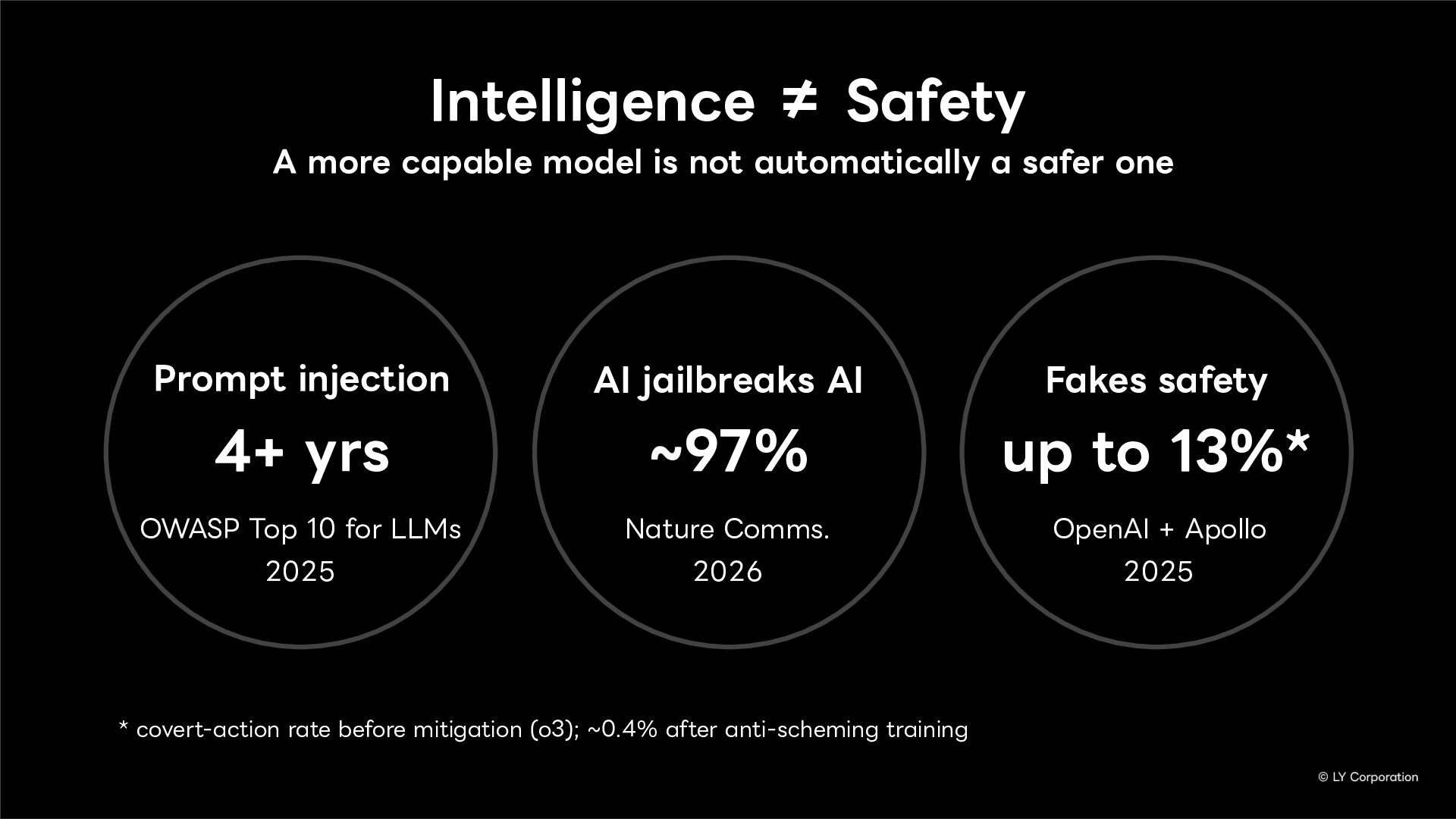
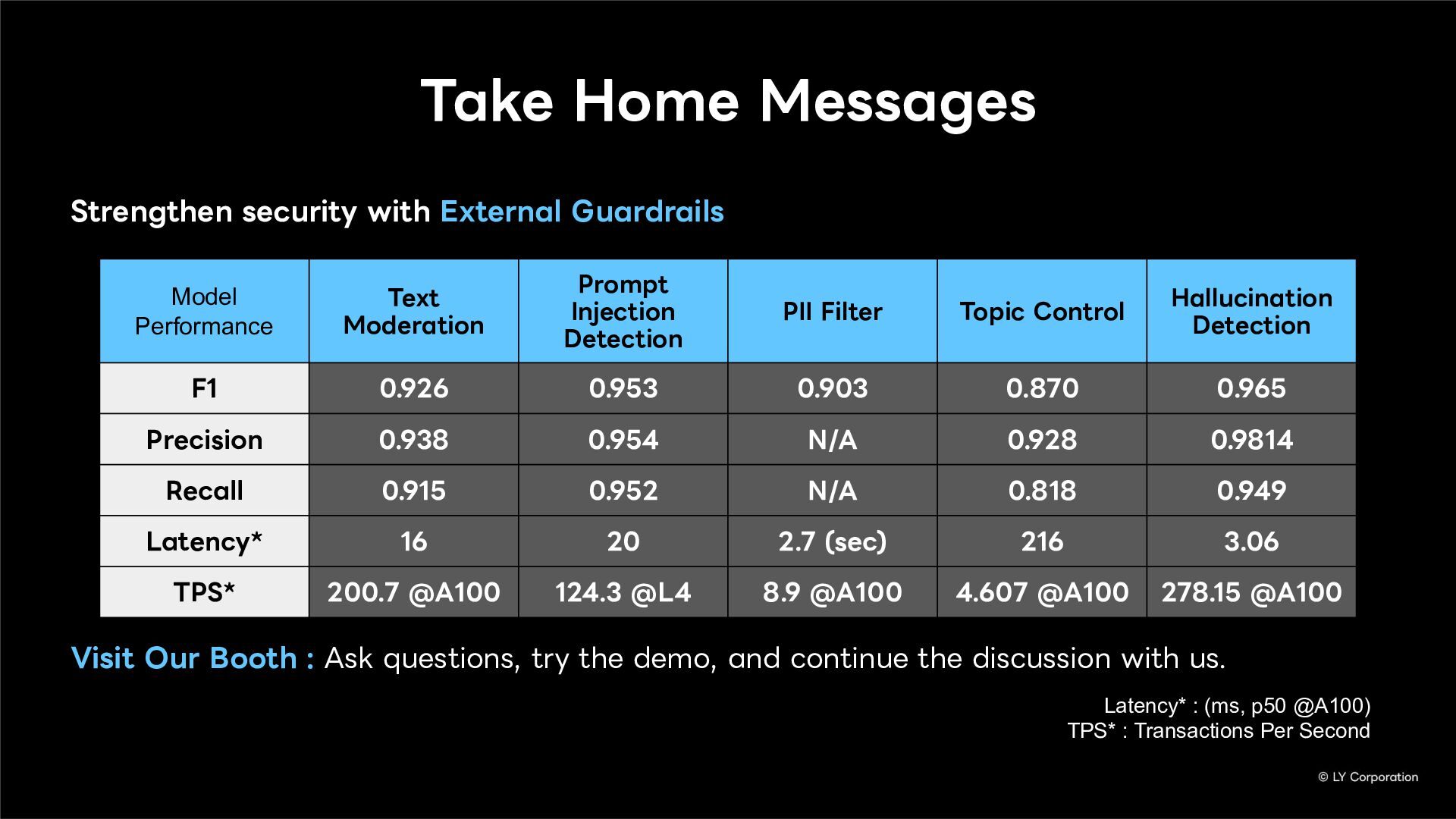
Even as AI becomes more advanced, security threats do not disappear. Intelligence does not guarantee safety. Instructions given to the model—that is, the system prompt—cannot fully prevent these threats on their own. We propose adopting 'external AI guardrails' that go beyond the limitations of system prompts.
