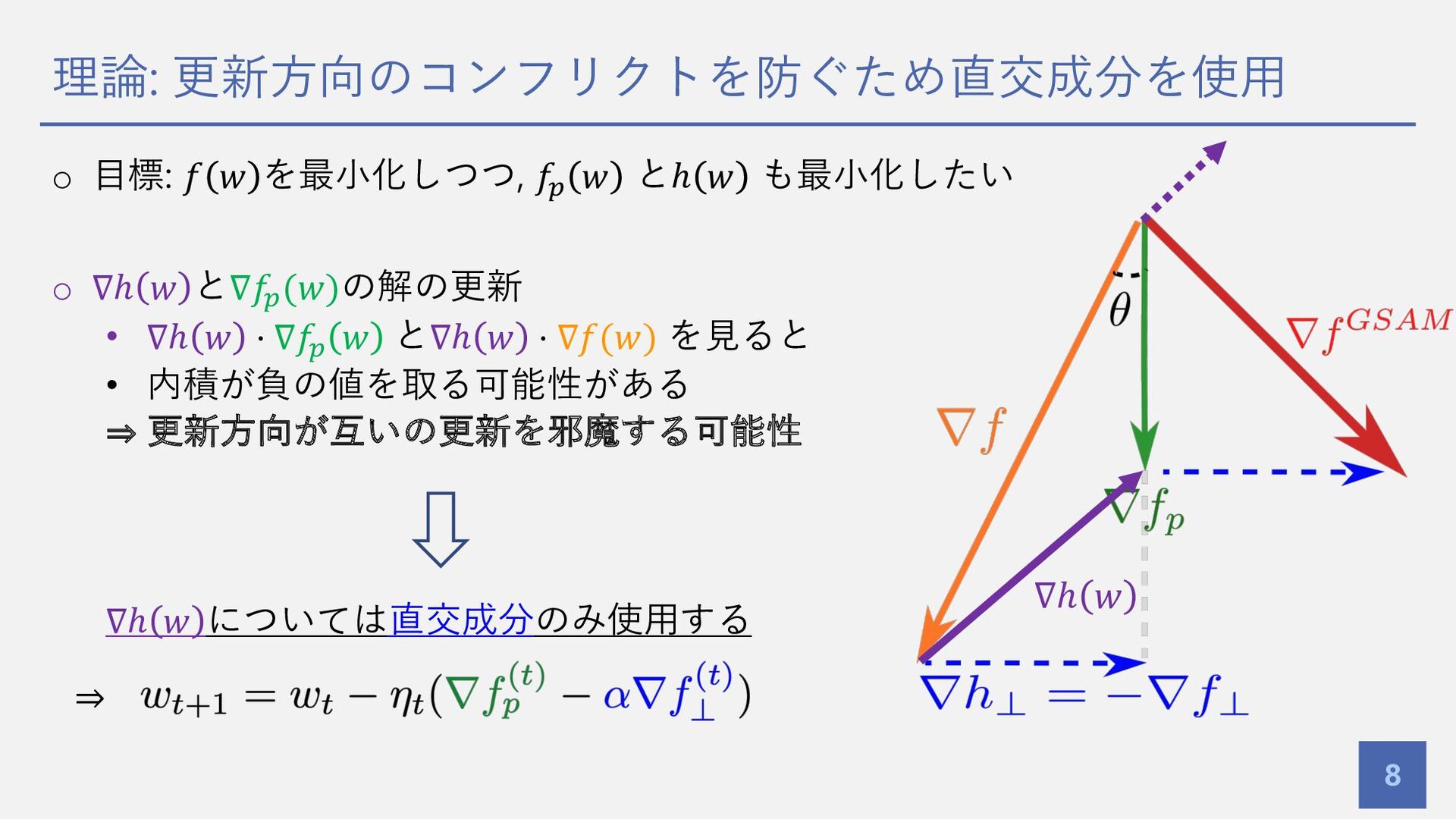
理論: 更新⽅向のコンフリクトを防ぐため直交成分を使⽤ 8 o ⽬標: 𝑓 𝑤 を最⼩化しつつ, 𝑓# 𝑤
とℎ 𝑤 も最⼩化したい o ∇ℎ 𝑤 と∇𝑓#(𝑤)の解の更新 • ∇ℎ 𝑤 ⋅ ∇𝑓# 𝑤 と∇ℎ 𝑤 ⋅ ∇𝑓(𝑤) を⾒ると • 内積が負の値を取る可能性がある ⇒ 更新⽅向が互いの更新を邪魔する可能性 ∇ℎ 𝑤 については直交成分のみ使⽤する ∇ℎ 𝑤 ⇒
