Duflo, Christian Hansen, Whitney Newey, and James Robins. Double/debiased machine learning for treatment and structural parameters. The Econometrics Journal, 2018. • Victor Chernozhukov, Whitney K. Newey, and Rahul Singh. Automatic debiased machine learning of causal and structural effects. Econometrica, 2022 • Takafumi Kanamori, Shohei Hido, and Masashi Sugiyama. A least-squares approach to direct importance estimation. In JMLR, 2008. • Masahiro Kato and Takeshi Teshima. Non-negative bregman divergence minimization for deep direct density ratio estimation. In ICML, 2021. • B. Rhodes, K. Xu, and M.U. Gutmann. Telescoping density-ratio estimation. In NeurIPS, 2020. • Kristy Choi, Chenlin Meng, Yang Song, and Stefano Ermon. Density ratio estimation via infinitesimal classification. In AISTATS, 2022. • Oscar Jord`a. Estimation and inference of impulse responses by local projections. American Economic Review, 2005. • Yuichirou Ito, Shougo Nakano, Shunsuke Haba, and Takahiro Yamanaka. Medium- to long-term effects of monetary policy. Working Paper 24-J-21, Bank of Japan, Tokyo, Japan, November 2024. In Japanese. Original Japanese title: 金融政策の中 長期的な影響. • Masahiro Kato. Direct bias-correction term estimation for propensity scores and average treatment effect estimation, 2025. • Masahiro Kato. A Unified Framework for Debiased Machine Learning:\\ Riesz Representer Fitting under