Slide of the talk at IEEE ICSM 2010 (International Conference on Software Maintenance), held in Timisoara (Romania) on Sept. 2010
**Abstract**:
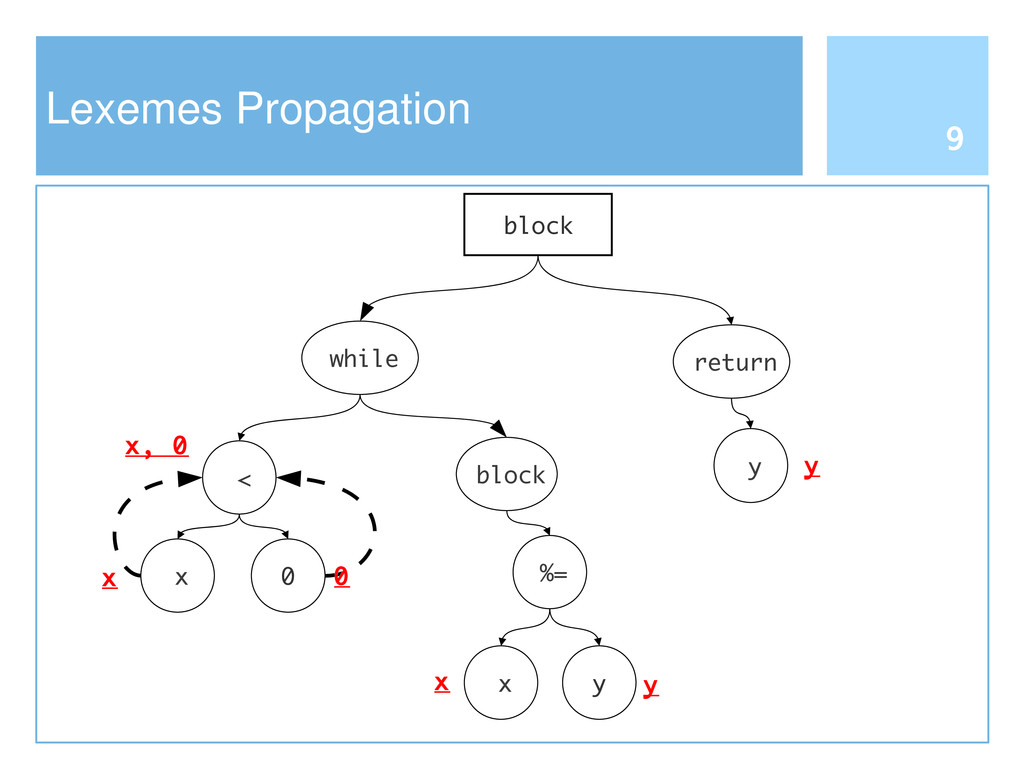
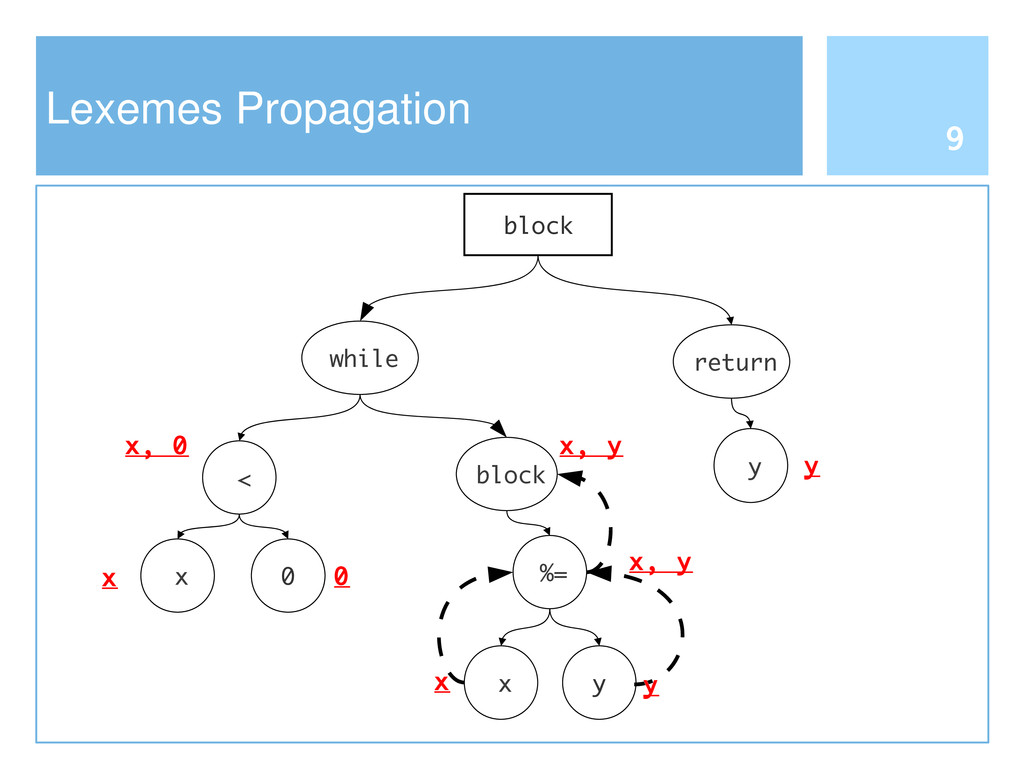
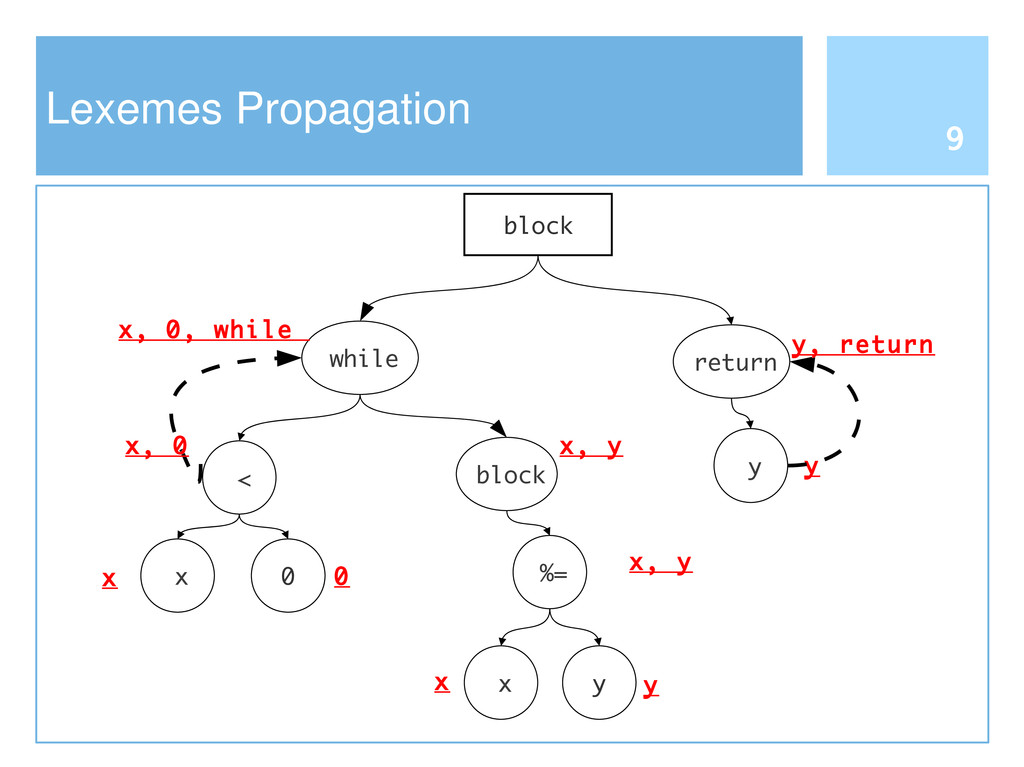