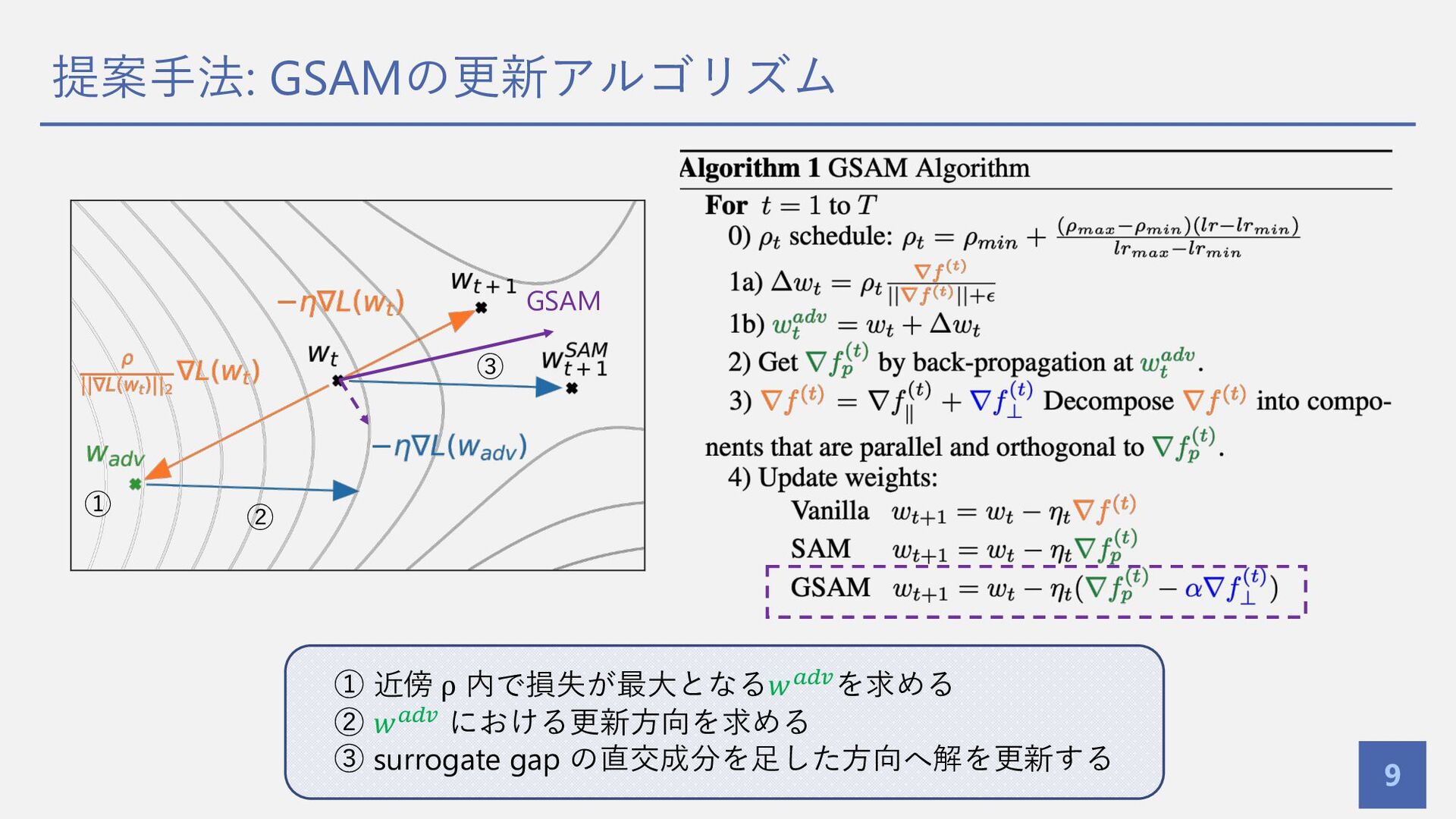
提案⼿法: GSAMの更新アルゴリズム 9 GSAM ① ② ③ ① 近傍 ρ
内で損失が最⼤となる𝑤!"#を求める ② 𝑤!"# における更新⽅向を求める ③ surrogate gap の直交成分を⾜した⽅向へ解を更新する
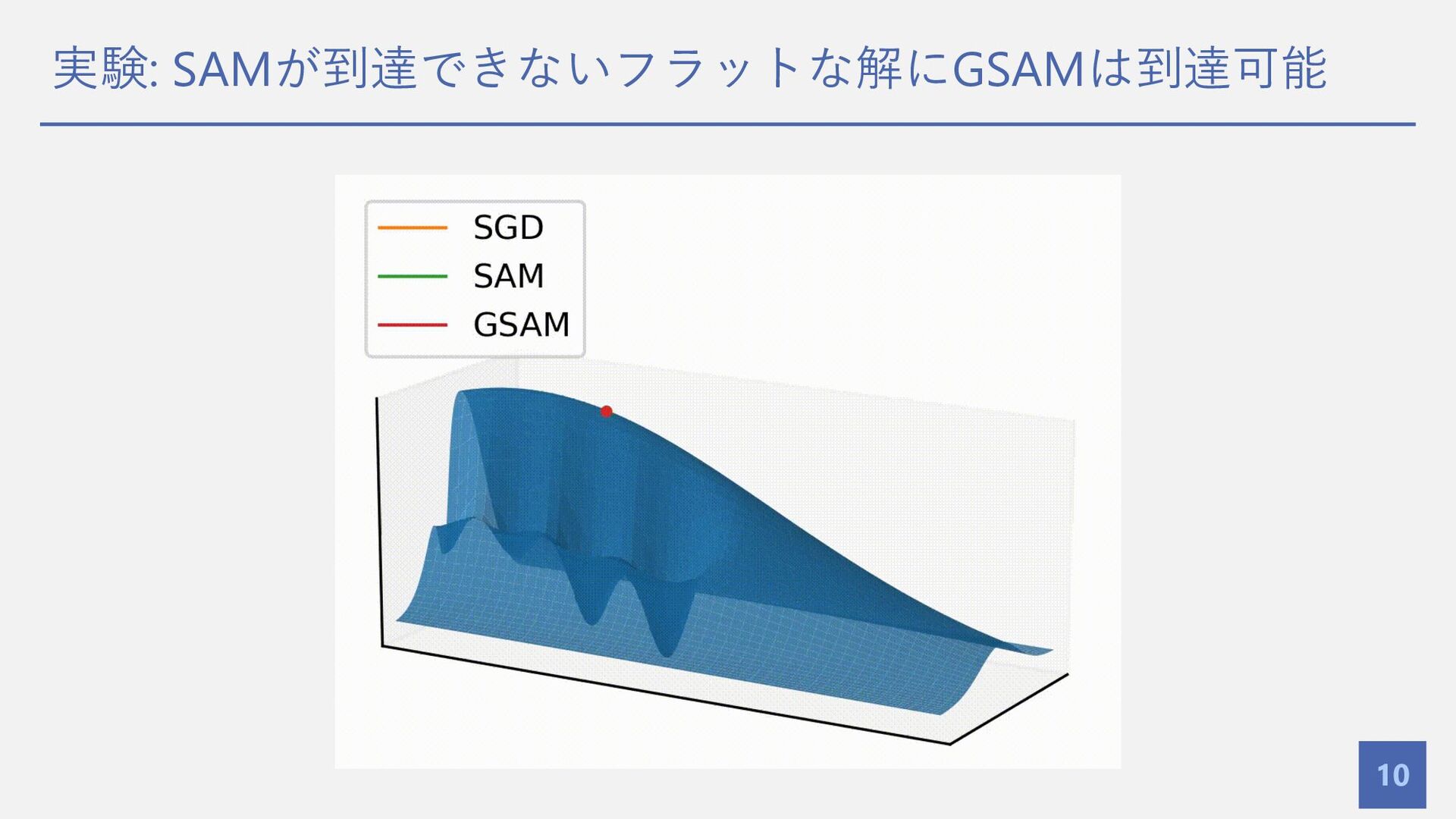
実験: SAMが到達できないフラットな解にGSAMは到達可能 10
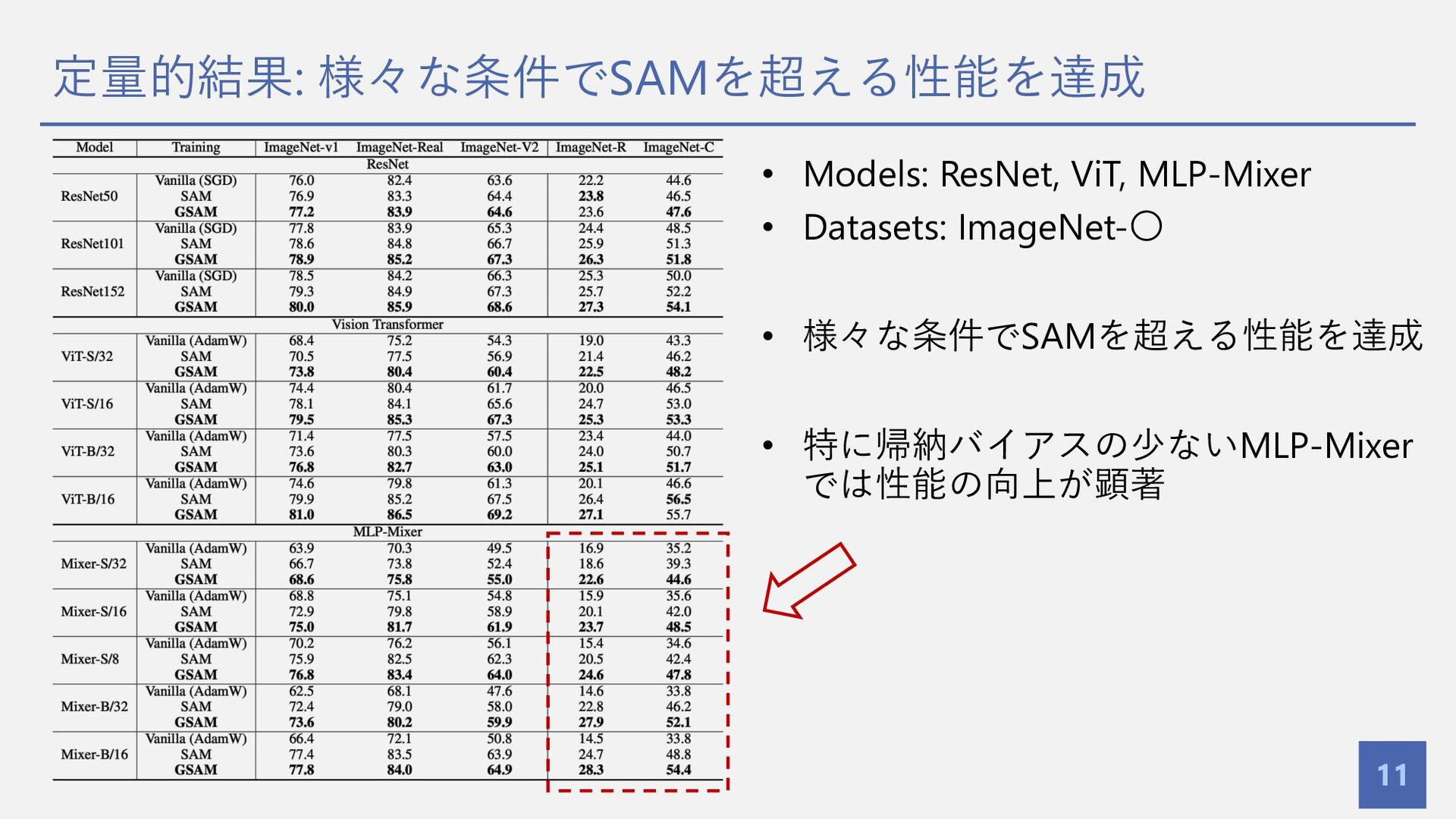