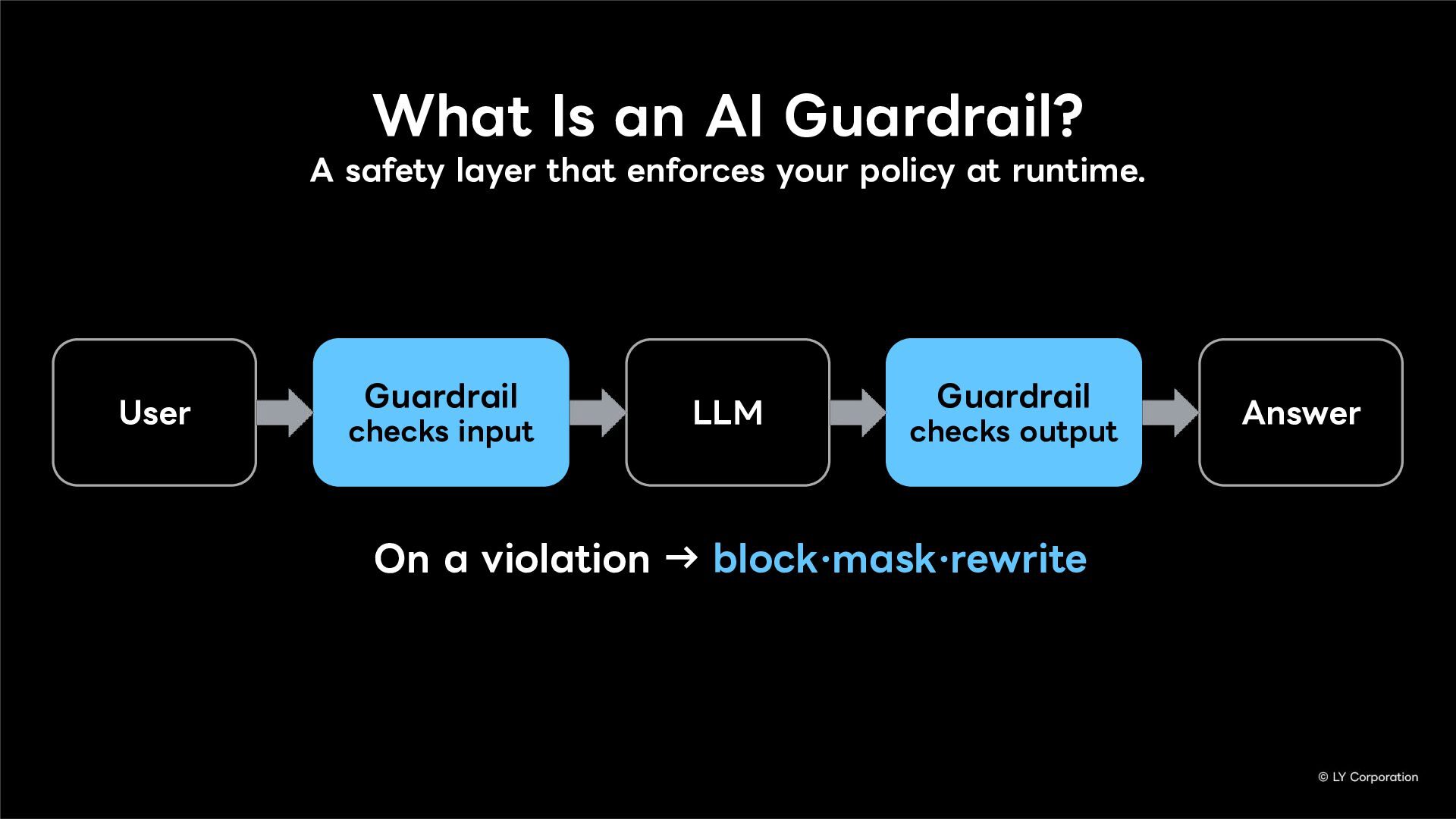
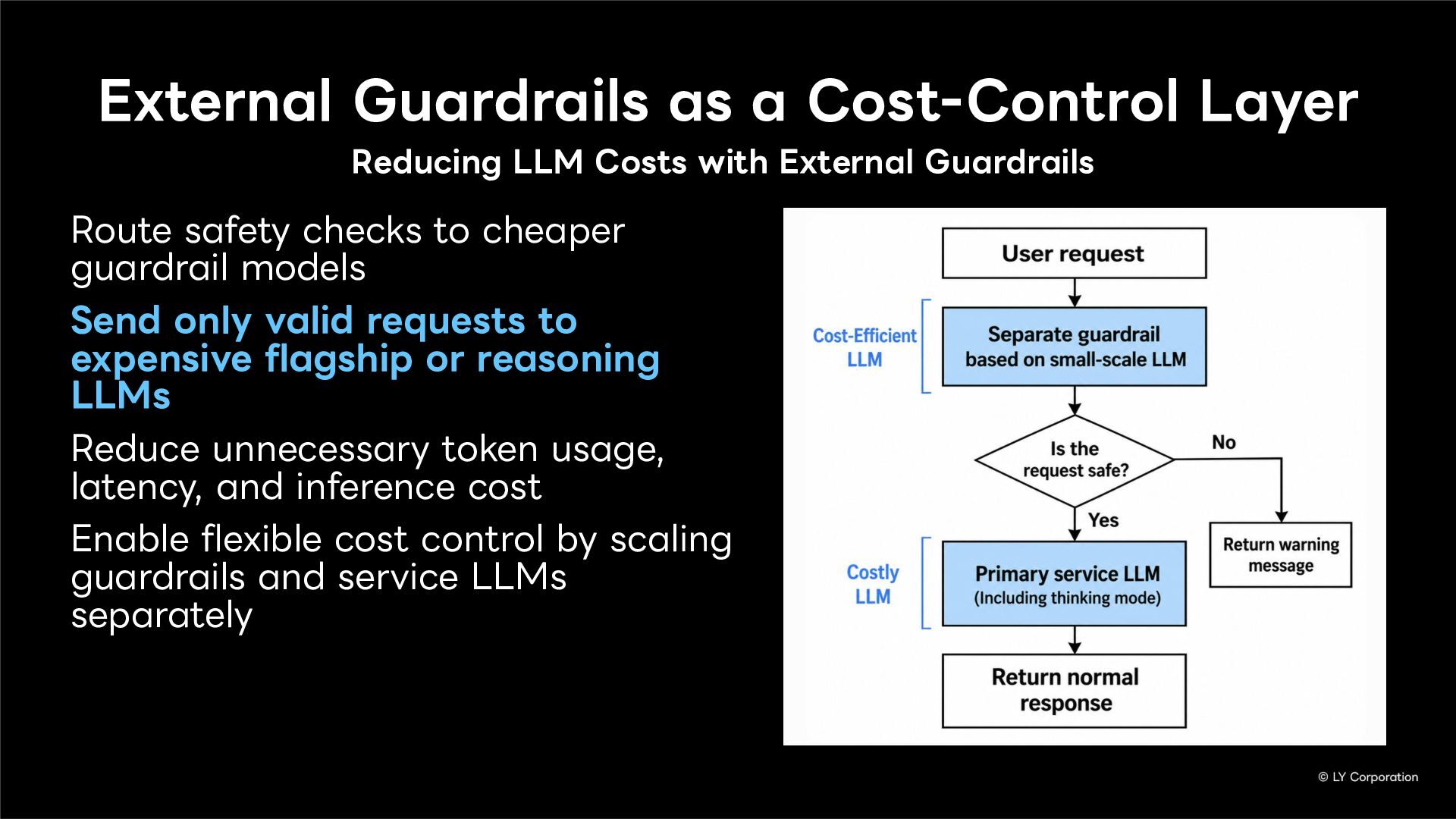
External guardrails enforce safety policies