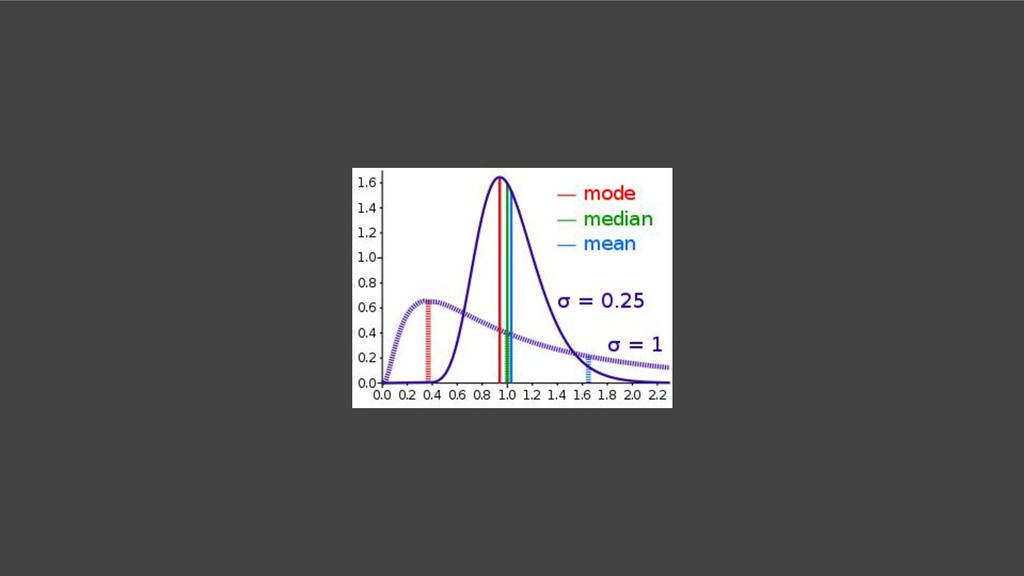
Median - Middle values - Mode - Mostly repeated value - Standard Deviation - How data is spread in the dataset https://docs.google.com/spreadsheets/d/1KuG47YaIv8xQBEasGeNpNu24dyUT06ADj_0yvK4S67g/edit#gid=0
computer science that gives computers the ability to learn without being explicitly programmed - Arthur Samuel, 1959 - Wikipedia Machine learning is about the construction and study of systems that can learn from data. - Freebase
requires high precision, e.g. Spam filter - If false positives are ok, requires high recall, e.g. Medical Diagnosis Precision Recall F-1 Score Accuracy Accuracy = Ratio of correctly classified points / total points
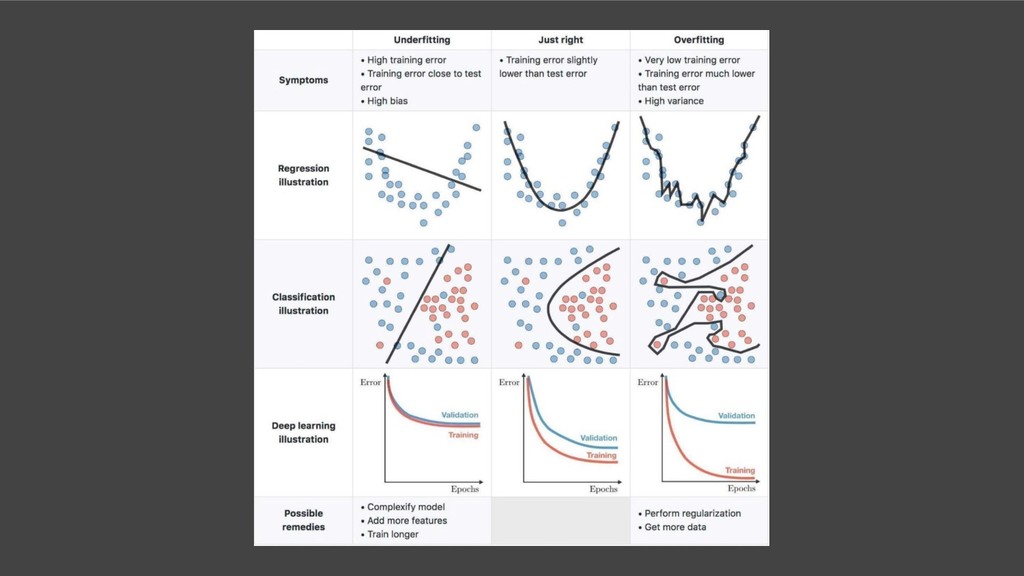
Write down columns and it’s correlation 3. Make questions derived from the dataset 4. Explanatory Analysis with visualization 5. Frame problem 6. Create solution by creating model
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![- Numpy (Numeric Python) - List [‘Hello’, ‘GDG’, ‘Baroda’] -](https://files.speakerdeck.com/presentations/a67ac333fd5747b1b4335c779b9dbb66/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}