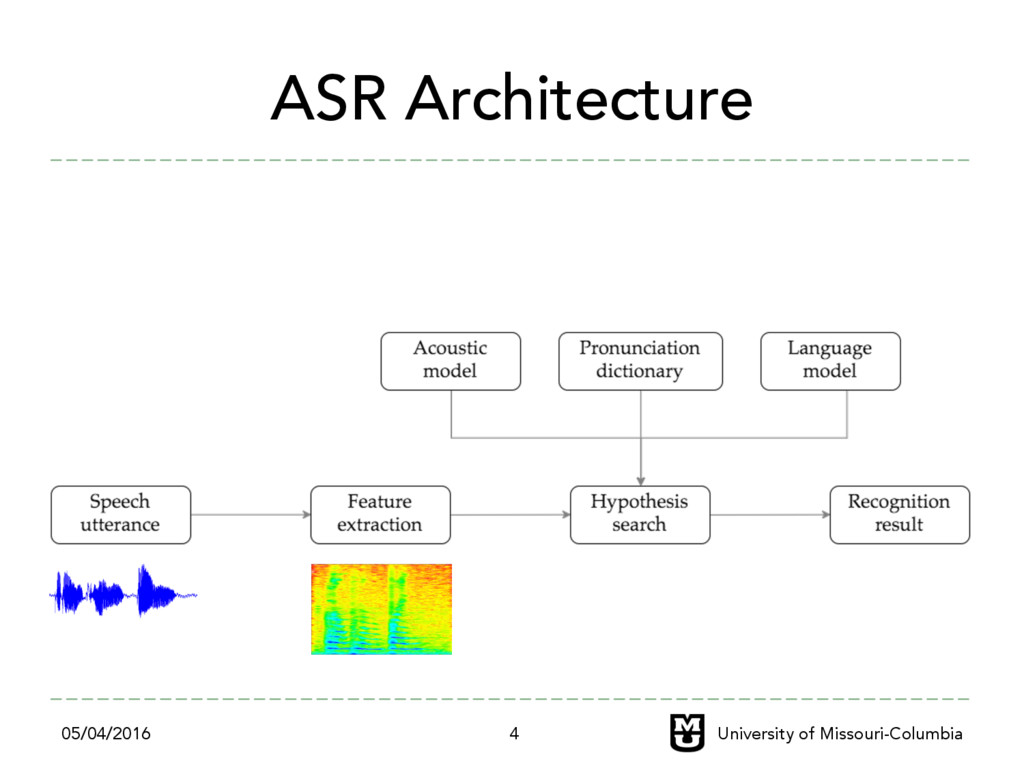
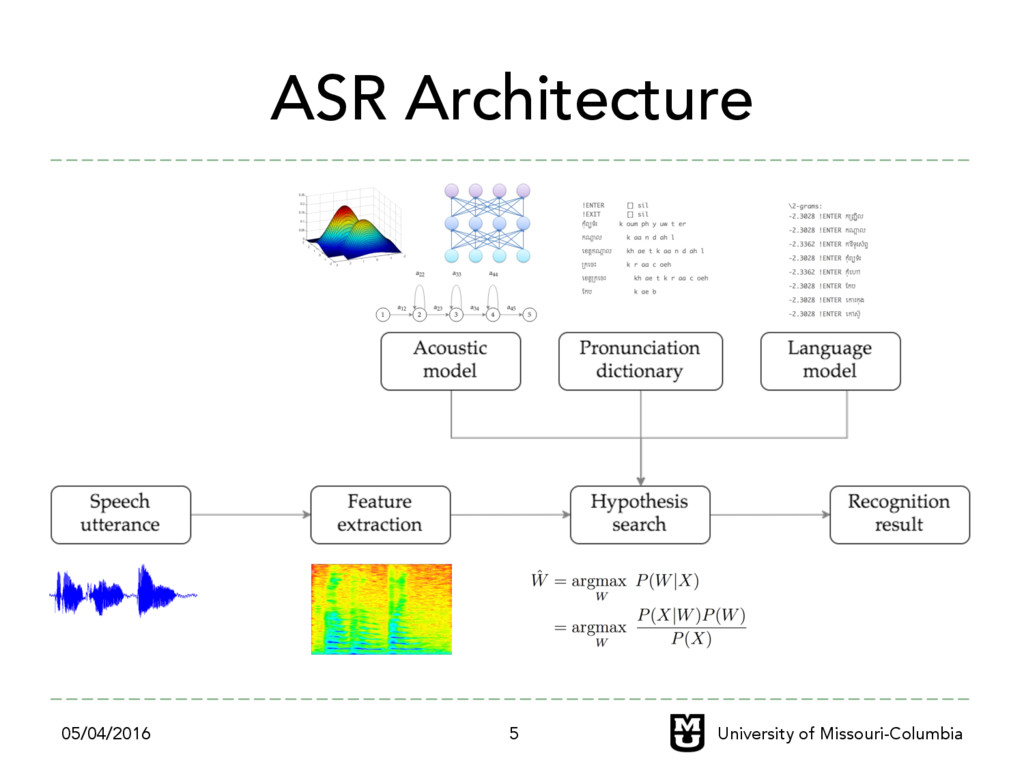
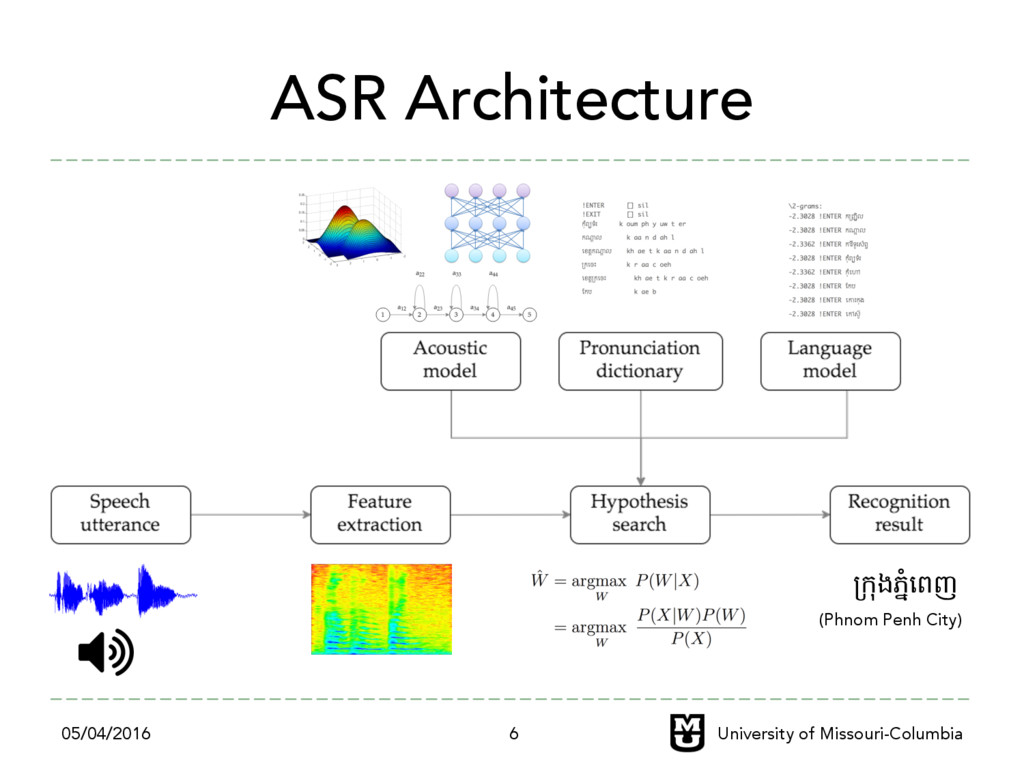
challenging – Lack of training data – Interdisciplinary field of research (linguistic, signal processing and machine learning) ‣ To build ASR for my own language ``Khmer (+្"រ)” ‣ To preserve Khmer language