evaluation and comparison of programs dealing with quantitative tasks in historical linguistics requires a large number of accurate reference sets which can be used as test cases to identify the strong and weak points of the numerous programs. (Original Plagiarism) 3 / 30
evaluation and comparison of programs dealing with quantitative tasks in historical linguistics requires a large number of accurate reference sets which can be used as test cases to identify the strong and weak points of the numerous programs. (Original Plagiarism) 3 / 30
comprehensive evaluation and comparison of alignment programs requires a large number of accurate reference alignments which can be used as test cases. It has been shown (McClure et al., 1994) that the performance of alignment programs depends on the number of sequences, the degree of similarity between sequences and the number of insertions in the alignment. [...] We have constructed BAliBASE (Benchmark Alignment dataBASE) containing high-quality, documented alignments to identify the strong and weak points of the numerous alignment programs now available. (Thompson et al. 1998: 87) 3 / 30
need Benchmark Databases? For comparative reasons, since otherwise, we won’t be able to really tell whether two independently proposed algorithms exhibit a similar performance or not. 4 / 30
need Benchmark Databases? For comparative reasons, since otherwise, we won’t be able to really tell whether two independently proposed algorithms exhibit a similar performance or not. For development reasons, since we should test our new algorithms on actual data in order to guarantee their applicability and accuracy. 4 / 30
I care for Benchmark Databases? Who said you need to care? If you are no historical linguist or dialectologist or typologist, or not interested in quantitative applications but prefer to do everything manually, or 5 / 30
I care for Benchmark Databases? Who said you need to care? If you are no historical linguist or dialectologist or typologist, or not interested in quantitative applications but prefer to do everything manually, or not interested in enhancing and formalizing existing methods with help of computational approaches, 5 / 30
I care for Benchmark Databases? Who said you need to care? If you are no historical linguist or dialectologist or typologist, or not interested in quantitative applications but prefer to do everything manually, or not interested in enhancing and formalizing existing methods with help of computational approaches, then you don’t need to care about benchmark databases at all... . 5 / 30
