'Vella', 'Melia', 'Noel', 'Terrence', 'Leigh', 'Rubin', 'Tanja', 'Shirlene', 'Deidre', 'Dorthy', 'Leighann', 'Mamie', 'Gabriella', 'Tanika', 'Kennith', 'Merilyn', 'Tonda', 'Adolfo', 'Von', 'Agnus', 'Kieth', 'Lisette', 'Hui', 'Lilliana',] CITIES = ['Washington', 'Springfield', 'Franklin', 'Greenville', 'Bristol', 'Fairview', 'Salem', 'Madison', 'Georgetown', 'Arlington', 'Ashland',] STATES = ['MO','SC','IN','CA','IA','DE','ID','AK','NE','VA','PR','IL','ND','OK','VT','DC','CO','MS', 'CT','ME','MN','NV','HI','MT','PA','SD','WA','NJ','NC','WV','AL','AR','FL','NM','KY','GA','MA', 'KS','VI','MI','UT','AZ','WI','RI','NY','TN','OH','TX','AS','MD','OR','MP','LA','WY','GU','NH'] PRODUCTS = ['Product 2', 'Product 2 XL', 'Product 3', 'Product 3 XL', 'Product 4', 'Product 4 XL', 'Product 5', 'Product 5 XL',]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
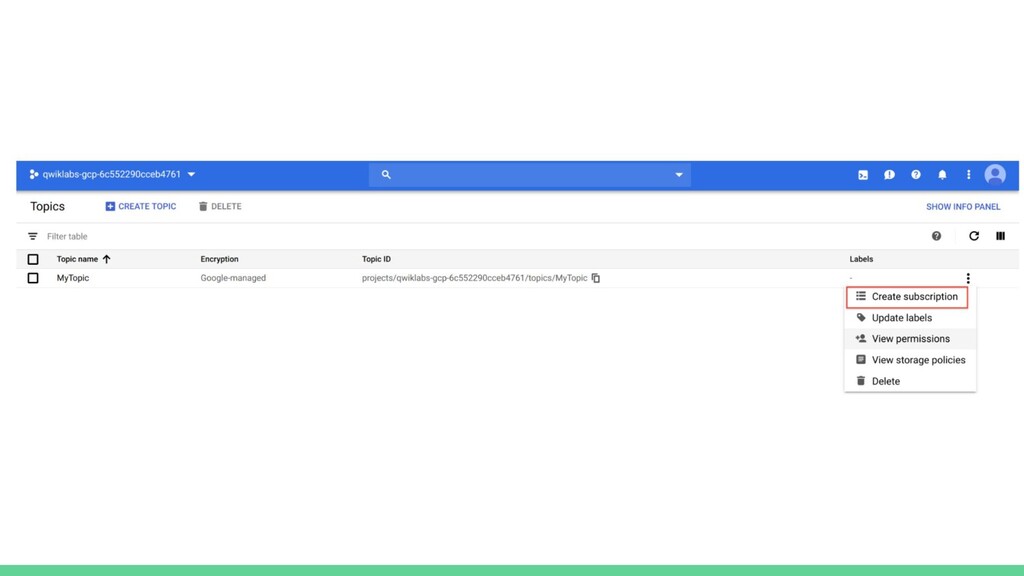{kind=link}
