(Zhu et al., 2010) ◦ train 89,042 pair ◦ dev 205 pair ◦ test 100 pair • English Wikipedia and Simple English Wikipedia (EW-SEW) (Hwang et al.2015) ◦ train 280,000 pair ◦ dev 2000 pair ◦ test 359 pair
2002) ◦ PWKP single reference ◦ EW-SEW multi reference • Human evaluation. (1 is very bad, 5 is very good) ◦ Fluency(流暢性) 1 ~ 5 ◦ Adequacy(妥当性)1 ~ 5 ◦ Simplicity(簡潔性) 1 ~ 5
Media Short Text Summarization Dataset(LCSTS) 2,400,000文ペア • Part1 2,400,591ペア train • Part2 8,685ぺア validation • Part3 725ペア test Part2とPart3は1~5で自動評価されていて、スコア3以上のものを選択
{kind=link}
{kind=link}
{kind=link}
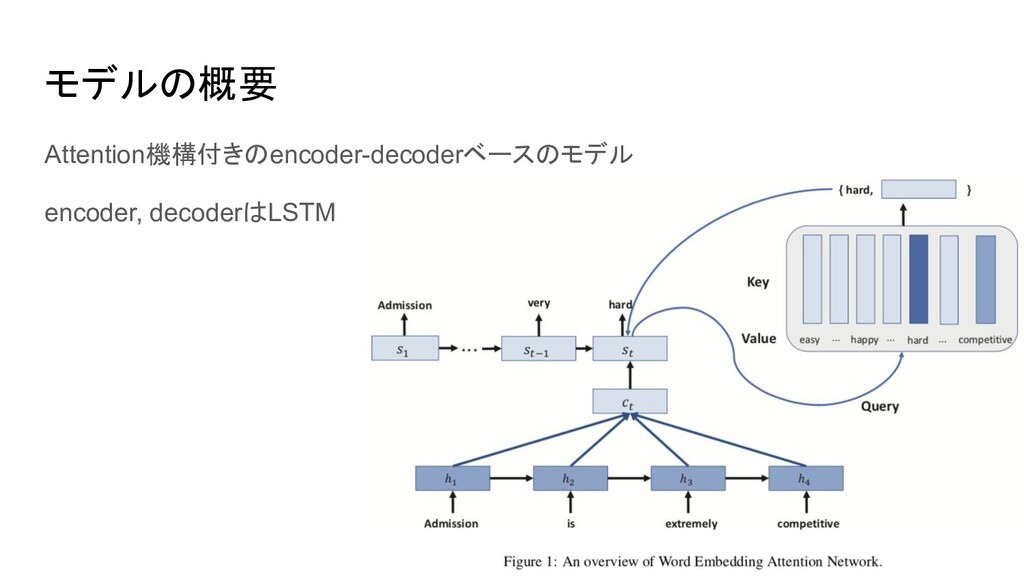{kind=link}
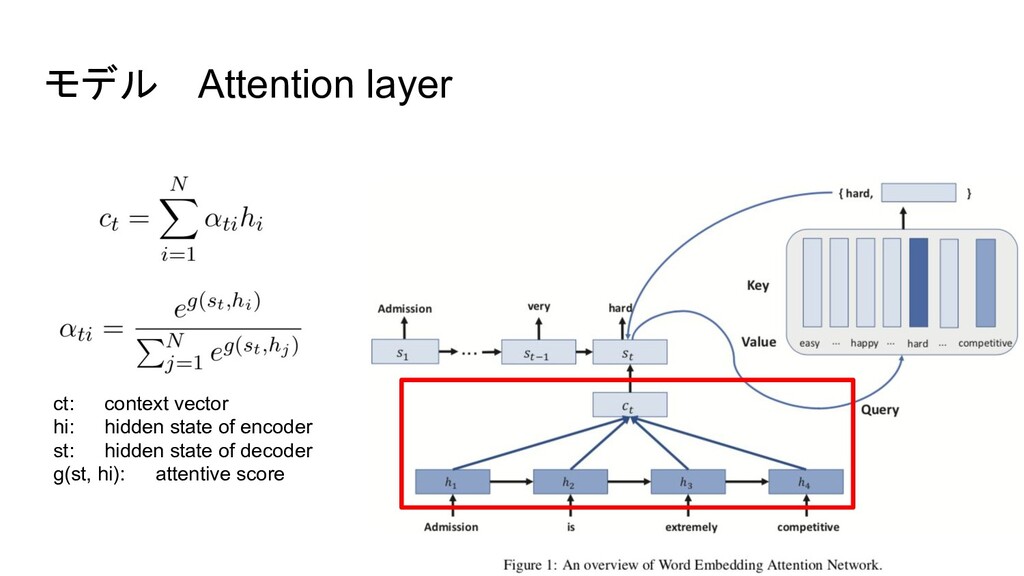{kind=link}
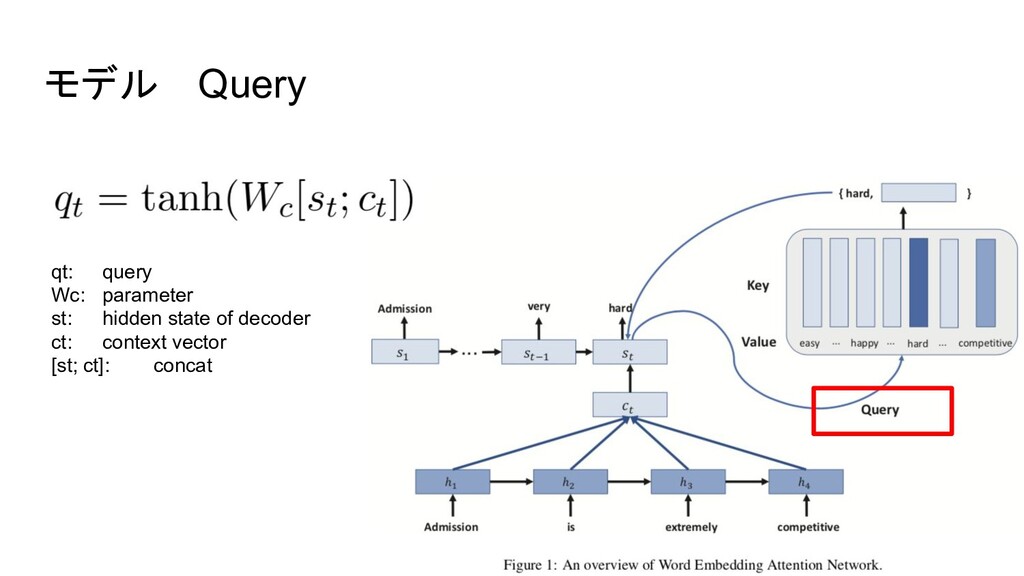{kind=link}
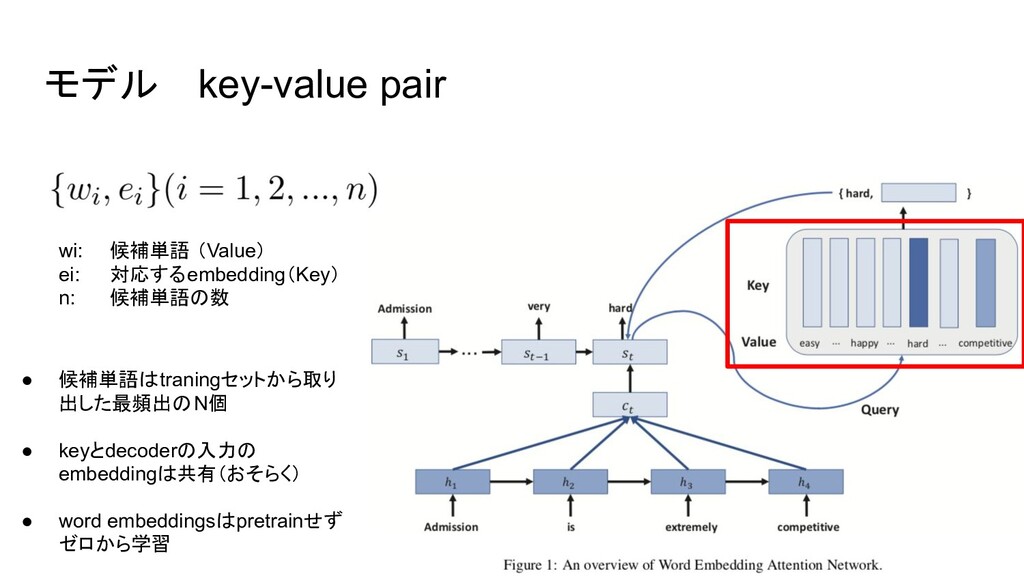{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}