I care for Benchmark Databases? Who said you need to care? If you are no historical linguist or dialectologist or typologist, or not interested in quantitative applications but prefer to do everything manually, or not interested in enhancing and formalizing existing methods with help of computational approaches, then you don’t need to care about benchmark databases at all... . But please don’t jump out of the room right now, I will make some jokes you shouldn’t miss in the end of the talk. . 5 / 30
I care for Benchmark Databases? Who said you need to care? If you are no historical linguist or dialectologist or typologist, or not interested in quantitative applications but prefer to do everything manually, or not interested in enhancing and formalizing existing methods with help of computational approaches, then you don’t need to care about benchmark databases at all... . But please don’t jump out of the room right now, I will make some jokes you shouldn’t miss in the end of the talk. . I promise! 5 / 30
What do you mean by “Gold Standard”? Is the data simulated? There is no such thing as a “Gold Standard”. How can you make a “Gold Standard” if even historical linguists do not really have a clue what was going on? 7 / 30
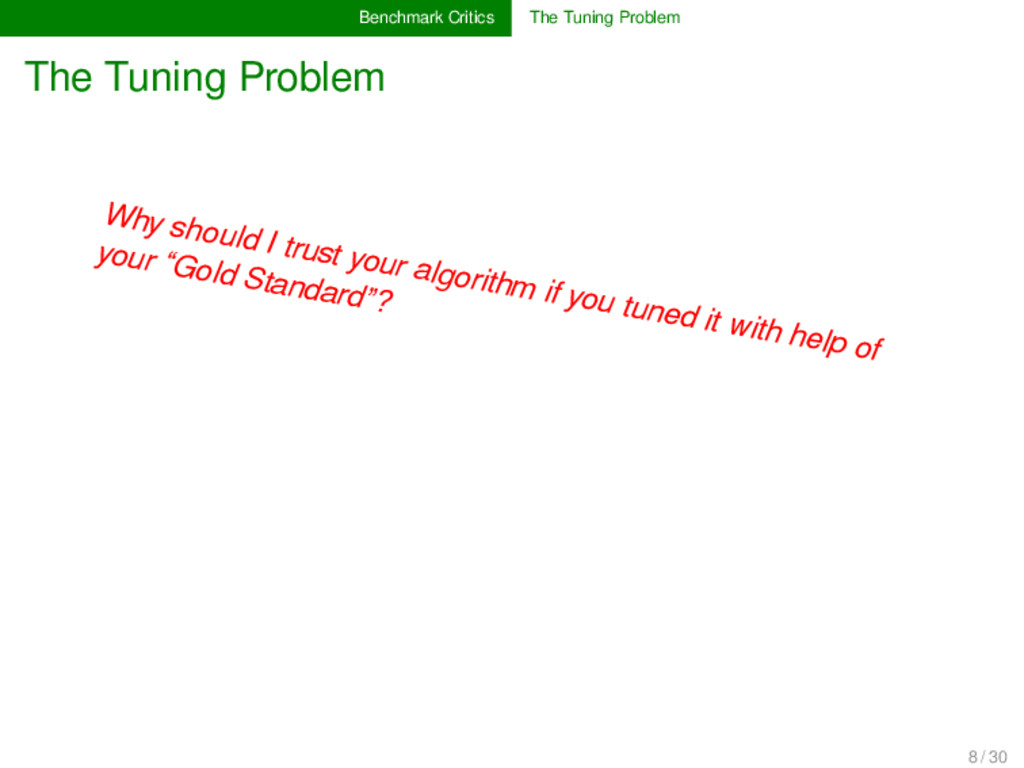
I trust your algorithm if you tuned it with help of your “Gold Standard”? Seriously, how can I trust your algorithm despite all the scores if it fails to find the correspondences between Armenian [jɛɾˈku] and German [t͜svai]?!? 8 / 30
you used the data of XYZ to create your benchmark. Why didn’t you create your own dataset? Oh, you created the benchmark data YOURSELF. Why didn’t you use the excellent data by XYZ? 9 / 30
you used the data of XYZ to create your benchmark. Why didn’t you create your own dataset? Oh, you created the benchmark data YOURSELF. Why didn’t you use the excellent data by XYZ? How could you use the data of XYZ as the basis for your “Gold Standard” for Germanic languages, given that EVERYONE knows that their reconstruction of Proto-Nostratic is complete nonsense? 9 / 30
Historical Linguistics Our knowledge of the past is a construct in the sense used in psychology (cf. Cronbach and Meehl 1995). This does not mean that what we know is just a “wissenschaftliche Fiktion” (Schmidt 1872). There are good reasons to be confident that our traditional methods are better than random guesses. 11 / 30
