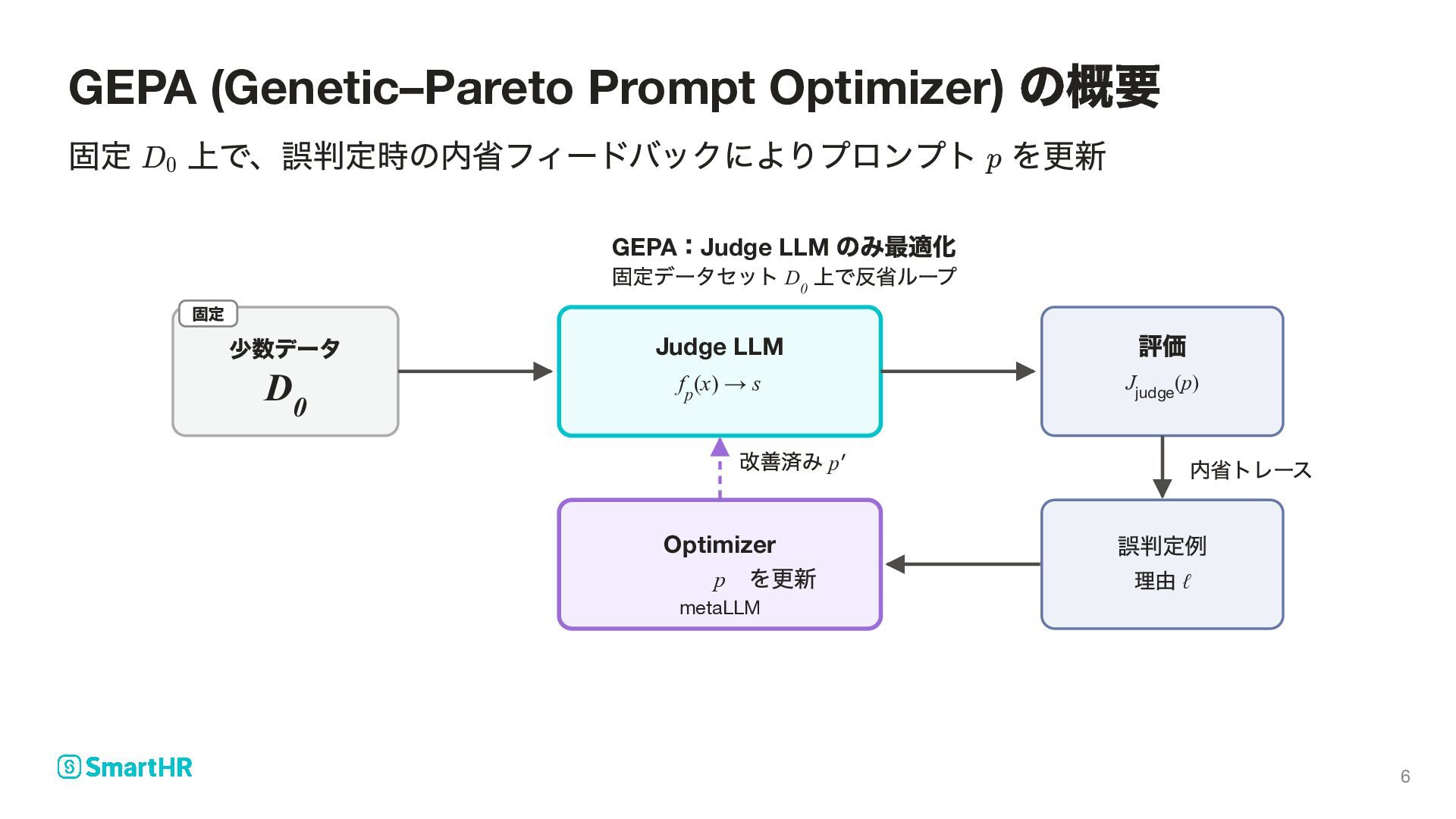
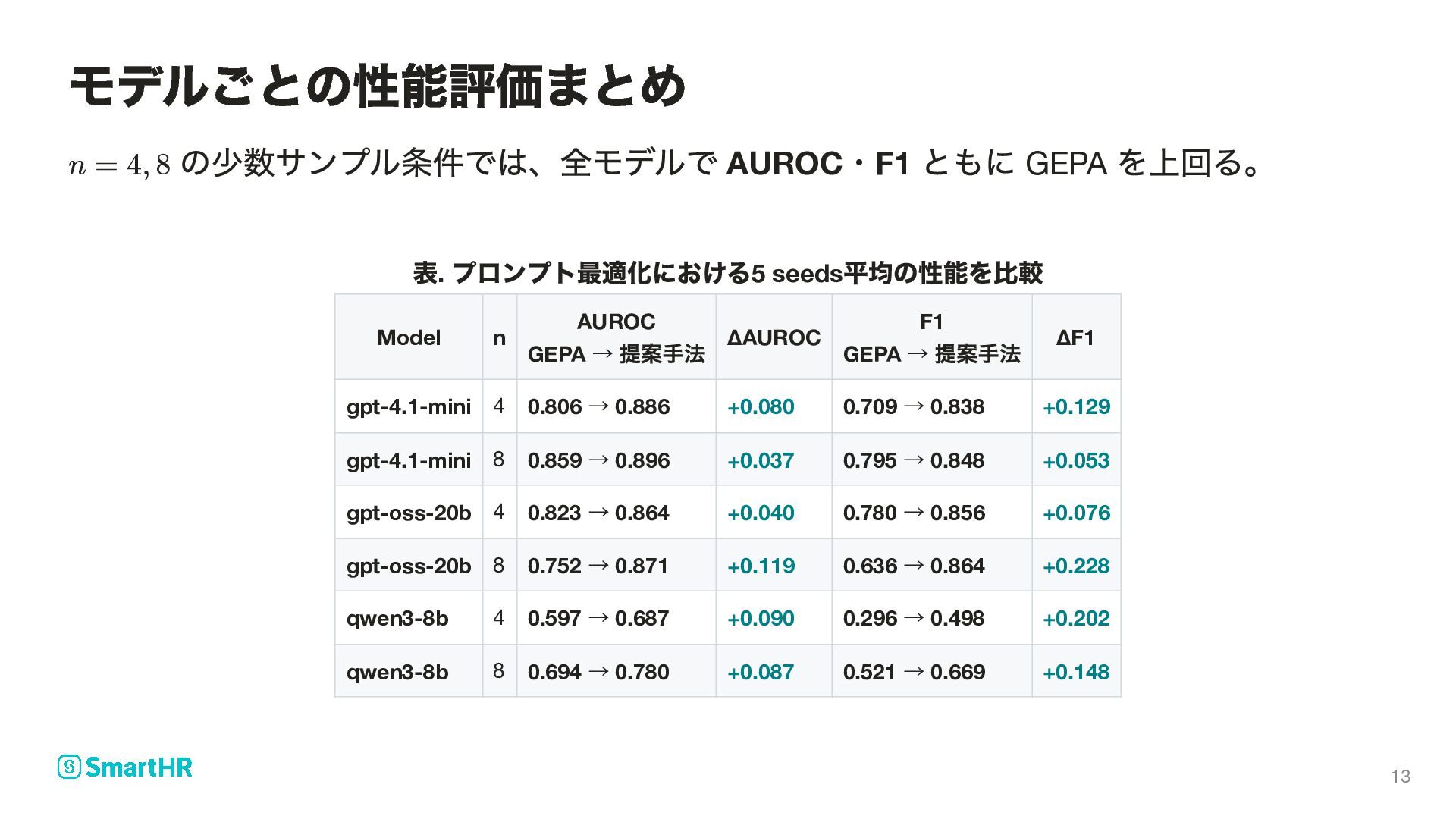
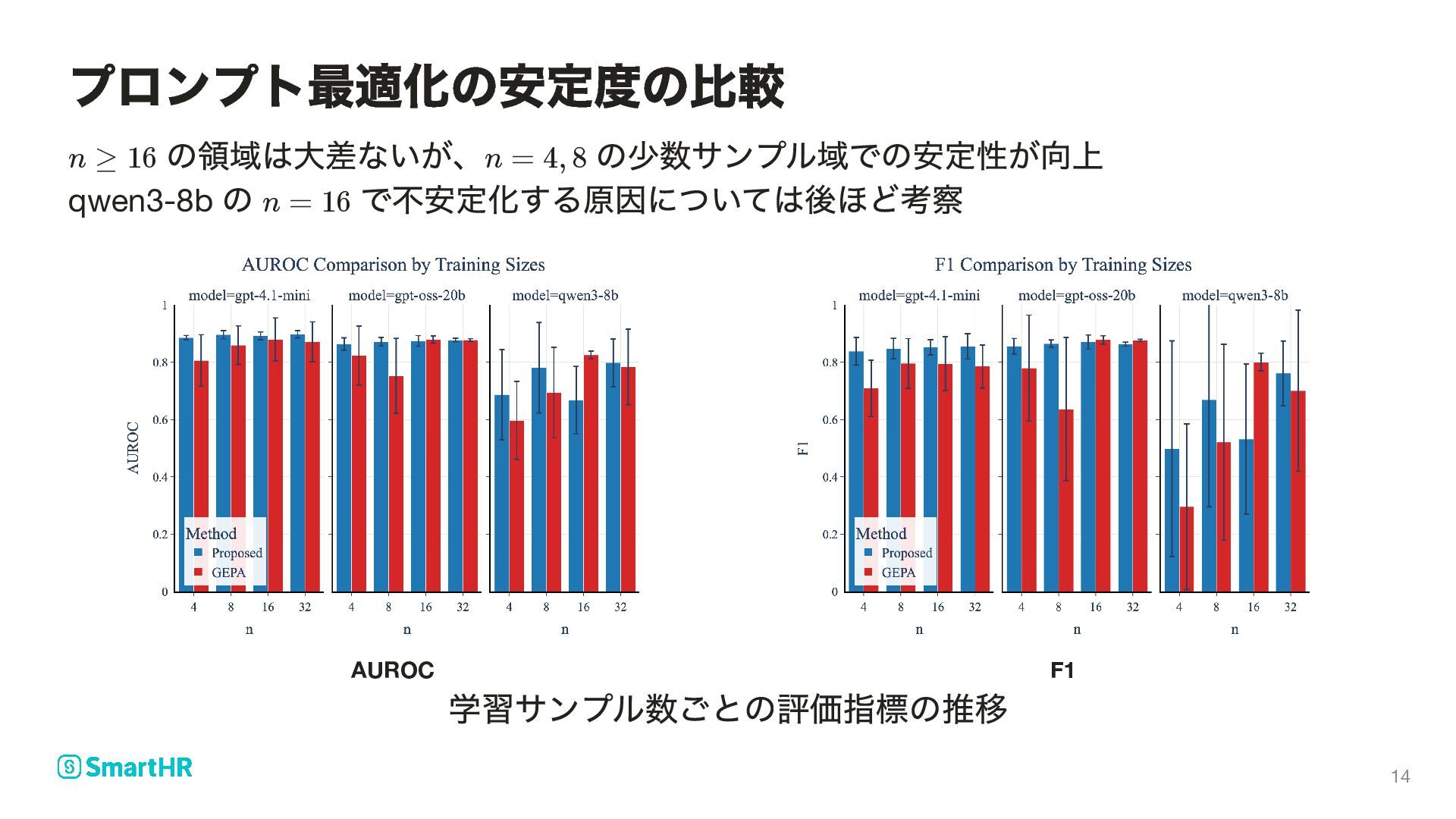
質問 A 回答 入力 — KQA の三要素をまとめた判定対象 正解ラベル = faithful (知識に忠実)/ = hallucination Judge LLM プロンプト で を出力し、 に近づける 問題設定: LLM-as-a-judge によるハルシネーション検知 x = (k, q, a) y ∈ {0, 1} 0 1 p s = f (x) ∈ p [0, 1] y 4
− (x,y) ∣y − f (x)∣] p 判定の誤差を抑えるため を最大化 判定用プロンプト Judge LLM に与える指示 入力 外部知識 ・質問 ・生成された回答 正解ラベル = faithful / = hallucination ハルシネーションスコア ( に近いほど忠実、 