定量的結果: 様々な条件でSAMを超える性能を達成 11 • Models: ResNet, ViT, MLP-Mixer • Datasets:
ImageNet-〇 • 様々な条件でSAMを超える性能を達成 • 特に帰納バイアスの少ないMLP-Mixer では性能の向上が顕著
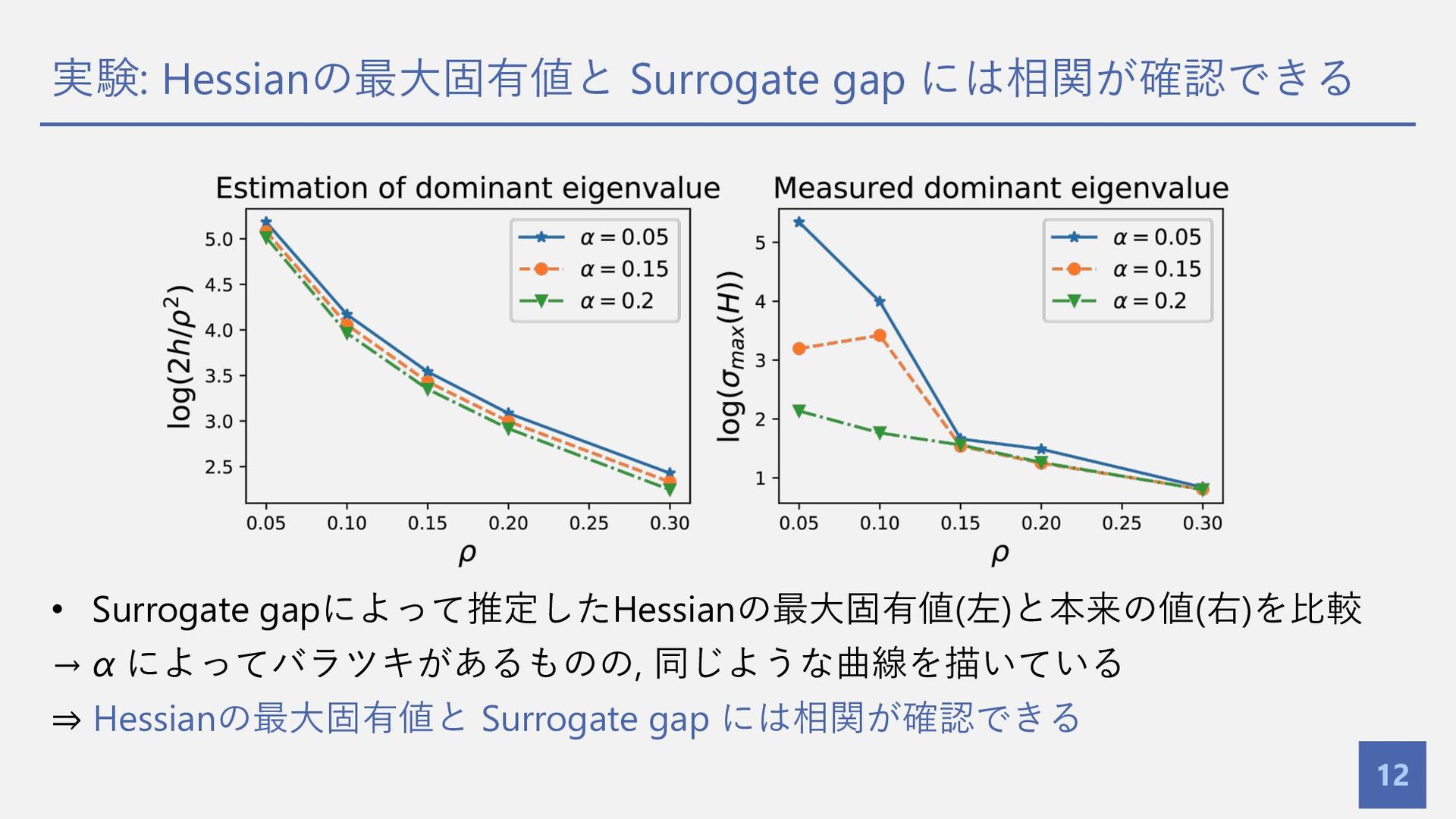
実験: Hessianの最⼤固有値と Surrogate gap には相関が確認できる 12 • Surrogate gapによって推定したHessianの最⼤固有値(左)と本来の値(右)を⽐較 →
α によってバラツキがあるものの, 同じような曲線を描いている ⇒ Hessianの最⼤固有値と Surrogate gap には相関が確認できる
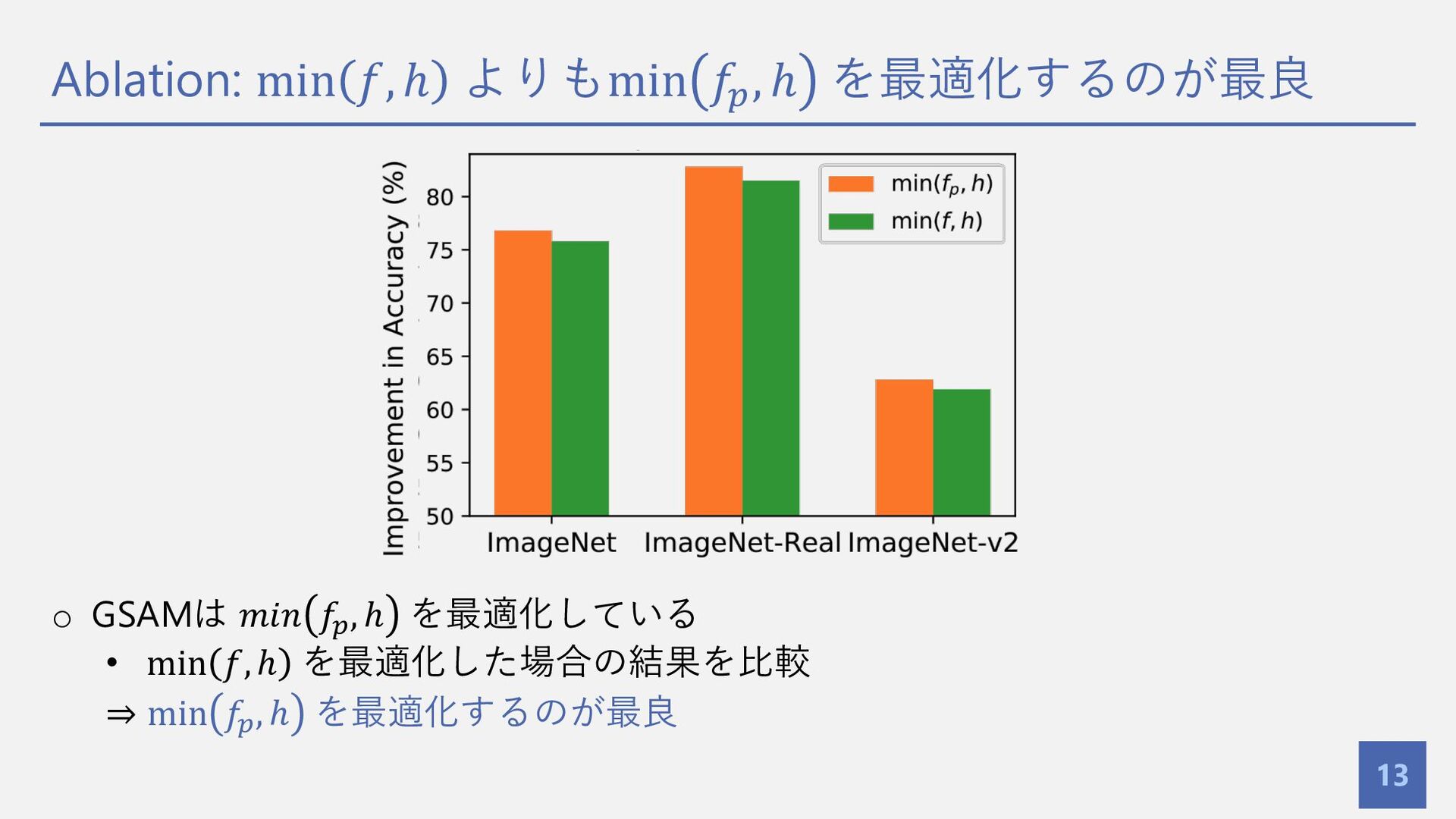
Ablation: min 𝑓, ℎ よりもmin 𝑓! , ℎ を最適化するのが最良 13
o GSAMは 𝑚𝑖𝑛 𝑓#, ℎ を最適化している • min 𝑓, ℎ を最適化した場合の結果を⽐較 ⇒ min 𝑓# , ℎ を最適化するのが最良
まとめ 14 ü 最適化⼿法GSAM(Gap Guided Sharpness-Aware Minimization)を提案 ü Surrogate gapの導⼊によりSAMを改良
ü Surrogate gapがHessianの最⼤固有値と相関を持つことを理論的に証明 ü 様々なモデル・データセットでSAMを超える性能を達成
Appendix: 実験設定 15
{kind=link}
{kind=link}
![既存⼿法: SAM(Sharpness-Aware Minimization) 3 o 最適化⼿法 SAM(Sharpness-Aware Minimization) [Foret+, ICLR21]](https://files.speakerdeck.com/presentations/86b705d3acdb49b49201be9c58a152ca/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}