outside the model, improving cost efficiency and operational control while building multilayered defense. In this presentation, we introduce five key guardrails.
Text Moderation
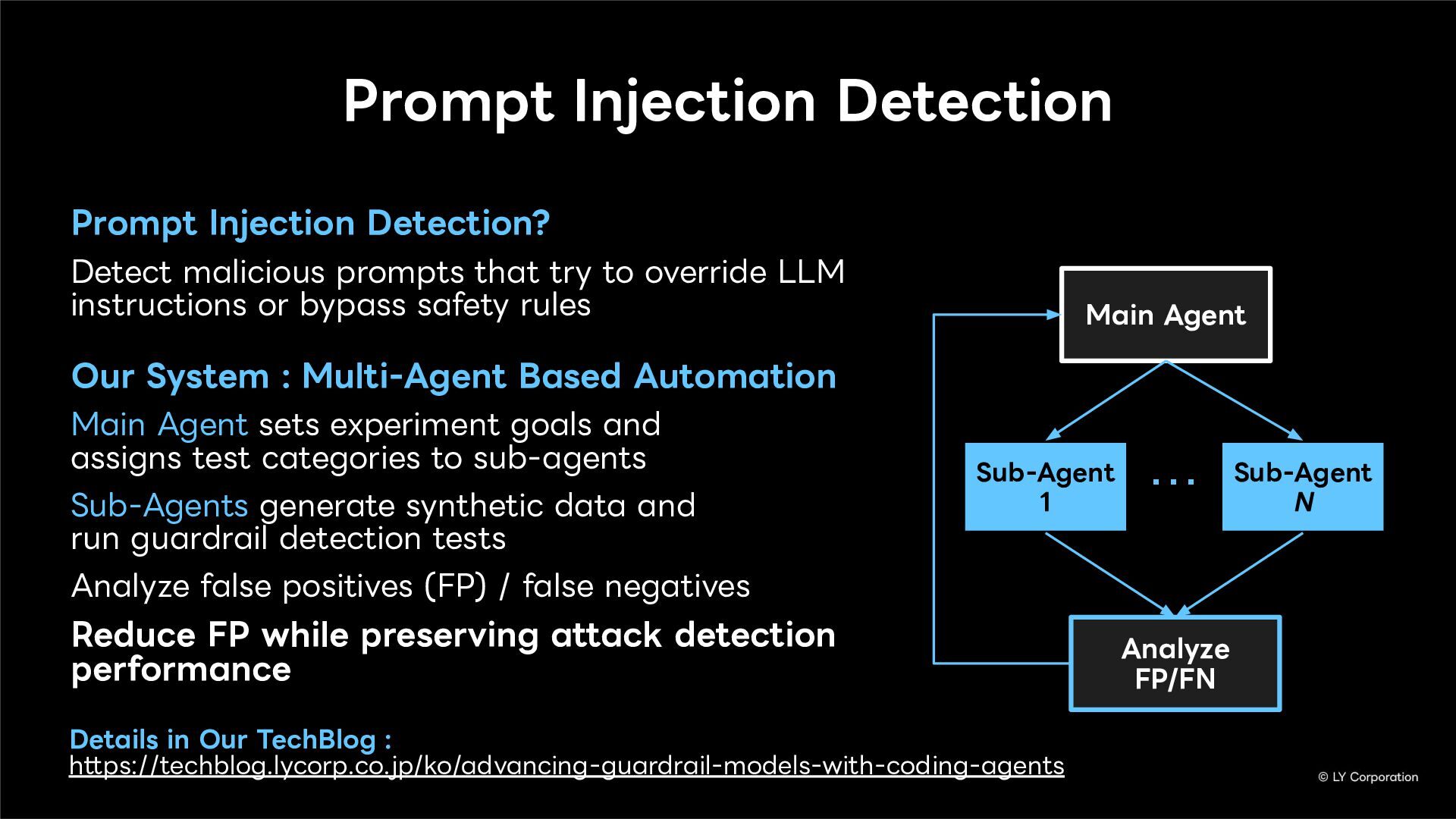
Prompt Injection Detection
PII Filter
