growing at an annual rate of 35%. Expecting $3.5 billion in 2021” (Technavio) > “By 2020, 55 percent of large companies will use more than one chatbot .. In 2021, more than 50 percent of companies will spend more on chatbot than mobile apps.” > “Chatbot is expected to help us save more than $2 billion this year and $8 billion annually by 2022 (Juniper Research)
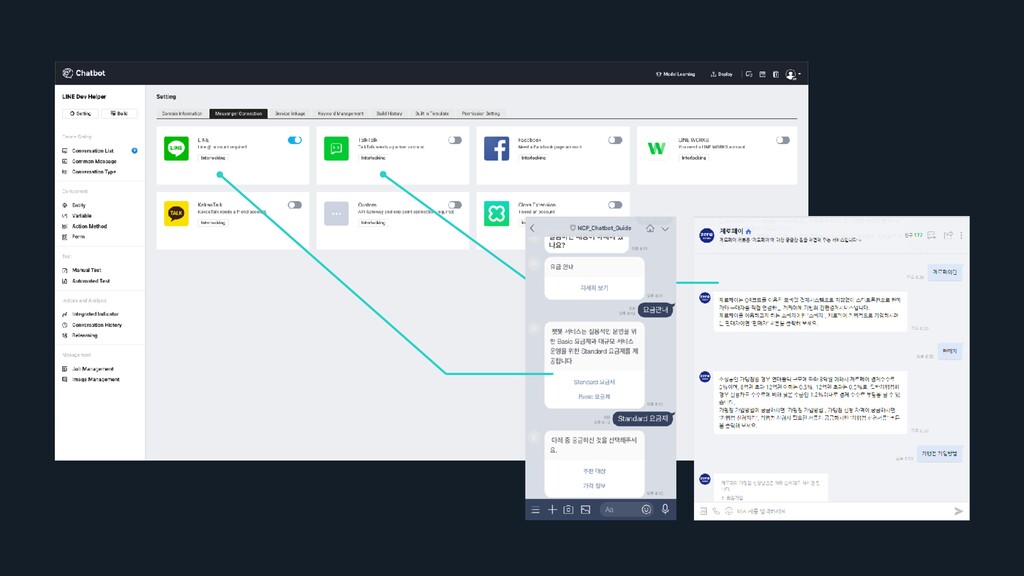
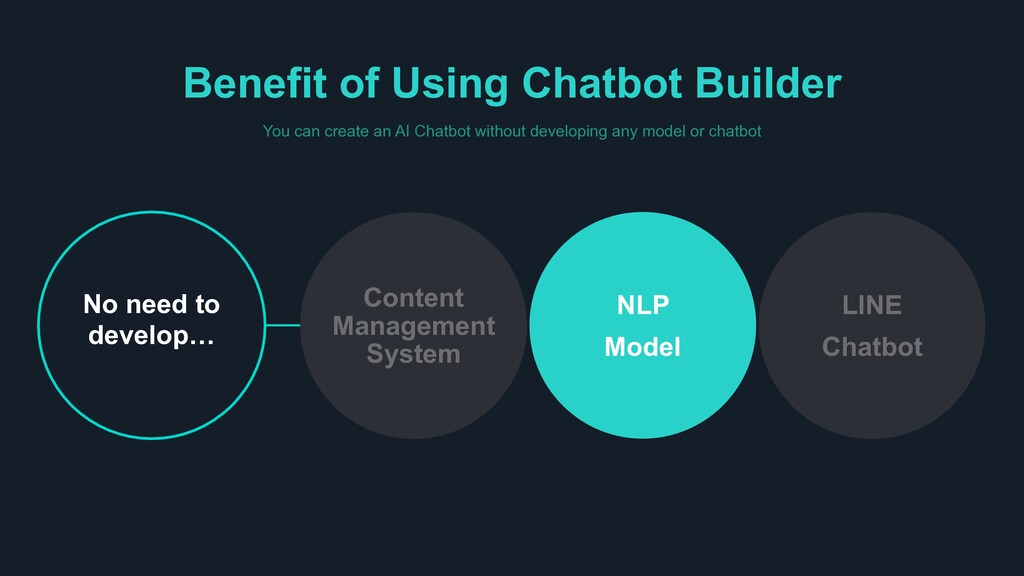
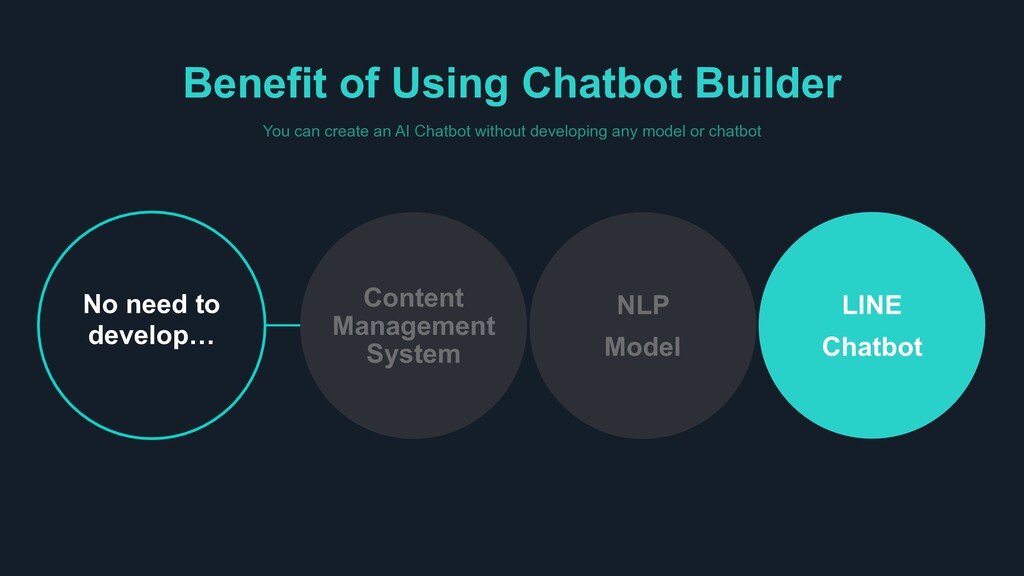
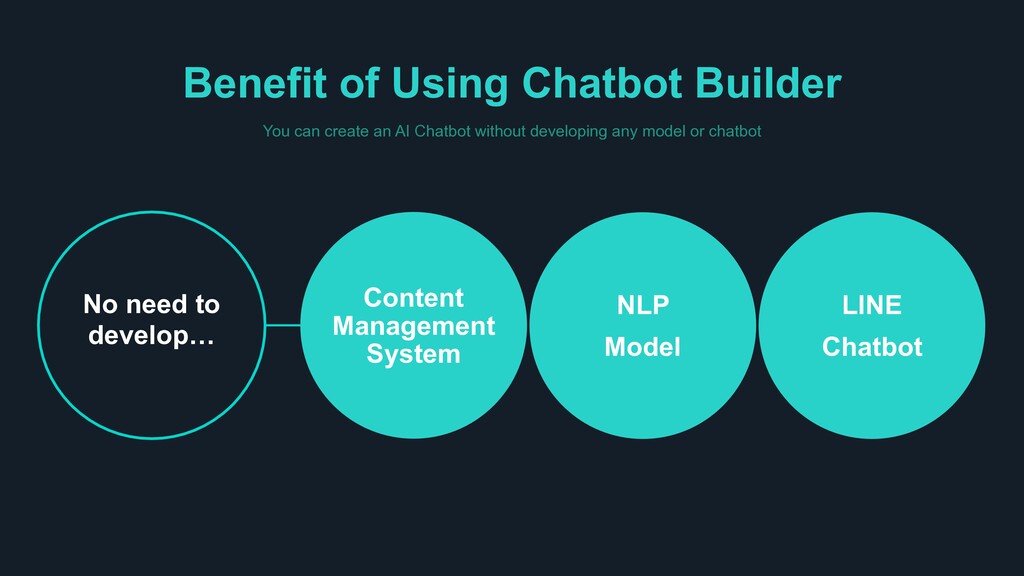
Chatbot’ Easy to BUILD > Build your own Chatbot within one day > Built-in Templates for each industry > Less scenario, still outstanding performance Easy to SERVE > Leverage LINE platform > Legacy DB I/F for Enterprise > Adjust to each messenger format Easy to EXPAND > Supports 6 or more languages > Compatible with smart speakers > No limit on number of intents or scenarios
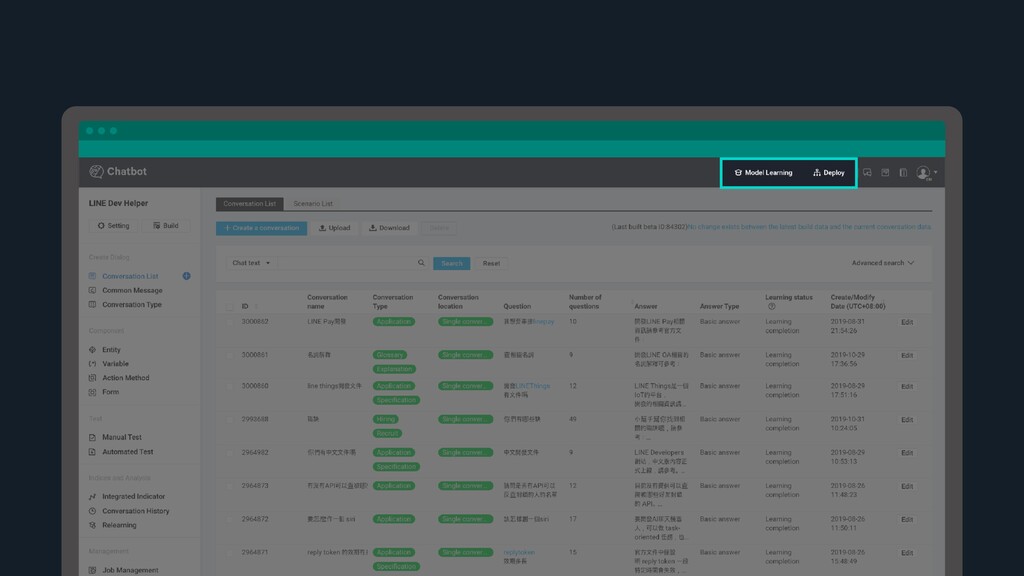
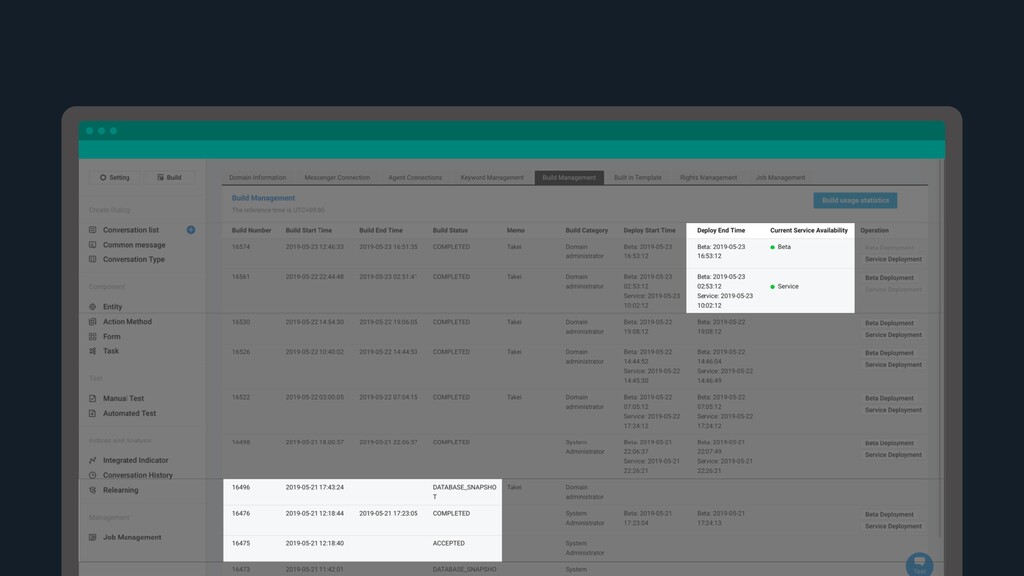
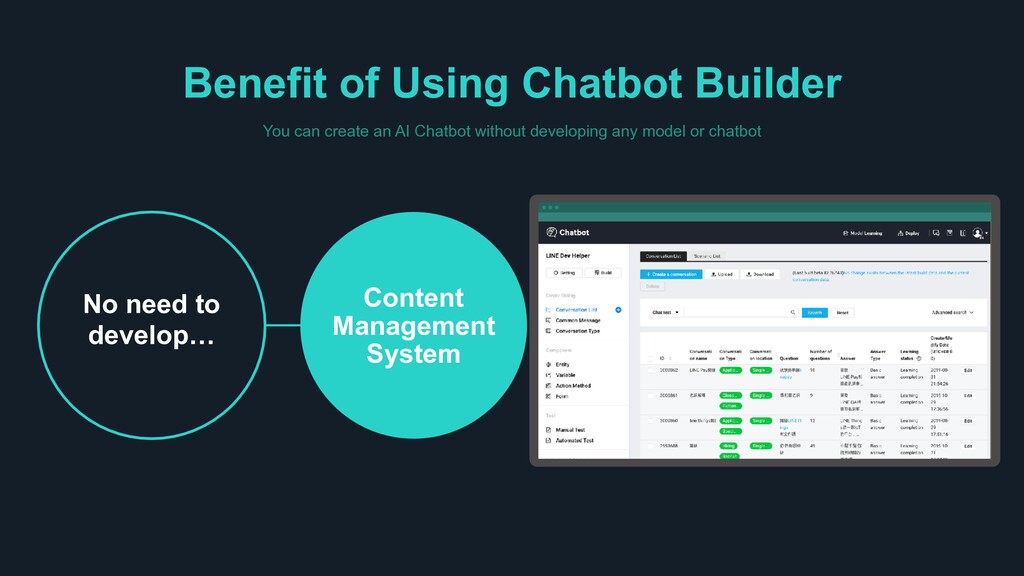