Historical Linguistics Our knowledge of the past is a construct in the sense used in psychology (cf. Cronbach and Meehl 1995). This does not mean that what we know is just a “wissenschaftliche Fiktion” (Schmidt 1872). There are good reasons to be confident that our traditional methods are better than random guesses. Although we should be careful in writing Indo-European fables, there are also good reasons to be confident that our methods uncover some kind of reality (cf. Saussure’s prediction of laryngeals in 1879). 11 / 30
Historical Linguistics Our knowledge of the past is a construct in the sense used in psychology (cf. Cronbach and Meehl 1995). This does not mean that what we know is just a “wissenschaftliche Fiktion” (Schmidt 1872). There are good reasons to be confident that our traditional methods are better than random guesses. Although we should be careful in writing Indo-European fables, there are also good reasons to be confident that our methods uncover some kind of reality (cf. Saussure’s prediction of laryngeals in 1879). If it was not for these reasons that give us confidence in our traditional methods, then why should we bother pursuing them? 11 / 30
Historical Linguistics Our knowledge of the past is a construct in the sense used in psychology (cf. Cronbach and Meehl 1995). This does not mean that what we know is just a “wissenschaftliche Fiktion” (Schmidt 1872). There are good reasons to be confident that our traditional methods are better than random guesses. Although we should be careful in writing Indo-European fables, there are also good reasons to be confident that our methods uncover some kind of reality (cf. Saussure’s prediction of laryngeals in 1879). If it was not for these reasons that give us confidence in our traditional methods, then why should we bother pursuing them? As long as we are confident that our traditional methods work more or less, we can use our traditional knowledge to compile benchmark databases and to test, how “good” automatic methods work. 11 / 30
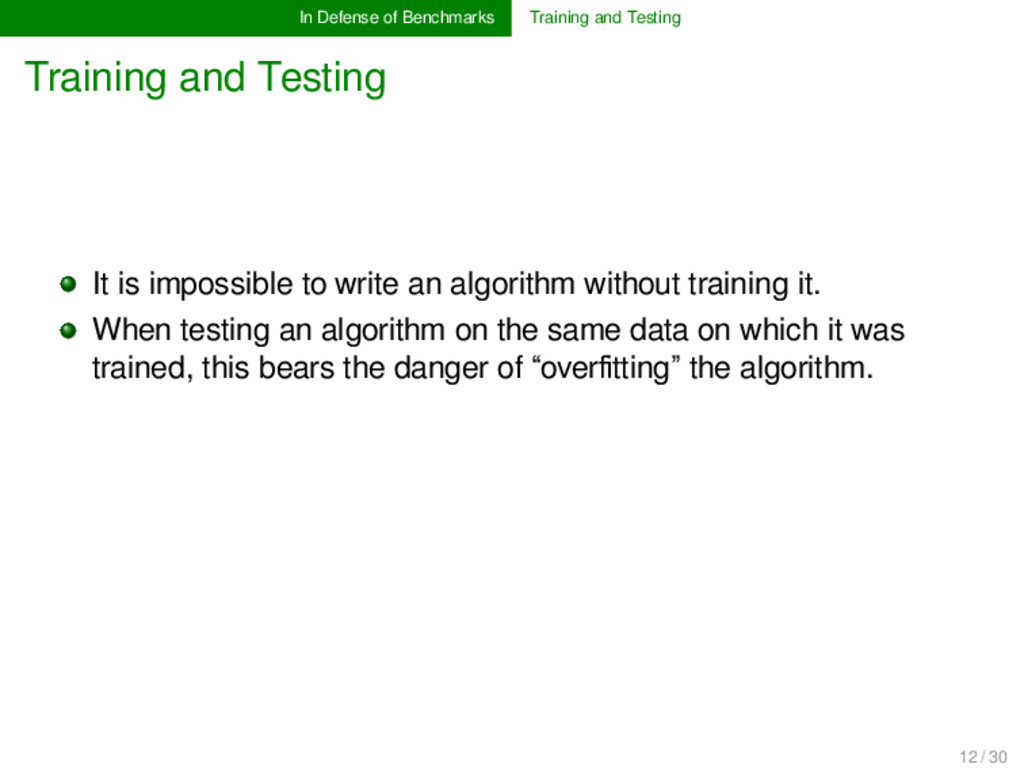
It is impossible to write an algorithm without training it. When testing an algorithm on the same data on which it was trained, this bears the danger of “overfitting” the algorithm. 12 / 30
It is impossible to write an algorithm without training it. When testing an algorithm on the same data on which it was trained, this bears the danger of “overfitting” the algorithm. The fact that benchmark databases often serve both to train and to test the algorithms may be considered as problematic. Nevertheless, this is no real problem of benchmarks, but of the way how benchmarks are handled by those who write and train the programs. 12 / 30
