Data augmentation • Experiments Impact of MS COCO pretraining Finding the right balance Evaluation datasets Results on the evaluation datasets • Conclusion 2 Outline
camera surveillance is needed to provide services, safety and security without sta+ • Wide angle or Fisheye cameras will be used (barrel distortion) • Objective : a method to adapt computer vision algorithms to deal with both rectilinear and sheye images Context 3
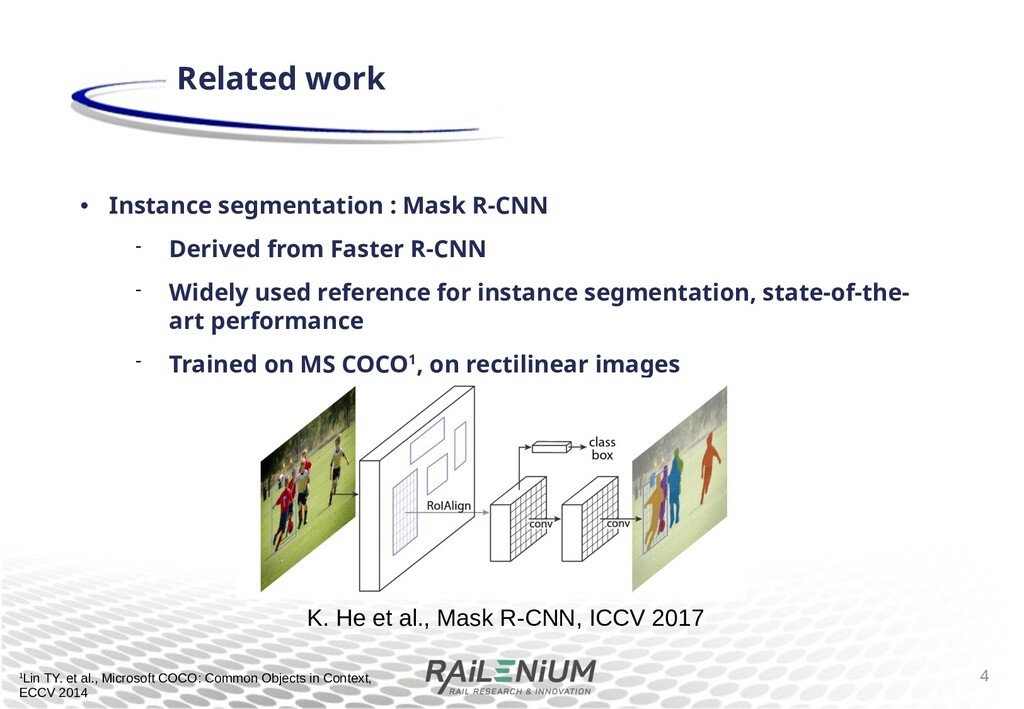