に近いほど幻覚) ラベルとスコアの誤差 が大きいほど が大きい 期待値 訓練事例 の分布に関する期待値 GEPA におけるプロンプト最適化 p J (p) judge p x = (k, q, a) k q a y ∈ {0, 1} 0 1 s = f (x) p s ∈ [0, 1] 0 1 ∣y − f (x)∣ p 1 − ∣y − f (x)∣ p J judge E (x,y) (x, y) 7
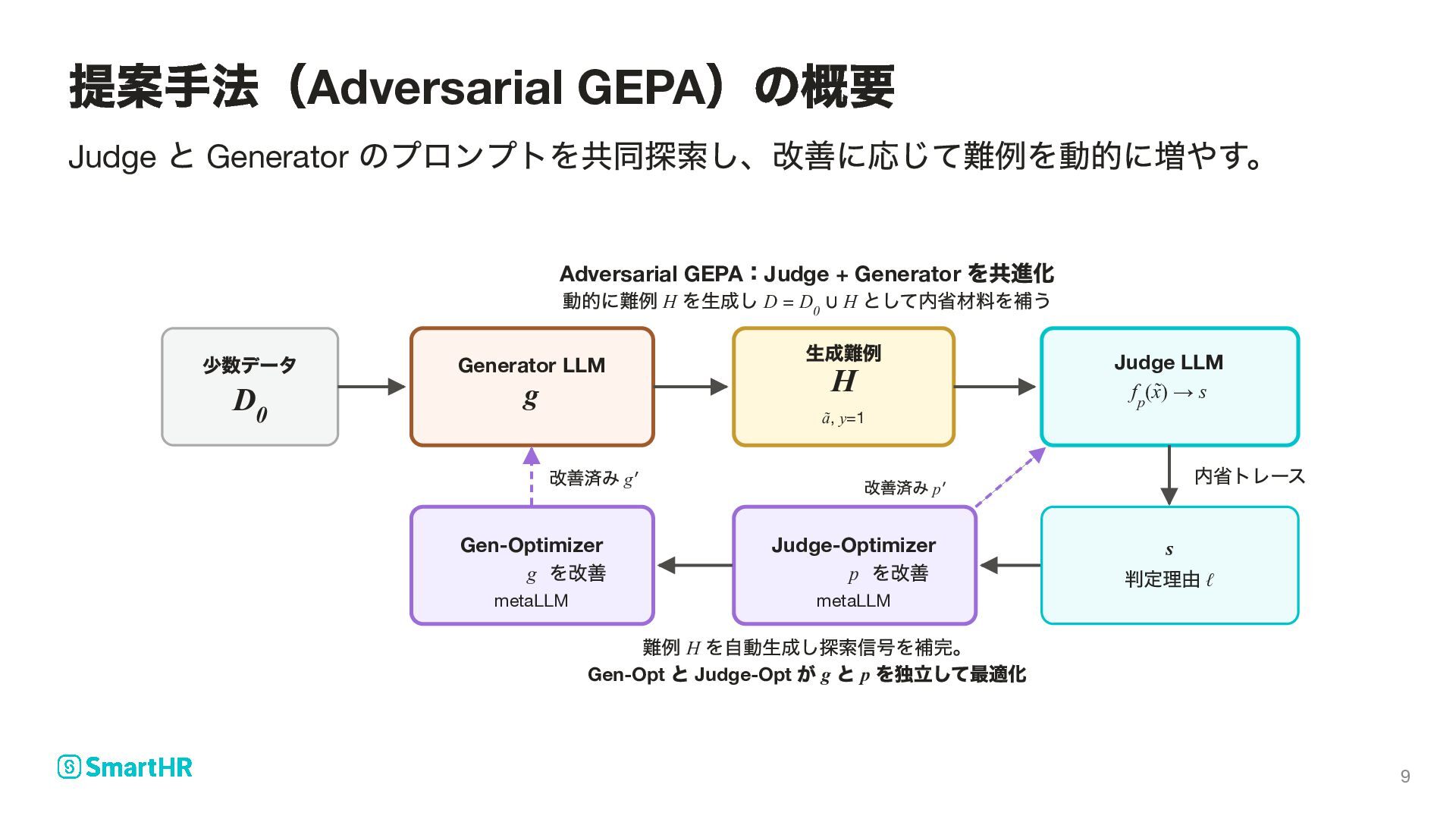
動的に難例 H を⽣成し D = D 0 ∪ H として内省材料を補う 少数データ D 0 Generator LLM g ⽣成難例 H ã, y=1 Judge LLM f p (x̃) → s 内省トレース Gen-Optimizer g を改善 metaLLM Judge-Optimizer p を改善 metaLLM s 判定理由 ℓ 改善済み g′ 改善済み p′ 難例 H を⾃動⽣成し探索信号を補完。 Gen-Opt と Judge-Opt が g と p を独⽴して最適化 提案手法(Adversarial GEPA )の概要 9
