distributed system management Data Analyzer/Planner who wants to know how to deal with such big scale data platform Data Manager/Evangelist who tackles complex Data Management/Governance tasks with many stakeholders
SUM(s_sent.cnt) FROM lineshop.sticker_sent AS s_sent JOIN sticker_stats.ranking AS s_rank ON (s_sent.sticker_id = s_rank.sticker_id) WHERE s_sent.dt = '20211110' AND s_rank.dt = '20211110' AND s_rank.rank = 1 lineshop.sticker_sent sticker_sent.ranking Datachain Hive/Spark Hive/Spark cannot recognize another cluster’s table information.
distcp distcp distcp - Uncontrollable copy job timing by each stakeholder - A lot of resources (vCore/Mem) are required for distcp - Network bursting risk, especially inter-IDC
to data copy, double-write - Keep same directory structure, permission as-is - Disk resource is shared with all HDFS clusters - IU federation is “logical” one - Physically, all HDFS share same machines - Get bigger scale disk capacity - IU HDFS uses viewfs - No need to consider federated HDFS cluster on user-side - More convenient to access data itself /dfs/data/ ├── datachain/ ├── datalake/ ├── iu01/ ├── iu02/ └── iu03/
transition - Decommision/Recommision, IDC relocation & OS re-setup requires a lot of time - Prepare several relocation phases to minimize resource lacking risk - IDC-level relocation - To achieve more efficient capacity planning - Co-work with “moving service company”! - Hybrid hiveserver2 – IU YARN with old metastore - YARN resource is decreasing - but some users still require old metastore - Apply a hiveserver2 patch to work on IU YARN with old metastore IU YARN Hybrid Hive Non-IU metastore Get table info Submit job
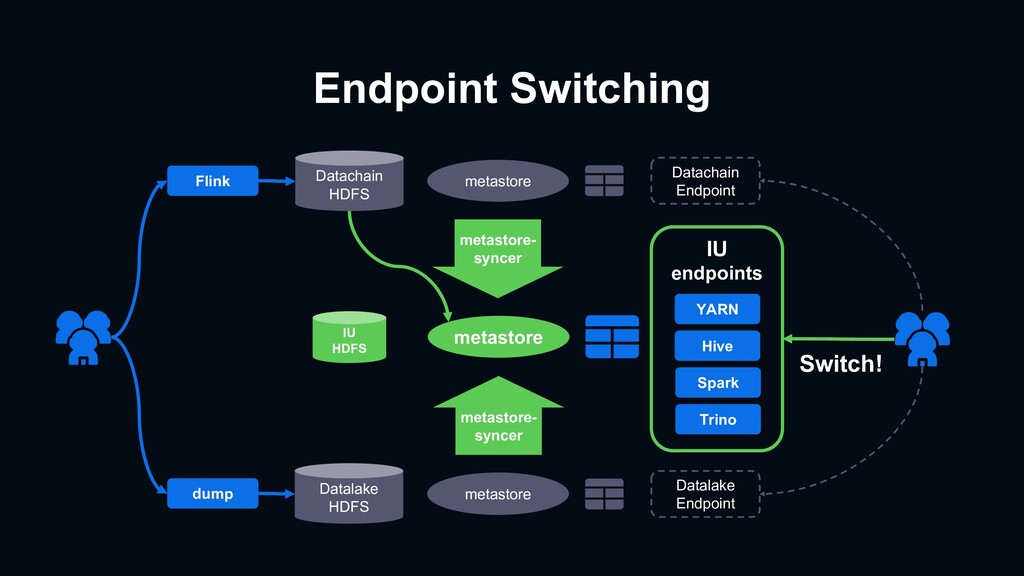
from IU endpoint - To promote IU components - Kafka producer – local disk writing + fluentd tail plugin - Local disk is more durable than network writing - If Kafka/SyncWorker trouble, we can resume missing DDL events from local file - Each table’s event is assigned to corresponding Kafka partition - Easy to detect metastore-syncer trouble - SyncWorker has filtering/converting feature - Not all tables require migrating to IU - Outdated table - A user decides double writing strategy
simple - Keeping current policy as-is helps platform users reduce system changing cost - Making situation simple is a great first step to improve big-scale system/service
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}