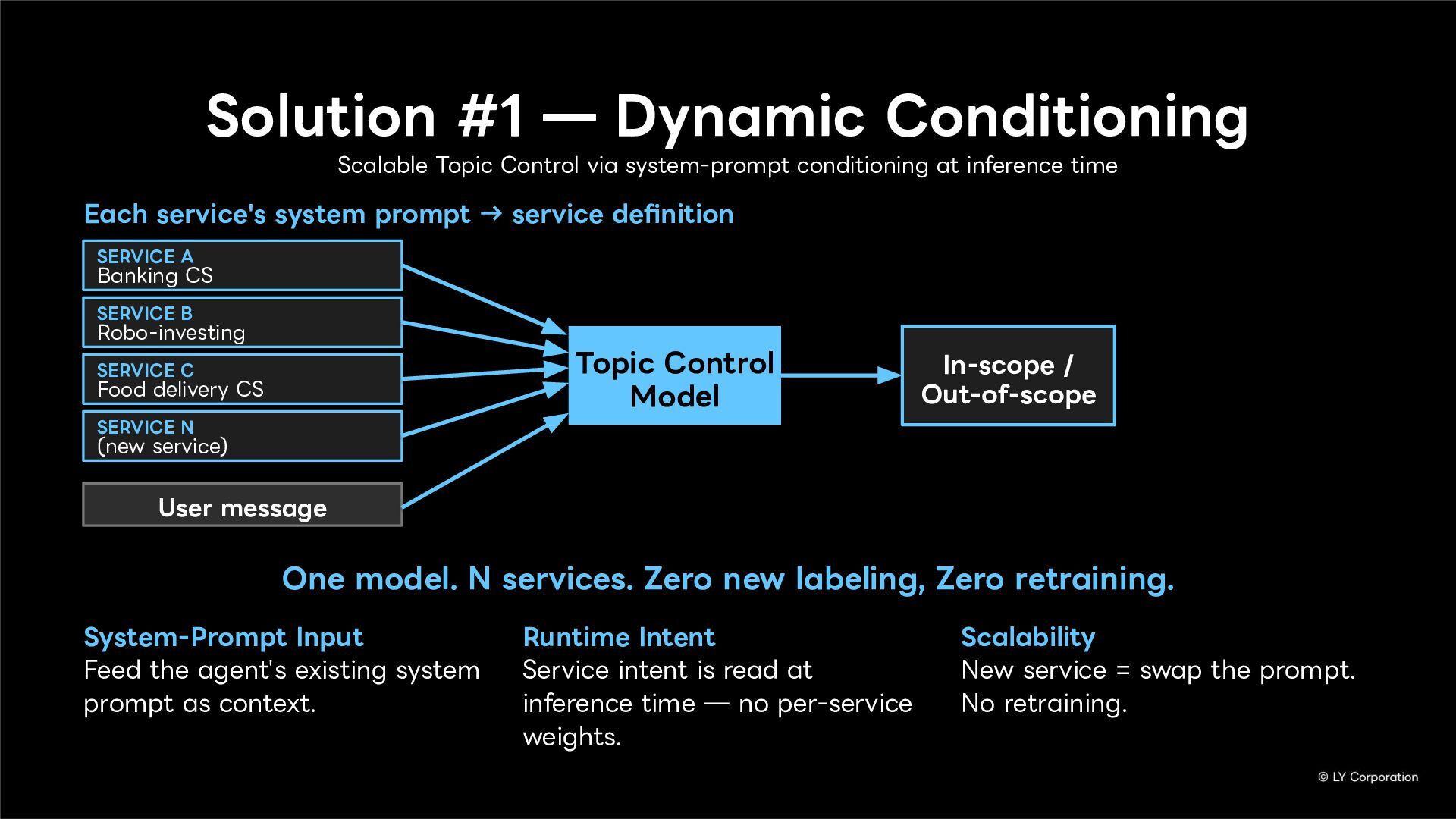
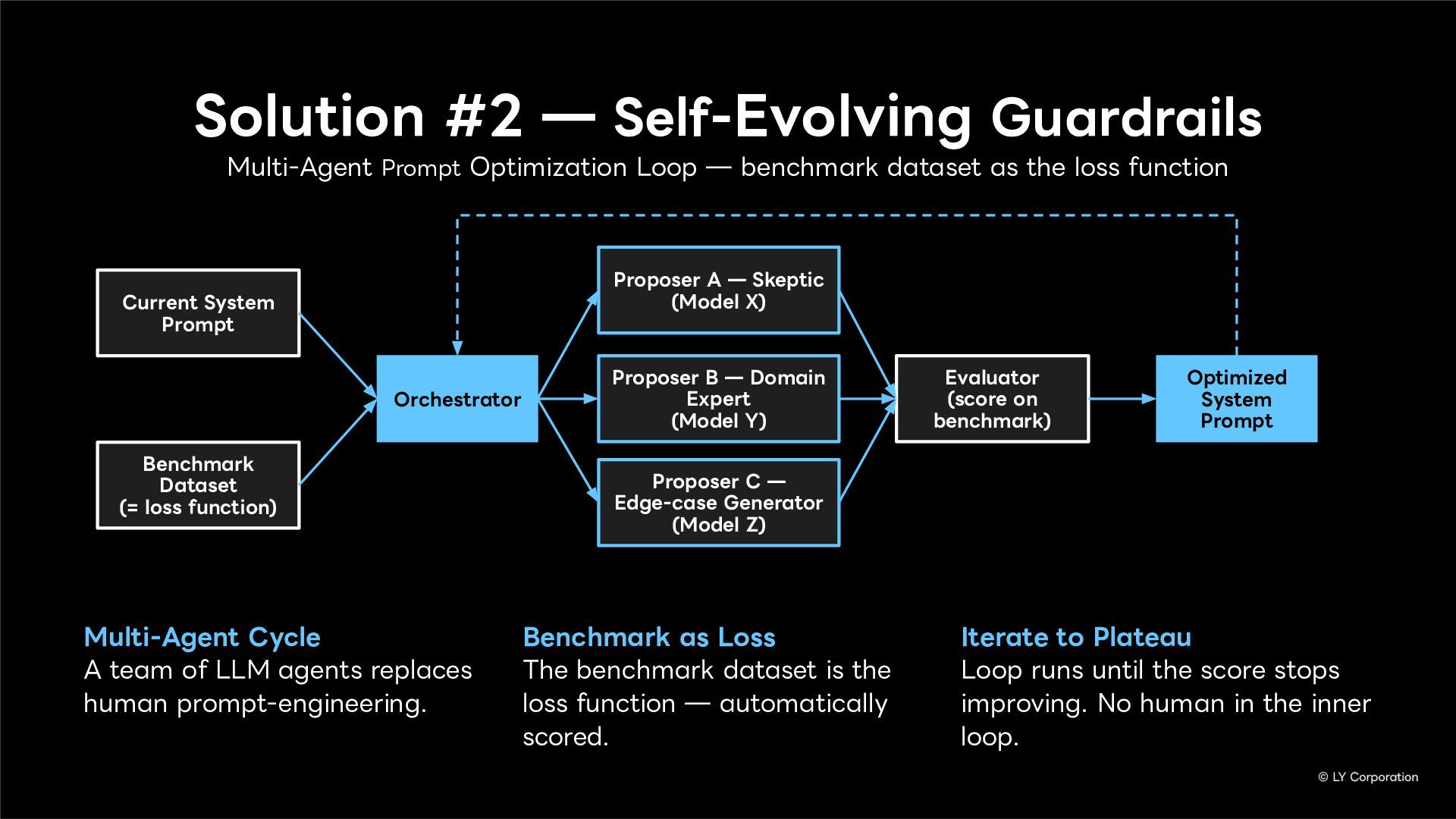
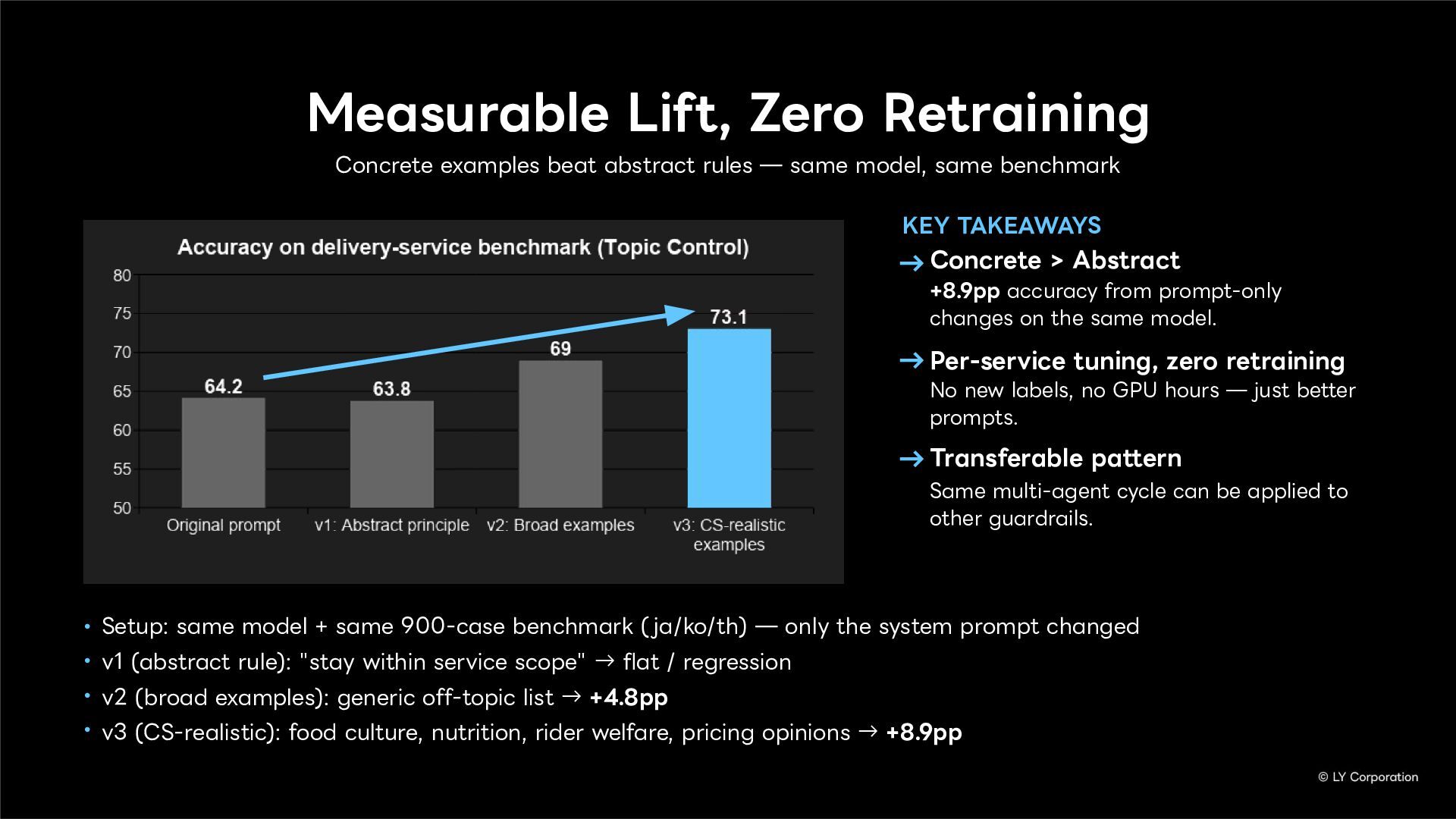