R-CNN Widely used reference for instance segmentation, state-of-the- art performance Trained on MS COCO1, on rectilinear images 4 Related work K. He et al., Mask R-CNN, ICCV 2017 1Lin TY. et al., Microsoft COCO: Common Objects in Context, ECCV 2014
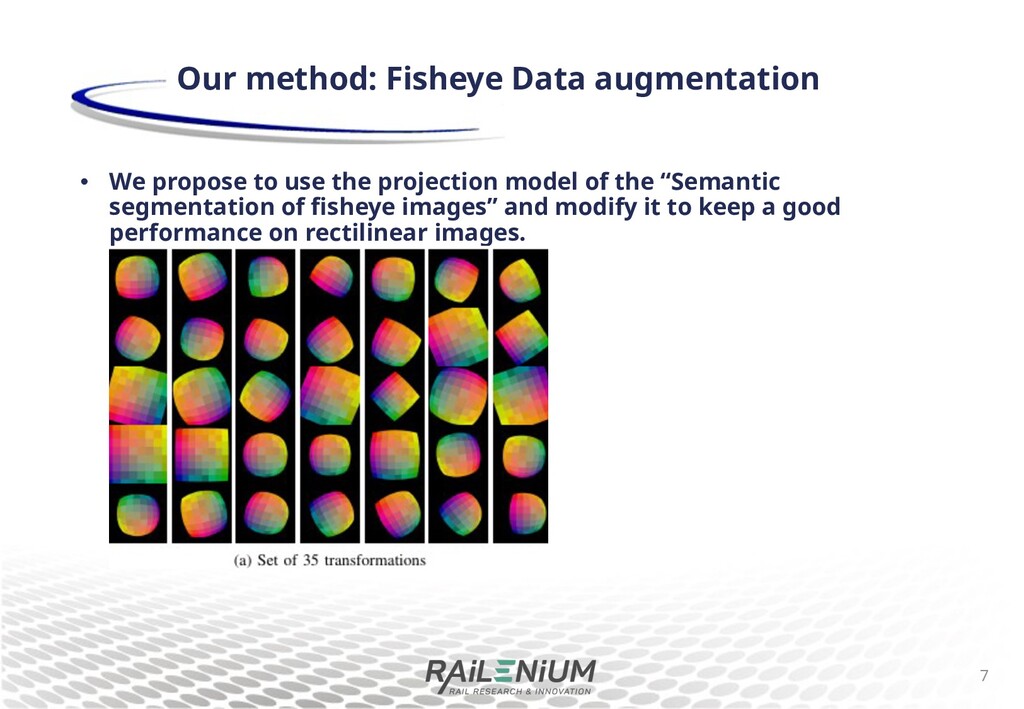
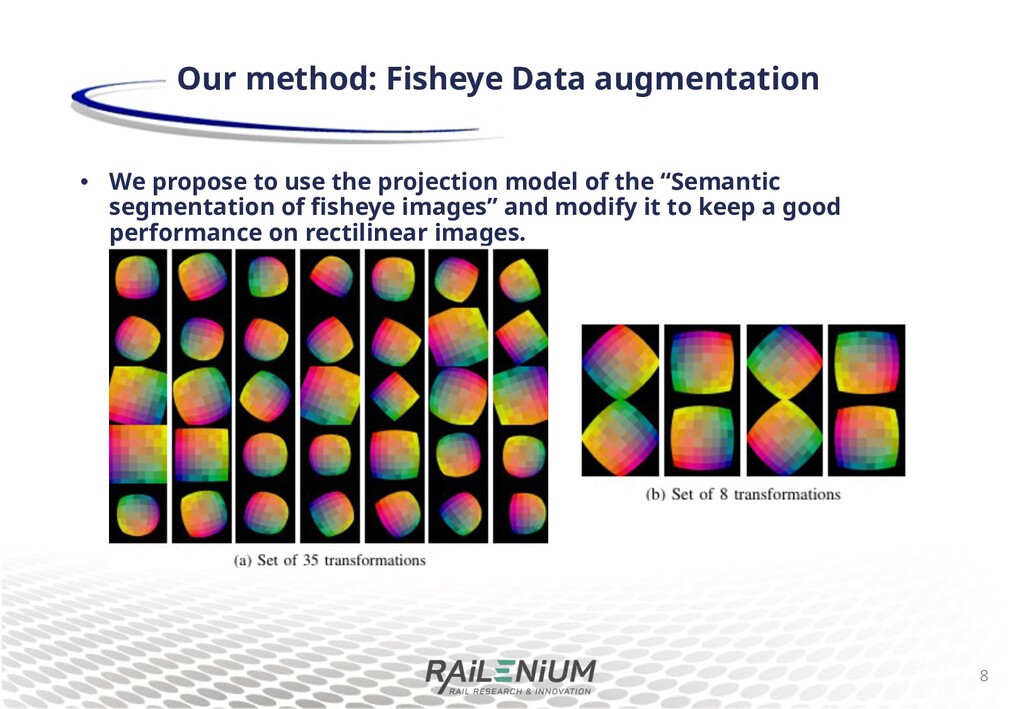
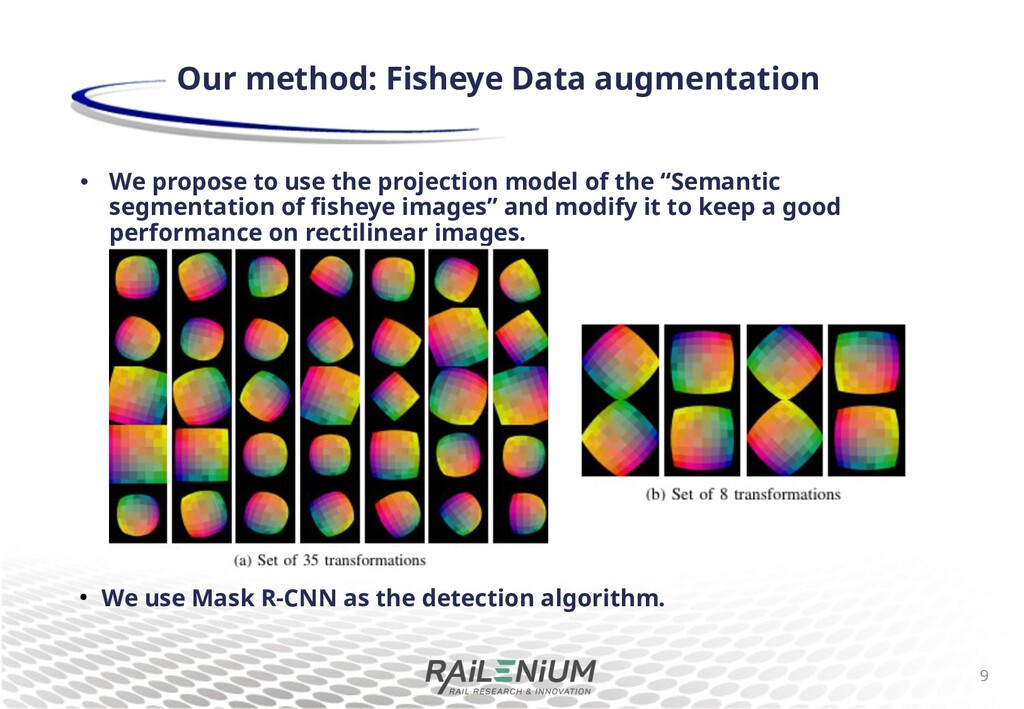
projection model to apply a sheye e+ect (FE) A set of 25 sheye transformations for data