2. Situs mengenai berita-berita di Indonesia 3. No.2 online news portal di Indonesia 4. Dimulai sejak Agustus 2014 5. Pengunjung website mencapai 3.5 Juta per Hari 6. Total artikel 1.2 Juta 7. Rata-rata comment per hari sebanya 550 comment
2. Sebuah wadah untuk video sharing, fokus kepada local content creator 3. No.1 local video sharing di Indonesia 4. Dimulai sejak Agustus 2014 5. Pengunjung mencapai 1 Juta per Hari 6. Total video 300 ribu 7. Rata-rata upload video per hari 550 video 8. Rata-rata comment per hari 200 comments
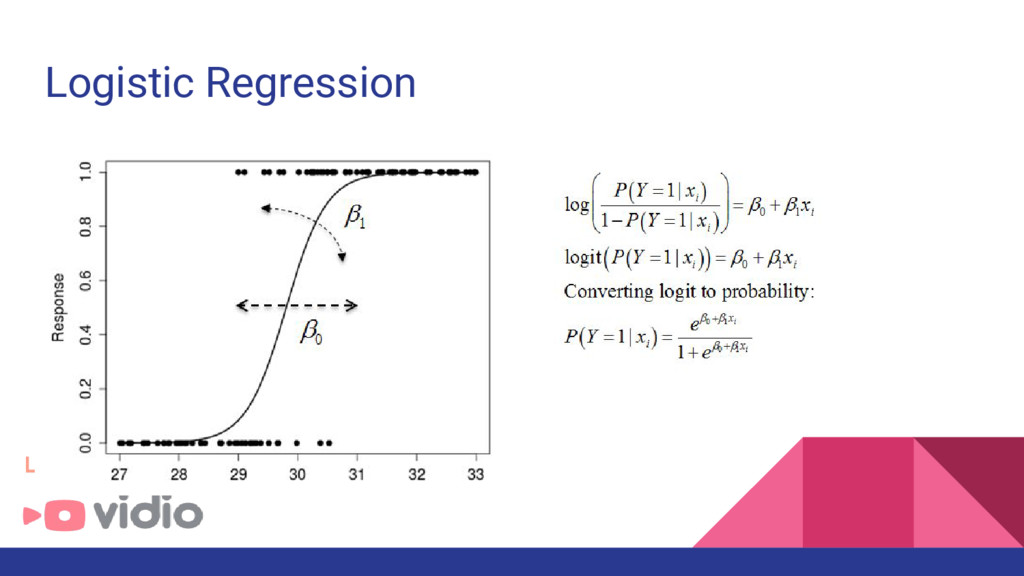
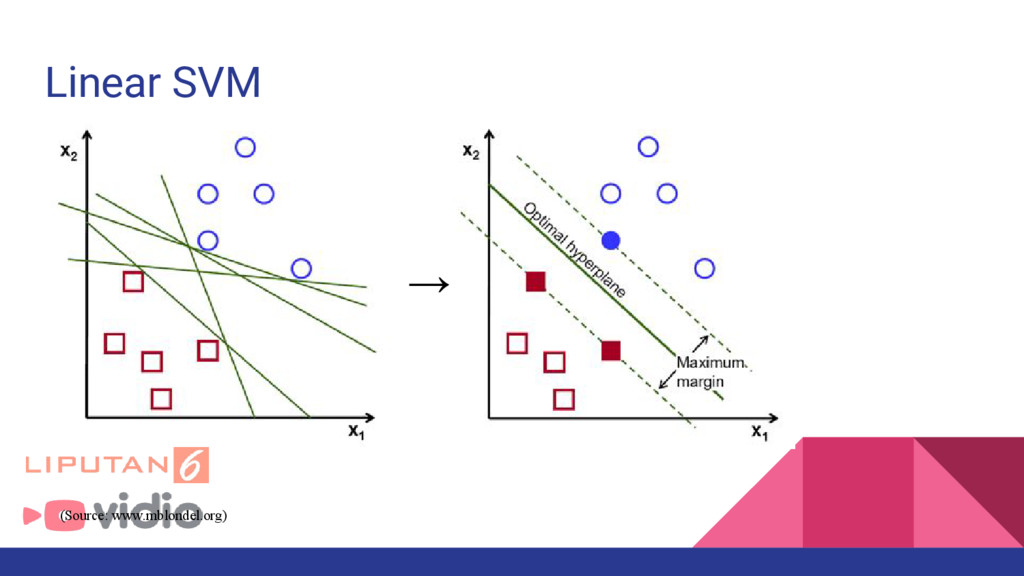
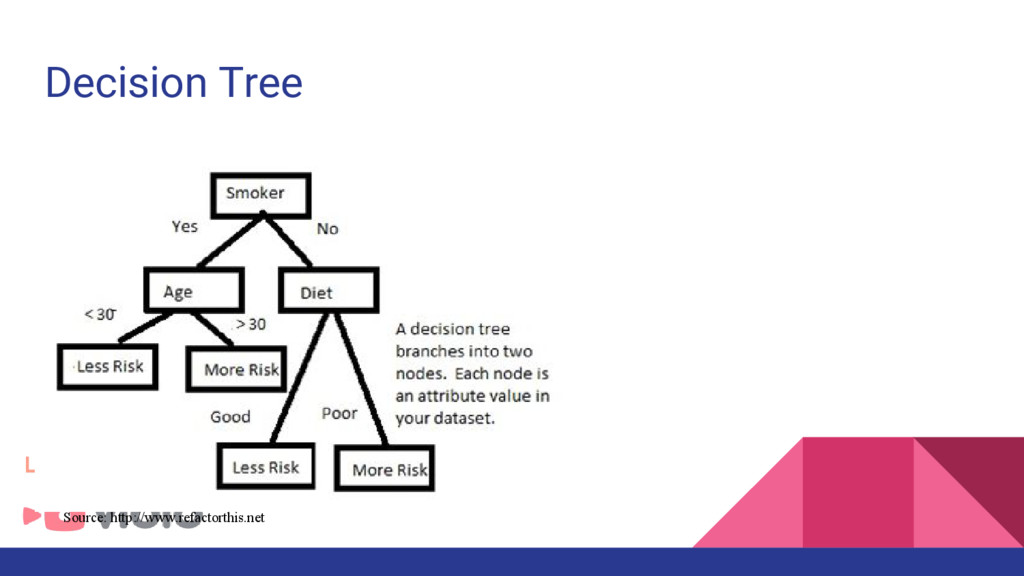
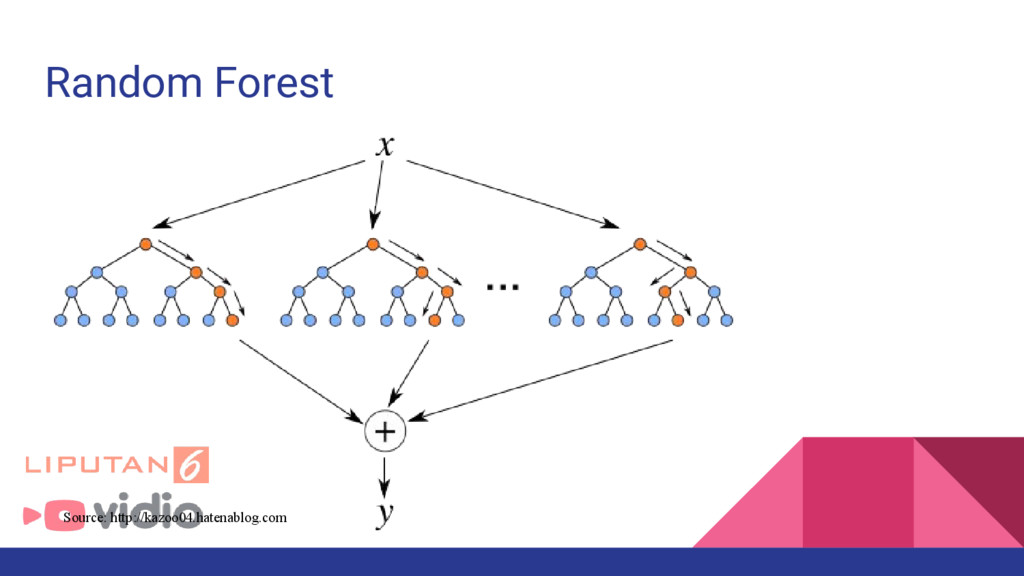
