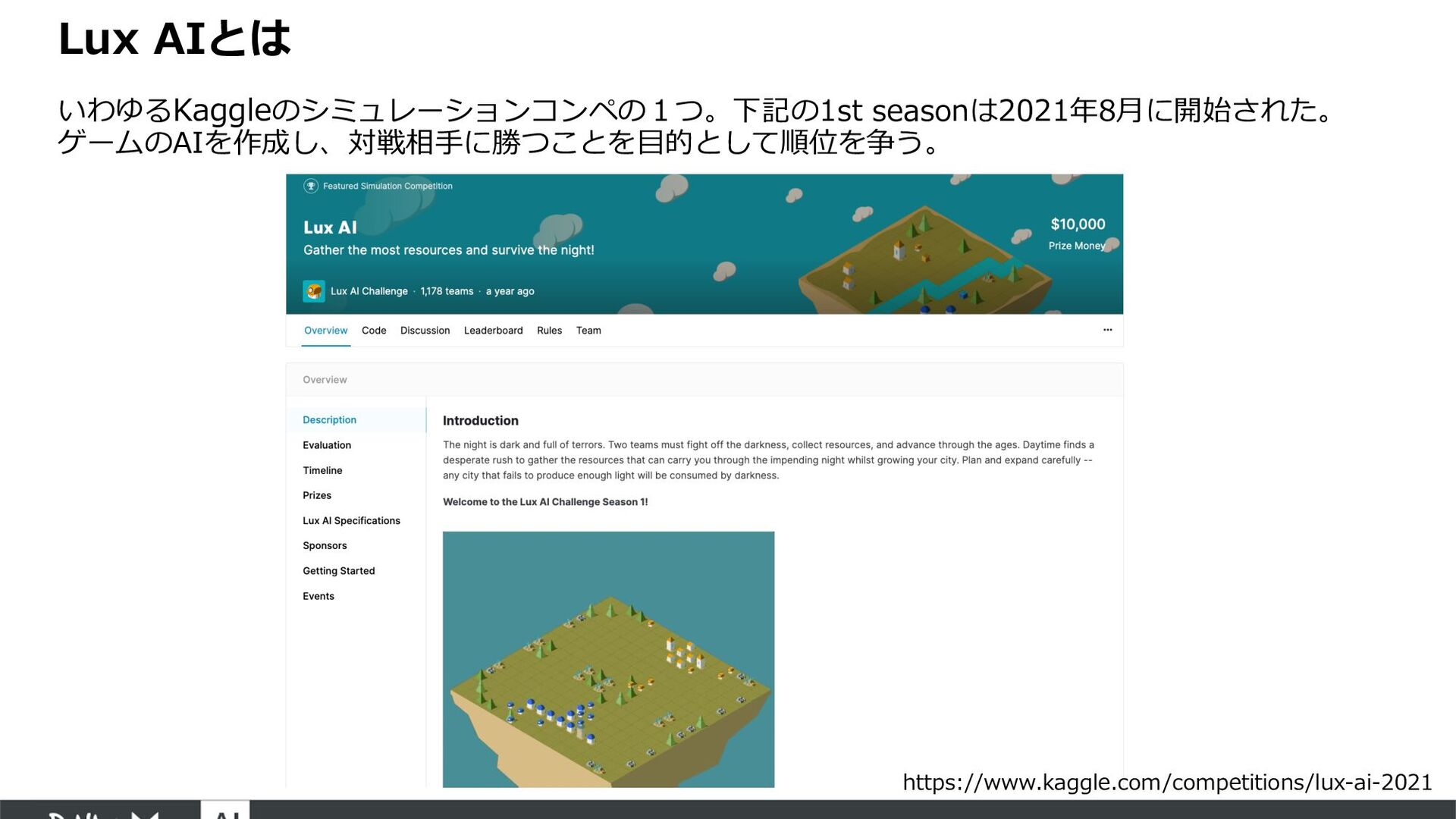
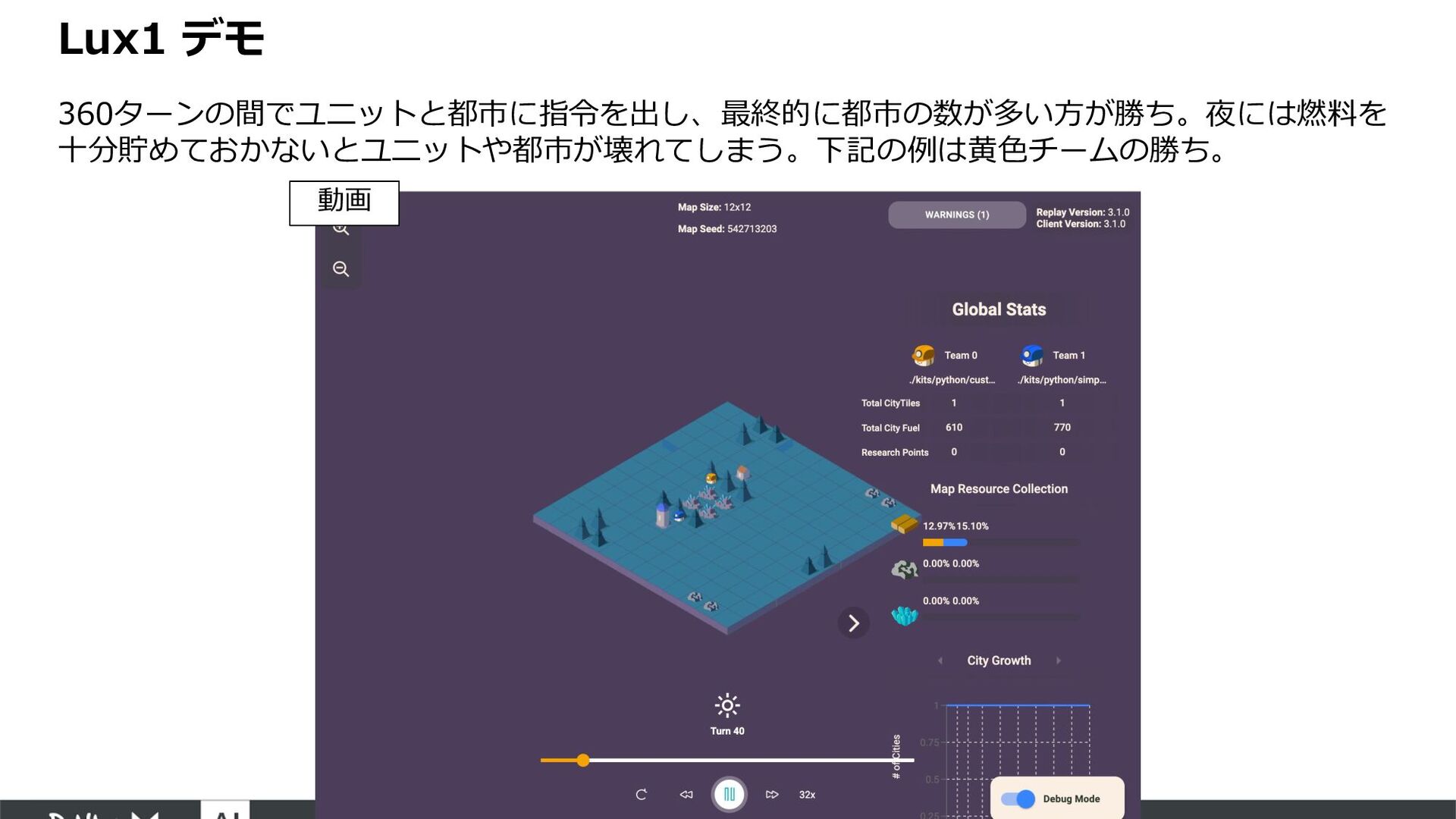
'rank': 1}, {'agentID': 1, 'rank': 2}], 'replayFile': 'replay.json'} replay["teamDetails"] [{'name': './kits/python/customize_001/main.py', 'tournamentID': ’’}, {'name': './kits/python/simple/main.py', 'tournamentID’: replay["allCommands"] [[{'agentID': 0, 'command': 'bw 5 1'}, {'agentID': 0, 'command': 'bcity u_1'}, {'agentID': 1, 'command': 'm u_2 n'}], [{'agentID': 0, 'command': 'bw 5 1'}, {'agentID': 0, 'command': 'm u_1 n'}], [{'agentID': 0, 'command': 'bw 5 1'}, {'agentID': 1, 'command': 