This is presentation is to understand the basic terms that are used in ML. I covered the most frequently used topics.
#UFest18 #IndiaMLCC #UFestIndia2018
all predictions - Box plot - displays range of variations in data - Backpropagation - update weights reduce errors - Batches - small chunks and splitted data - Batch normalization - improve performance and stability of DNN 16
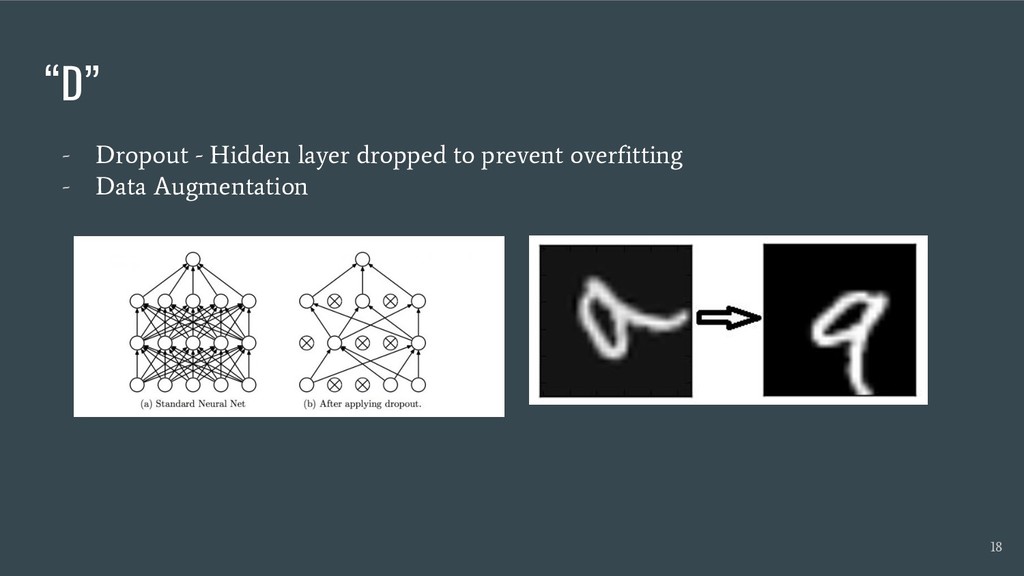
graph execution - Epochs - single training iteration - Early stopping - prevent overfitting “F” - Forward propagation - only one way input to output, no backward 19
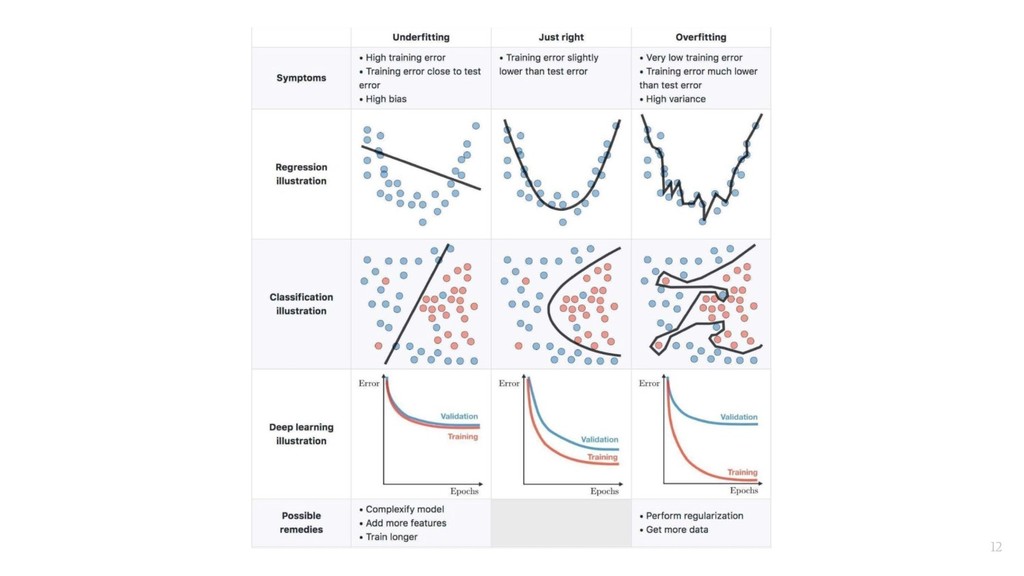
for previously unseen data - Difference between expected and proven error - Mostly occurs in deep learning model, training sets working fine, but not fitting in real data 21
requires high precision, e.g. Spam filter - If false positives are ok, requires high recall, e.g. Medical Diagnosis Precision Recall F-1 Score Accuracy Accuracy = Ratio of correctly classified points / total points 27
Write down columns and it’s correlation 3. Make questions derived from the dataset 4. Explanatory Analysis with visualization 5. Frame problem 6. Create solution by creating model 28
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}