and Personal SMS Spam Filtering Feature : Word occurence, Classifier : Naive Bayes, SVM 2. Tiago. A. Almeid et al : Contributions to the study of SMS Spam Filtering: New Collection and Results Feature : Word Count, Classifier : Naive Bayes, k-Nearest Network, Decision Tree, SVM 3. Sin-Eon Kim et al : SMS Spam Filterinig Using Keyword Frequency Ratio Feature : Frequency ratio, Classifier : Naive Bayes, Decision Tree, Logistic Regression
(title and descriptions) from vidio.com 2. All data collect before September 2015 3. Composition from 284,976 data : a. 135,160 (47.45%) is Spam (labeled with 0) b. 148,816 (52.55%) is Ham (labeled with 1) 4. We offered is available to public by requests
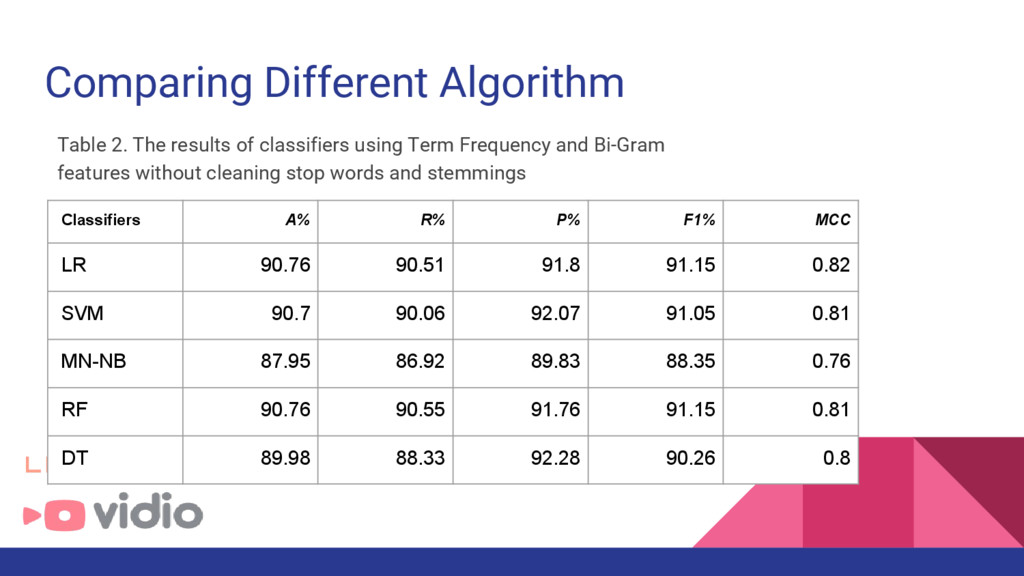
dan Zhang et al [2] mengatakan jika menggunakan stemming dan stop words akan menurunkan performa dari classifier. Untuk itu pada penelitian ini kita akan membandingkan hasil antara menggunakan stemming dan classifier dan dengan tidak menggunakan 4. Stop words yang akan digunakan adalah stop words dari Tala [3] [1] Gordon V. Cormack. 2008. Email Spam Filtering: A Systematic Review. Found. Trends Inf. Retr. 1, 4 (April 2008), 335-455. DOI=http://dx.doi.org/10.1561/1500000006 [2] Le Zhang, Jingbo Zhu, and Tianshun Yao. 2004. An evaluation of statistical spam filtering techniques. 3, 4 (December 2004), 243-269. DOI=http://dx.doi.org/10. 1145/1039621.1039625 [3] Tala, F. 2003. A study of stemming effects on information retrieval in Bahasa Indonesia. M.S. thesis, University of Amsterdam.
