Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[IR Reading 2021秋 論文紹介] Fairness among New Item...
Search
Kohei Shinden
PRO
October 30, 2021
Research
190
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[IR Reading 2021秋 論文紹介] Fairness among New Items in Cold Start Recommender Systems (SIGIR 2021) /IR-Reading-2022-Fall
https://sigirtokyo.github.io/post/2021-10-30-irreading_2021fall/
Kohei Shinden
PRO
October 30, 2021
More Decks by Kohei Shinden
See All by Kohei Shinden
[IR Reading 2026春 論文紹介] LLM-based Listwise Reranking under the Effect of Positional Bias (ECIR 2026) /IR-Reading-2026-Spring
koheishinden
PRO
0
220
[IR Reading 2023秋 論文紹介] On the Impact of Outlier Bias on User Clicks (SIGIR 2023) /IR-Reading-2023-Fall
koheishinden
PRO
0
200
[IR Reading 2023春 論文紹介] A Unified Framework for Learned Sparse Retrieval (ECIR 2023) /IR-Reading-2023-Spring
koheishinden
PRO
0
190
[IR Reading 2022秋 論文紹介] Price DOES Matter!: Modeling Price and Interest Preferences in Session-based Recommendation (SIGIR 2022) /IR-Reading-2022-Fall
koheishinden
PRO
0
190
[ACM SIGMOD-J 79] The Web Conference 2022 国際会議報告 Security セッション /ACM-SIGMOD-J-79-The-Web-Conf-2022
koheishinden
PRO
0
190
[IR Reading 2022春 論文紹介] Personalized Transfer of User Preferences for Cross-domain Recommendation (WSDM 2022) /IR-Reading-2022-Spring
koheishinden
PRO
0
190
[IR Reading 2021春 論文紹介] Investigating the Influence of Ads on User Search Performance, Behaviour, and Experience during Information Seeking (CHIIR 2021) /IR-Reading-2021-Spring
koheishinden
PRO
0
190
Other Decks in Research
See All in Research
「AIとWhyを深堀る」をAIと深堀る
iflection
0
520
2026年度 生成AI を活用した論文執筆ガイド/ワークショップ / 2026 Academic Year Guide to Writing Papers Using Generative AI - Workshop
ks91
PRO
0
190