Bregman Divergence, 2026. • Pascal Vincent. A connection between score matching and denoising autoencoders. Neural Computation, 23(7):1661– 1674, 2011
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
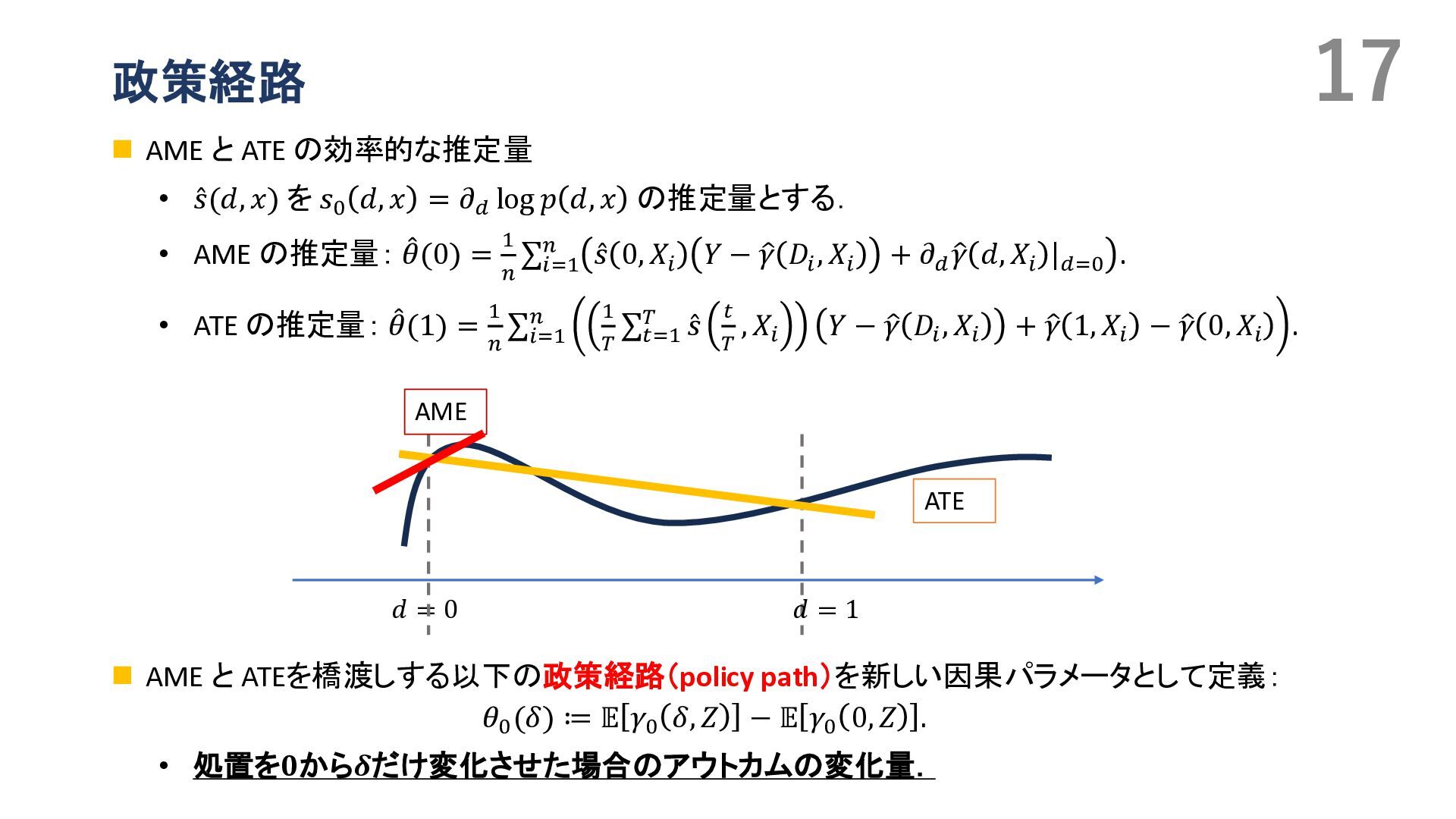{kind=link}
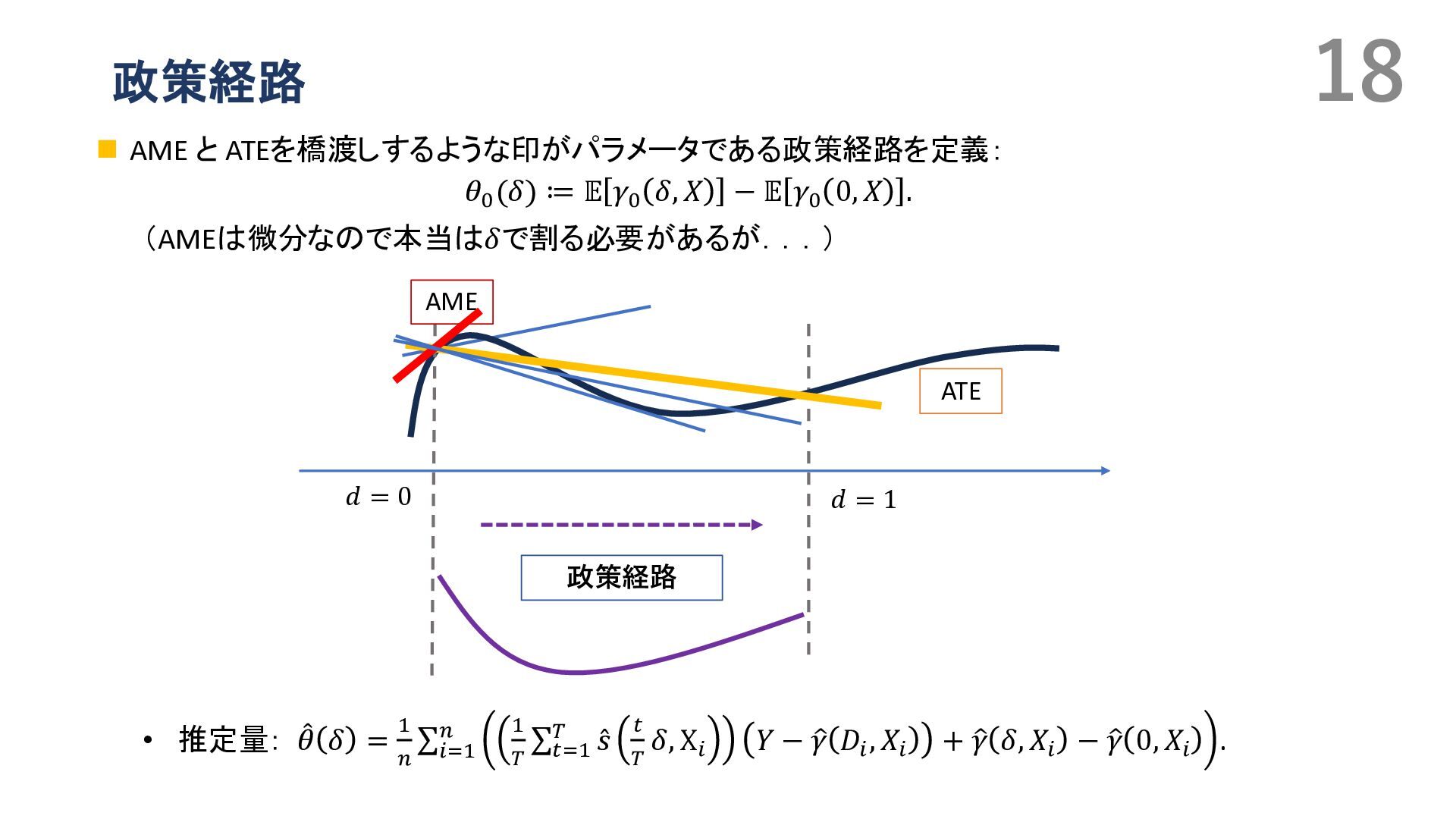{kind=link}
{kind=link}
{kind=link}
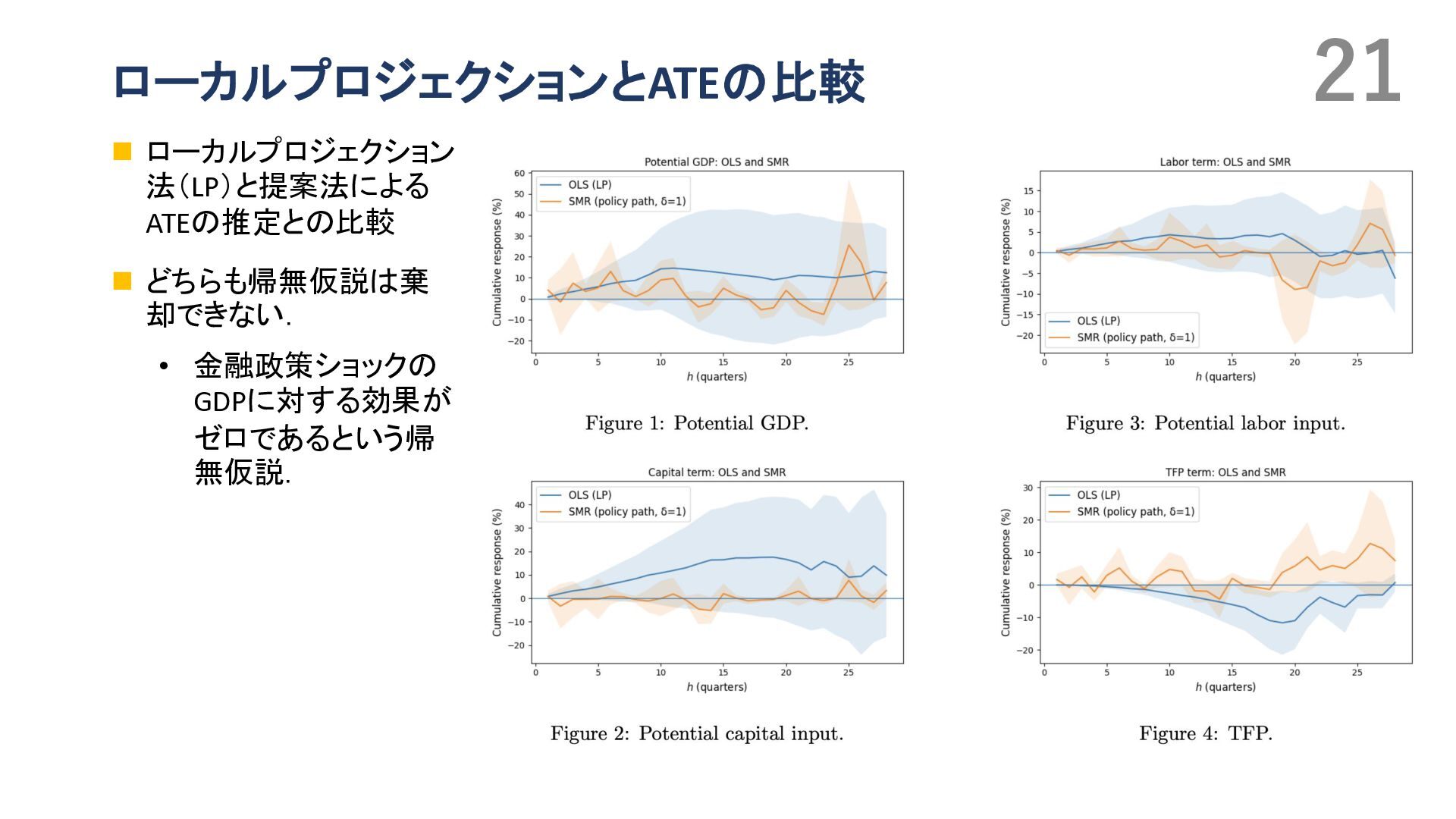{kind=link}
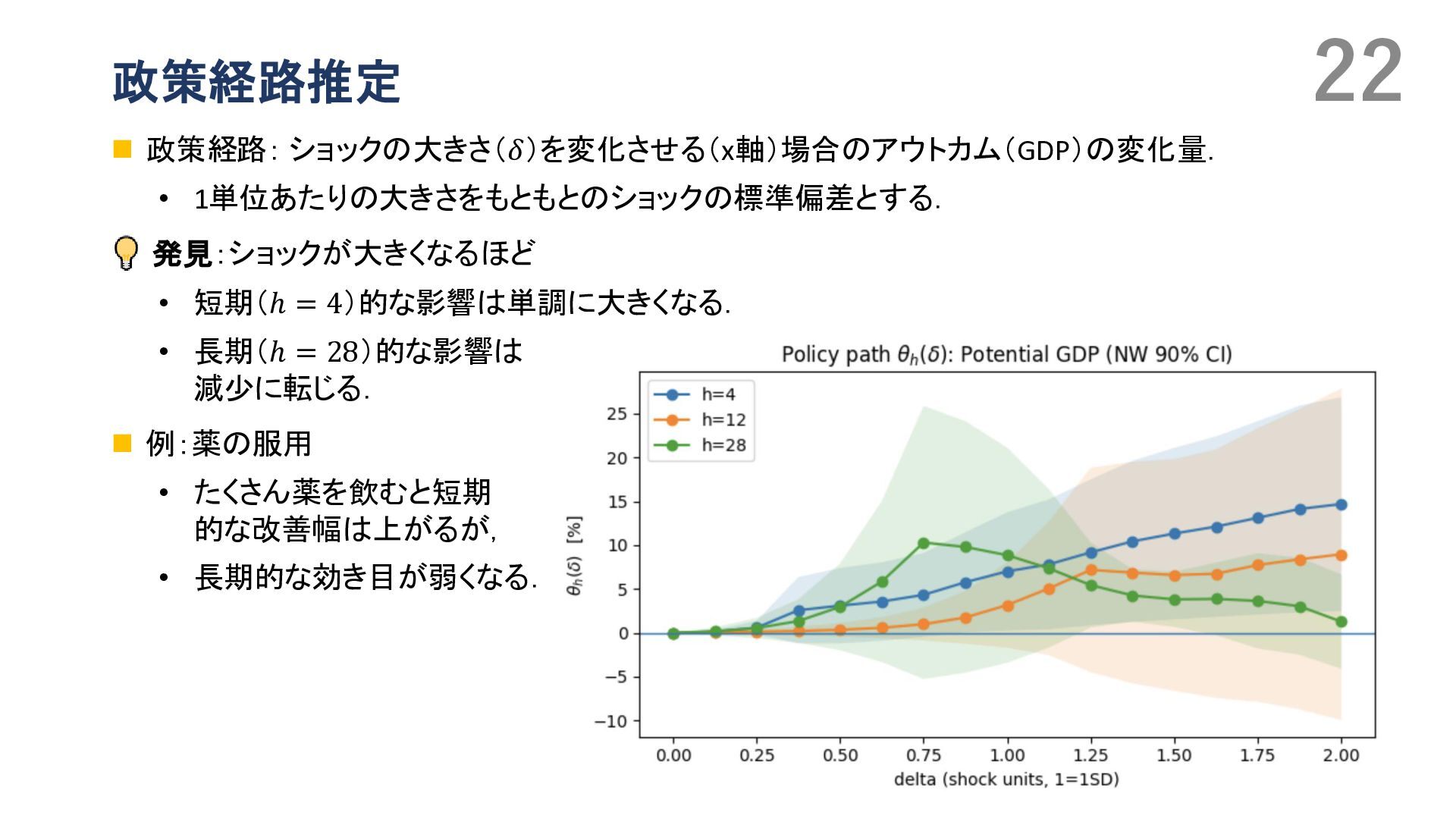{kind=link}
{kind=link}
{kind=link}