augmentation Improves semantic segmentation performance on real custom sheye camera dataset. 5 Related work G. Blott et al., Semantic segmentation of fisheye images, ECCV 2018
“Semantic segmentation of sheye images” and modify it to keep a good performance on rectilinear images. 9 Our method: Fisheye Data augmentation • We use Mask R-CNN as the detection algorithm.
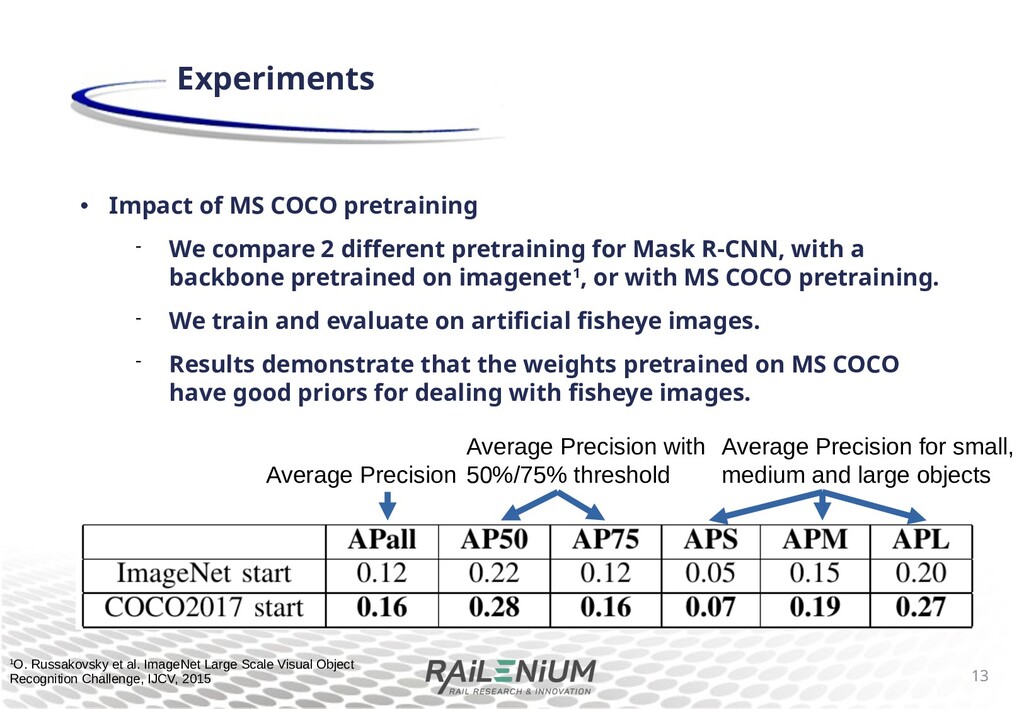
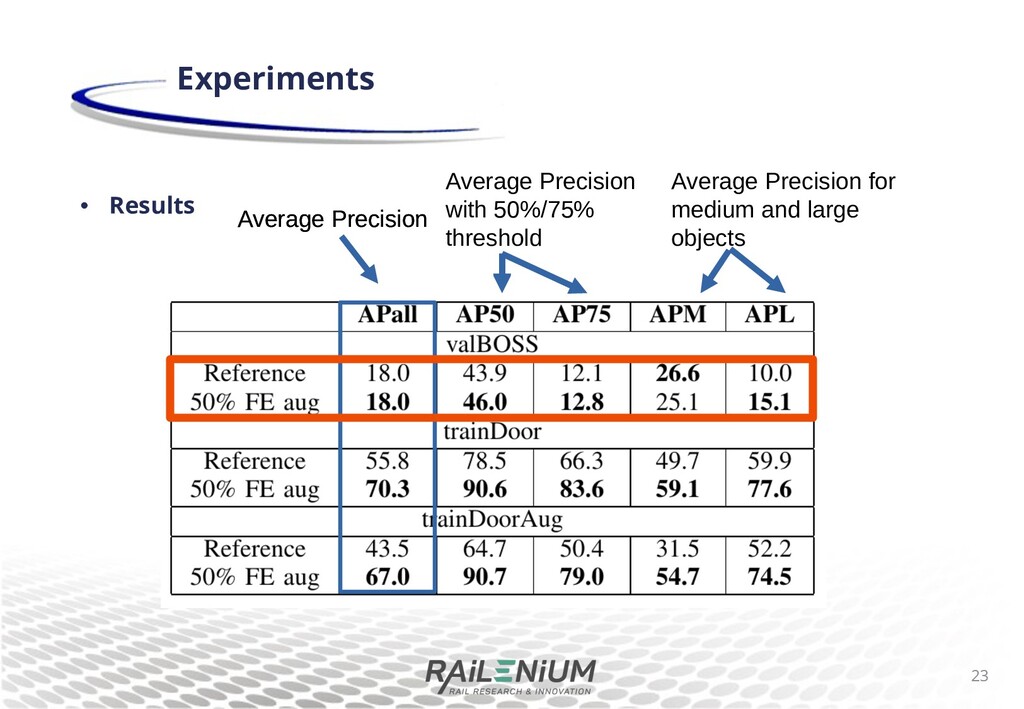
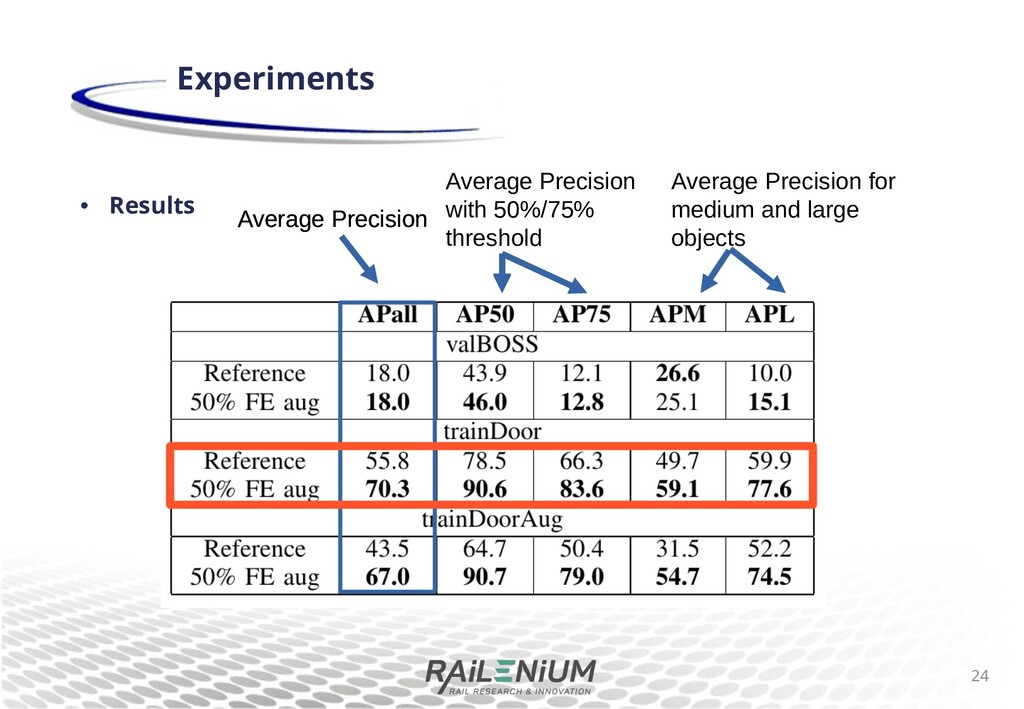