PGDM: Physically Guided Diffusion Model for L Downscaling
satai
3
350
言語モデルから言語について語る際に押さえておきたいこと
eumesy
PRO
6
2.5k
SAKURAONE: An Open Ethernet-based AI HPC System And Its Observed Workload Dynamics in a Single-Tenant LLM Development Environment
yuukit
1
450
Sequences of Logits Reveal the Low Rank Structure of Language Models
sansantech
PRO
1
280
老舗ものづくり企業でリサーチが変革を起こすまで - 三菱重工DXの実践
skydats
0
220
SOTAのさらに先へ:厳しい推論制約下での高性能モデルのPost-Training
analokmaus
0
1.3k
CVPR2026論文紹介_VLMにとって良いvision encoderとは何か?Rethinking Model Selection in VLM Through the Lens of Gromov-Wasserstein Distance
kobayashi31
1
170
AIで最適化を解けるか?
mickey_kubo
0
140
2026年3月1日(日)福島「除染土」の公共利用をかんがえる
atsukomasano2026
0
660
コーディングエージェントとABNを再考
hf149
2
760
Featured
See All Featured
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Faster Mobile Websites
deanohume
310
32k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
A designer walks into a library…
pauljervisheath
211
24k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.8k
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
How STYLIGHT went responsive
nonsquared
100
6.2k
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
The Illustrated Children's Guide to Kubernetes
chrisshort
51
53k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
310
Transcript
[論⽂紹介] Fairness among New Items in Cold Start Recommender Systems
Ziwei Zhu1, Jingu Kim2, Trung Nguyen2, Aish Fenton2, James Caverlee1 1 Texas A&M University, 2 Netflix SIGIR 2021 論⽂紹介する⼈ 筑波⼤学加藤研究室 新⽥洸平 https://sites.google.com/view/kohei-shinden ※スライド中の図は論⽂より引⽤ 2021年10⽉30⽇ IR Reading 2021 秋 セッション 2 No.2
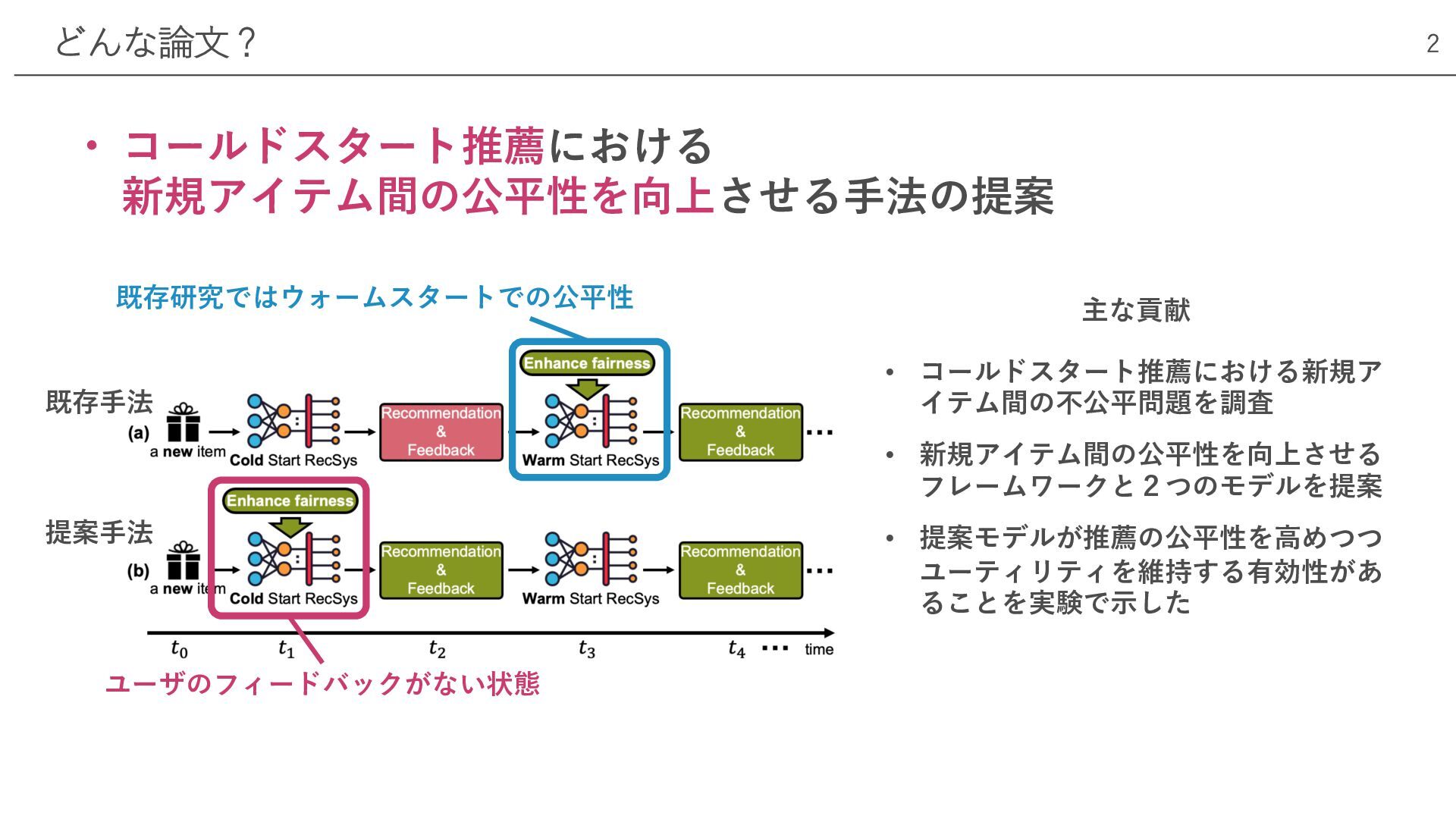
• コールドスタート推薦における 新規アイテム間の公平性を向上させる⼿法の提案 どんな論⽂? 2 既存研究ではウォームスタートでの公平性 既存⼿法 提案⼿法 主な貢献 •