train (199,483 contents) and 30 % data test (85,943 contents). • Not using technique to reduce the dimensionality of the training data. • To comparing the results we are using measures Accuracy (A), Recall (R), Precision (P), F1-Score (F1), and Matthews Correlation Coefficient (MCC) [1]. [1] Tiago A. Almeida, Akebo Yamakami, and Jurandy Almeida. 2009. Evaluation of Approaches for Dimensionality Reduction Applied with Naive Bayes Anti-Spam Filters. In Proceedings of the 2009 International Conference on Machine Learning and Applications (ICMLA '09). IEEE Computer Society, Washington, DC, USA, 517-522. DOI=http://dx.doi.org/10. 1109/ICMLA.2009.22
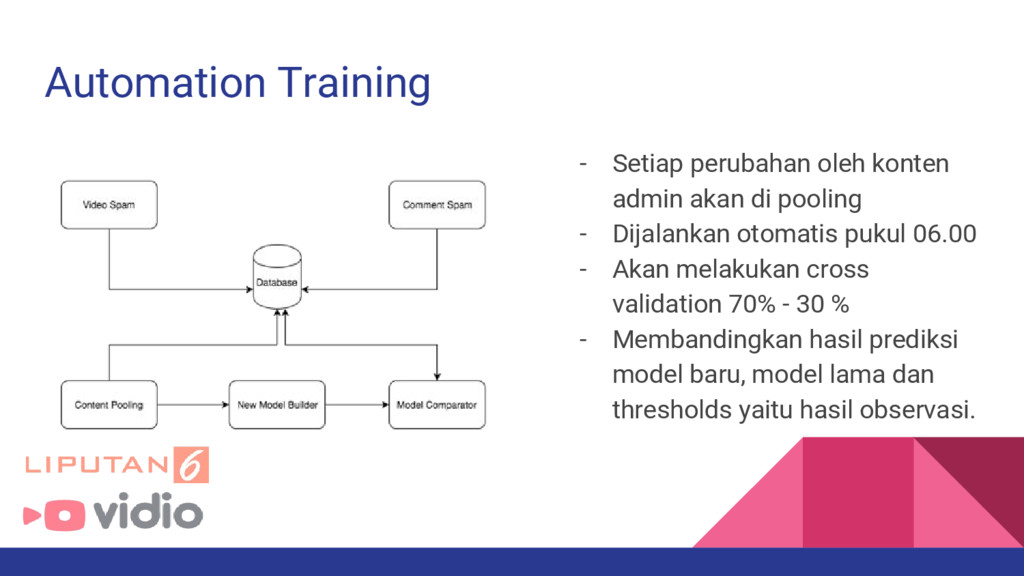
pooling - Dijalankan otomatis pukul 06.00 - Akan melakukan cross validation 70% - 30 % - Membandingkan hasil prediksi model baru, model lama dan thresholds yaitu hasil observasi.