Built-in dashboard to control different domains > Visualize and re-train chatbot through chat history and statistics WHY CLOVA? Build your own AI Chatbot that truly understands what people say, not just their intents and keywords > It is difficult to cover all combinations of human expression just by adding simple question and answers. Clova chatbot not only understands incoming queries, but also provides the best answer within given scenarios
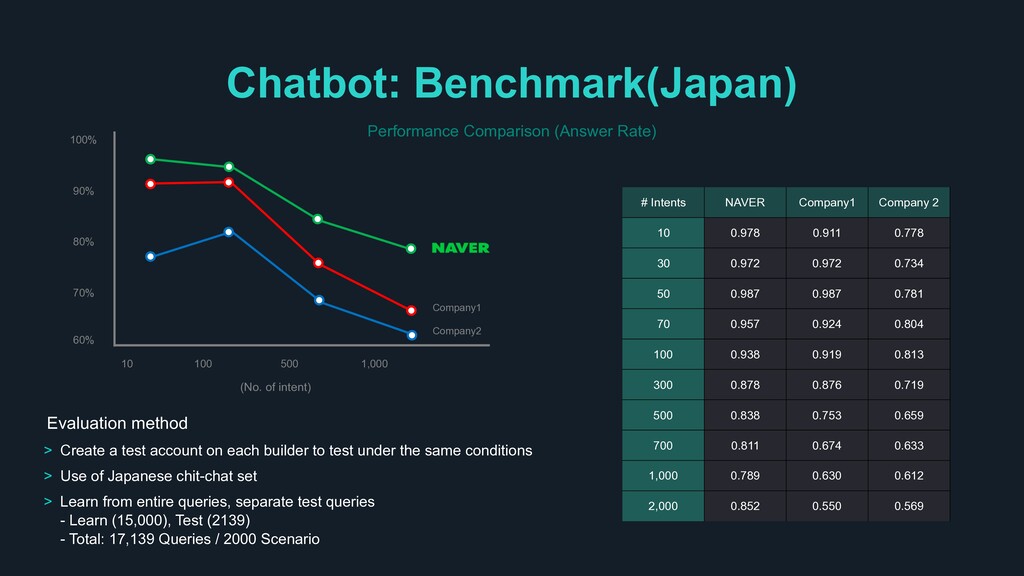
each chatbot builder Used Korean chit-chat dataset and translated into English Randomly selected test queries from the sample data - Korean: train(1,665), test(159) - English: train(512), test(152) 95.6% 91.8% 88.7% 72.3% KOREAN 91.4% 90.1% 88.2% ENGLISH 91.4% “Utilizing large amount of data collected from NAVER search engine, Clova has the most powerful language processing capabilities, and through auto-tuning for each domain within chatbot builder, it learns new domain with less amount of data” Company1 Company2 Company3 Company1 Company2 Company3
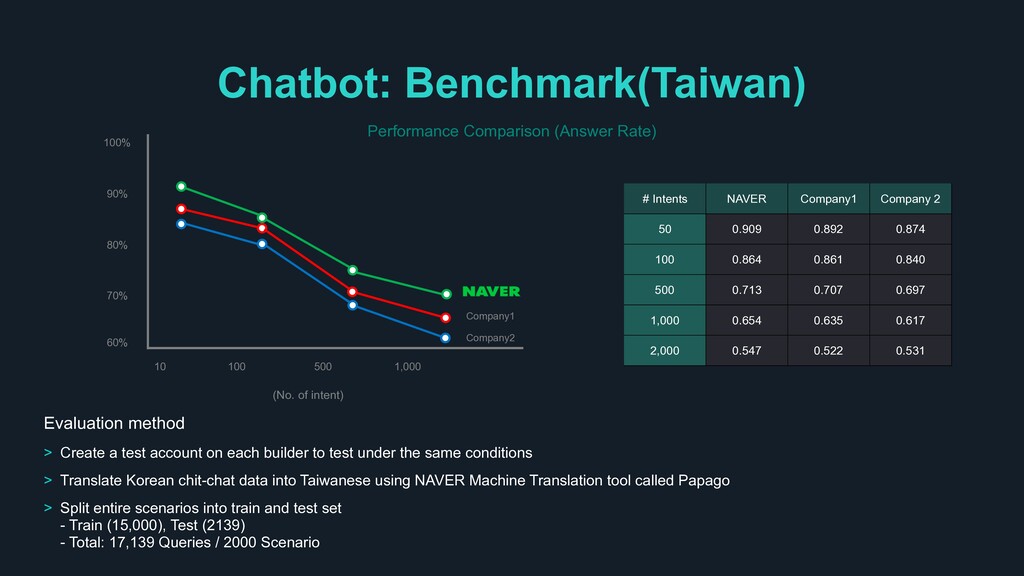