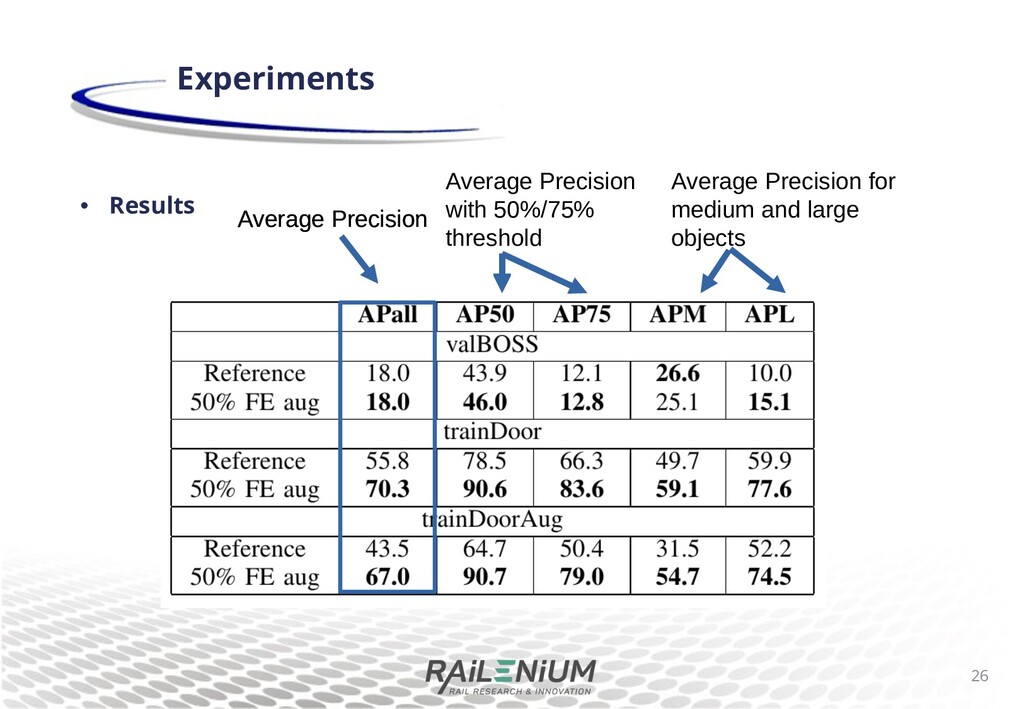
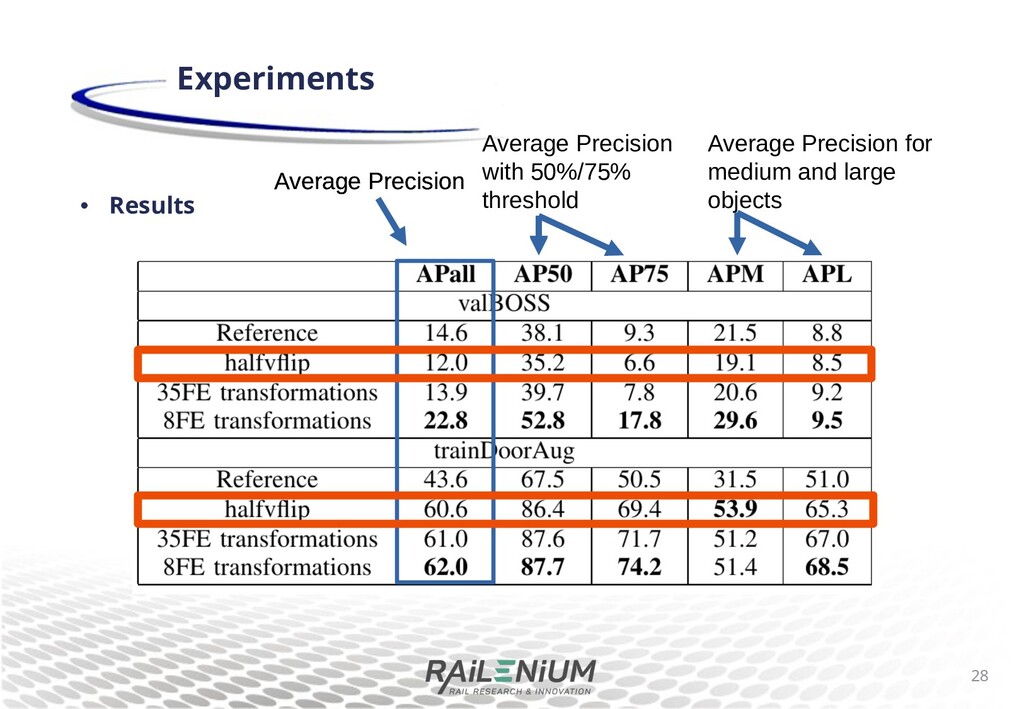
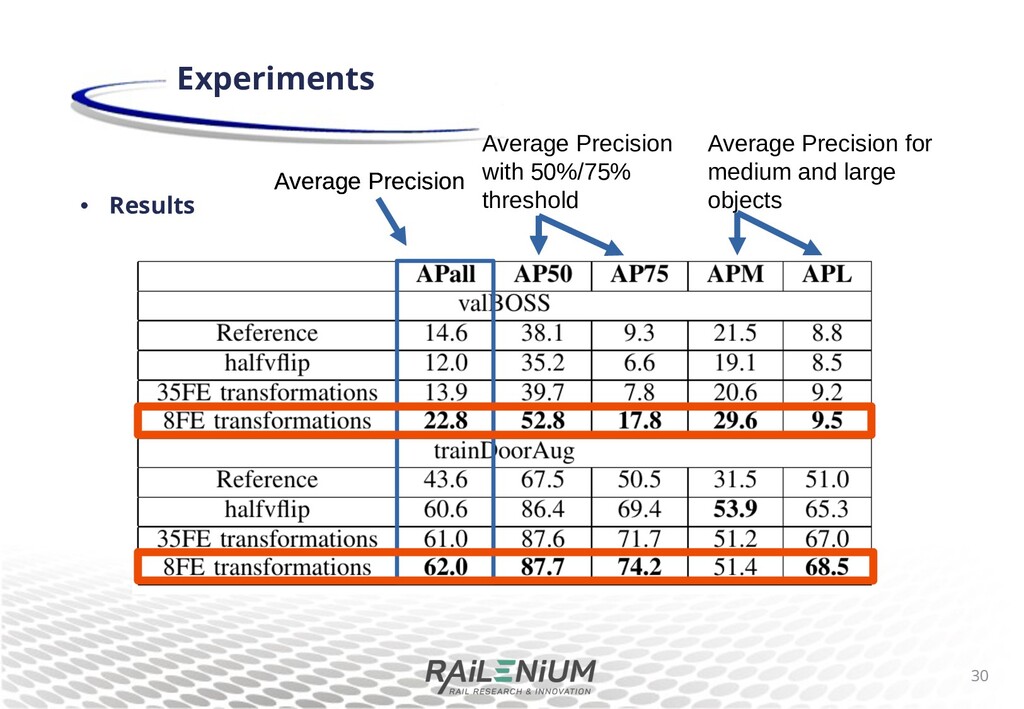
di+erent pretraining for Mask R-CNN, with a backbone pretrained on imagenet1, or with MS COCO pretraining. We train and evaluate on arti cial sheye images. Results demonstrate that the weights pretrained on MS COCO have good priors for dealing with sheye images. 12 Experiments 1O. Russakovsky et al. ImageNet Large Scale Visual Object Recognition Challenge, IJCV, 2015