Ideally, a benchmark database in historical linguistics serves as a standard for training new algorithms, testing new algorithms, and defining common formats used by the algorithms. 13 / 30
Ideally, a benchmark database in historical linguistics serves as a standard for training new algorithms, testing new algorithms, and defining common formats used by the algorithms. A benchmark database can be much more than a simple database. It can help to initiate the standardization of formats for data exchange and storage and thus force those who design new algorithms to comply with them. 13 / 30
data is already there, but it needs to be cleaned, referenced, linked, and checked before publication. Since the data should be provided in form of multiple alignments, the alignments for all cognate sets compared to the proto-forms need to be manually checked. For further data, cooperations are planned (some of the collaborators do not yet know that they are among those lucky ones that have been chosen...). 17 / 30
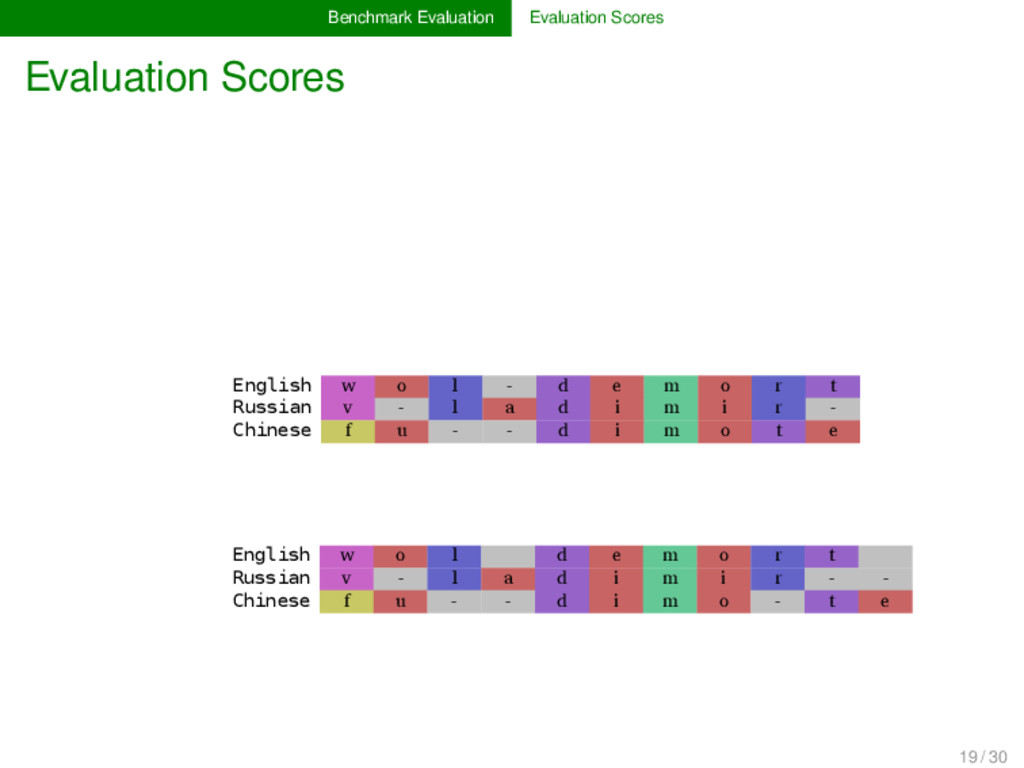
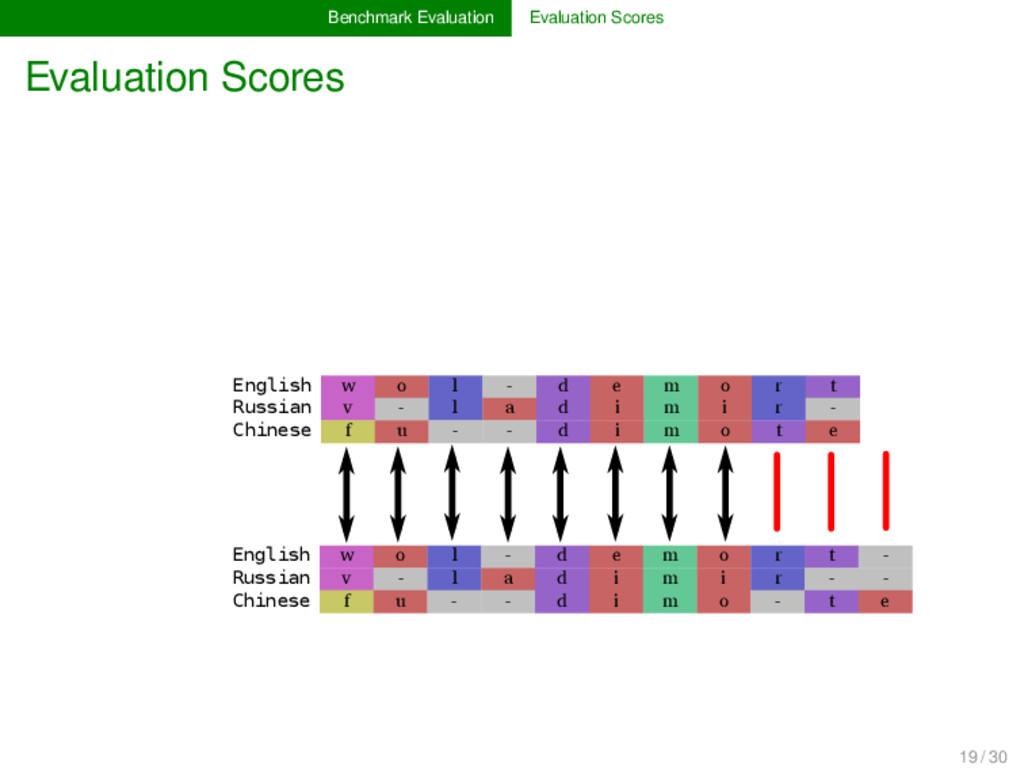
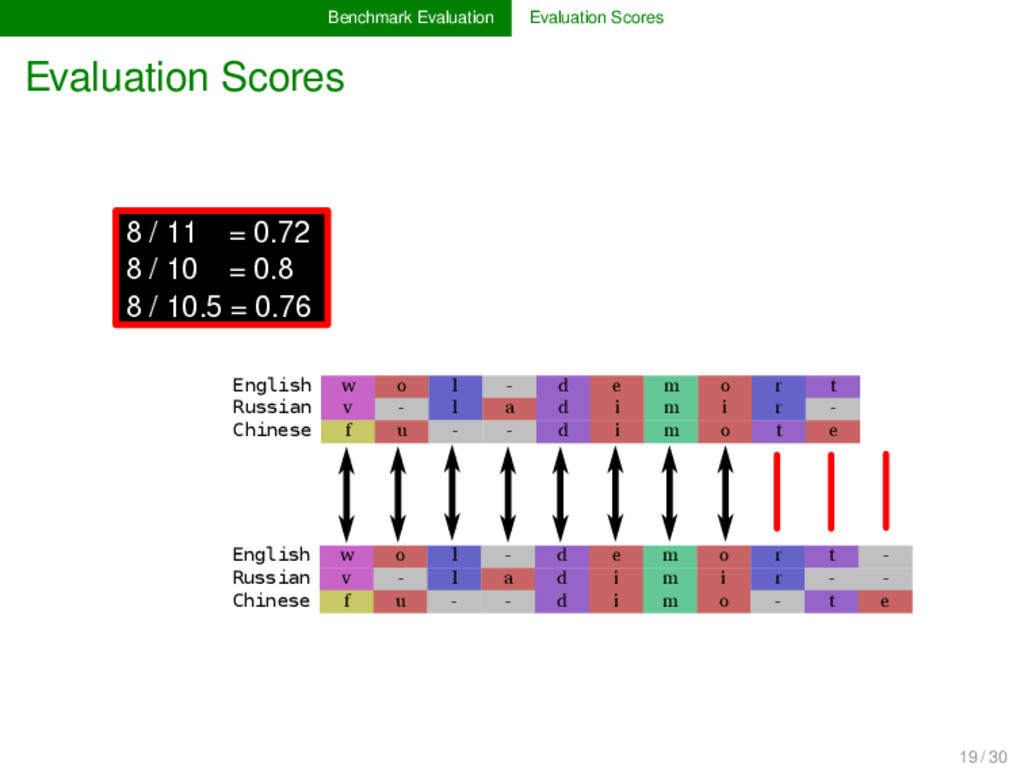
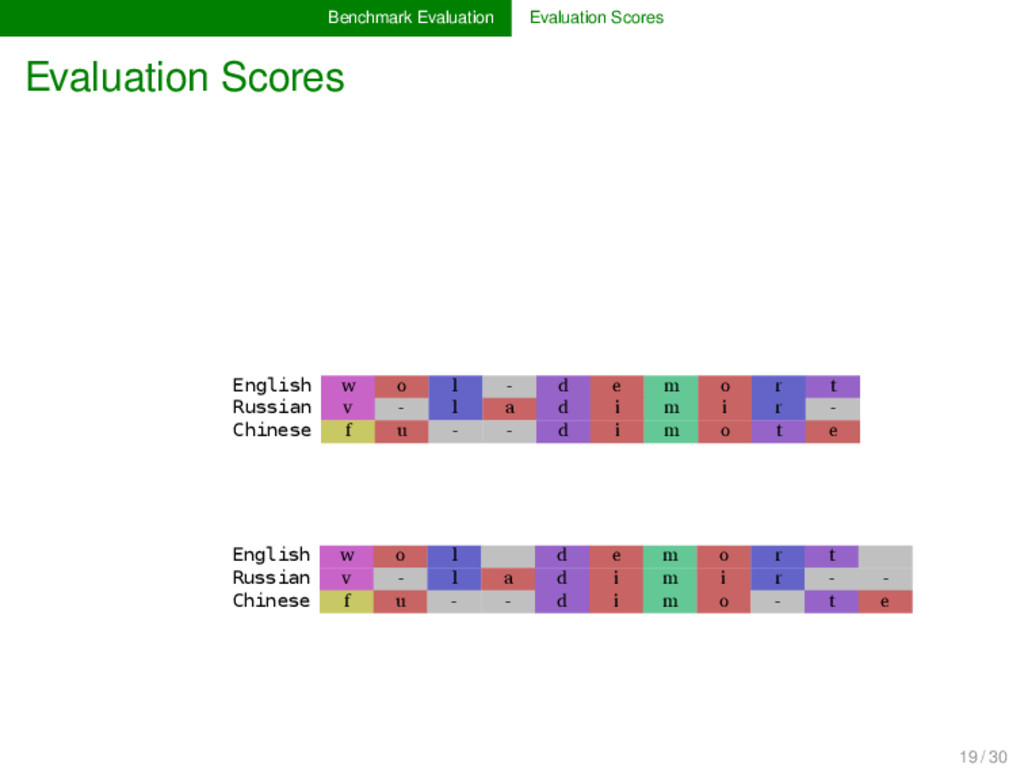
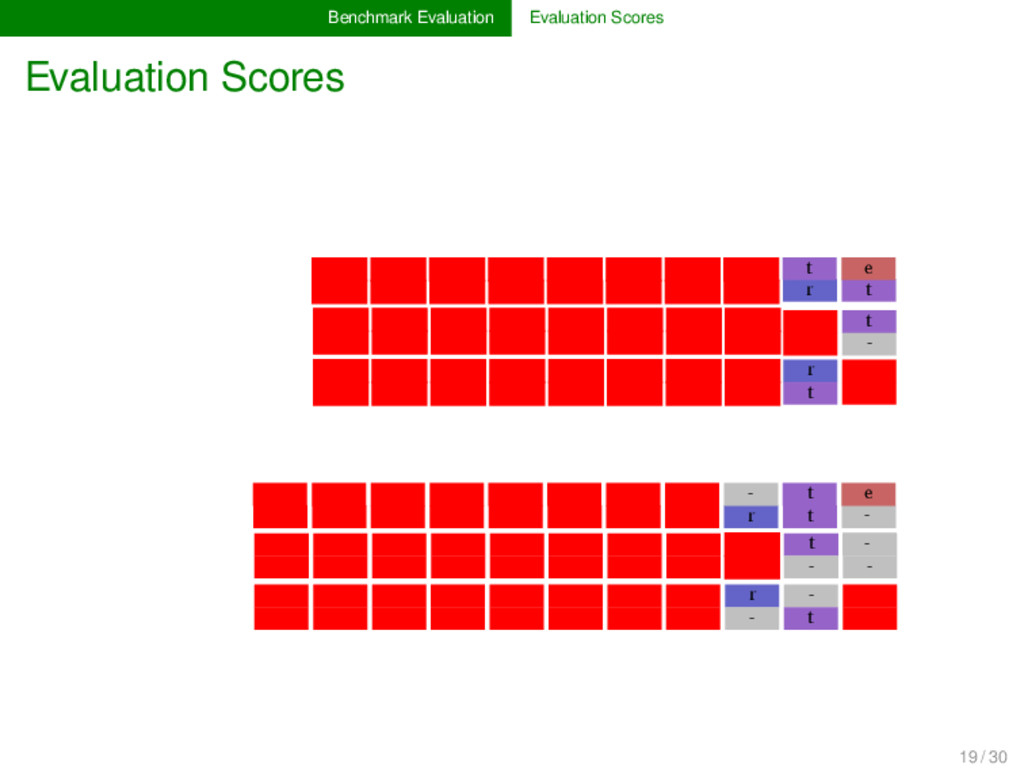
- d e m o r t Russian v - l a d i m i r - Chinese f u - - d i m o t e English w o l d e m o r t Russian v - l a d i m i r - - Chinese f u - - d i m o - t e 8 / 11 = 0.72 8 / 10 = 0.8 8 / 10.5 = 0.76 19 / 30
- d e m o r t Russian v - l a d i m i r - Chinese f u - - d i m o t e XXX XXX XXX XXX XXX XXX XXX XXX XXX XXX English w o l - d e m o r t - Russian v - l a d i m i r - - Chinese f u - - d i m o - t e 8 / 11 = 0.72 8 / 10 = 0.8 8 / 10.5 = 0.76 19 / 30
- d e m o r t Russian v - l a d i m i r - Chinese f u - - d i m o t e XXX XXX XXX XXX XXX XXX XXX XXX XXX XXX English w o l - d e m o r t - Russian v - l a d i m i r - - Chinese f u - - d i m o - t e 8 / 11 = 0.72 8 / 10 = 0.8 8 / 10.5 = 0.76 19 / 30
- d e m o r t Russian v - l a d i m i r - Chinese f u - - d i m o t e English w o l d e m o r t Russian v - l a d i m i r - - Chinese f u - - d i m o - t e 8 / 11 = 0.72 8 / 10 = 0.8 8 / 10.5 = 0.76 19 / 30
w o l d e m o r t f u - - d i m o - t e w o l d e m o r t v - l a d i m i r - - - - v - l a d i m i r - - f u - - d i m o - t e w o l d e m o f u - - d i m o w o l d e m o v - l a d i m i - v - l a d i m i f u - - d i m o r t t e r t r - English Russian English Russian Russian Chinese Russian Chinese English Chinese English Chinese 19 / 30
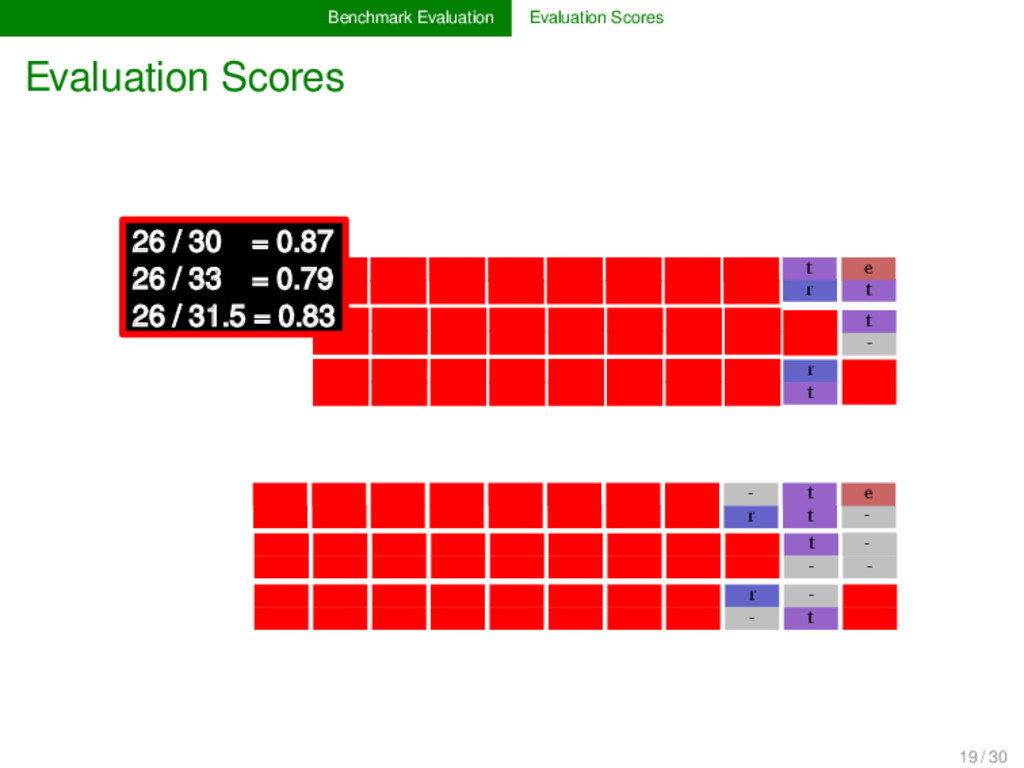