0.892 0.874 100 0.864 0.861 0.840 500 0.713 0.707 0.697 1,000 0.654 0.635 0.617 2,000 0.547 0.522 0.531 Evaluation method > Create a test account on each builder to test under the same conditions > Translate Korean chit-chat data into Taiwanese using NAVER Machine Translation tool called Papago > Split entire scenarios into train and test set - Train (15,000), Test (2139) - Total: 17,139 Queries / 2000 Scenario (No. of intent) 10 100 500 1,000 70% 80% 90% 100% 60% Company1 Company2 Performance Comparison (Answer Rate)
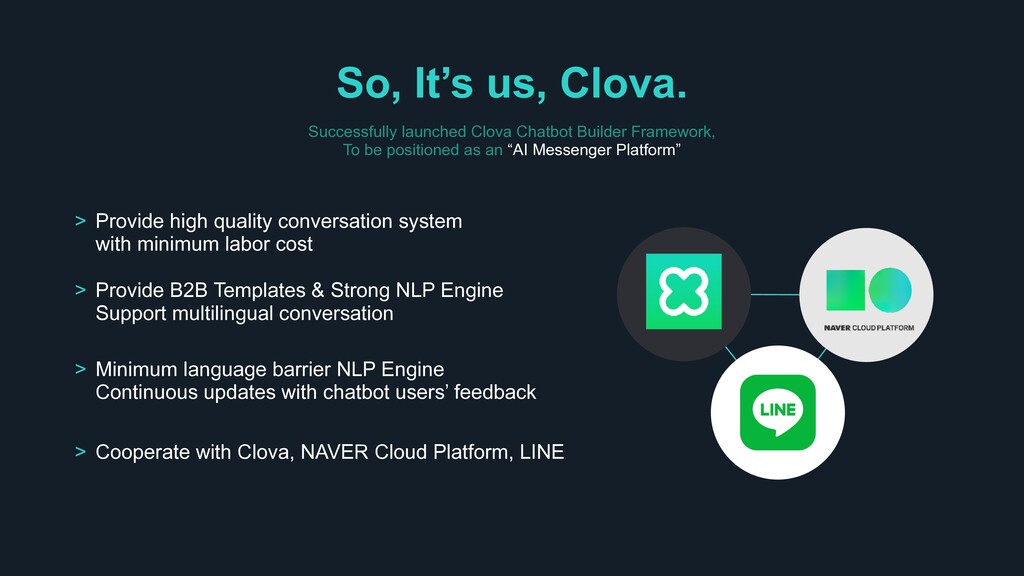
To be positioned as an “AI Messenger Platform” > Minimum language barrier NLP Engine Continuous updates with chatbot users’ feedback > Cooperate with Clova, NAVER Cloud Platform, LINE > Provide B2B Templates & Strong NLP Engine Support multilingual conversation > Provide high quality conversation system with minimum labor cost
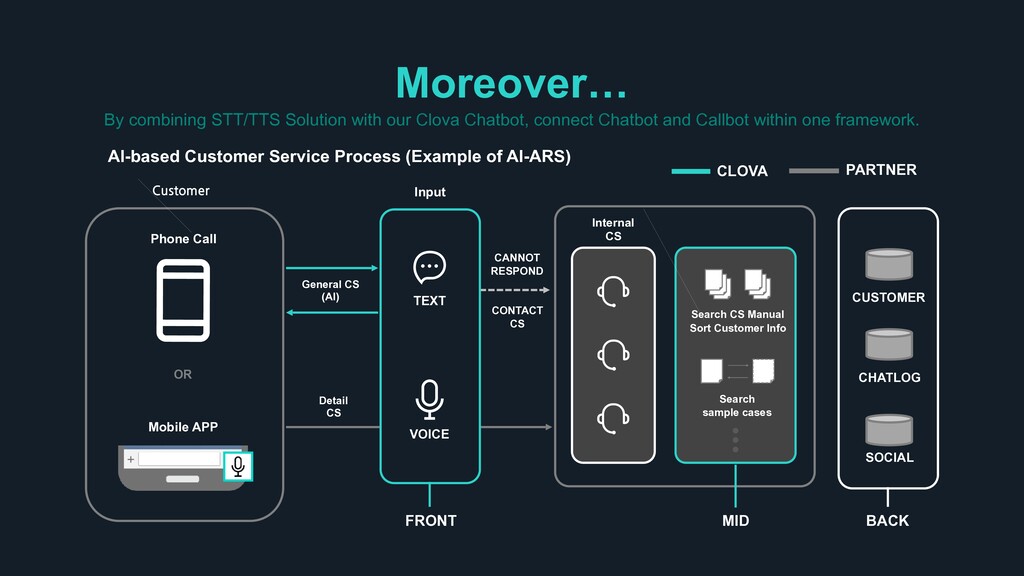
Chatbot and Callbot within one framework. OR Phone Call Mobile APP , CA: CLOVA PARTNER CUSTOMER CHATLOG SOCIAL Search CS Manual Sort Customer Info Search sample cases A A’ Internal CS MID BACK General CS (AI) Detail CS Input TEXT VOICE FRONT CANNOT RESPOND CONTACT CS AI-based Customer Service Process (Example of AI-ARS)