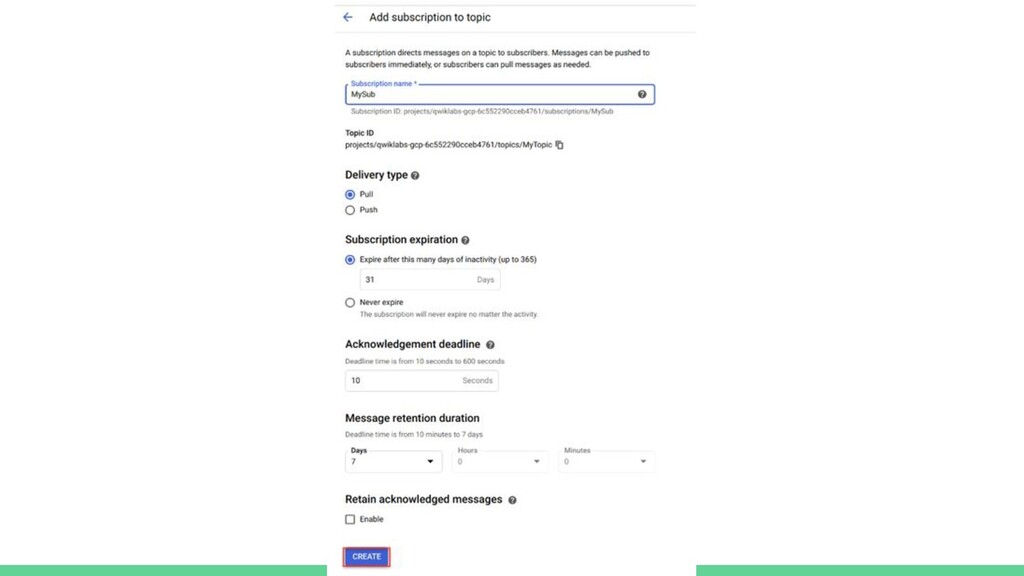{kind=link}
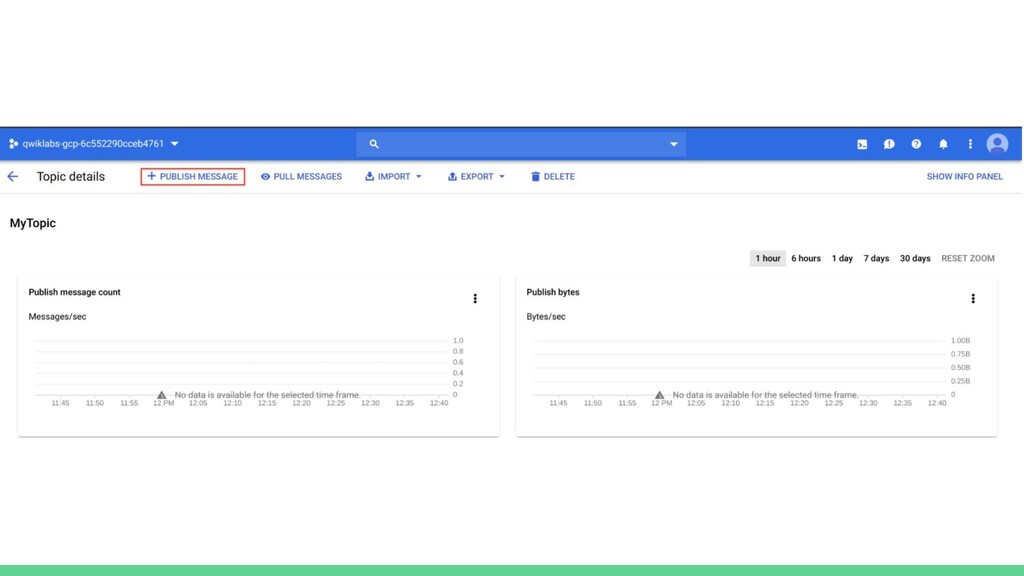{kind=link}
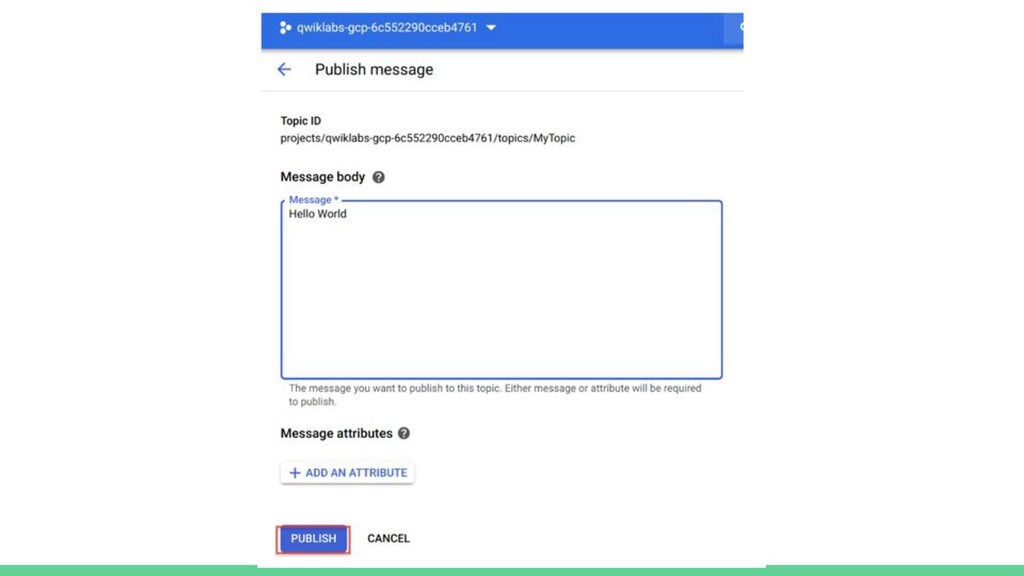{kind=link}
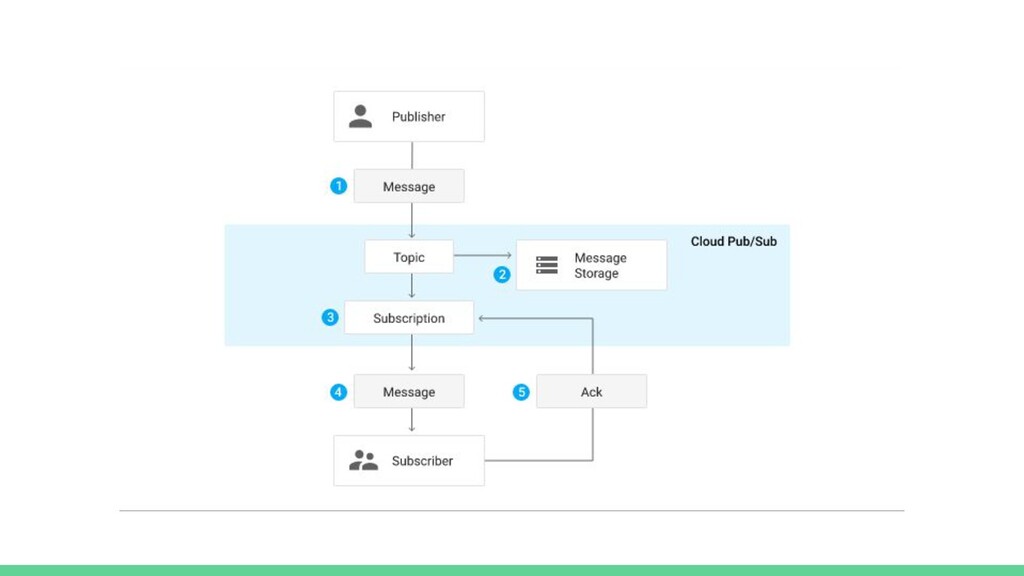{kind=link}
{kind=link}
{kind=link}
{kind=link}
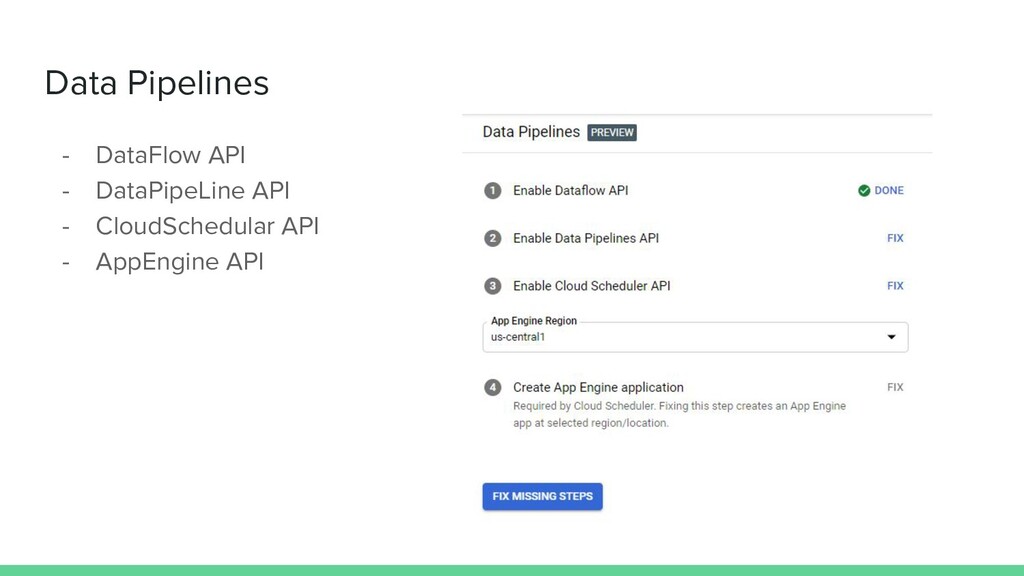{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