25 / 30 = 0.83 25 / 33 = 0.76 25 / 31.5 = 0.80 w o l d e m o r t f u - - d i m o - t e w o l d e m o r t v - l a d i m i r - - - - v - l a d i m i r - - f u - - d i m o - t e w o l d e m o f u - - d i m o w o l d e m o v - l a d i m i - v - l a d i m i f u - - d i m o r t t e r t r - - 19 / 30
o l v - l v - l f u - r - t e 26 / 30 = 0.87 26 / 33 = 0.79 26 / 31.5 = 0.83 w o l d e m o r t f u - - d i m o - t e w o l d e m o r t v - l a d i m i r - - - - v - l a d i m i r - - f u - - d i m o - t e d e m o - d i m o d e m o a d i m i - a d i m i - d i m o r t t e r t r - - 19 / 30
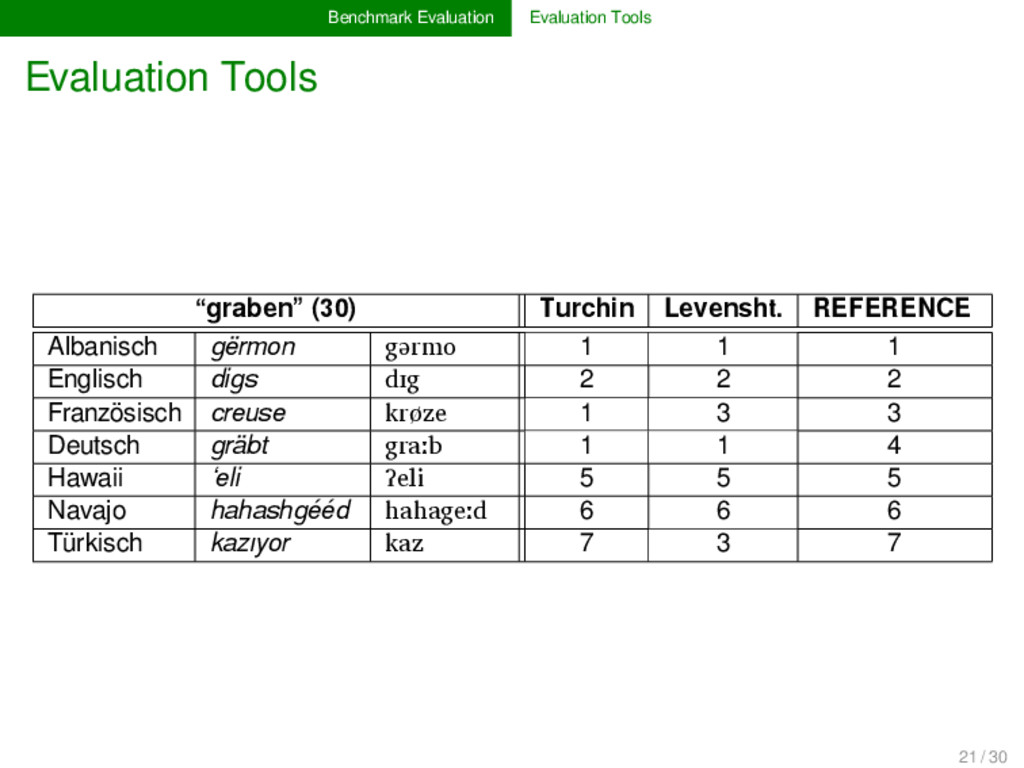
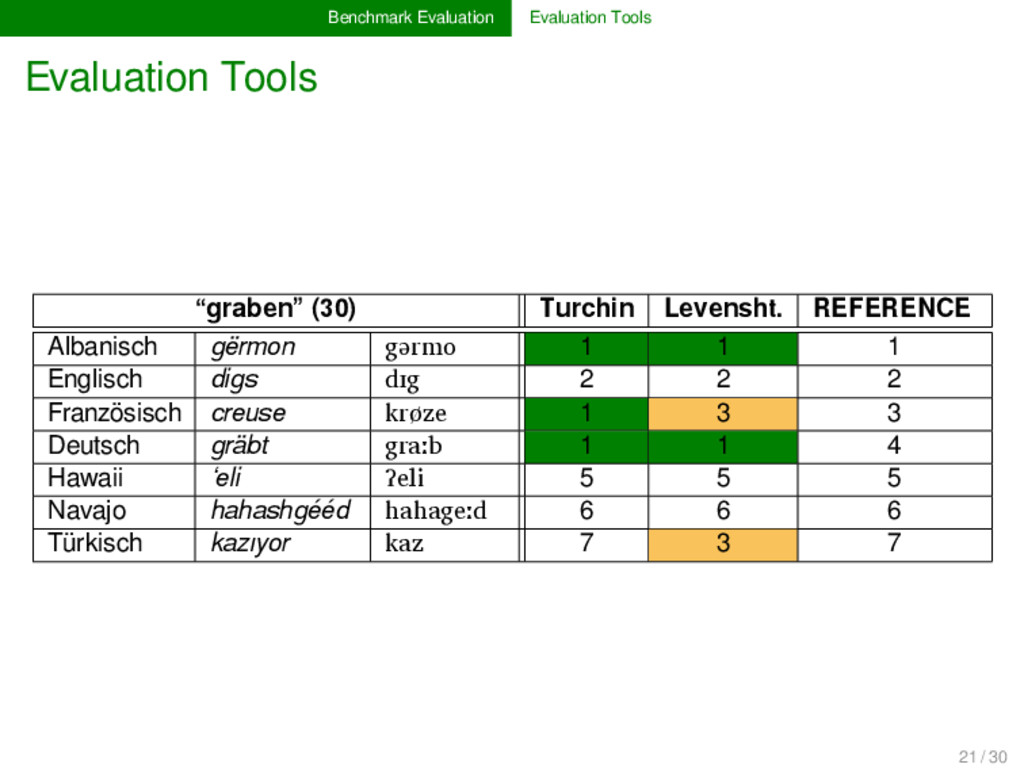
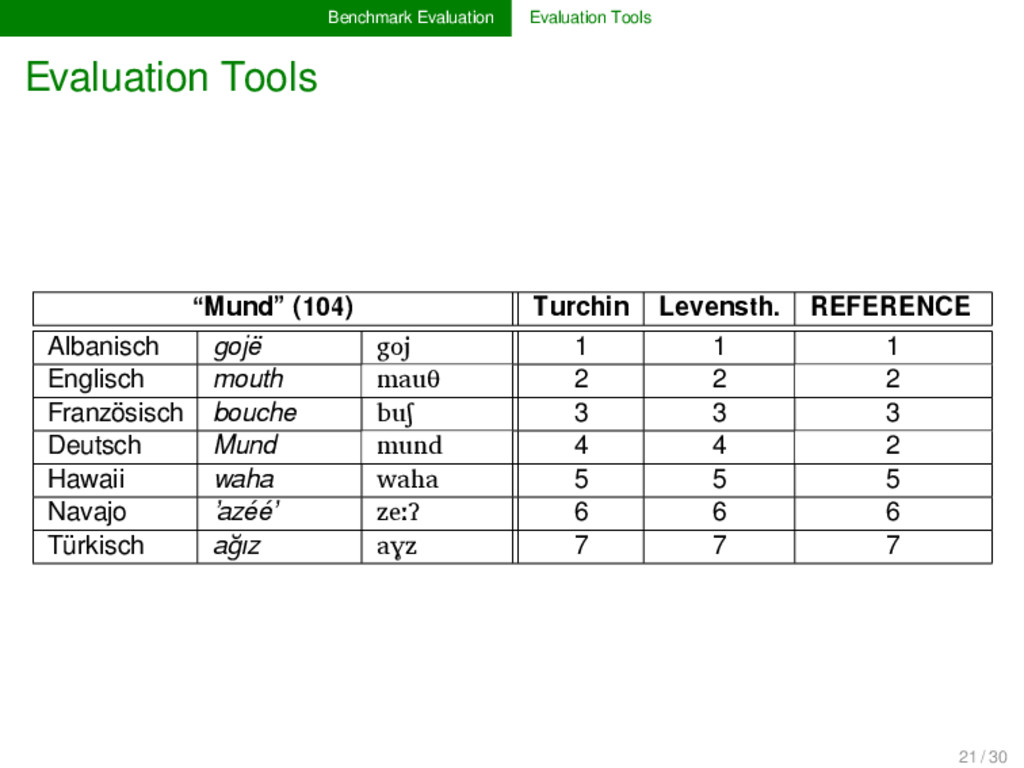
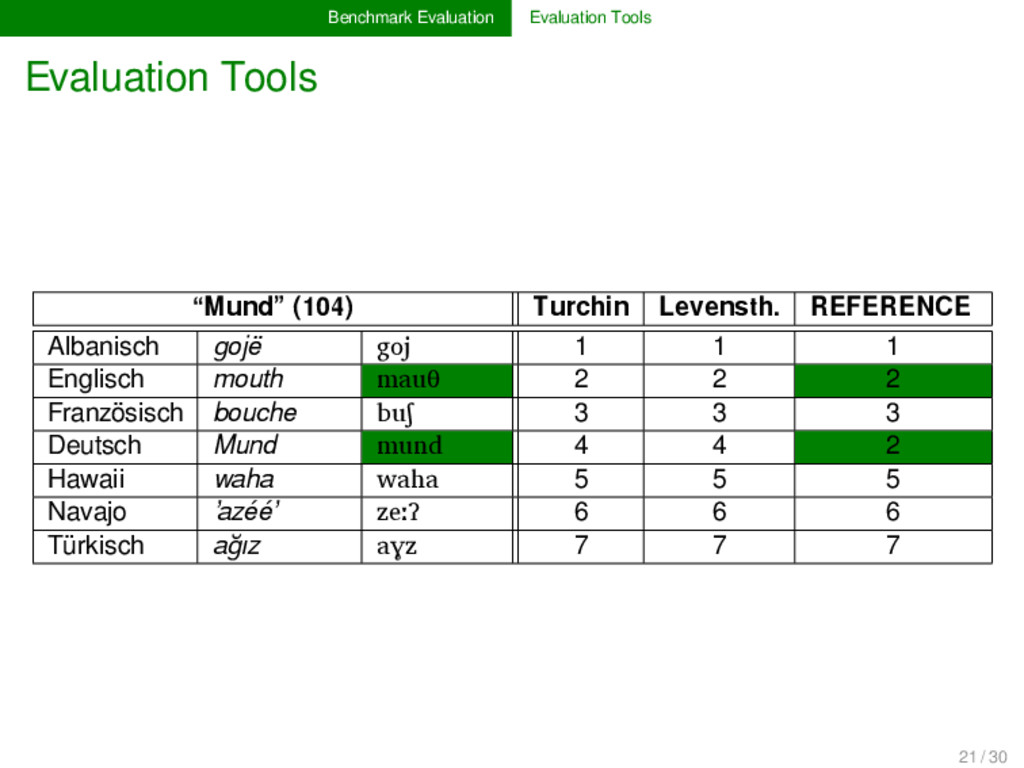
is essential for the eva- luation of a given algorithm. Standardization is of crucial im- portance here, since this is the only way to guarantee the comparability of alternative approaches. While for some tasks (alignment analyses, cognate detec- tion), proper evaluation scores are well-established (cf. the overview in List 2014), evaluation scores for other tasks (bor- rowing detection, linguistics reconstruction) are largely un- explored. Those who provide benchmark databases should also offer formal ways and code to evaluate algorithm performance. 19 / 30
no real tools for the evaluation of the re- sults of automatic approaches. Nevertheless, if we want to increase the interaction between manual and automatic ap- proaches in historical linguistics, it seems worthwhile to in- vest in proper tools for the expert evaluation of algorithms. 21 / 30
the majority of computational approaches in histori- cal linguistics largely disregards the actual needs of histori- cal linguistics. Despite the frequent claims that the algorith- ms are intended to supplement traditional research, many of them are mere attempts to prove the power of modern machine learning approaches and completely disregard the achievements of traditional research in historical linguistics. 23 / 30
really want to make a difference with computational ap- proaches and not simply seek to replace every expert who likes books with a computer or abacus, we need to work much, much harder, on a real integration of computational and traditional approaches. 23 / 30
BOPP VERY, VERY LONG TITLE Apart from “computational historical linguistics”, we need to establish a new discipline of “computer-aided historical linguistics”. Such a framework needs bench- mark databases (no wonder) and new standards, both for traditional and computational linguistics. However, such a framework will also need additional resources that help traditional approaches to leave the realm of intuition. 23 / 30