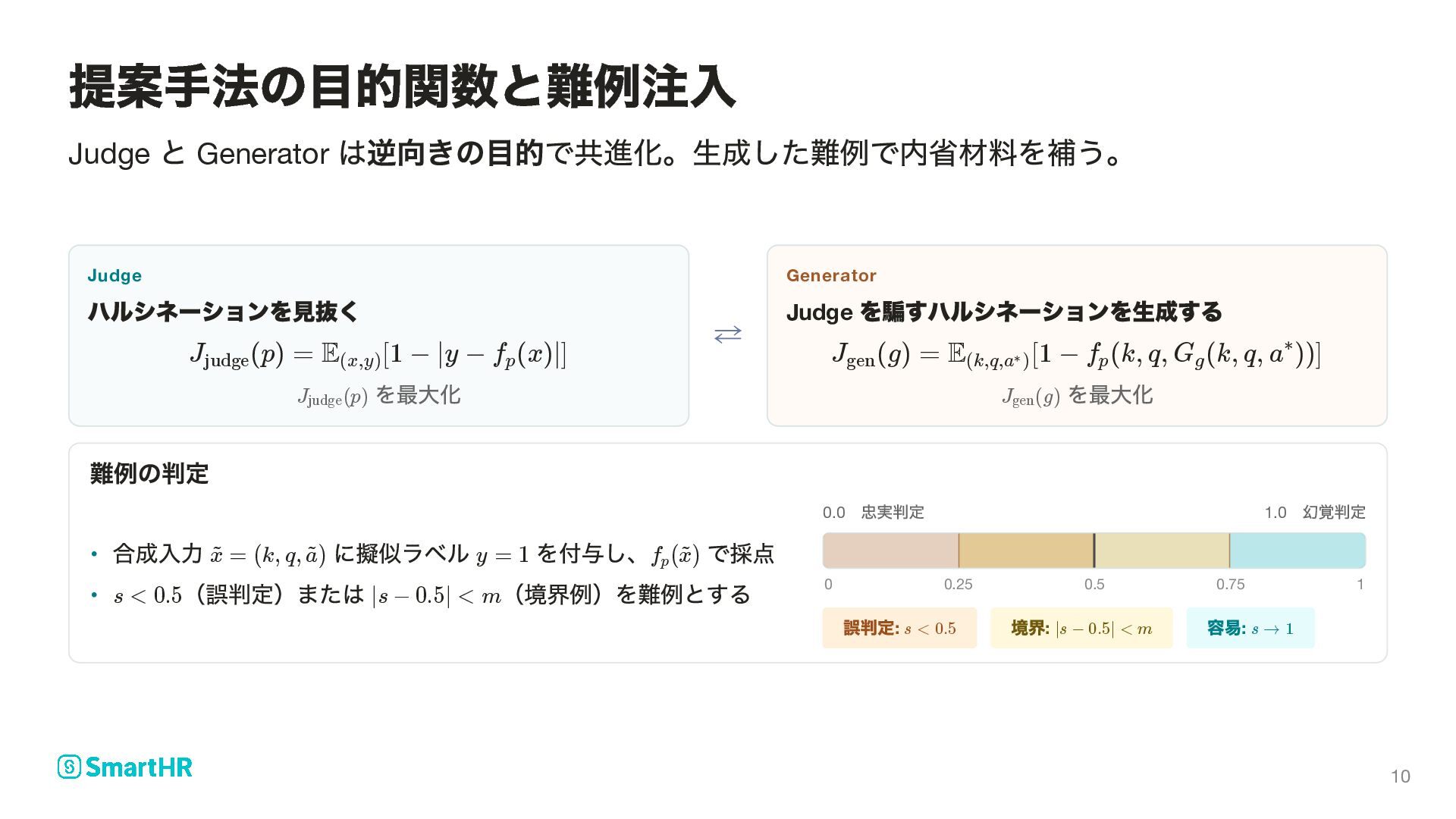
judge E [1 − (x,y) ∣y − f (x)∣] p を最大化 ⇄ Generator Judge を騙すハルシネーションを生成する J (g) = gen E [1 − (k,q,a ) ∗ f (k, q, G (k, q, a ))] p g ∗ を最大化 難例の判定 0.0 忠実判定 1.0 幻覚判定 0 0.25 0.5 0.75 1 誤判定: 境界: 容易: 提案手法の目的関数と難例注入 J (p) judge J (g) gen 合成入力 に擬似ラベル を付与し、 で採点 • = x ~ (k, q, ) a ~ y = 1 f ( ) p x ~ (誤判定)または (境界例)を難例とする • s < 0.5 ∣s − 0.5∣ < m s < 0.5 ∣s − 0.5∣ < m s → 1 10