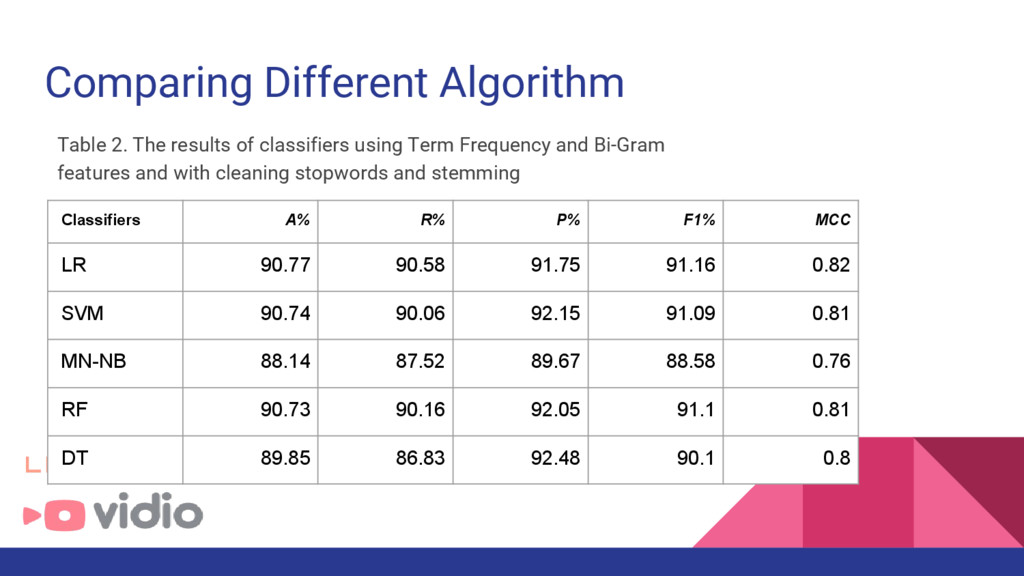
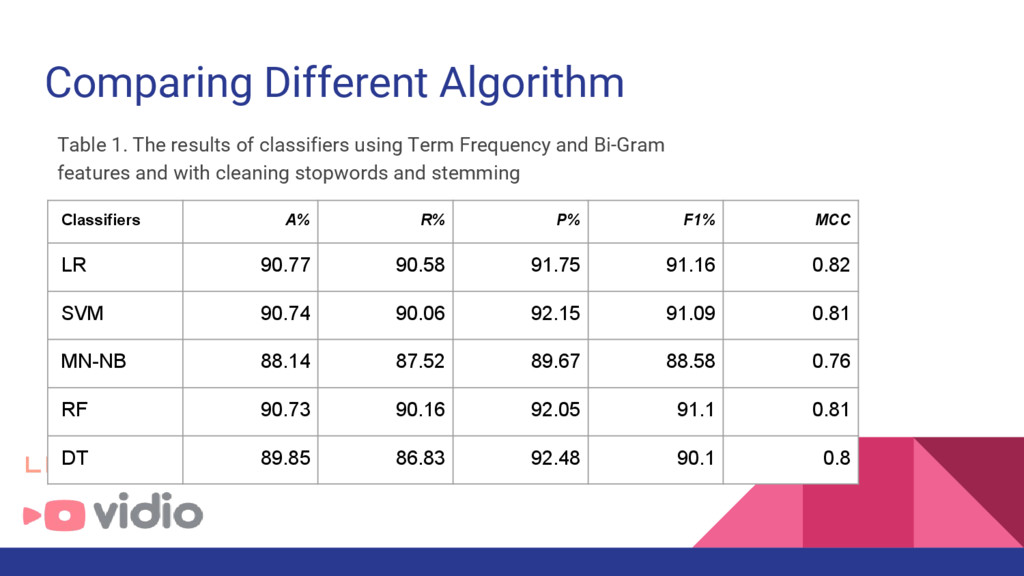
• Membersihkan dan melakukan stemming dapat meningkatkan performa baik • Sukses melakukan deteksi spam sebanyak 47.694 (26,4 %) dari seluruh content yg masuk dari bulan November 2015 - April 2016
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Tahap - tahap Dataset Cleaning 3. Gordon et al [1]](https://files.speakerdeck.com/presentations/ac14f30e27e5470f84315b006fa53f81/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}