that hypotheses in historical linguistics stand and fall with a proper treatment of semantic change. So far, however, we lack the cross-linguistic data to assess the plausibility of proposed patterns of semantic shift. There is, however, hope for improvement: 24 / 30
that hypotheses in historical linguistics stand and fall with a proper treatment of semantic change. So far, however, we lack the cross-linguistic data to assess the plausibility of proposed patterns of semantic shift. There is, however, hope for improvement: The Database of Semantic Shifts (DatSemShifs, Burlak et al. http://semshifts.iling-ran.ru/) offers a constantly increasing amount of patterns of semantic shifts, drawn from the linguistic literature. Shifts are categorized, tagged for meanings, and – where accessible – directions. In the future, this may turn into a very valuable resource for those interested in semantic change. 24 / 30
that hypotheses in historical linguistics stand and fall with a proper treatment of semantic change. So far, however, we lack the cross-linguistic data to assess the plausibility of proposed patterns of semantic shift. There is, however, hope for improvement: The Database of Semantic Shifts (DatSemShifs, Burlak et al. http://semshifts.iling-ran.ru/) offers a constantly increasing amount of patterns of semantic shifts, drawn from the linguistic literature. Shifts are categorized, tagged for meanings, and – where accessible – directions. In the future, this may turn into a very valuable resource for those interested in semantic change. The Database of Cross-Linguistic Collexifications (CLICS, List et al., http://clics.lingpy.org) offers collections of colexifications (“polysemy”) patterns in some 200 languages. The data has been crawled semi-automatically from existing sources like the Intercontinental Dictionary Series (IDS, Key & Comrie 2007, http://lingweb.eva.mpg.de/ids/) and automatically cleaned and tagged for colexification. The automatic handling without proper checking of the data are a drawback which needs to be handled in the future. A strong aspect of the database are the visualizations of colexifications using up-to-date JavaScript libraries. 24 / 30
not all sounds are equally likely to occur in correspondence relation in historically related words has been noted by many linguists in the past. 25 / 30
not all sounds are equally likely to occur in correspondence relation in historically related words has been noted by many linguists in the past. However, only a few linguists have ever tried to substantiate this claim with data (Dolgopolsky 1964, Brown et al. 2013). 25 / 30