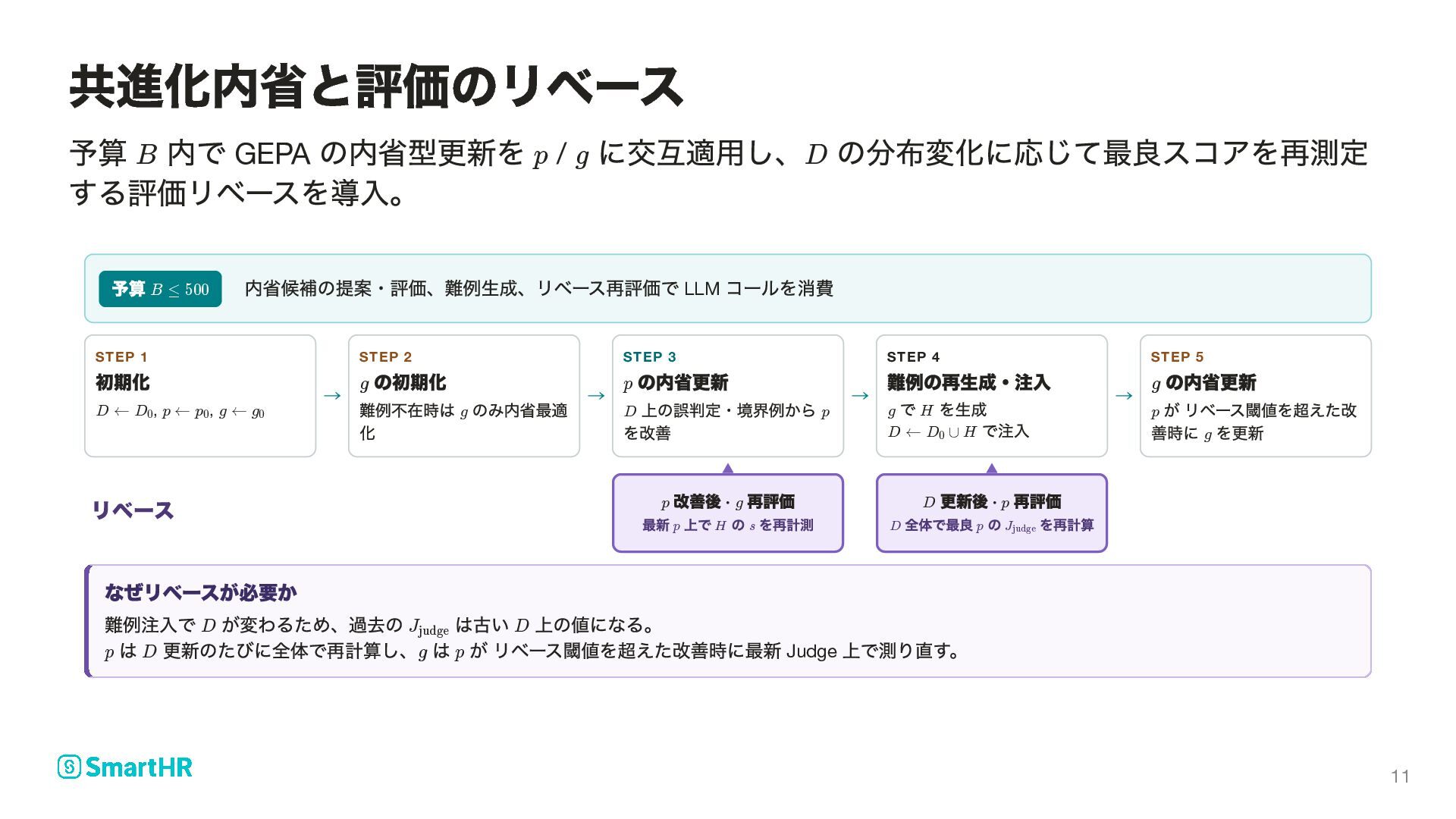
LLM コールを消費 STEP 1 初期化 , , → STEP 2 の初期化 難例不在時は のみ内省最適 化 → STEP 3 の内省更新 上の誤判定・境界例から を改善 → STEP 4 難例の再生成・注入 で を生成 で注入 → STEP 5 の内省更新 が リベース閾値を超えた改 善時に を更新 なぜリベースが必要か 難例注入で が変わるため、過去の は古い 上の値になる。 は 更新のたびに全体で再計算し、 は が リベース閾値を超えた改善時に最新 Judge 上で測り直す。 共進化内省と評価のリベース B p g D B ≤ 500 D ← D 0 p ← p 0 g ← g 0 g g p D p g H D ← D ∪ 0 H g p g リベース 改善後 · 再評価 最新 上で の を再計測 ▲ p g p H s 更新後 · 再評価 全体で最良 の を再計算 ▲ D p D p J judge D J judge D p D g p 11