components 1. Use External API to provide answers ${ActionMethod} Answer : Today’s weather in Taipei is ${weather} Example : ${Weather} = http://weather.com?location=#{Bangkok} 2. Provide Mutiple-Choice Type or Short Answer Type ${Form} 3. Complicated customer order & Slot filling to complete such actions from each customer ${Task} , C 2: : , CB 2:C CB : , C : $ 2 BB 2: : , : : : $ 2 BB 2 C N : : ) 2 B ?C?
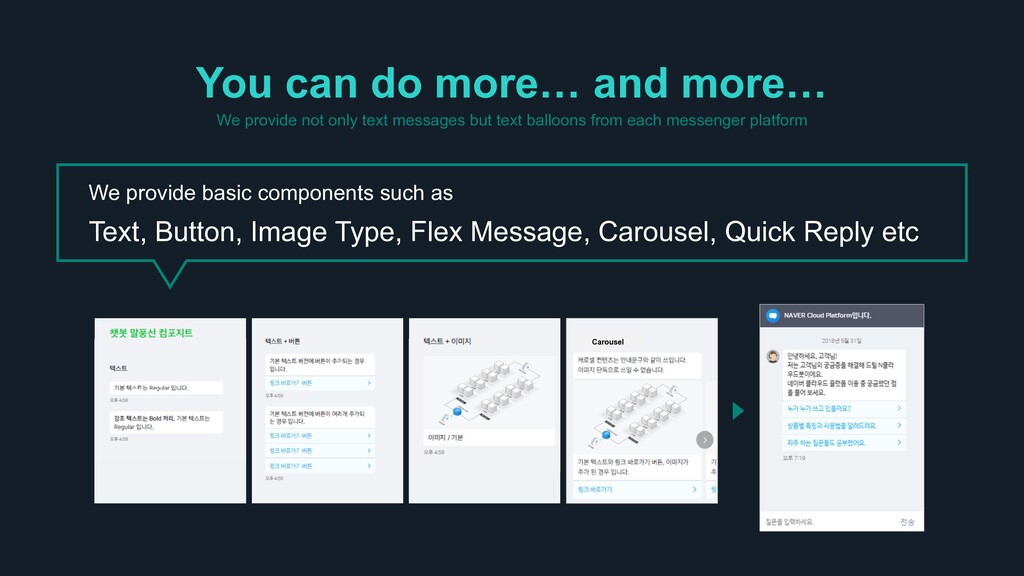
only text messages but text balloons from each messenger platform We provide basic components such as Text, Button, Image Type, Flex Message, Carousel, Quick Reply etc
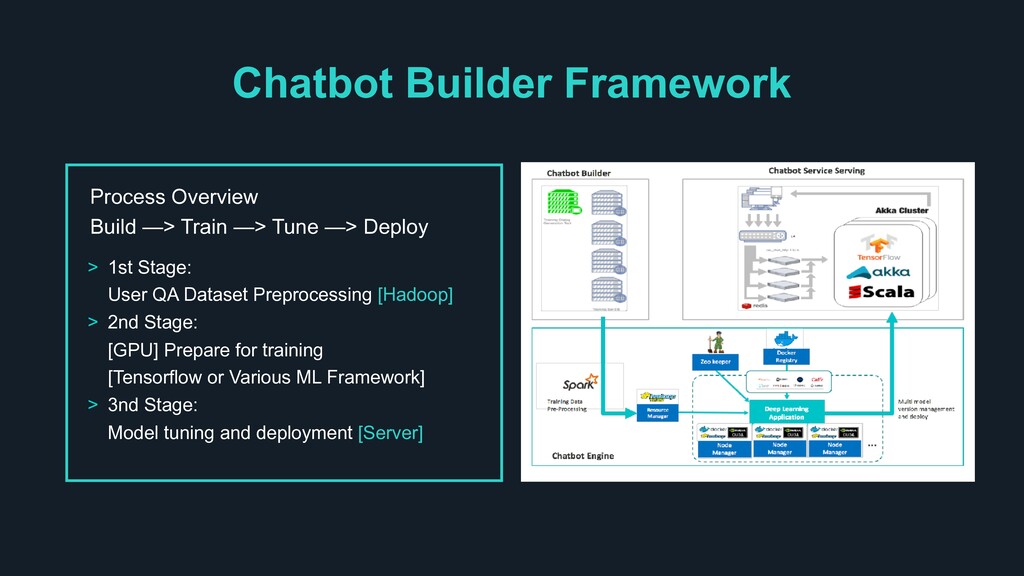
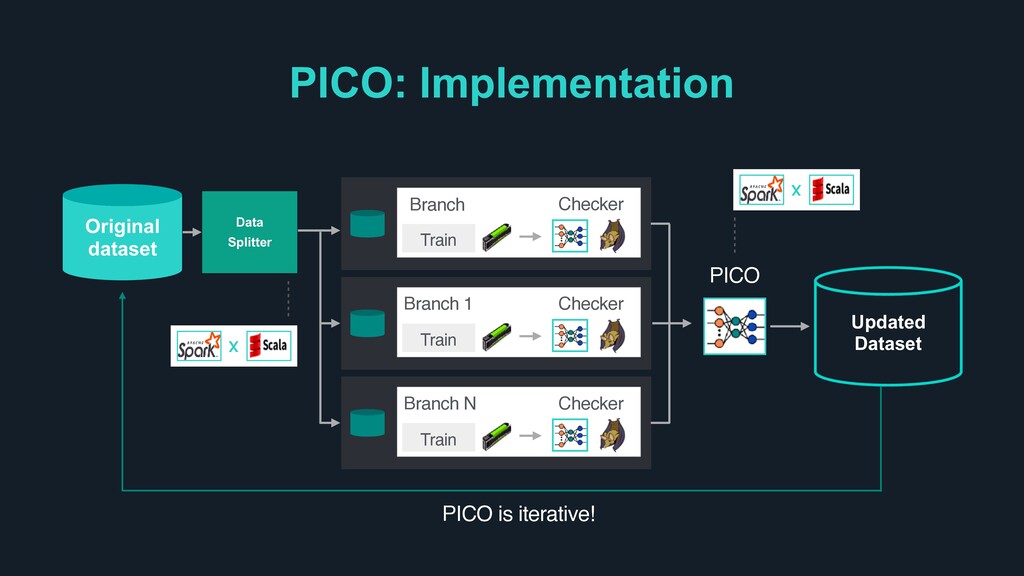
1st Stage: User QA Dataset Preprocessing [Hadoop] > 2nd Stage: [GPU] Prepare for training [Tensorflow or Various ML Framework] > 3nd Stage: Model tuning and deployment [Server] Chatbot Builder Framework
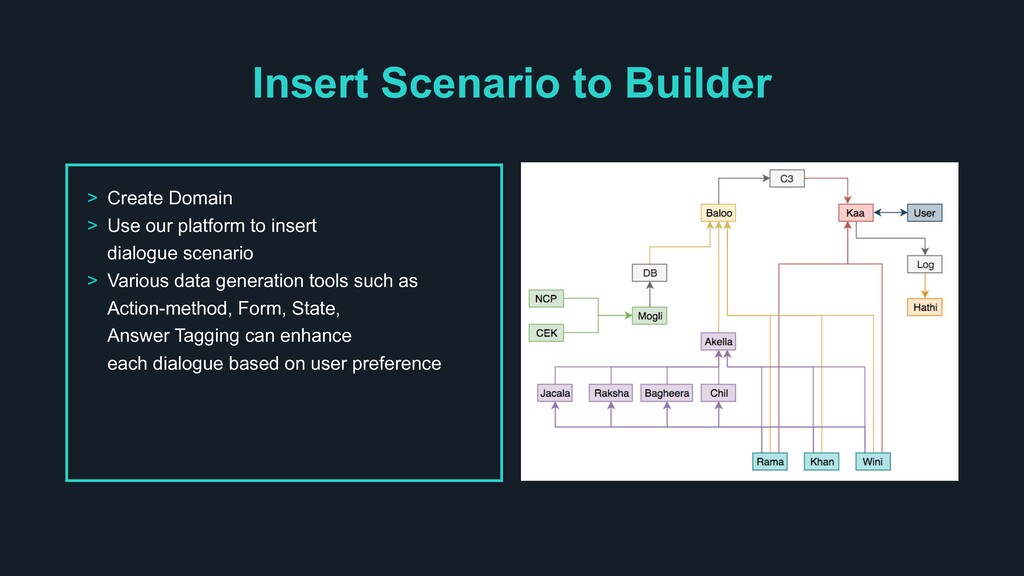
platform to insert dialogue scenario > Various data generation tools such as Action-method, Form, State, Answer Tagging can enhance each dialogue based on user preference
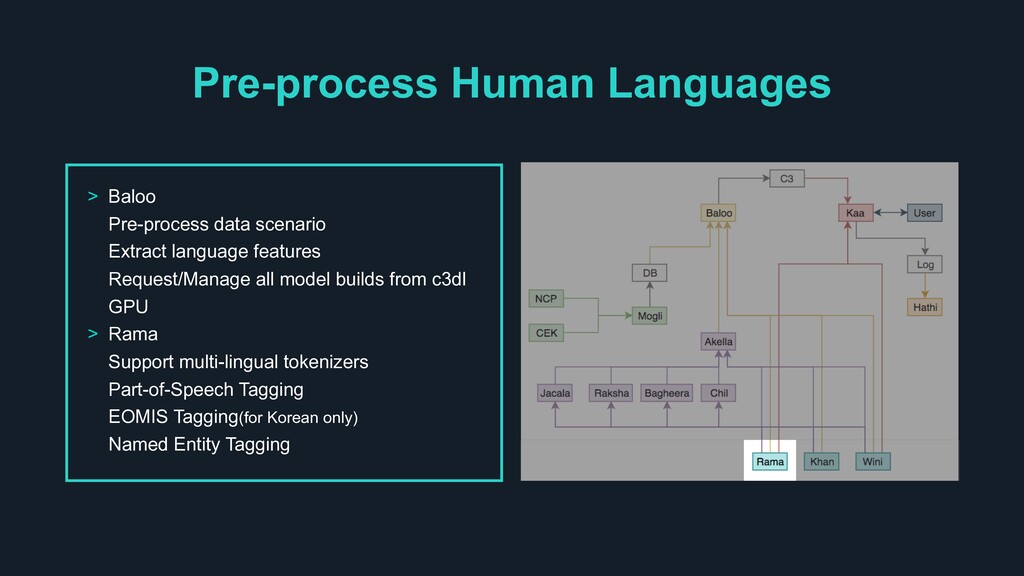