コールドスタート推薦における新規ア イテム間の不公平問題を調査 • 新規アイテム間の公平性を向上させる フレームワークと2つのモデルを提案 • 提案モデルが推薦の公平性を⾼めつつ ユーティリティを維持する有効性があ ることを実験で⽰した ユーザのフィードバックがない状態
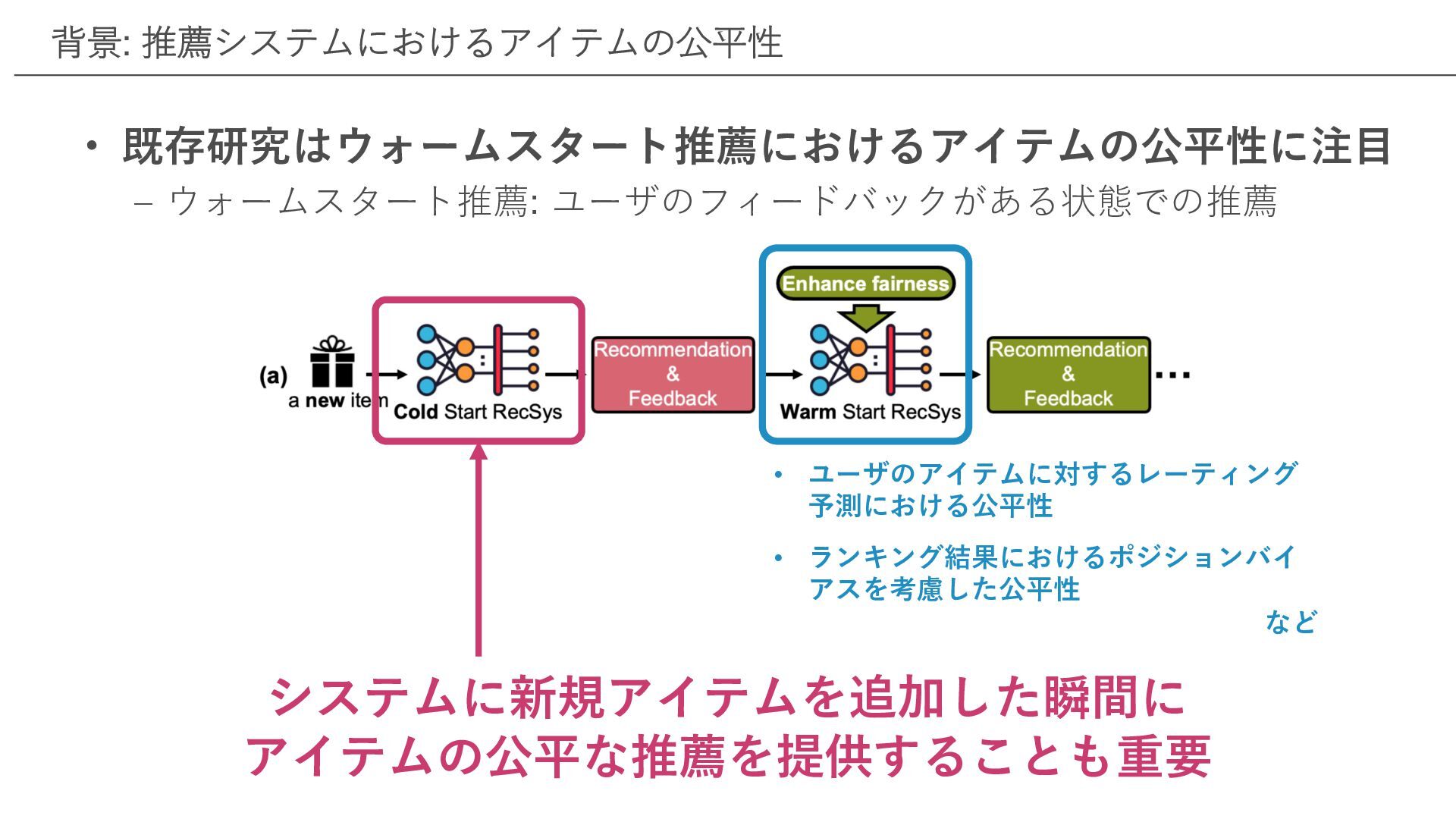
システムに新規アイテムを追加した瞬間に アイテムの公平な推薦を提供することも重要 背景: 推薦システムにおけるアイテムの公平性 • 既存研究はウォームスタート推薦におけるアイテムの公平性に注⽬ ‒ ウォームスタート推薦: ユーザのフィードバックがある状態での推薦 •
ユーザのアイテムに対するレーティング 予測における公平性 • ランキング結果におけるポジションバイ アスを考慮した公平性 など
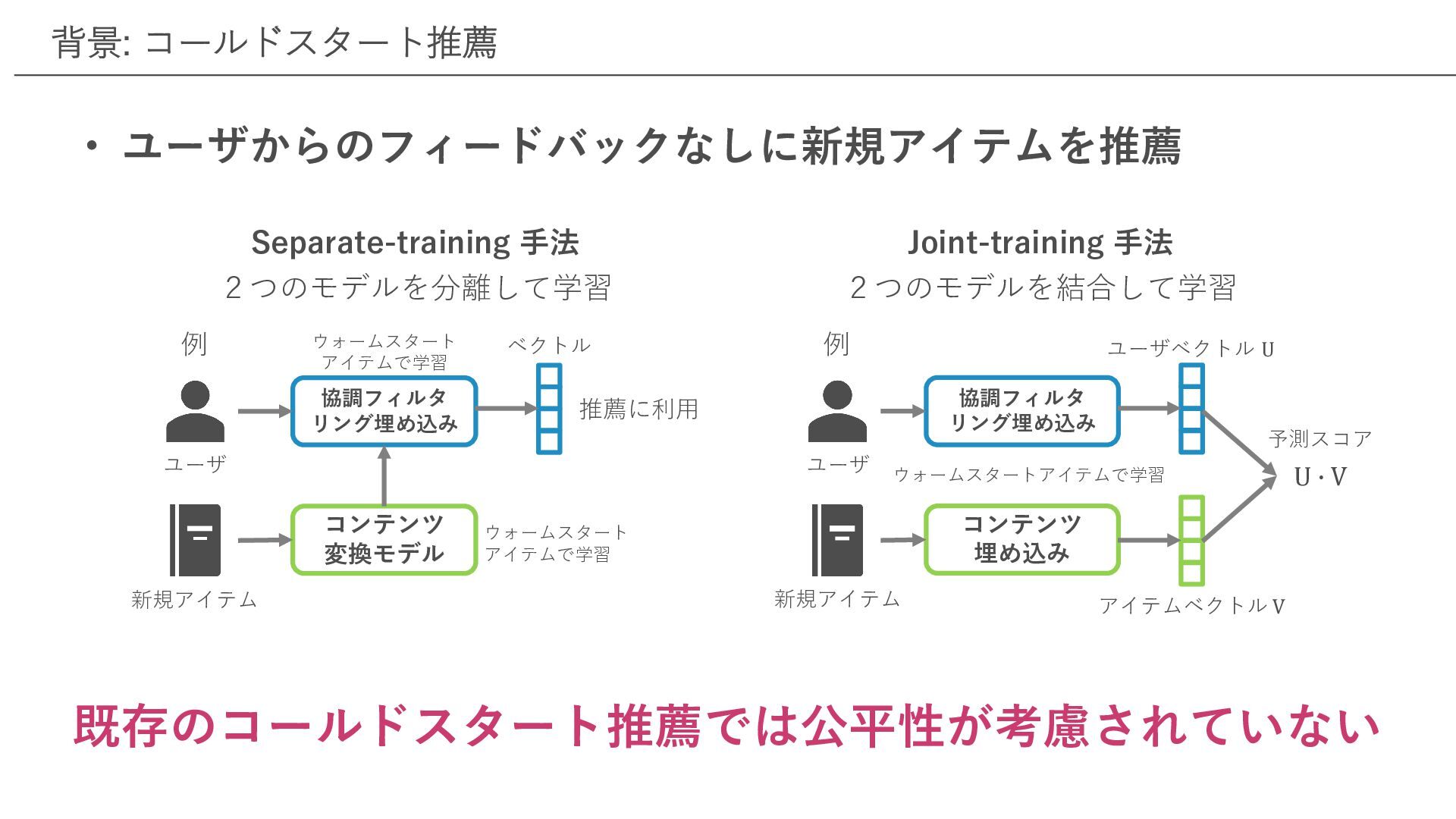
既存のコールドスタート推薦では公平性が考慮されていない 背景: コールドスタート推薦 • ユーザからのフィードバックなしに新規アイテムを推薦 Separate-training ⼿法 2つのモデルを分離して学習 Joint-training ⼿法
2つのモデルを結合して学習 協調フィルタ リング埋め込み コンテンツ 埋め込み U " V ユーザベクトル U アイテムベクトル V 新規アイテム ユーザ ウォームスタートアイテムで学習 協調フィルタ リング埋め込み コンテンツ 変換モデル ベクトル 新規アイテム ユーザ ウォームスタート アイテムで学習 推薦に利⽤ 予測スコア 例 例 ウォームスタート アイテムで学習
コールドスタート推薦における公平性を⾼める⼿法の提案 具体的な内容 • コールドスタート推薦における新規アイテムの不公平について調査 ‒ 既存のコールドスタート推薦ではアイテムが不公平に扱われている • 新規アイテム間の公平性を向上させる後処理フレームワーク,具体 的な2つのモデルを提案 •
提案⼿法が公平性を向上させて推薦のユーティリティを維持する有 効性を実験で⽰した ⽬的と研究内容 5