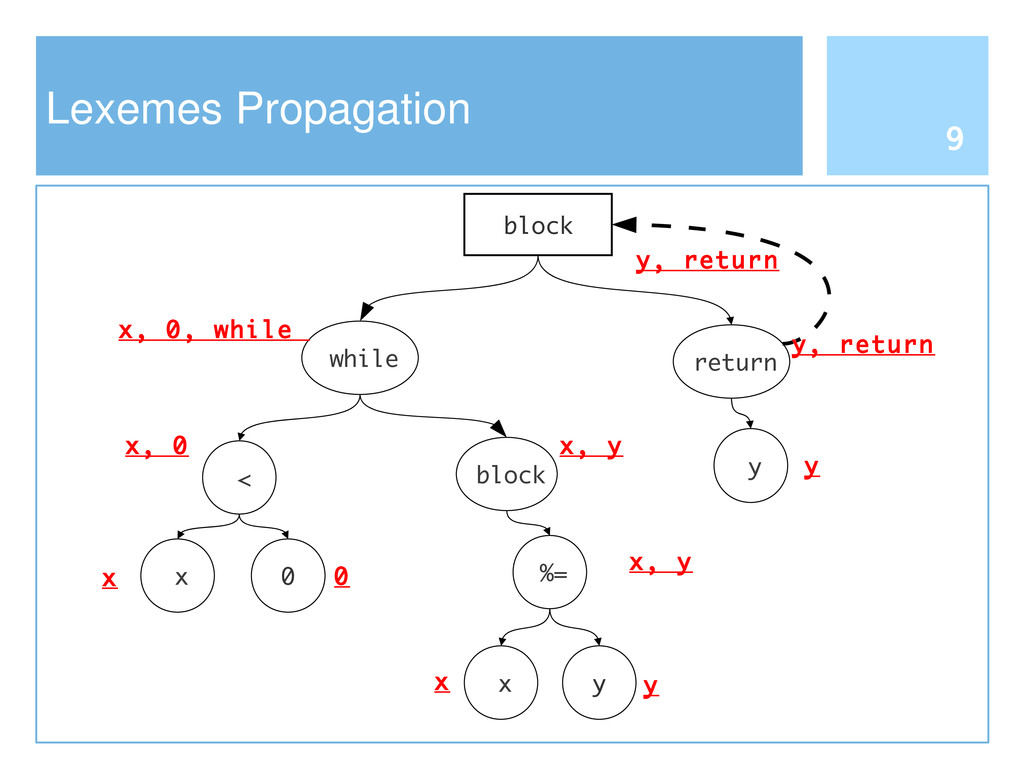
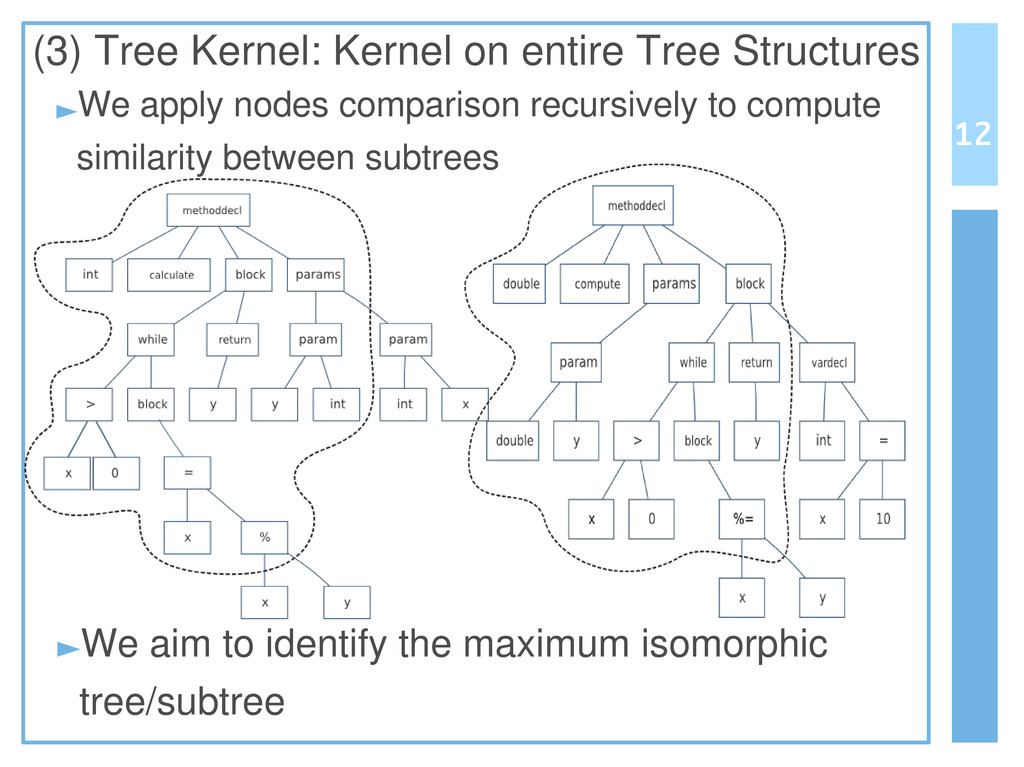
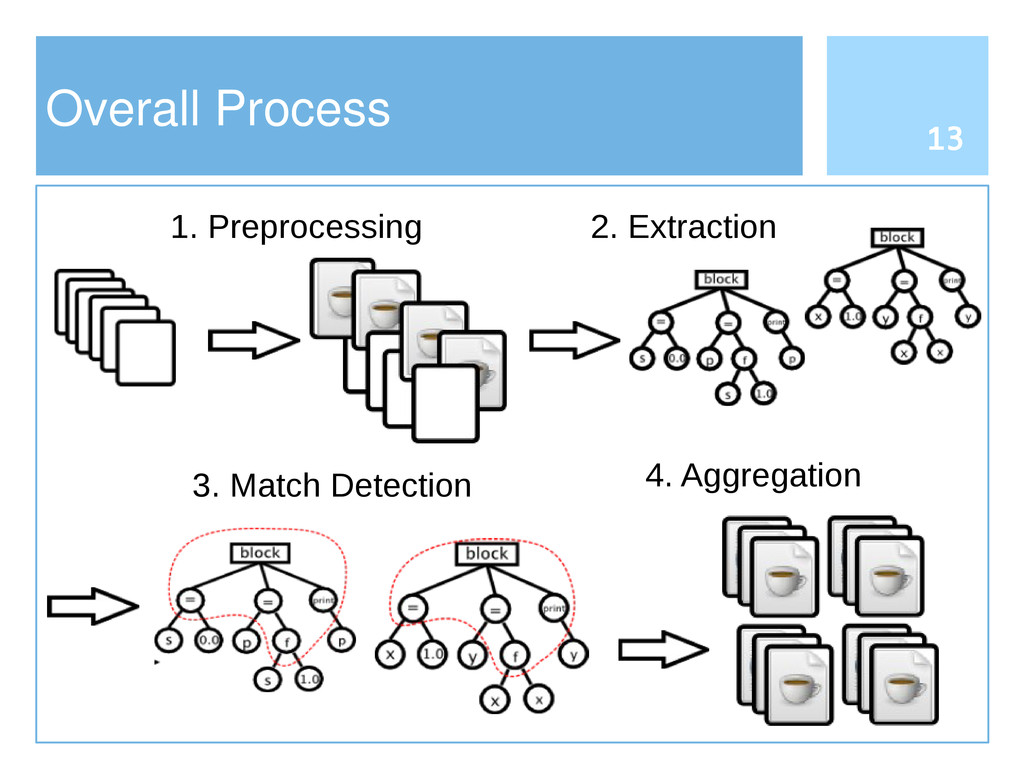
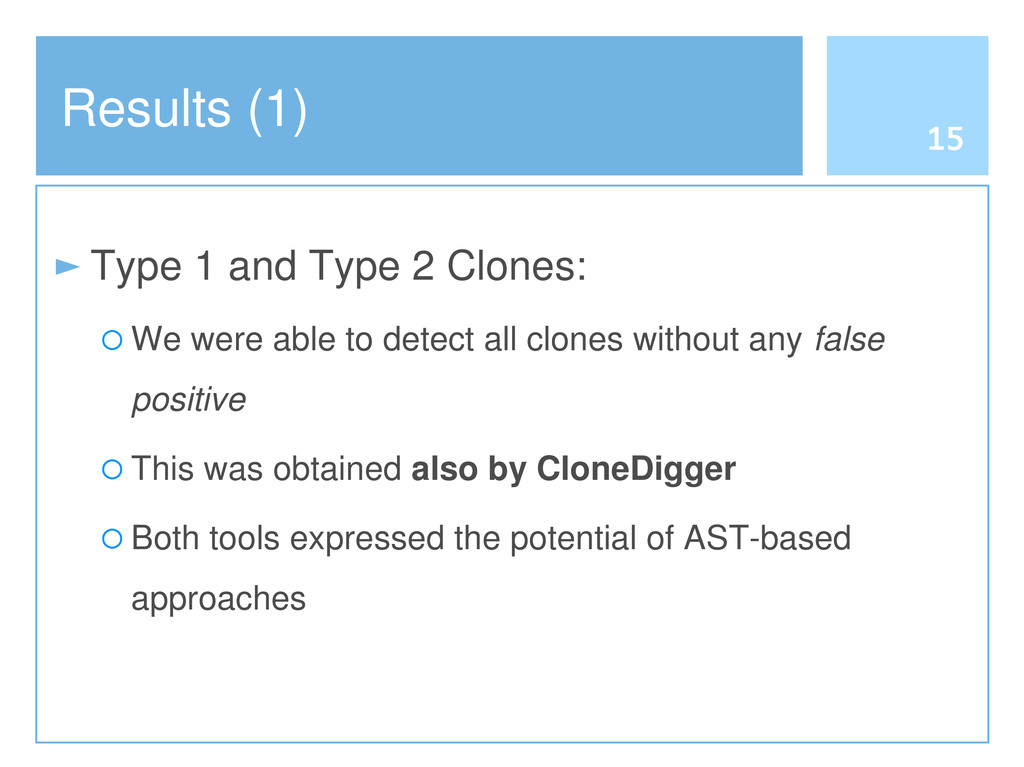
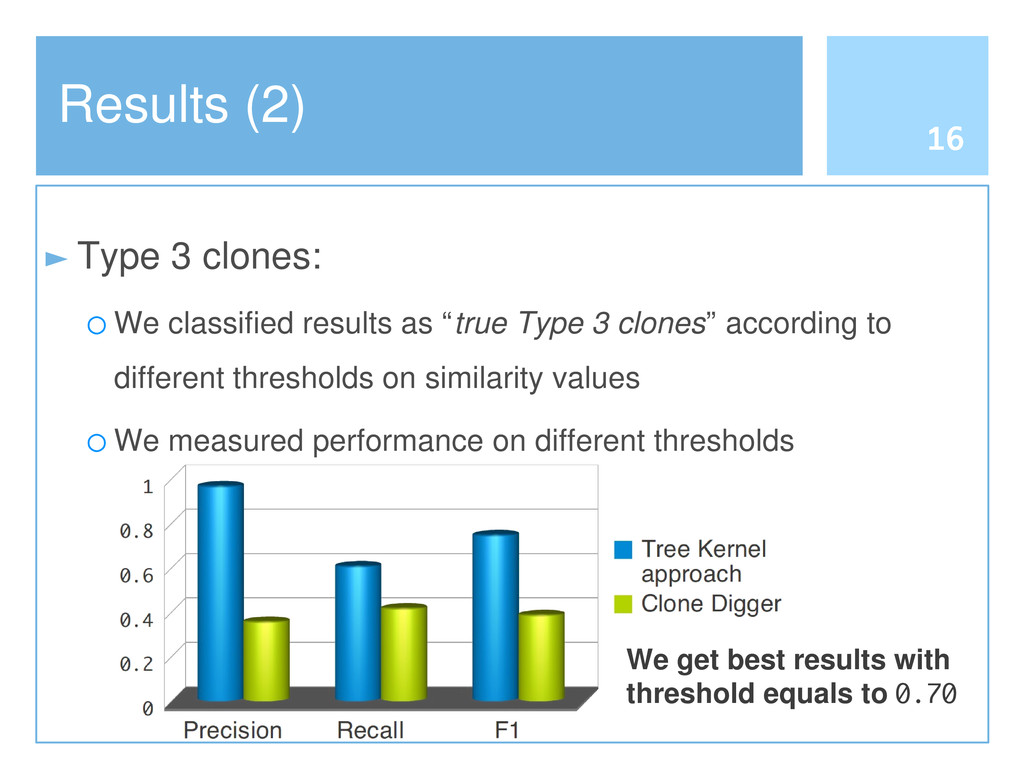
Reusing software by copying and pasting is a common practice in software development. This phenomenon is widely known as code cloning. Problems with clones are mainly due to the need of managing each duplication, thus increasing the effort to maintain software systems. Clone detection approaches generally take into account either the syntactic structure (e.g., Abstract Syntax Tree) or lexical elements (e.g., the signature of a function). In this paper we propose an approach to detect code clones, based on syntactic information enriched by lexical elements. To this end, we have defined a Tree Kernel function to compare Abstract Syntax Trees. A preliminary investigation has been also conducted to assess the validity of the proposed approach.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}