features Request/Manage all model builds from c3dl GPU > Rama Support multi-lingual tokenizers Part-of-Speech Tagging EOMIS Tagging(for Korean only) Named Entity Tagging
to one specific platform > Serve multiple messenger platforms such as LINE, facebook messenger, etc. > Use Akka Sharding to provide non-stop service by communicating with each server
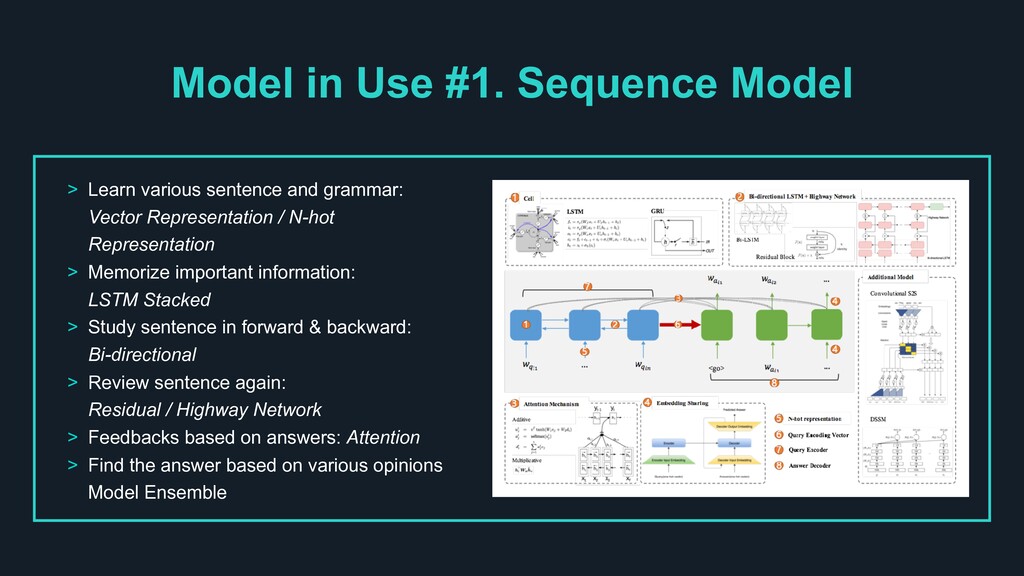
and grammar: Vector Representation / N-hot Representation > Memorize important information: LSTM Stacked > Study sentence in forward & backward: Bi-directional > Review sentence again: Residual / Highway Network > Feedbacks based on answers: Attention > Find the answer based on various opinions Model Ensemble
> Serve as API to provide word-level embeddings with syntactic and semantic information Overall Architecture > Divide into Embedding Layers and Classifier Layers for efficient serving > Feature-based Learning: Freeze Embedding Layers, Train Classifier Layers only —> Fast Training > Fine-tuning: Train both Embedding layers and Classifier layers —> Guarntee High Performance Sentence-level Embedding Layer, Phao > Serve as API to provide sentence-level embeddings with context information