in this modern digital age 05/04/2016 University of Missouri-Columbia 8
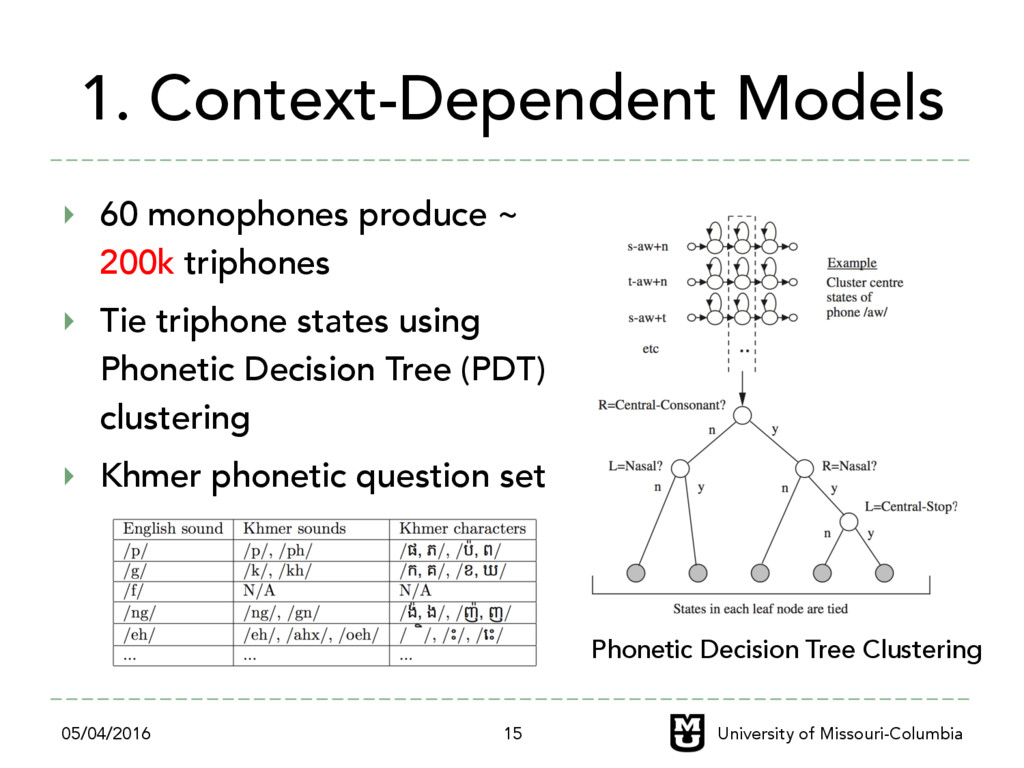
‣ Tie triphone states using Phonetic Decision Tree (PDT) clustering ‣ Khmer phonetic question set 05/04/2016 University of Missouri-Columbia 15 Phonetic Decision Tree Clustering
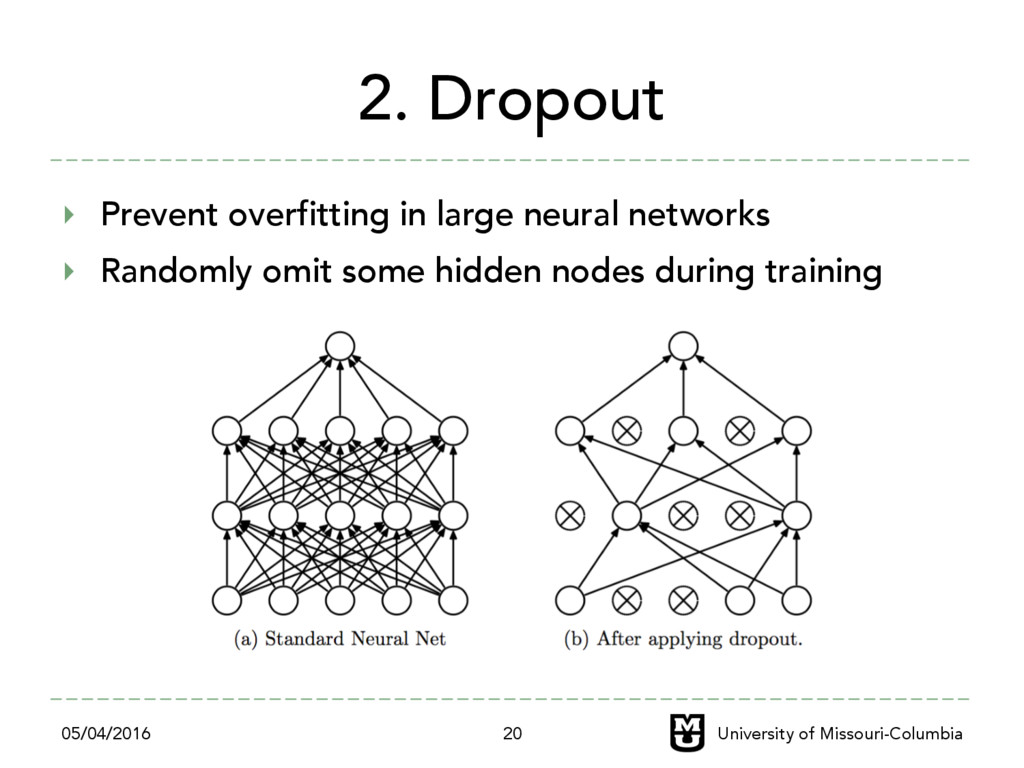