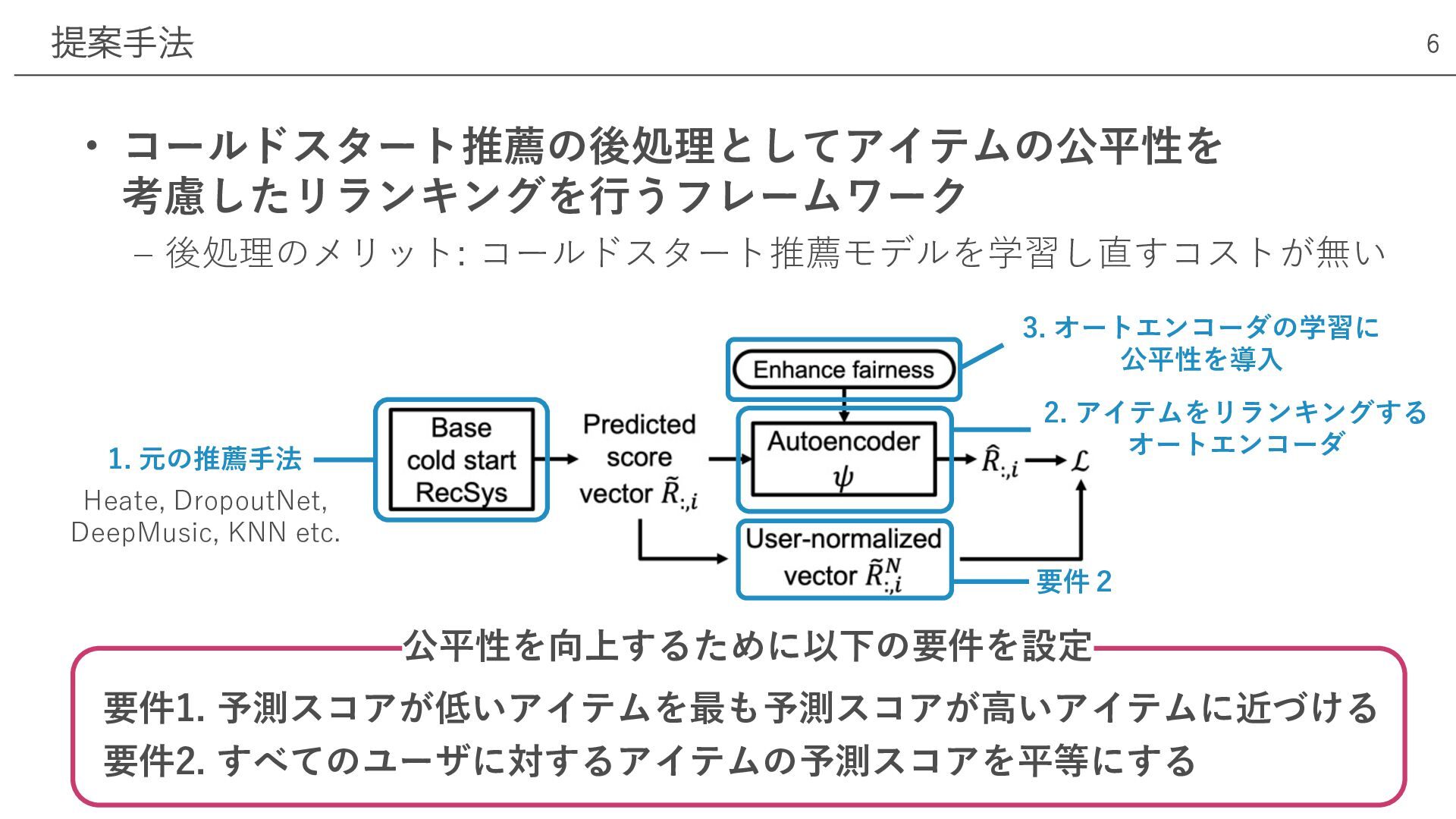
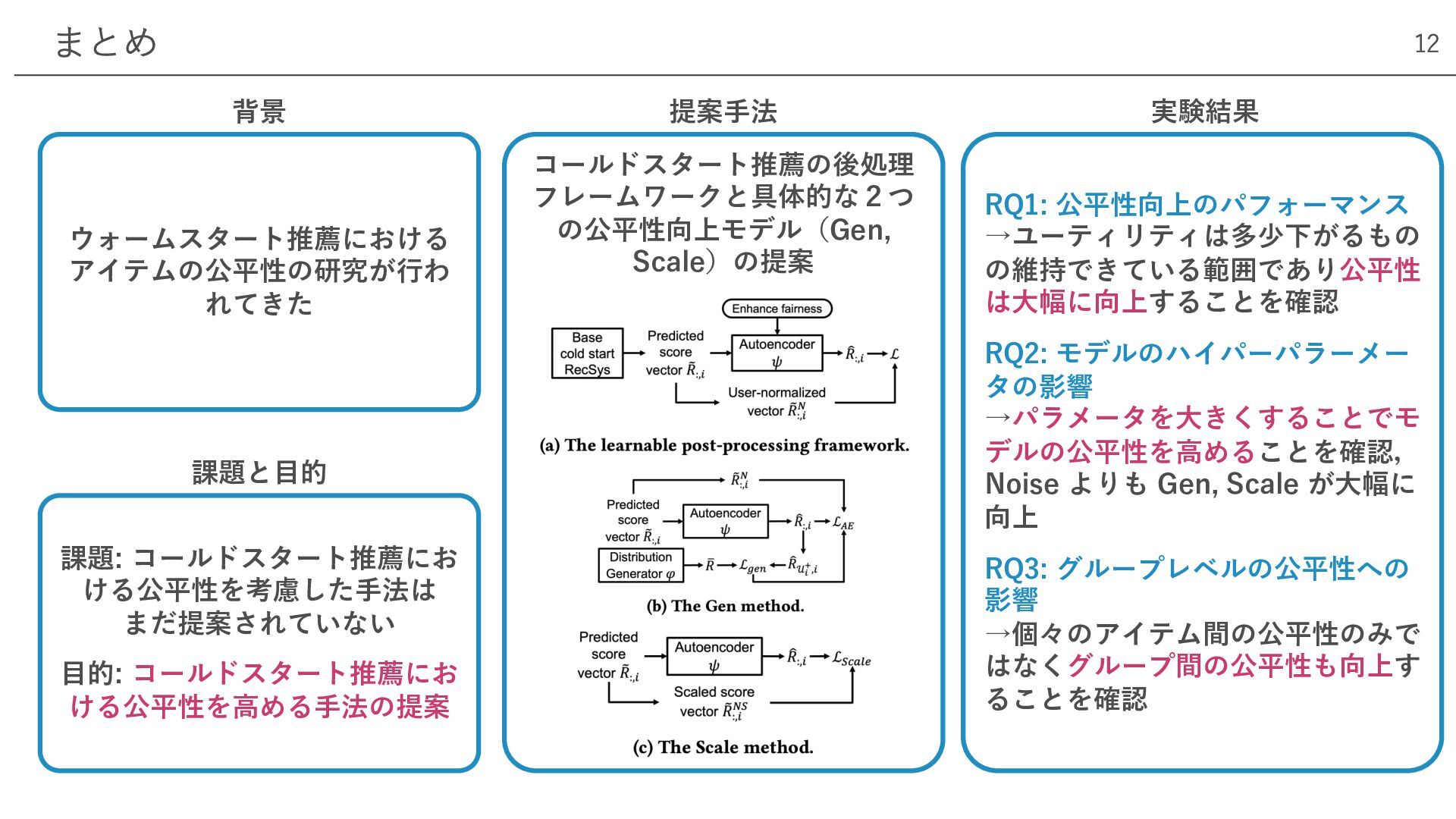
• コールドスタート推薦の後処理としてアイテムの公平性を 考慮したリランキングを⾏うフレームワーク ‒ 後処理のメリット: コールドスタート推薦モデルを学習し直すコストが無い 提案⼿法 6 Heate, DropoutNet,
DeepMusic, KNN etc. 1. 元の推薦⼿法 2. アイテムをリランキングする オートエンコーダ 3. オートエンコーダの学習に 公平性を導⼊ 要件2 公平性を向上するために以下の要件を設定 要件1. 予測スコアが低いアイテムを最も予測スコアが⾼いアイテムに近づける 要件2. すべてのユーザに対するアイテムの予測スコアを平等にする
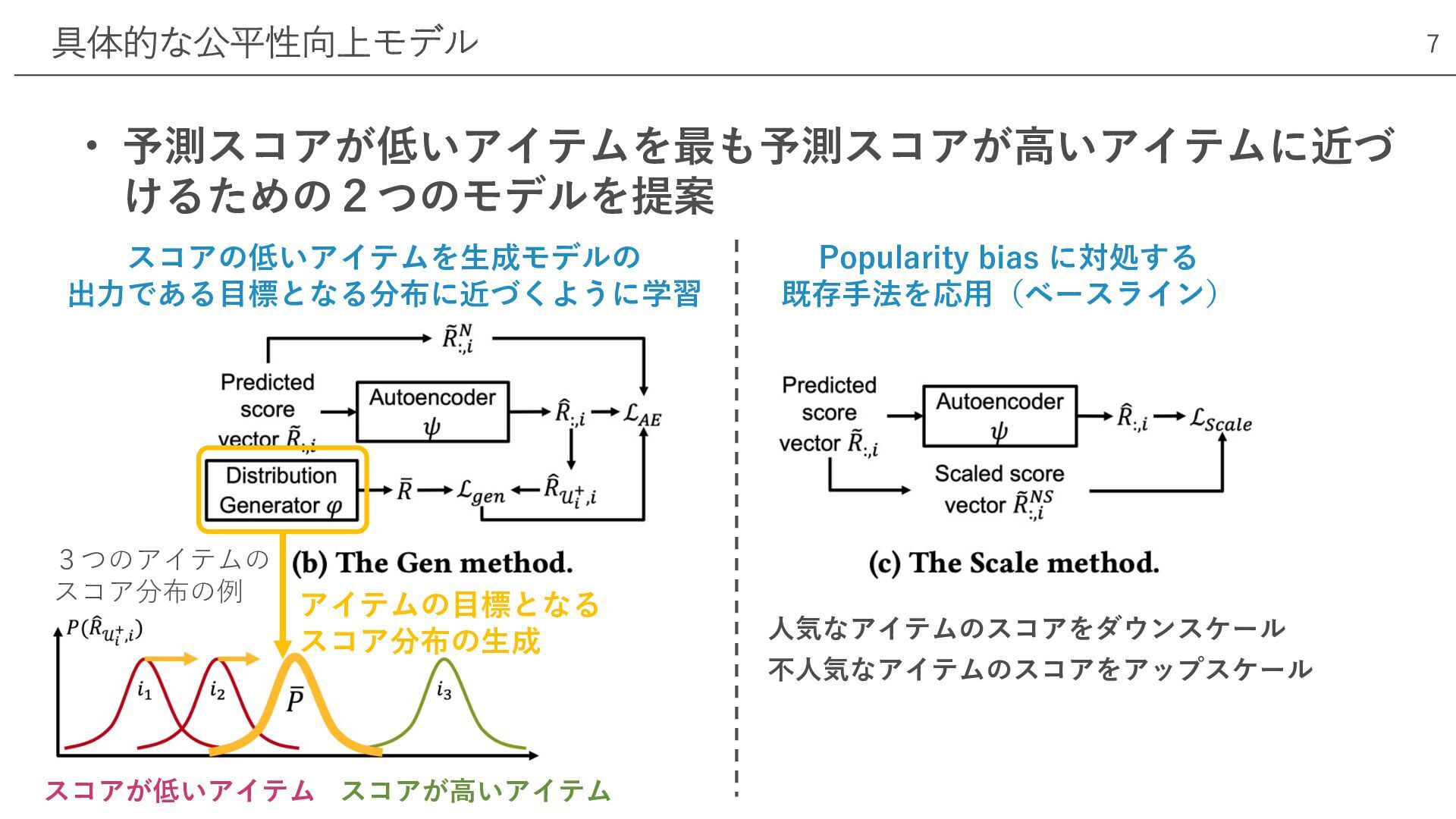
• 予測スコアが低いアイテムを最も予測スコアが⾼いアイテムに近づ けるための2つのモデルを提案 具体的な公平性向上モデル 7 アイテムの⽬標となる スコア分布の⽣成 3つのアイテムの スコア分布の例 スコアが低いアイテム
スコアが⾼いアイテム スコアの低いアイテムを⽣成モデルの 出⼒である⽬標となる分布に近づくように学習 Popularity bias に対処する 既存⼿法を応⽤(ベースライン) ⼈気なアイテムのスコアをダウンスケール 不⼈気なアイテムのスコアをアップスケール
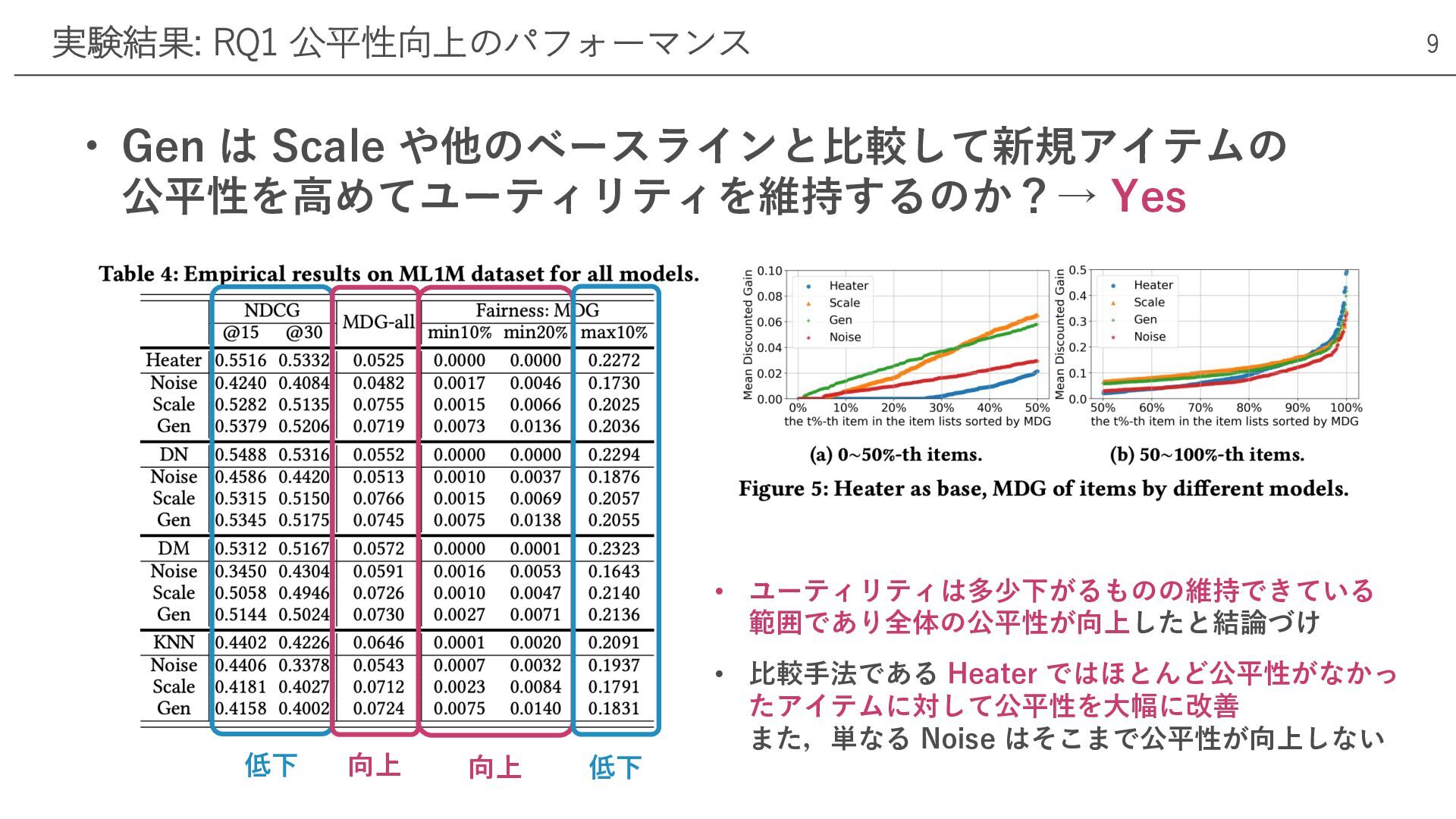
• RQ1: 公平性向上のパフォーマンス, RQ2: モデルのハイパーパラーメータの影響, RQ3: グループレベルの公平性への影響について検証 • 評価指標: nDCG,
