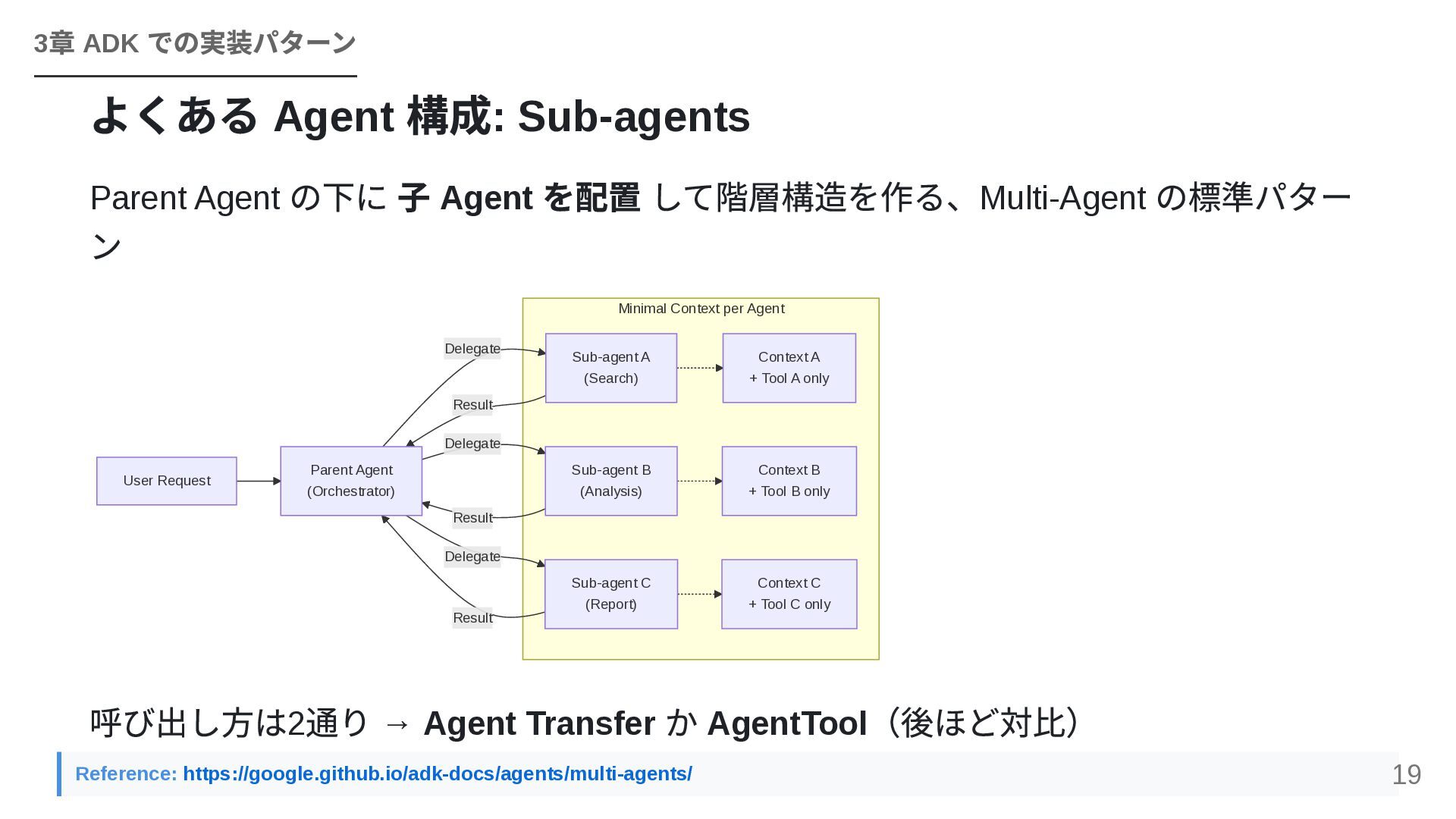
して階層構造を作る、Multi-Agent の標準パター ン Minimal Context per Agent Delegate Delegate Delegate Result Result Result User Request Parent Agent (Orchestrator) Sub-agent A (Search) Sub-agent B (Analysis) Sub-agent C (Report) Context A + Tool A only Context B + Tool B only Context C + Tool C only 呼び出し方は2 通り → Agent Transfer か AgentTool (後ほど対比) 3 章 ADK での実装パターン Reference: https://google.github.io/adk-docs/agents/multi-agents/ 19
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}