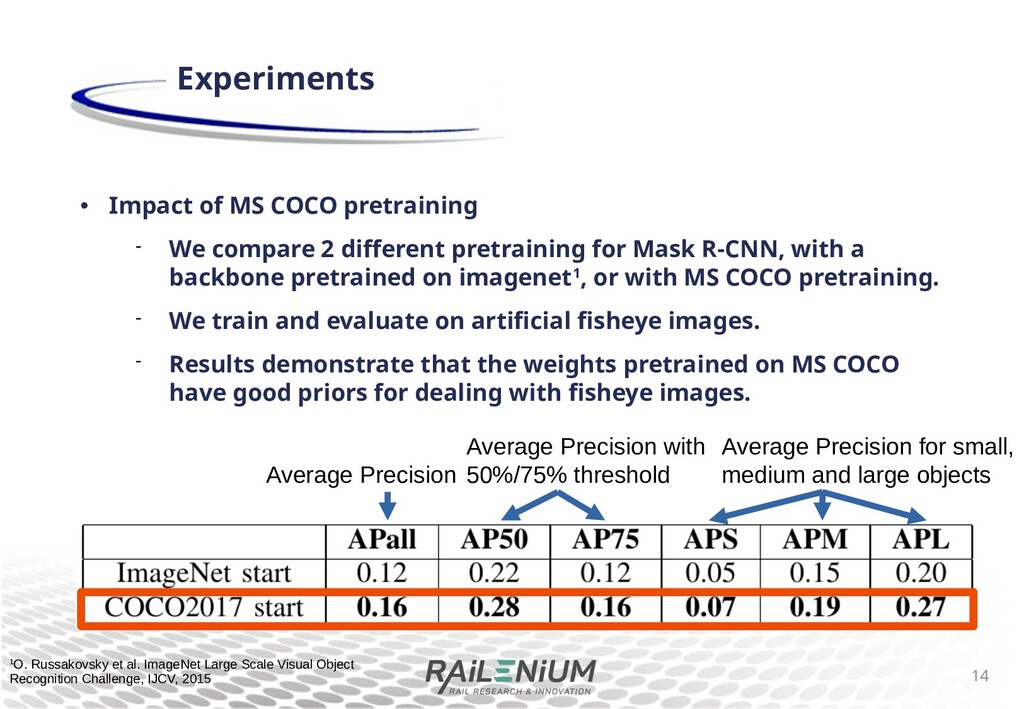
di+erent pretraining for Mask R-CNN, with a backbone pretrained on imagenet1, or with MS COCO pretraining. We train and evaluate on arti cial sheye images. Results demonstrate that the weights pretrained on MS COCO have good priors for dealing with sheye images. 13 Experiments Average Precision with 50%/75% threshold Average Precision Average Precision for small, medium and large objects 