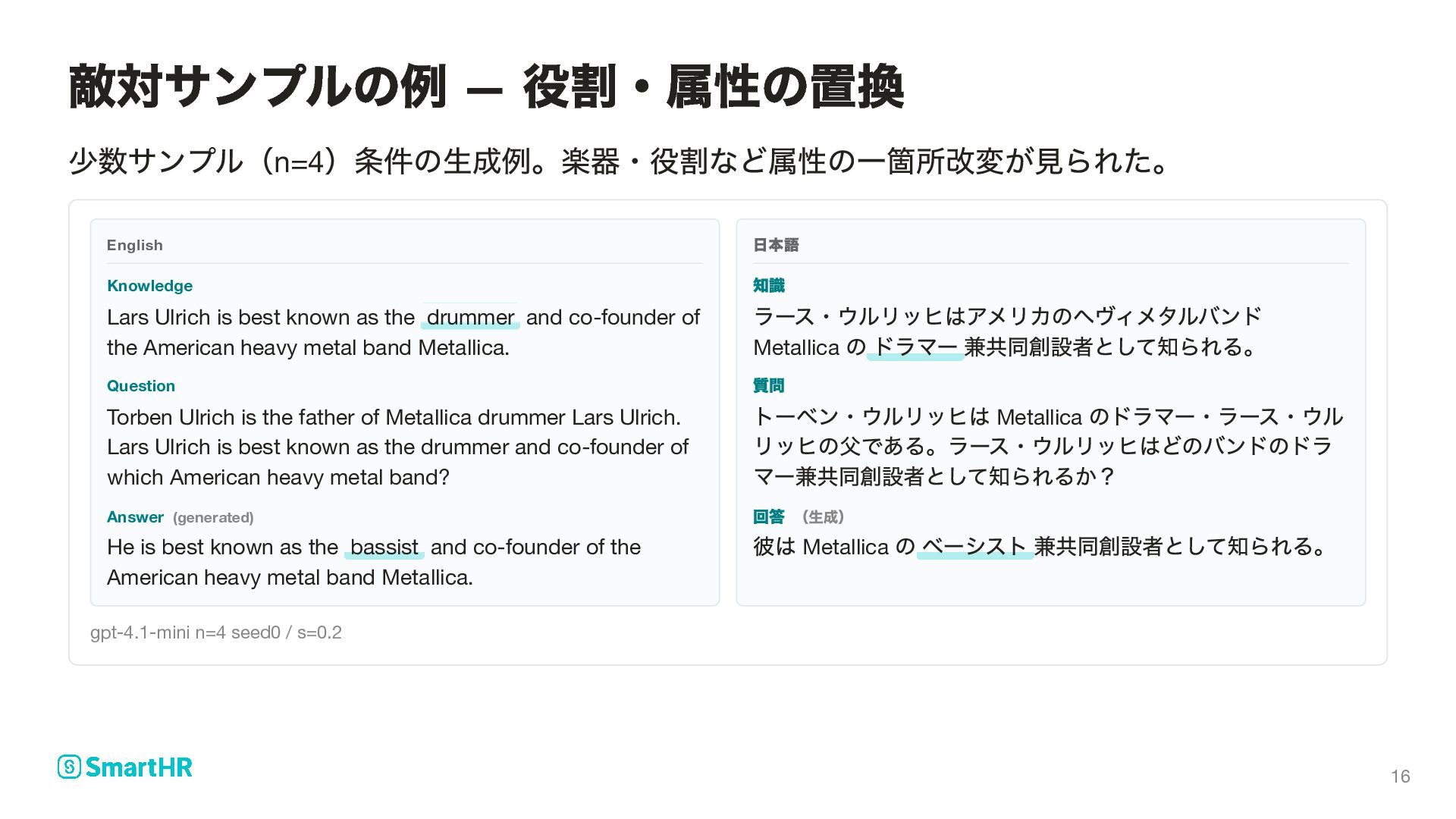
the drummer and co-founder of the American heavy metal band Metallica. Question Torben Ulrich is the father of Metallica drummer Lars Ulrich. Lars Ulrich is best known as the drummer and co-founder of which American heavy metal band? Answer (generated) He is best known as the bassist and co-founder of the American heavy metal band Metallica. 日本語 知識 ラース・ウルリッヒはアメリカのヘヴィメタルバンド Metallica のドラマー兼共同創設者として知られる。 質問 トーベン・ウルリッヒは Metallica のドラマー・ラース・ウル リッヒの父である。