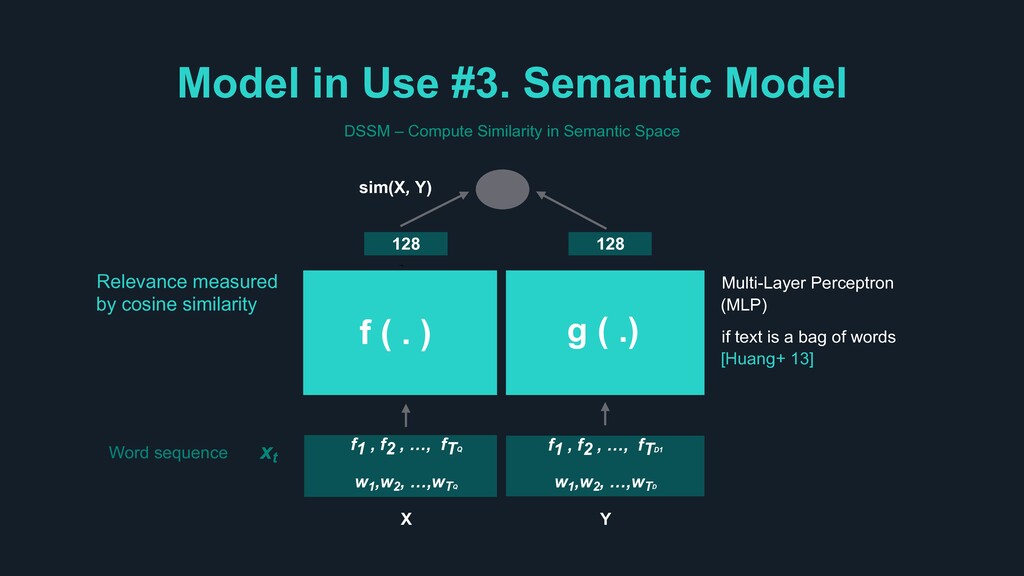
measured by cosine similarity f1 , f2 , …, fTQ w1,w2, …,wTQ 128 sim(X, Y) f1 , f2 , …, fTD1 w1,w2, …,wTD 128 X Y g ( .) f ( . ) Multi-Layer Perceptron (MLP) if text is a bag of words [Huang+ 13] DSSM – Compute Similarity in Semantic Space
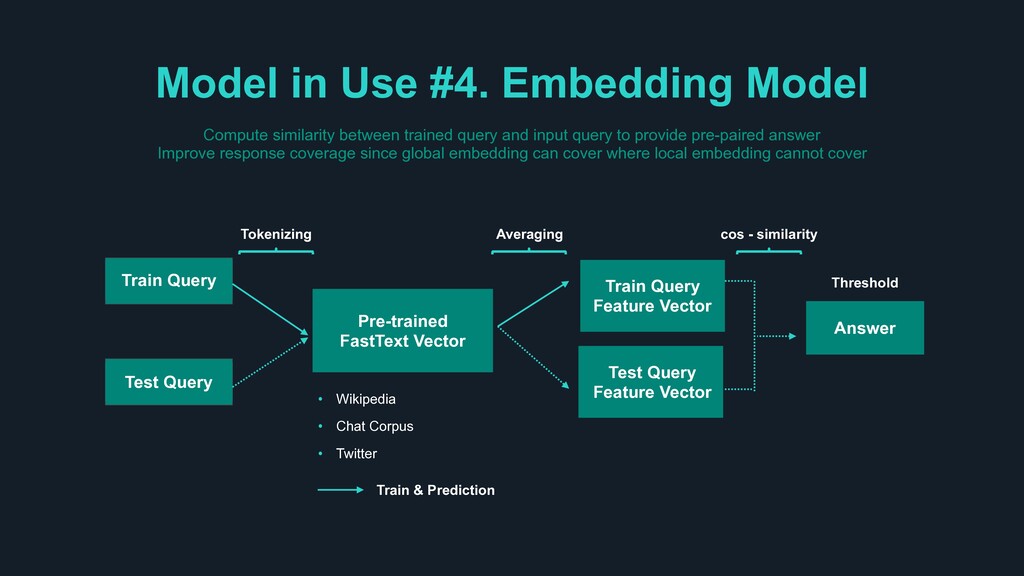
Query Train Query Feature Vector Tokenizing Answer Test Query Test Query Feature Vector Averaging cos - similarity Train & Prediction Threshold • Wikipedia • Chat Corpus • Twitter Compute similarity between trained query and input query to provide pre-paired answer Improve response coverage since global embedding can cover where local embedding cannot cover
: : CB : I: : : BC B I: : C : C : B 1 , C N A:B CB -B :B : : : : CAA:B B : : B : # ,CA : A # C : C CI : B : C : AC : I: C B : : : C -B :B Please recommend a nice restaurant around here Please recommend a nice restaurant around here Please recommend a nice restaurant around here