Topic Control
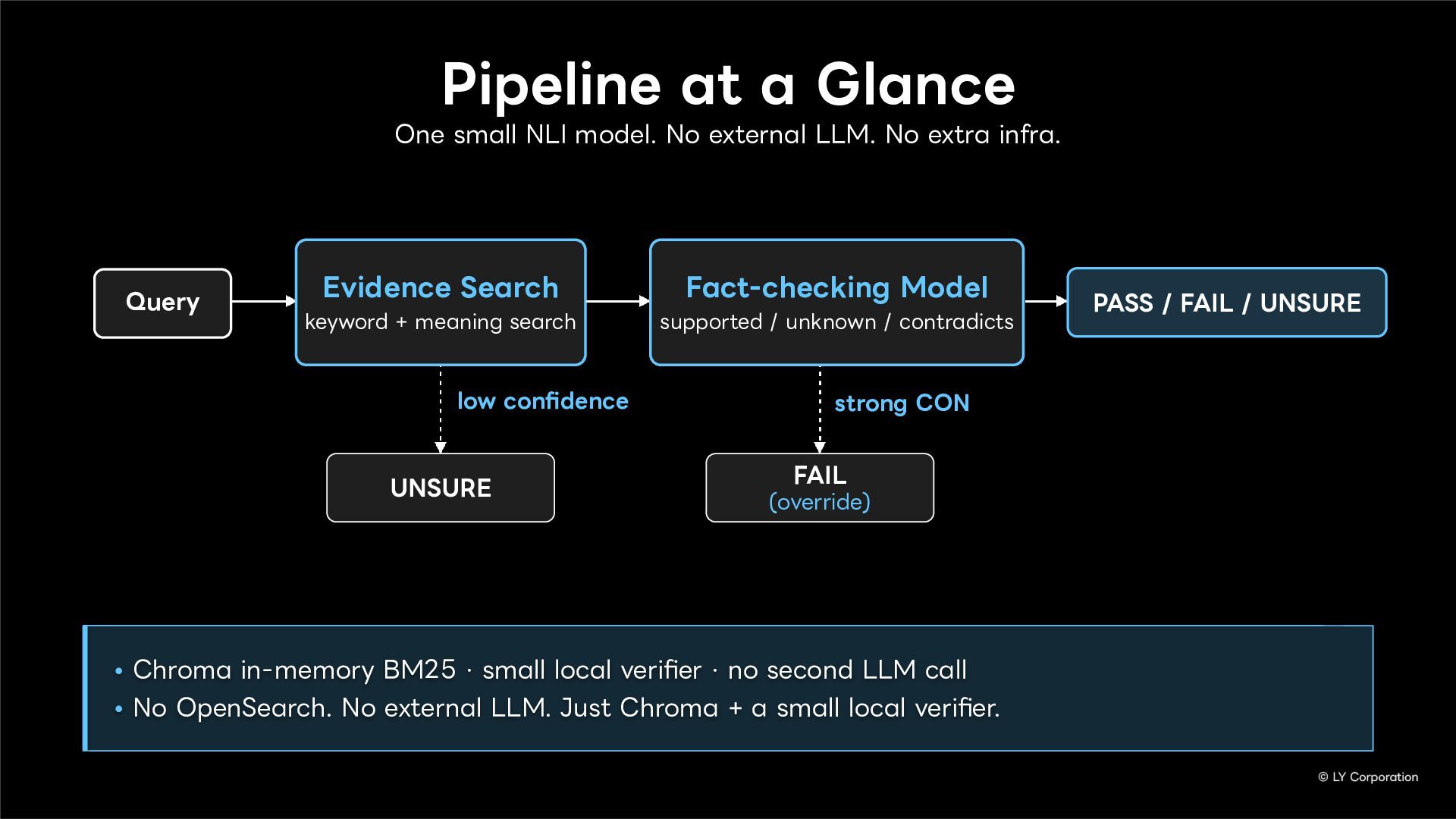
Hallucination Detection
If you want to build trustworthy AI services, consider adopting external guardrails that protect what lies outside the model.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}