not all sounds are equally likely to occur in correspondence relation in historically related words has been noted by many linguists in the past. However, only a few linguists have ever tried to substantiate this claim with data (Dolgopolsky 1964, Brown et al. 2013). The most notable resource known to me is the one by Brown et al. (2013), who report statistics based on ASJP data. The drawbacks of this approach are the limited number of symbols in ASJP code and the fact that identity relations are not covered. The advantages are the strictness of the procedure and the large amount of data that the analysis is based upon. 25 / 30
far, the only online resource known to me is the web-based platform for Diachronic Data and Models (DiaDM, http://www.diadm.ish-lyon.cnrs.fr) which offers a database on Diachronic Universals (UniDia). Unfortunately, the database has been under construction for almost two years now, and no real progress regarding the presentation of the data has been visible so far. 26 / 30
far, the only online resource known to me is the web-based platform for Diachronic Data and Models (DiaDM, http://www.diadm.ish-lyon.cnrs.fr) which offers a database on Diachronic Universals (UniDia). Unfortunately, the database has been under construction for almost two years now, and no real progress regarding the presentation of the data has been visible so far. If the numbers presented on the UniDia website are true (10 349 sound changes in 302 languages), it contains an invaluable resource on known sound changes. 26 / 30
far, the only online resource known to me is the web-based platform for Diachronic Data and Models (DiaDM, http://www.diadm.ish-lyon.cnrs.fr) which offers a database on Diachronic Universals (UniDia). Unfortunately, the database has been under construction for almost two years now, and no real progress regarding the presentation of the data has been visible so far. If the numbers presented on the UniDia website are true (10 349 sound changes in 302 languages), it contains an invaluable resource on known sound changes. Unfortunately, it is not evident from the website, how (or if) this data will be made public in the future, and whether it can ever be used to either train our algorithms, or to provide our experts with something more than intuition. 26 / 30
to say that with MultiTree (http://multitree.org), Ethnologue (Lewis & Fennig 2014, http://ethnologue.com), and GlottoLog (v2.3, Hammarström et al. 2014, http://glottolog.org), a large number of expert classification is publicly available. 27 / 30