Vectors from given data corpus • Global Embedding Vectors from Glove, fastText, TAPI, etc. > Locate all words/sentence properly within given vector space > N elements in N-dimensions represent characteristics of each sentence > The Closer embedding vectors, The More Semantically matching
process by applying machine learning algorithms > AI-based solution to the ever-growing challenge by applying machine learning algorithms > Data Preprocessing, Algorithm Selection, Hyperparameter Optimization, etc.
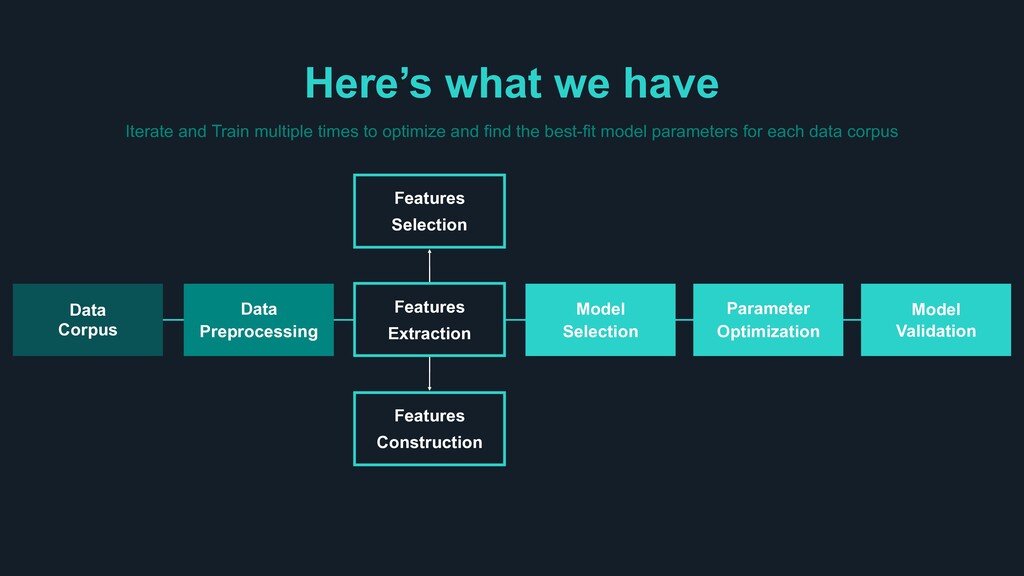
optimize and find the best-fit model parameters for each data corpus Model Selection Features Construction Features Selection Parameter Optimization Model Validation Features Extraction Data Corpus Data Preprocessing
located at the proper vector space > Use Cross-Validation to split train and valid set • Randomly sample from dataset with the ratio of 8:2 • Run several times to prevent model to be less biased > Or, Remove 1~2 queries from each group for evaluation • For each group, choose queries far from the center by computing cosine similarity
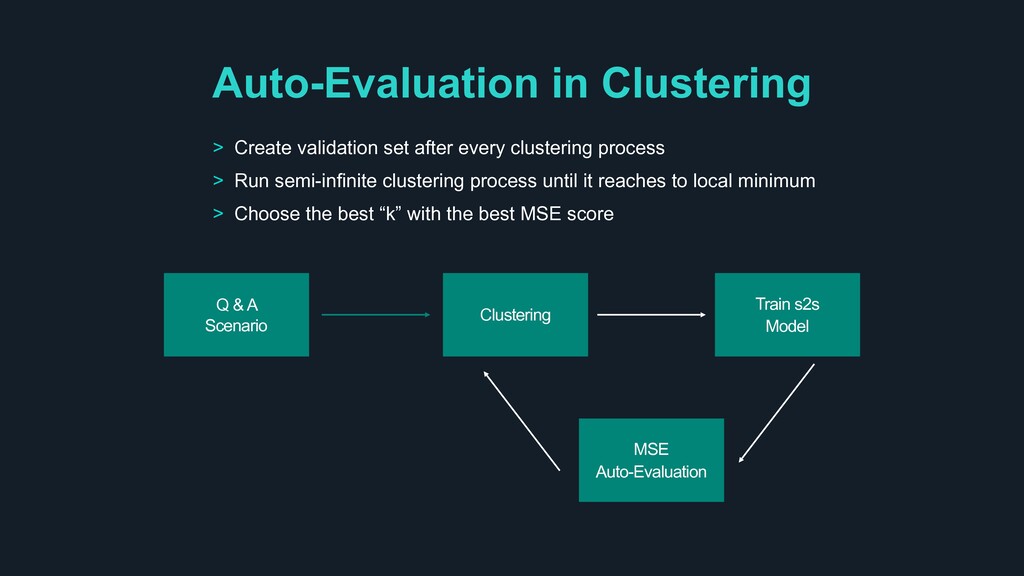
Model MSE Auto-Evaluation > Create validation set after every clustering process > Run semi-infinite clustering process until it reaches to local minimum > Choose the best “k” with the best MSE score
