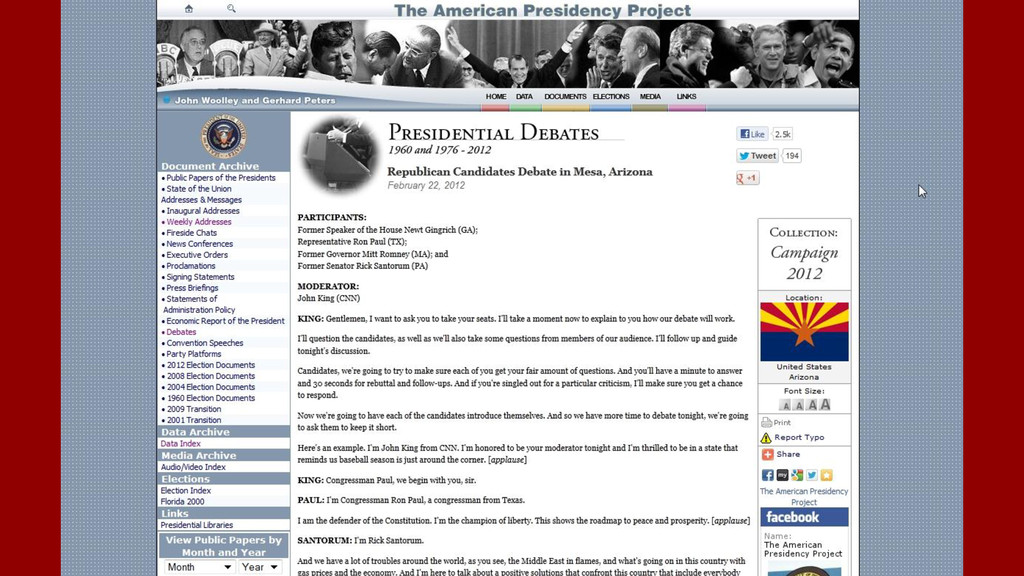
There are loads of places to find data – open government data at many levels, publicly released data from companies, and researched data from organizations. Ideally, these sources would be provided as web services. However, often they are a mish-mash of Excel or other loosely structured files, HTML tables, or even PDF documents.
It’s easy to become discouraged with so many obstacles to merely acquiring information for your app or site. Fortunately, there are many tools and techniques to help you gather, parse, and clean up data from a variety of sources.
This session will use a real-world example, Politilines, as an example. I will demonstrate how we found, gathered, parsed, and made sense of the public data needed for Politilines.
Presented at OSCON 2012.
![Digging into Open Data Kim Rees, Periscopic @krees, @periscopic [email protected]](https://files.speakerdeck.com/presentations/504a56f72fc8e100020156ee/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
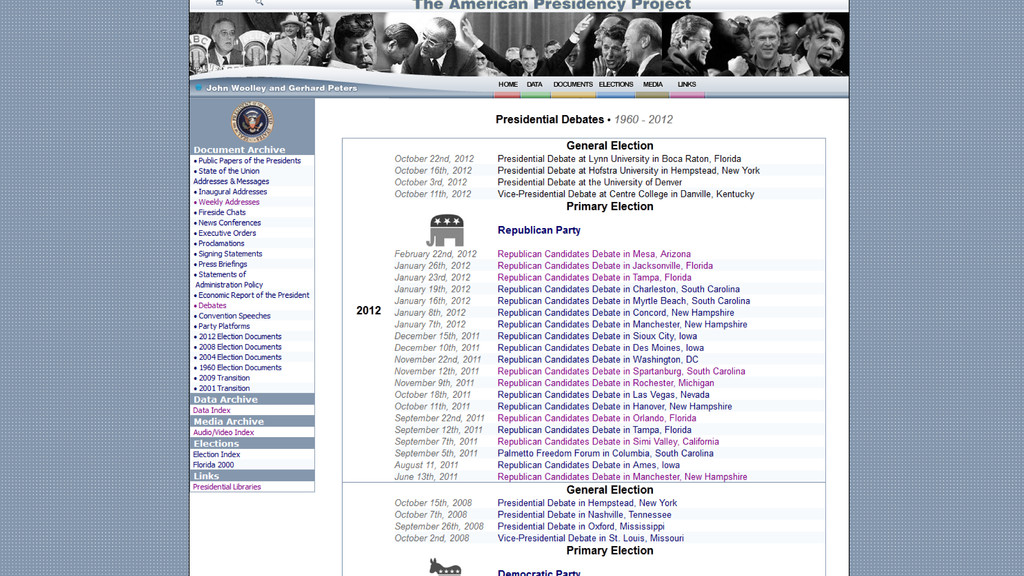{kind=link}
![import mechanize import re page_ids = [98936, 99001, 98929] #page](https://files.speakerdeck.com/presentations/504a56f72fc8e100020156ee/slide_16.jpg){kind=link}
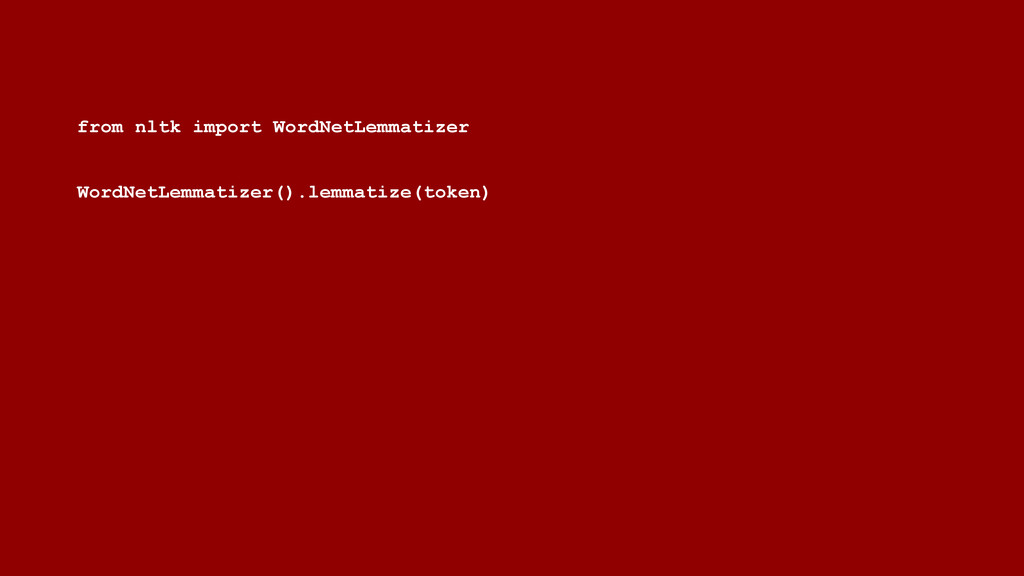{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Digging into Open Data Kim Rees, Periscopic @krees, @periscopic [email protected]](https://files.speakerdeck.com/presentations/504a56f72fc8e100020156ee/slide_22.jpg){kind=link}