MDG(MDG-min10%, MDG-min20%, MDG-max10%) • データセット: ML1M, ML20M, CiteULike, XING • ベースライン: Heter, DropoutNet, DeepMusic, KNN, Scale(提案⼿法), Noise(ランダムノイズを加える⼿法) • 再現性: https://github.com/Zziwei/Fairness-in-Cold-Start-Recommendation 実験内容 8 𝜹(𝒙): 𝒙 が真であれば 𝟏, 違えば 𝟎 𝑀𝐷𝐺𝒊 = 0: アイテムがマッチした全てのユーザに推薦されない 𝑀𝐷𝐺𝒊 = 1: アイテムがマッチした全てのユーザに1位で推薦される 新規アイテムの真の陽性率を計算,評価値が⼤きいほどシステムがより公平であることを⽰す
• Gen は Scale や他のベースラインと⽐較して新規アイテムの 公平性を⾼めてユーティリティを維持するのか?→ Yes 実験結果: RQ1 公平性向上のパフォーマンス
9 低下 向上 向上 低下 • ユーティリティは多少下がるものの維持できている 範囲であり全体の公平性が向上したと結論づけ • ⽐較⼿法である Heater ではほとんど公平性がなかっ たアイテムに対して公平性を⼤幅に改善 また,単なる Noise はそこまで公平性が向上しない
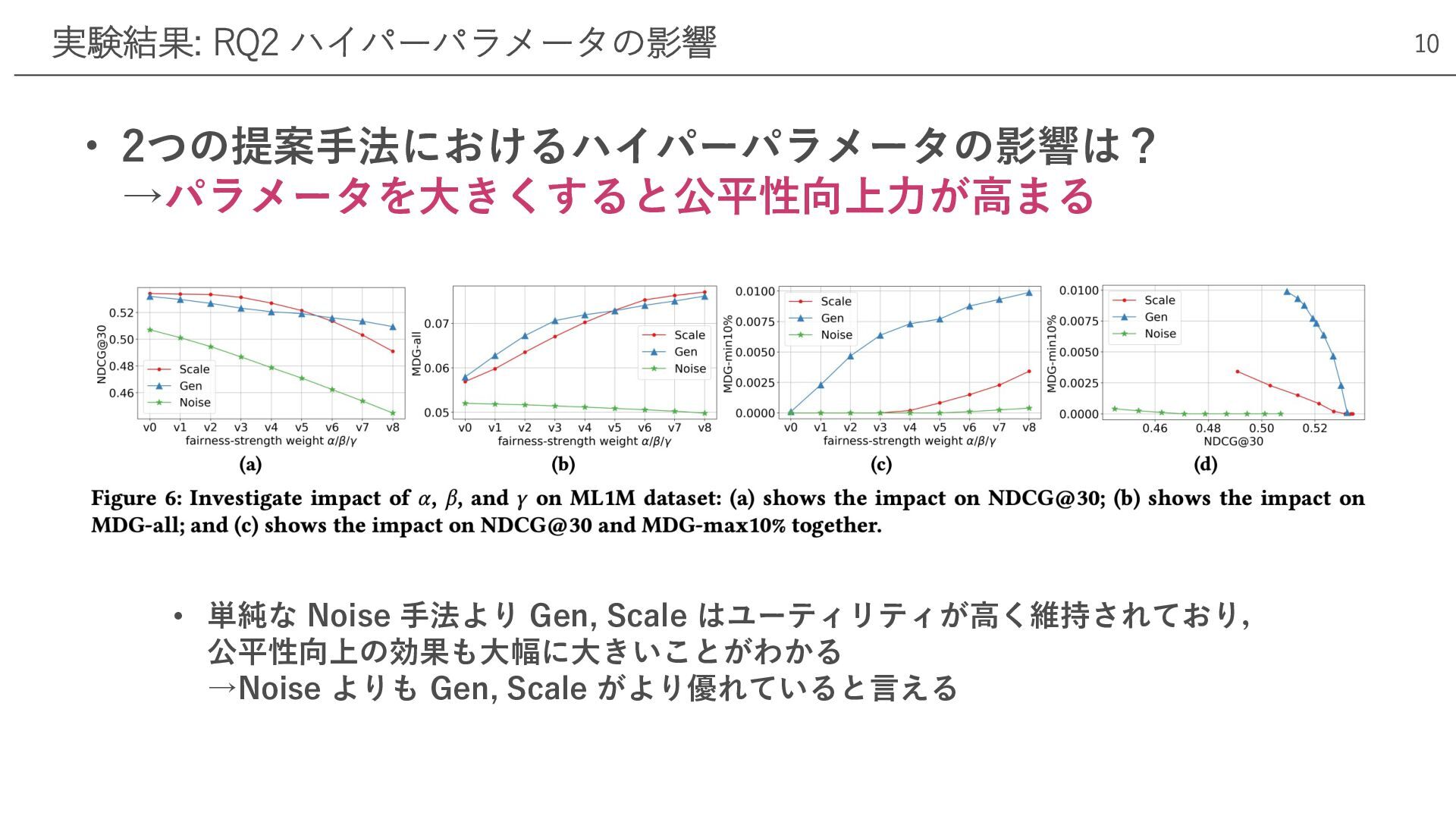
• 2つの提案⼿法におけるハイパーパラメータの影響は? →パラメータを⼤きくすると公平性向上⼒が⾼まる 実験結果: RQ2 ハイパーパラメータの影響 10 • 単純な Noise
⼿法より Gen, Scale はユーティリティが⾼く維持されており, 公平性向上の効果も⼤幅に⼤きいことがわかる →Noise よりも Gen, Scale がより優れていると⾔える
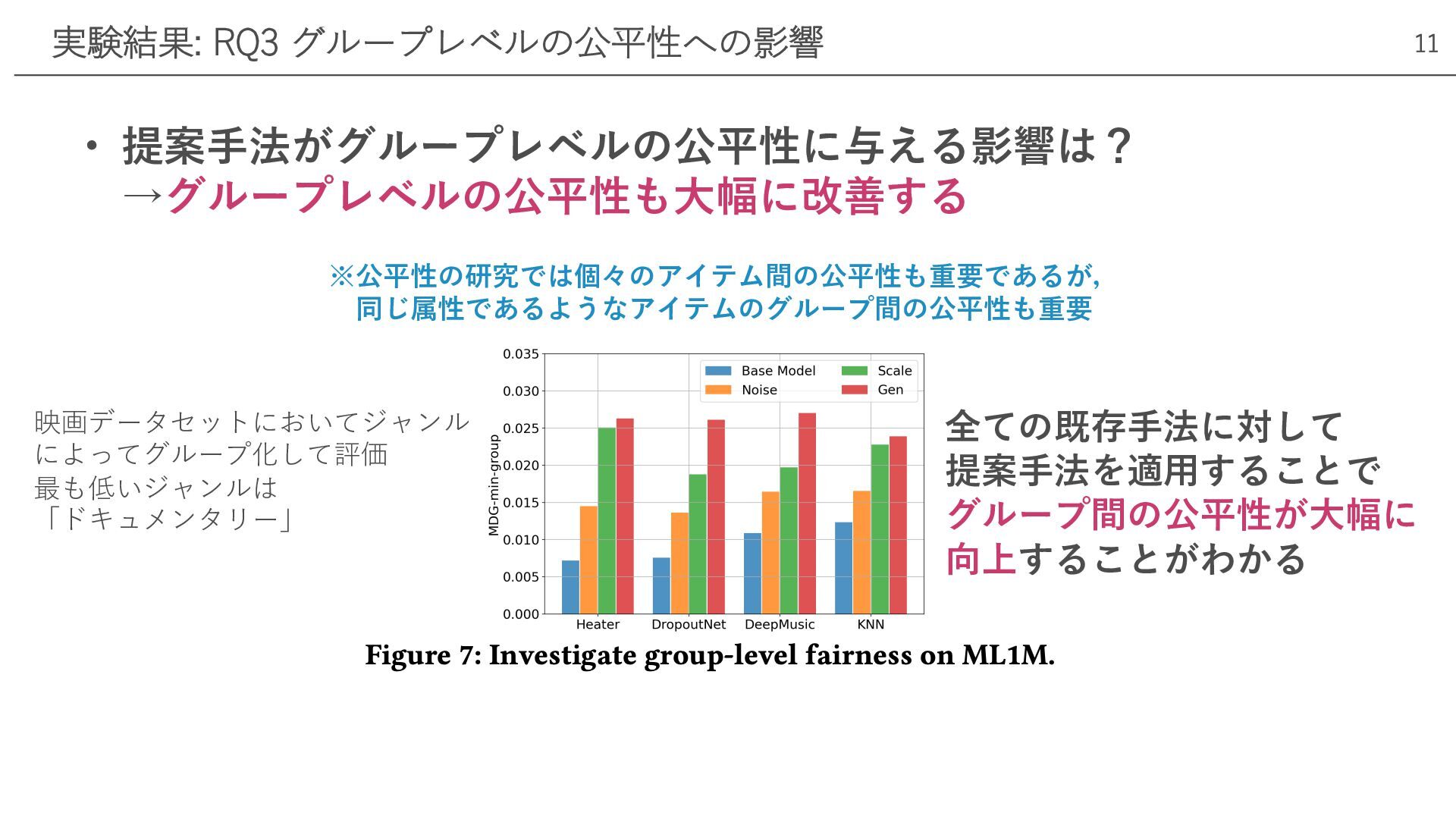
• 提案⼿法がグループレベルの公平性に与える影響は? →グループレベルの公平性も⼤幅に改善する 実験結果: RQ3 グループレベルの公平性への影響 11 ※公平性の研究では個々のアイテム間の公平性も重要であるが, 同じ属性であるようなアイテムのグループ間の公平性も重要 映画データセットにおいてジャンル