1O. Russakovsky et al. ImageNet Large Scale Visual Object Recognition Challenge, IJCV, 2015
di+erent pretraining for Mask R-CNN, with a backbone pretrained on imagenet1, or with MS COCO pretraining. We train and evaluate on arti cial sheye images. Results demonstrate that the weights pretrained on MS COCO have good priors for dealing with sheye images. 14 Experiments Average Precision with 50%/75% threshold Average Precision Average Precision for small, medium and large objects 1O. Russakovsky et al. ImageNet Large Scale Visual Object Recognition Challenge, IJCV, 2015
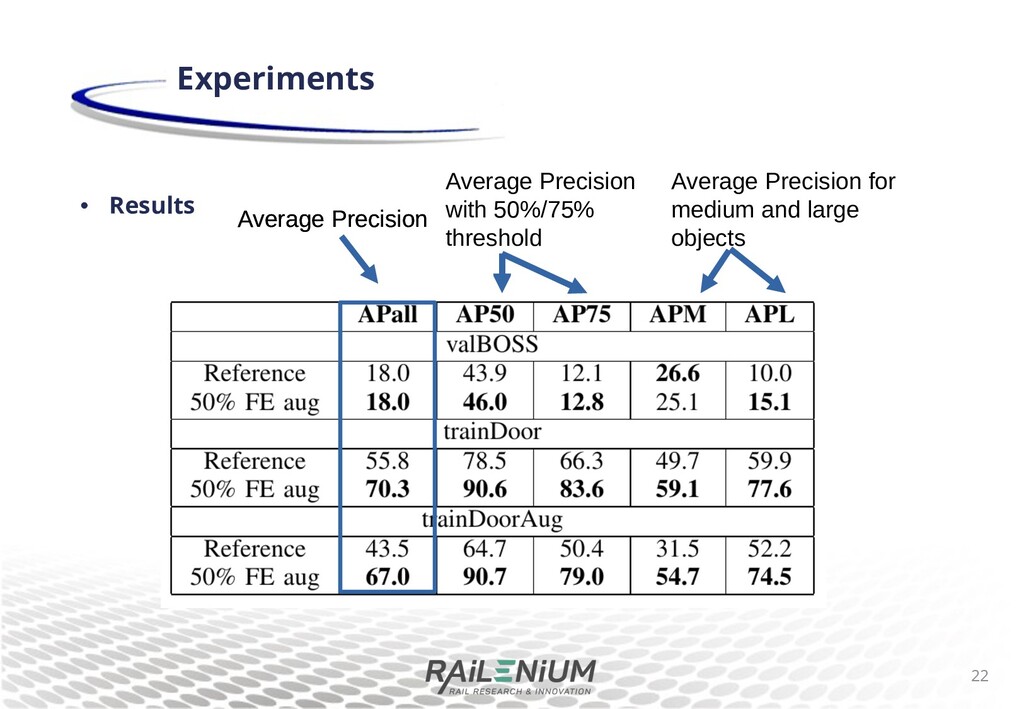
scenes meant to resemble pedestrians walking through a door. 121 images annotated for human instance segmentation. TrainDoorAug dataset : made by augmenting trainDoor with vertical 9ip. 242 images. Experiments 16
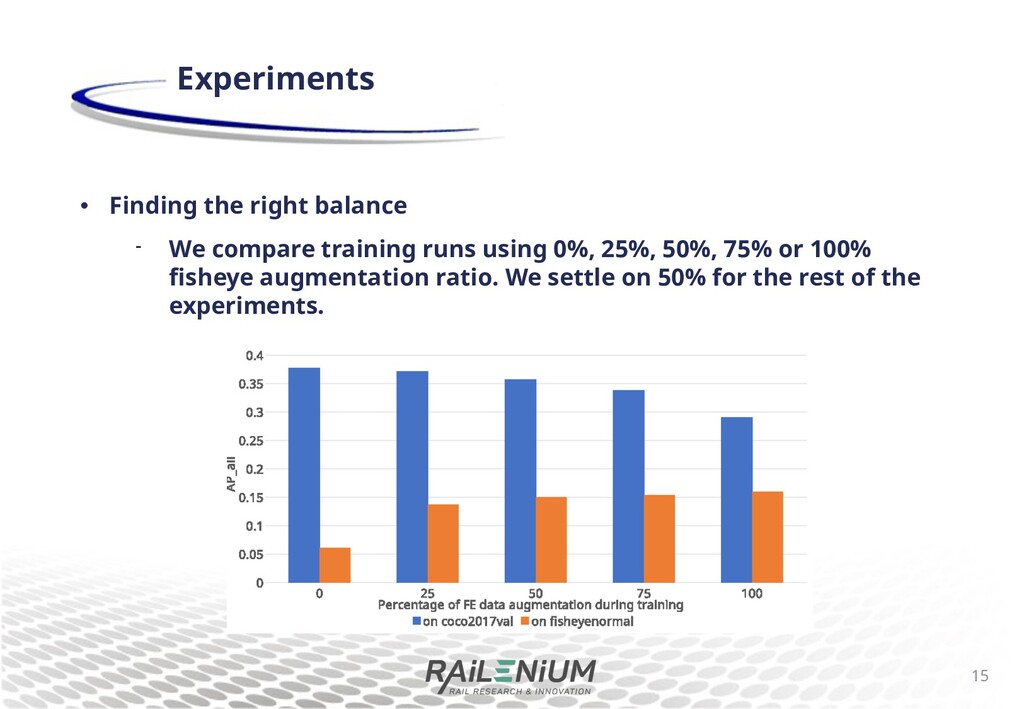
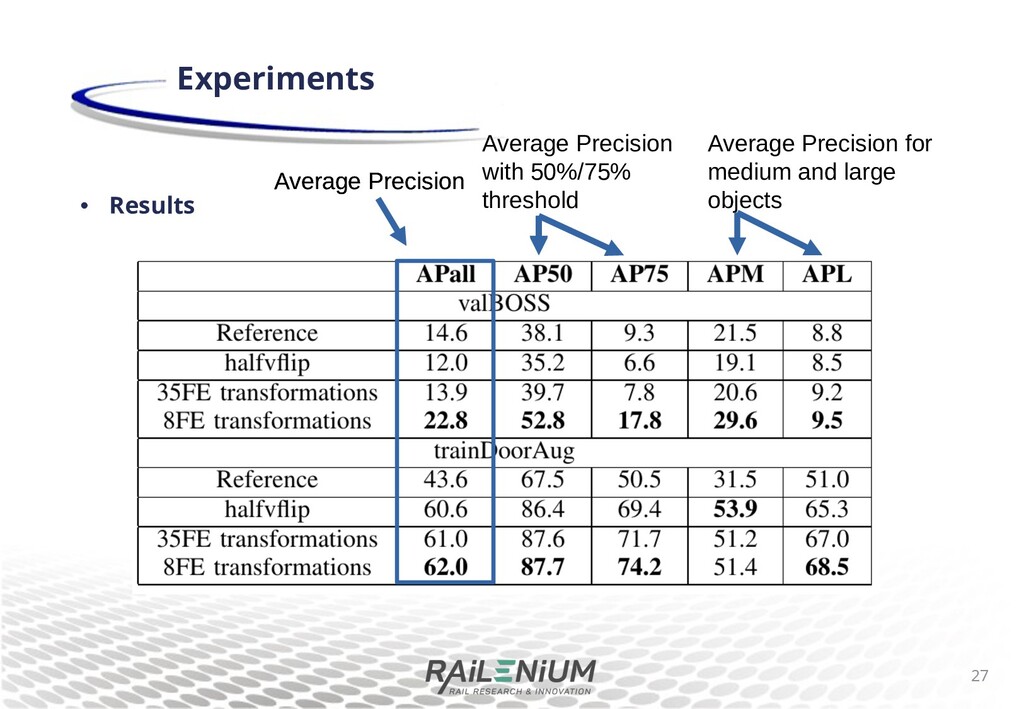
sheye images. • Using a sheye augmentation method for 50% of training examples can result in good performance on both rectilinear and sheye images. • Using only 8 di+erent sheye transformations is enough to get the increased performance. • Not speci c to segmentation tasks. • Doesn’t require additional computation. • We plan to use this method for other algorithms and other tasks related to the safety of train passengers. Conclusion 32
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}