to say that with MultiTree (http://multitree.org), Ethnologue (Lewis & Fennig 2014, http://ethnologue.com), and GlottoLog (v2.3, Hammarström et al. 2014, http://glottolog.org), a large number of expert classification is publicly available. What is lacking in quite a few current approaches to phylogenetic reconstruction is a proper evaluation of the algorithms that makes rigorously use of these resources. Just eyeballing a tree and claiming, that some method “reproduces expert classifications” based on some strange criterion, is simply not enough. 27 / 30
Indo-European Lexial Cognacy Databse (IELex, http://ielex.mpi.nl/, Dunn et al. 2012) list borrowings along with their sources. However, given the fact that in many areas of the world (and also in Indo-European) our knowledge in historical linguistics starts to reach its limits when it comes to distinguish borrowings from inherited words, it is quite likely that it is impossible at the moment to provide exhaustive test sets in which all borrowings are identified. 28 / 30
linguistics. Nevertheless, the majority of the new approaches shows a great lack in transparency and applicability. One reason for this is the lack of benchmark databases in historical linguistics which help programmers to train their code but also force them to test it rigorously. 29 / 30
linguistics. Nevertheless, the majority of the new approaches shows a great lack in transparency and applicability. One reason for this is the lack of benchmark databases in historical linguistics which help programmers to train their code but also force them to test it rigorously. In order to increase the interaction between traditional and computational historical linguists, we need to work hard on providing high-quality benchmark databases and high-quality tools for algorithm evaluation. 29 / 30
linguistics. Nevertheless, the majority of the new approaches shows a great lack in transparency and applicability. One reason for this is the lack of benchmark databases in historical linguistics which help programmers to train their code but also force them to test it rigorously. In order to increase the interaction between traditional and computational historical linguists, we need to work hard on providing high-quality benchmark databases and high-quality tools for algorithm evaluation. Not only benchmark databases are needed, but also cross-linguistics comparative databases that help historical linguists to asses the regularity and irregularity of patterns and proposals in a less intuitive way. 29 / 30
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}