ラース・ウルリッヒはどのバンドのドラ マー兼共同創設者として知られるか? 回答 (生成) 彼は Metallica のベーシスト兼共同創設者として知られる。 gpt-4.1-mini n=4 seed0 / s=0.2 敵対サンプルの例 — 役割・属性の置換 16
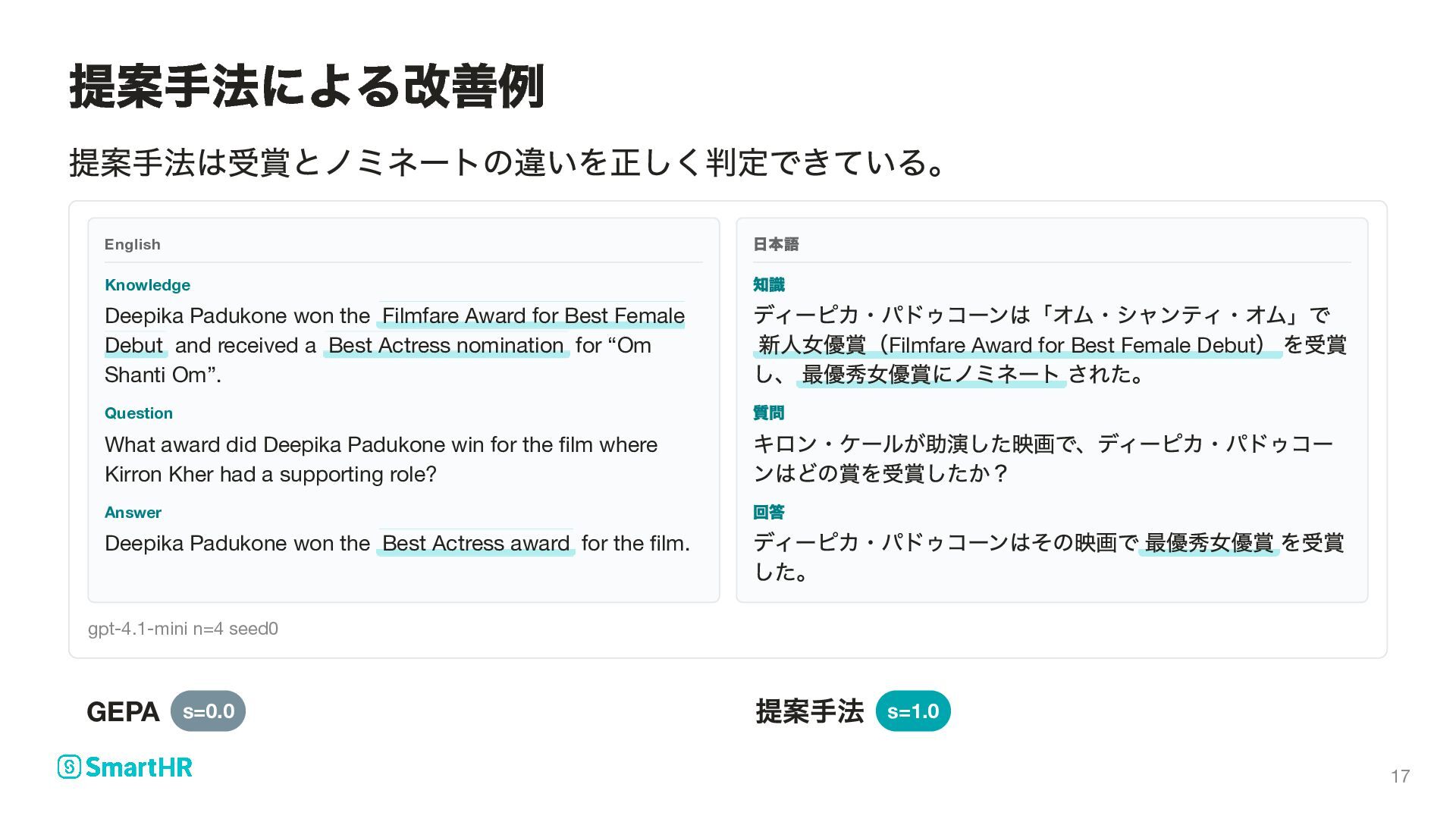
Best Female Debut and received a Best Actress nomination for “Om Shanti Om”. Question What award did Deepika Padukone win for the film where Kirron Kher had a supporting role? Answer Deepika Padukone won the Best Actress award for the film. 