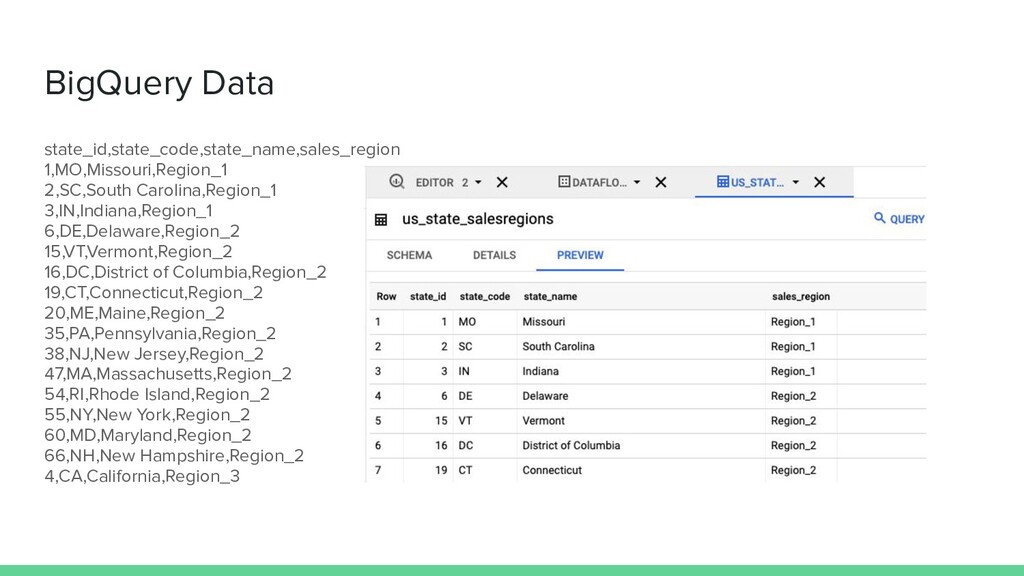{kind=link}
{kind=link}
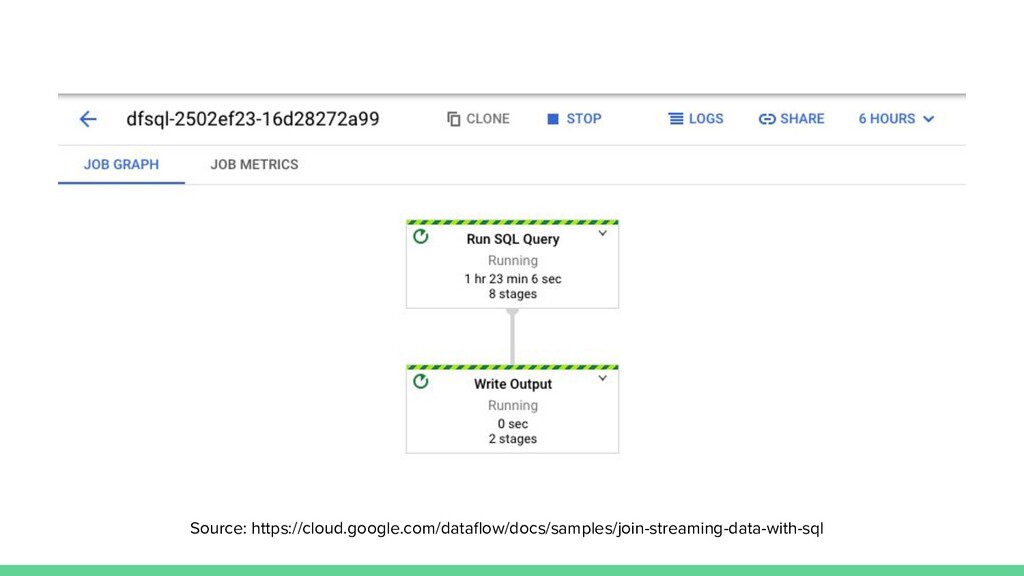{kind=link}
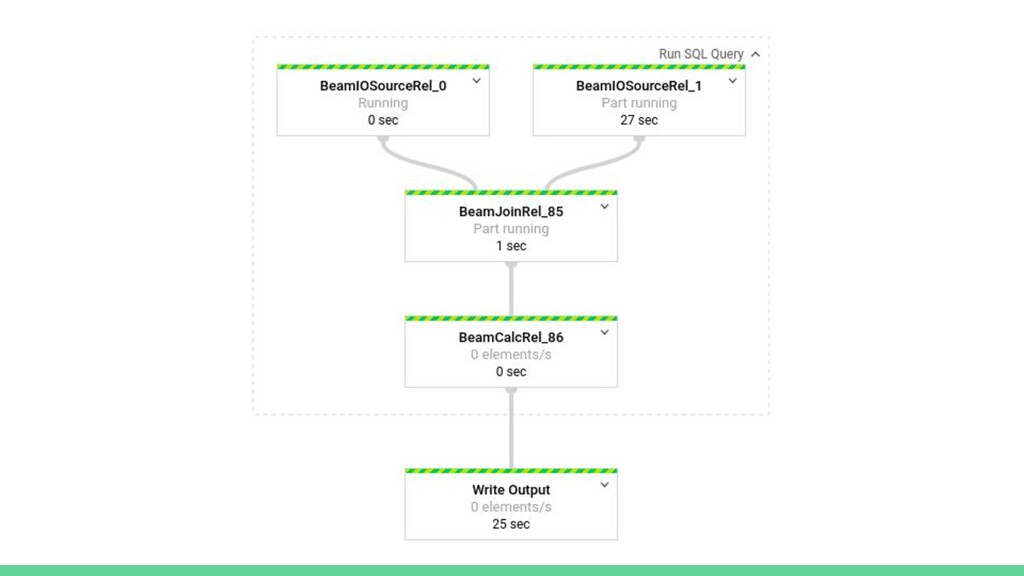{kind=link}
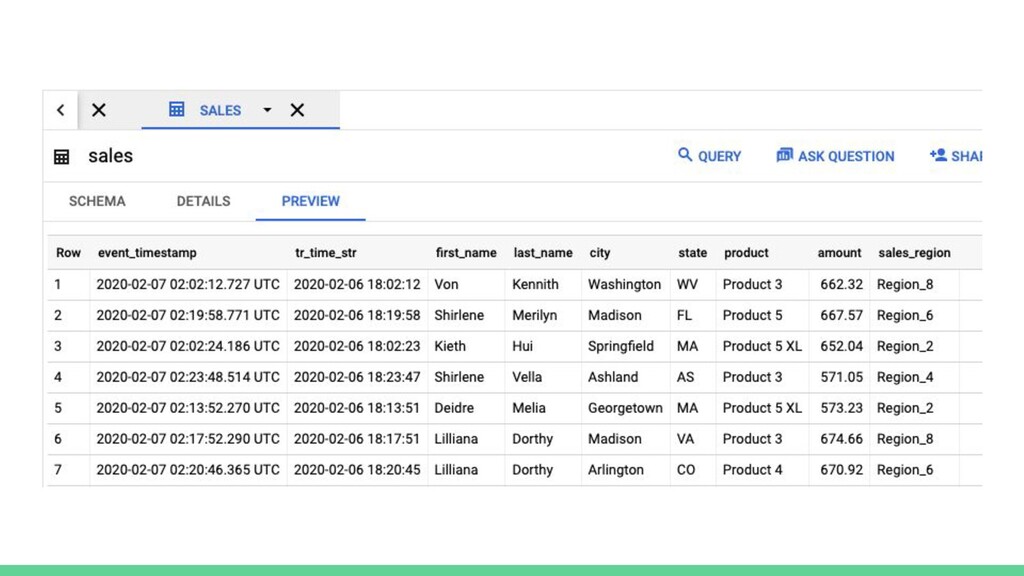{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}