'm u_2 s'}], [{'agentID': 0, 'command': 'bw 5 1'}, {'agentID': 0, 'command': 'm u_1 s'}, {'agentID': 1, 'command': 'm u_2 n'}], [{'agentID': 0, 'command': 'r 5 1'}, {'agentID': 0, 'command': 'm u_1 n'}], [{'agentID': 1, 'command': 'm u_2 s'}], [{'agentID': 0, 'command': 'bcity u_1'}, {'agentID': 1, 'command': 'm u_2 n'}], [{'agentID': 0, 'command': 'm u_1 s'}], [{'agentID': 0, 'command': 'm u_1 c'}, {'agentID': 1, 'command': 'm u_2 s'}], [{'agentID': 0, 'command': 'm u_1 n'}, {'agentID': 1, 'command': 'm u_2 n'}], [], [{'agentID': 0, 'command': 'm u_1 s'}, {'agentID': 1, 'command': 'm u_2 s'}], [{'agentID': 0, 'command': 'm u_1 n'}, {'agentID': 1, 'command': 'm u_2 n'}], [], [{'agentID': 0, 'command': 'bw 5 1'}, {'agentID': 0, 'command': 'bcity u_1'}, {'agentID': 1, 'command': 'm u_2 sʼ}], …, [{'agentID': 0, 'command': 'r 5 6'}, {'agentID': 0, 'command': 'bcity u_4'}, {'agentID': 0, 'command': 'bcity u_5'}, {'agentID': 0, 'command': 'bcity u_6'}, {'agentID': 0, 'command': 'bcity u_8'}]] どちらのチームが 勝ったかランクで表⽰ 対戦に利⽤したagentの プログラムコードの場所 lux-ai-2021 ./kits/python/customize_001/main.py ./kits/python/simple/main.py --python=python3 --out=replay.json --statefulReplay true --width 12 --height 12 対戦実⾏コマンド 各ユニット、都市の選択した アクションがstep毎に記録されている
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ローカルで対戦実⾏を⾏うと結果の情報がreplay.json形式で得られる。これを分析したり、学習 のためのデータとしたりすることができる。 2. 開発キット、プラットフォーム、データの理解 replay.jsonの構造 replay["results"] {'ranks‘: [ {'agentID': 0,](https://files.speakerdeck.com/presentations/fe780300942a4276a4c8a5d275ed303d/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
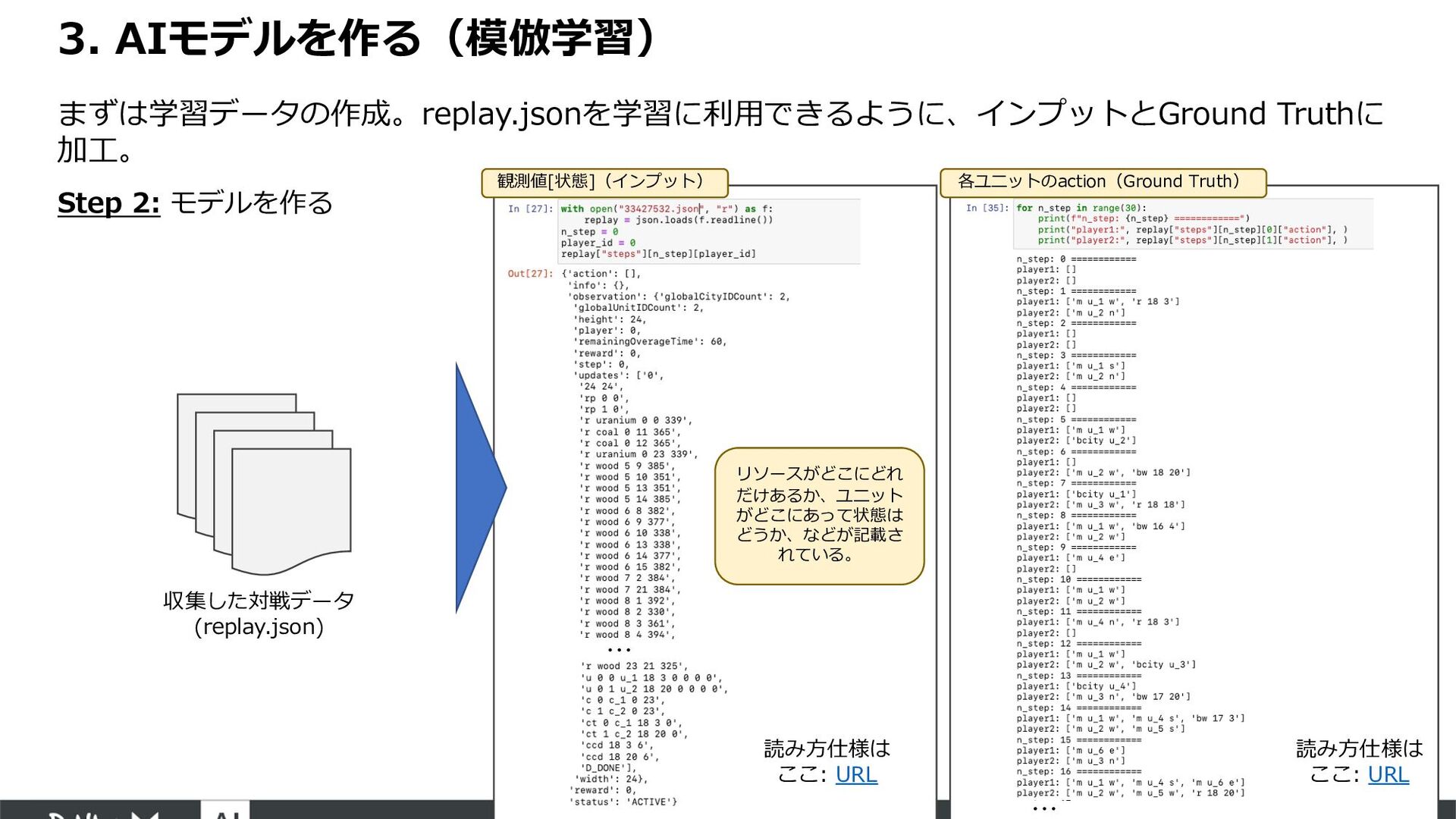{kind=link}
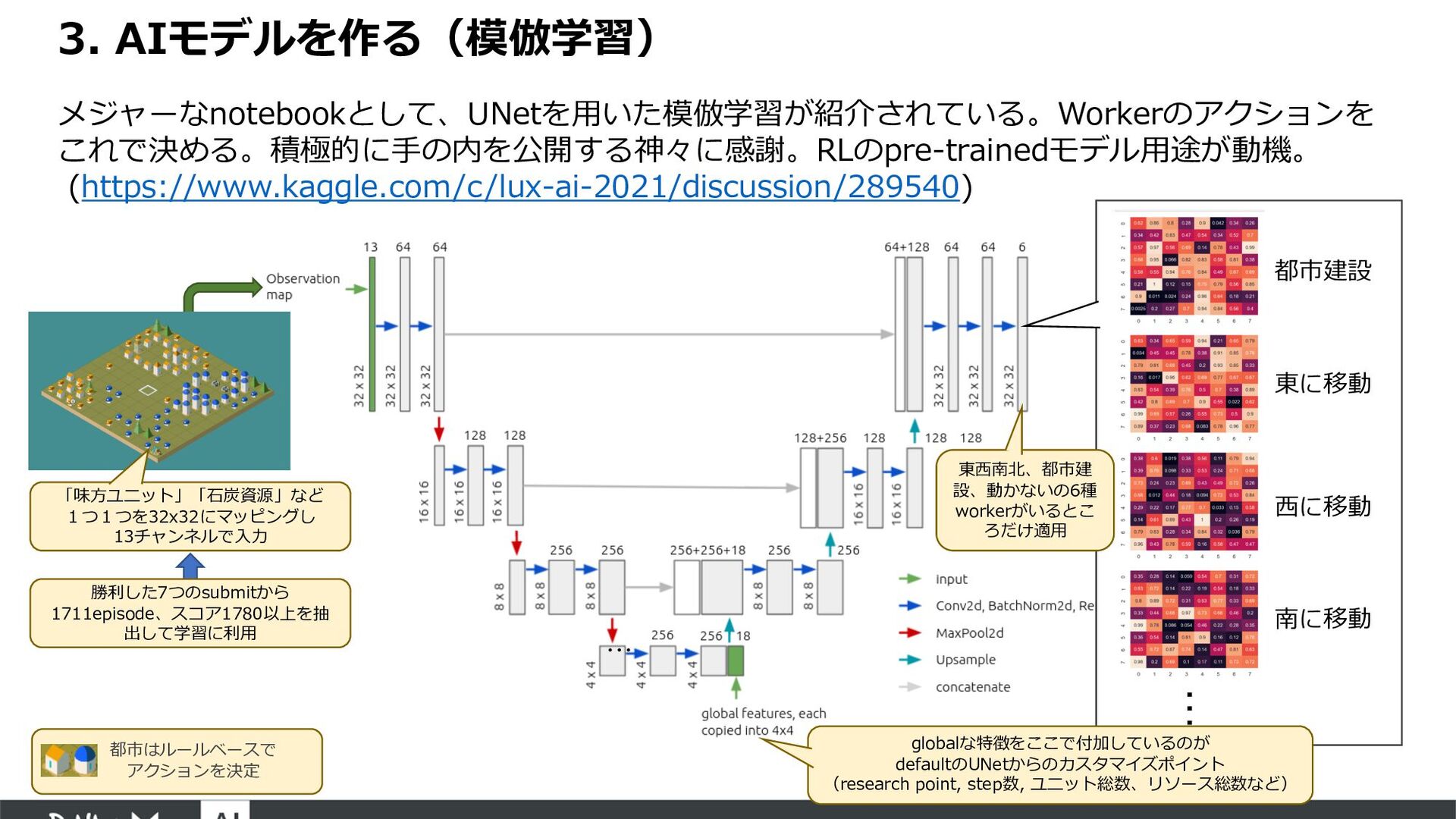{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}