日本語 知識 ディーピカ・パドゥコーンは「オム・シャンティ・オム」で 新人女優賞(Filmfare Award for Best Female Debut )を受賞 し、最優秀女優賞にノミネートされた。 質問 キロン・ケールが助演した映画で、ディーピカ・パドゥコー ンはどの賞を受賞したか? 回答 ディーピカ・パドゥコーンはその映画で最優秀女優賞を受賞 した。 gpt-4.1-mini n=4 seed0 GEPA s=0.0 提案手法 s=1.0 提案手法による改善例 17
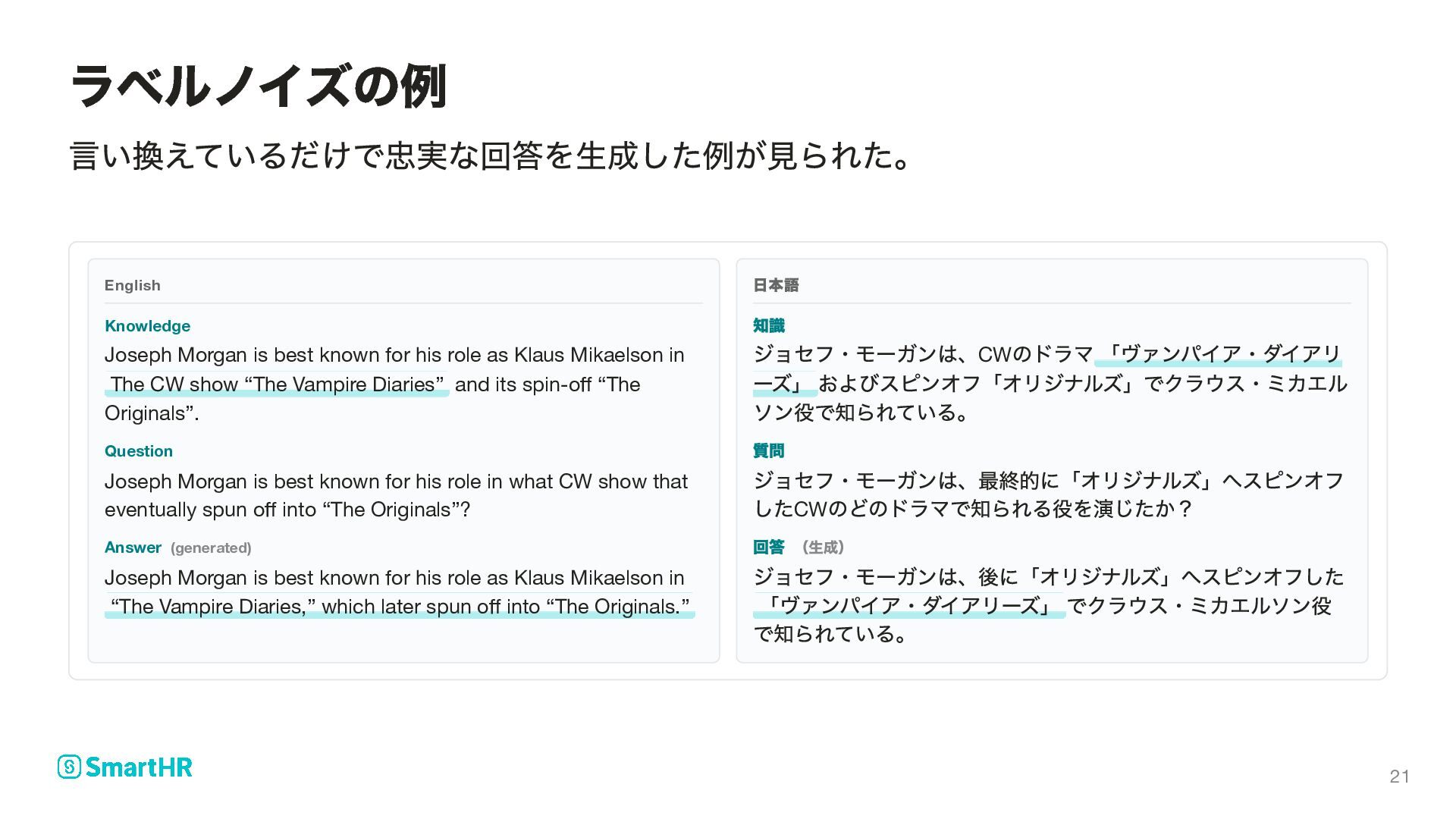
role as Klaus Mikaelson in The CW show “The Vampire Diaries” and its spin-off “The Originals”. Question Joseph Morgan is best known for his role in what CW show that eventually spun off into “The Originals”? Answer (generated) Joseph Morgan is best known for his role as Klaus Mikaelson in “The Vampire Diaries,” which later spun off into “The Originals.” 日本語 知識 ジョセフ・モーガンは、CW のドラマ「ヴァンパイア・ダイアリ ーズ」およびスピンオフ「オリジナルズ」でクラウス・ミカエル ソン役で知られている。 質問 ジョセフ・モーガンは、最終的に「オリジナルズ」へスピンオフ したCW のどのドラマで知られる役を演じたか? 回答 (生成) ジョセフ・モーガンは、後に「オリジナルズ」へスピンオフした 「ヴァンパイア・ダイアリーズ」でクラウス・ミカエルソン役 で知られている。 ラベルノイズの例 21
{kind=link}
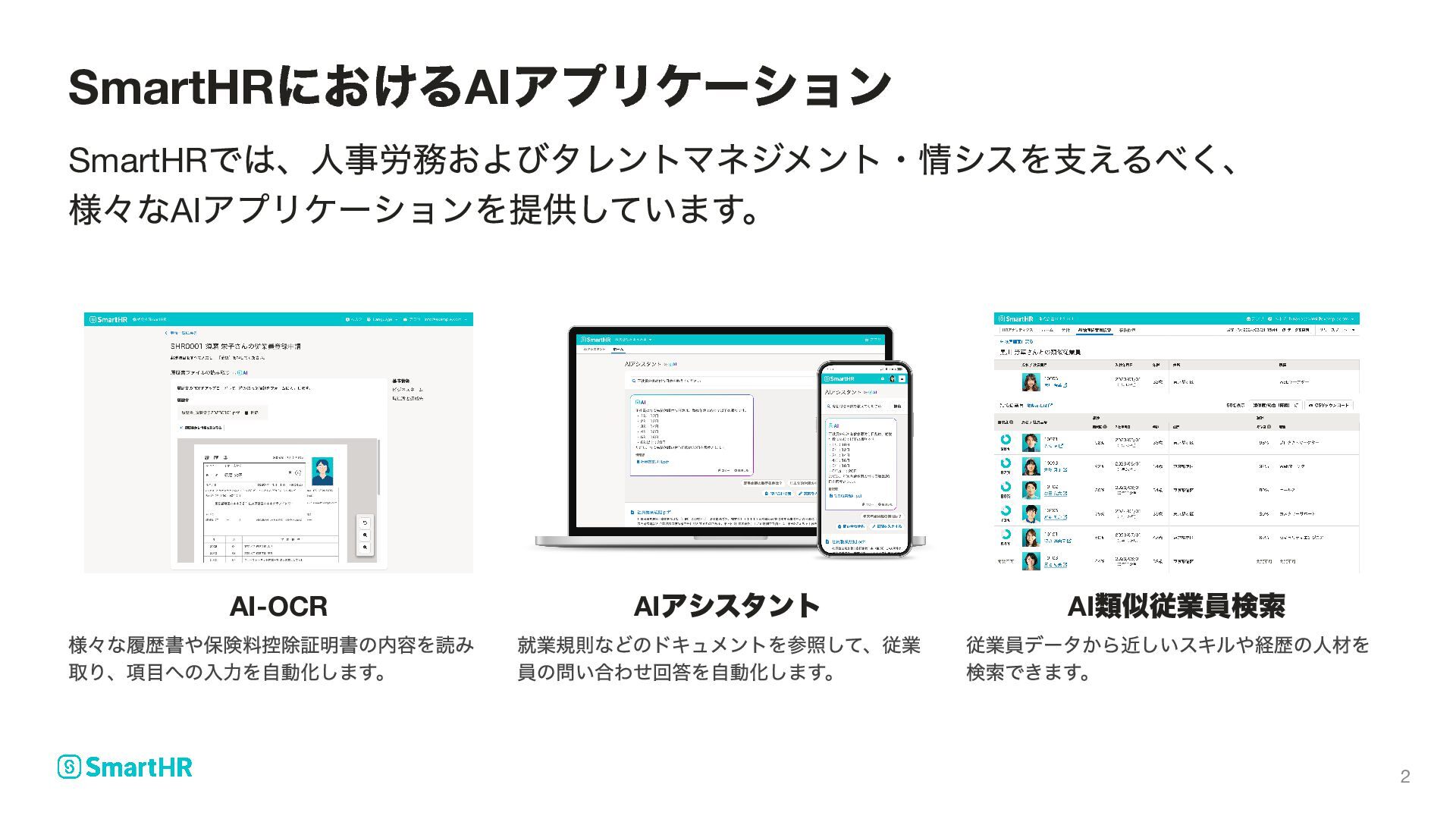{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}