Popular techniques – Gradient Clipping: Clip the gradient once it exceed the threshold – Weight Decay: Penalize objective function by adding scaled L2-norm – Momentum: Speed up convergence by adding velocity from the previous gradient – Max-norm: Set the maximum L2-norm bound and scale the weight once it exceed the bound 05/04/2016 University of Missouri-Columbia 19
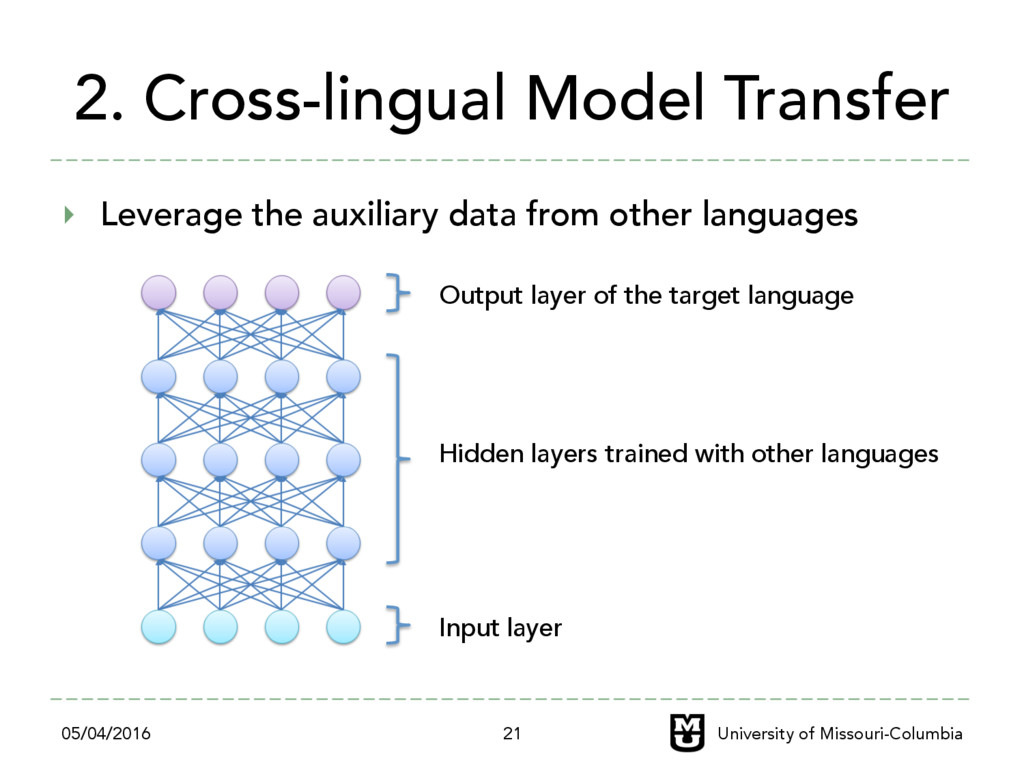
other languages 05/04/2016 University of Missouri-Columbia 21 Input layer Hidden layers trained with other languages Output layer of the target language
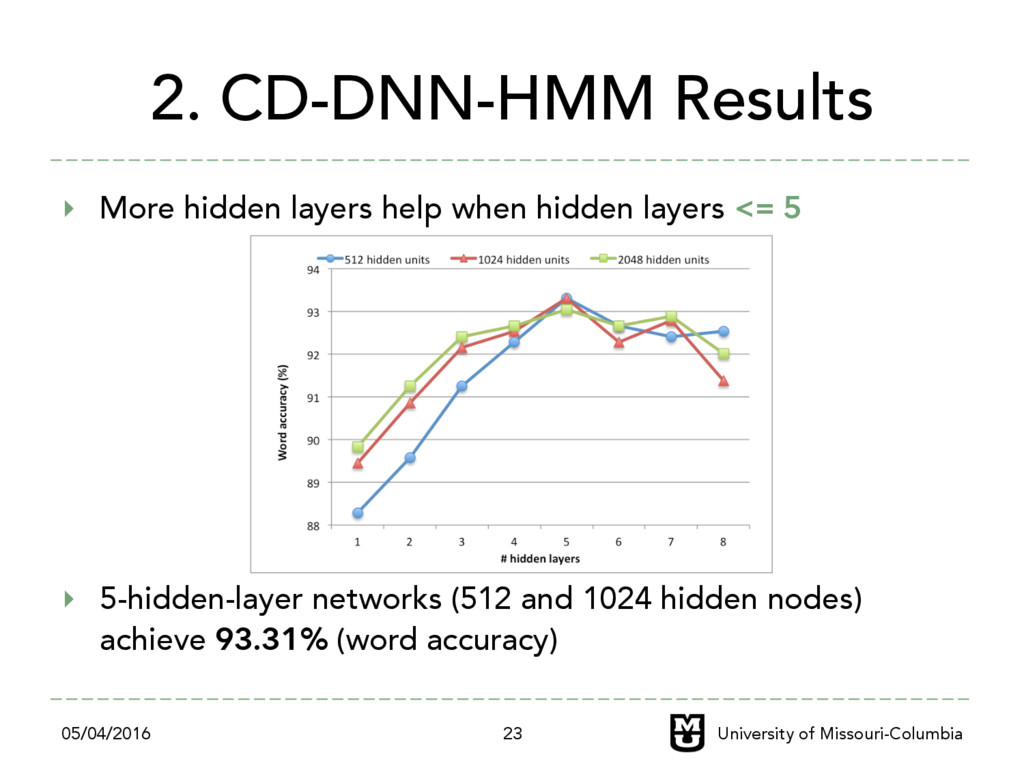
are build from scratch ‣ GMM-HMM baseline ‣ The first DNN-HMM training recipe for Khmer ASR ‣ Future works – Use unsupervised pre-training for transfer learning – Investigate other types of DNN. i.e., RNN and CNN – Use DNN with continuous speech recognition for Khmer 05/04/2016 University of Missouri-Columbia 26
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}