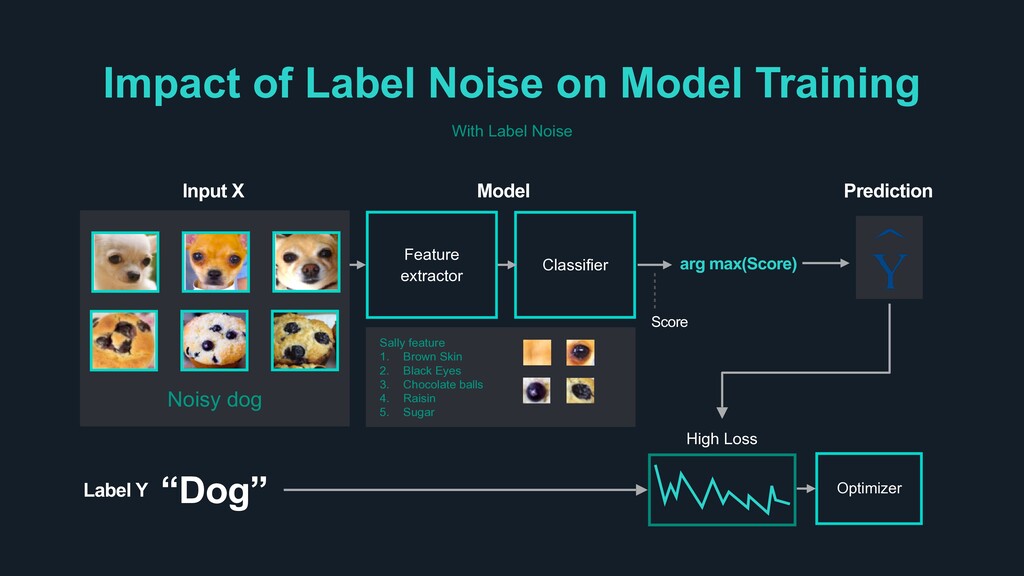
Score Label Y “Dog” Input X Noisy dog arg max(Score) Prediction Feature extractor Classifier Model High Loss Optimizer Sally feature 1. Brown Skin 2. Black Eyes 3. Chocolate balls 4. Raisin 5. Sugar
by models > More Efficiently? More Accurately? • Coordinate Search, Random Search, Genetic Algorithms • Bayesian Hyper-parameter Optimization > Use Cosine Similarity, MSE or Hit Ratio for validation score
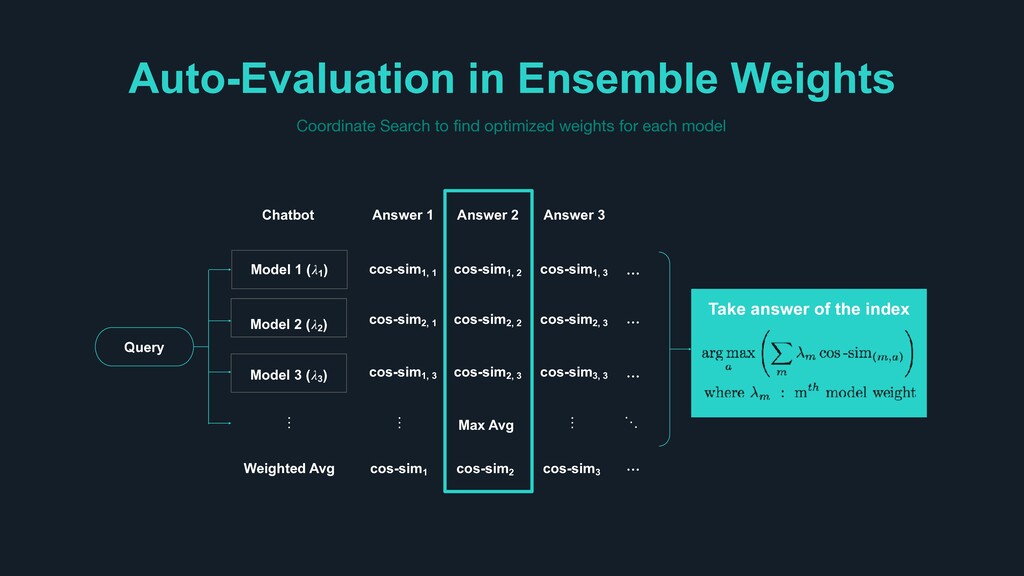
the others > For the given query, Response Selector provides final answer that maximizes the linear combination of each model’s prediction intensity such as cosine similarity and the accuracy of each model as the selection strength so-called ensemble weights Auto-Evaluation in Ensemble Weights
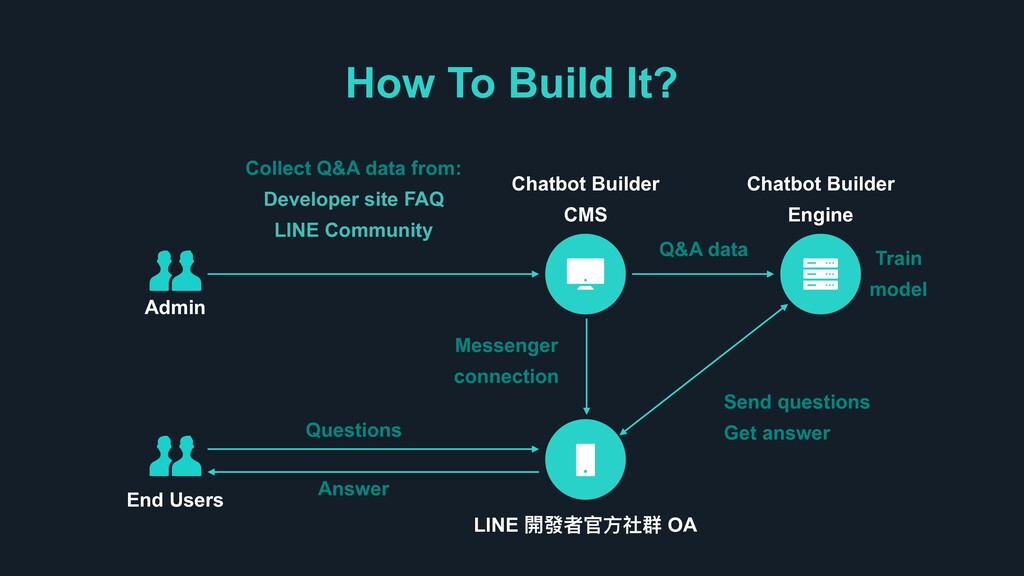
FAQ LINE Community Admin End Users Chatbot Builder CMS Chatbot Builder Engine LINE 樄咳ᘏਥොᐒᗭ OA Questions Answer Q&A data Messenger connection Send questions Get answer Train model
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}