によってグループ化して評価 最も低いジャンルは 「ドキュメンタリー」 全ての既存⼿法に対して 提案⼿法を適⽤することで グループ間の公平性が⼤幅に 向上することがわかる
まとめ 12 ウォームスタート推薦における アイテムの公平性の研究が⾏わ れてきた 課題: コールドスタート推薦にお ける公平性を考慮した⼿法は まだ提案されていない ⽬的:
コールドスタート推薦にお ける公平性を⾼める⼿法の提案 コールドスタート推薦の後処理 フレームワークと具体的な2つ の公平性向上モデル(Gen, Scale)の提案 RQ1: 公平性向上のパフォーマンス →ユーティリティは多少下がるもの の維持できている範囲であり公平性 は⼤幅に向上することを確認 RQ2: モデルのハイパーパラーメー タの影響 →パラメータを⼤きくすることでモ デルの公平性を⾼めることを確認, Noise よりも Gen, Scale が⼤幅に 向上 RQ3: グループレベルの公平性への 影響 →個々のアイテム間の公平性のみで はなくグループ間の公平性も向上す ることを確認 背景 課題と⽬的 提案⼿法 実験結果
Appendix 13
• Gen は Scale や他のベースラインと⽐較して新規アイテムの公平 性をどのように⾼めてユーティリティを維持するのか? 実験結果: RQ1 公平性向上のパフォーマンス 14
低下 向上 向上 低下 • 4つのデータセットを利⽤した実験でも ユーティリティは多少下がるものの維持 できている範囲であり全体の公平性が向上
![[論⽂紹介] Fairness among New Items in Cold Start Recommender Systems](https://files.speakerdeck.com/presentations/e42169b63a034a1d91ef8a1ac036e6e7/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}