Work @ VMware (Kubernetes Upstream) • Within the Kubernetes community - SIG-{API Machinery, Scalability, Architecture, ContribEx}. ◦ Please reach out if you’d like to get started in the community! • Doing Go stuff for ~3 years, particularly love things around the Go runtime!
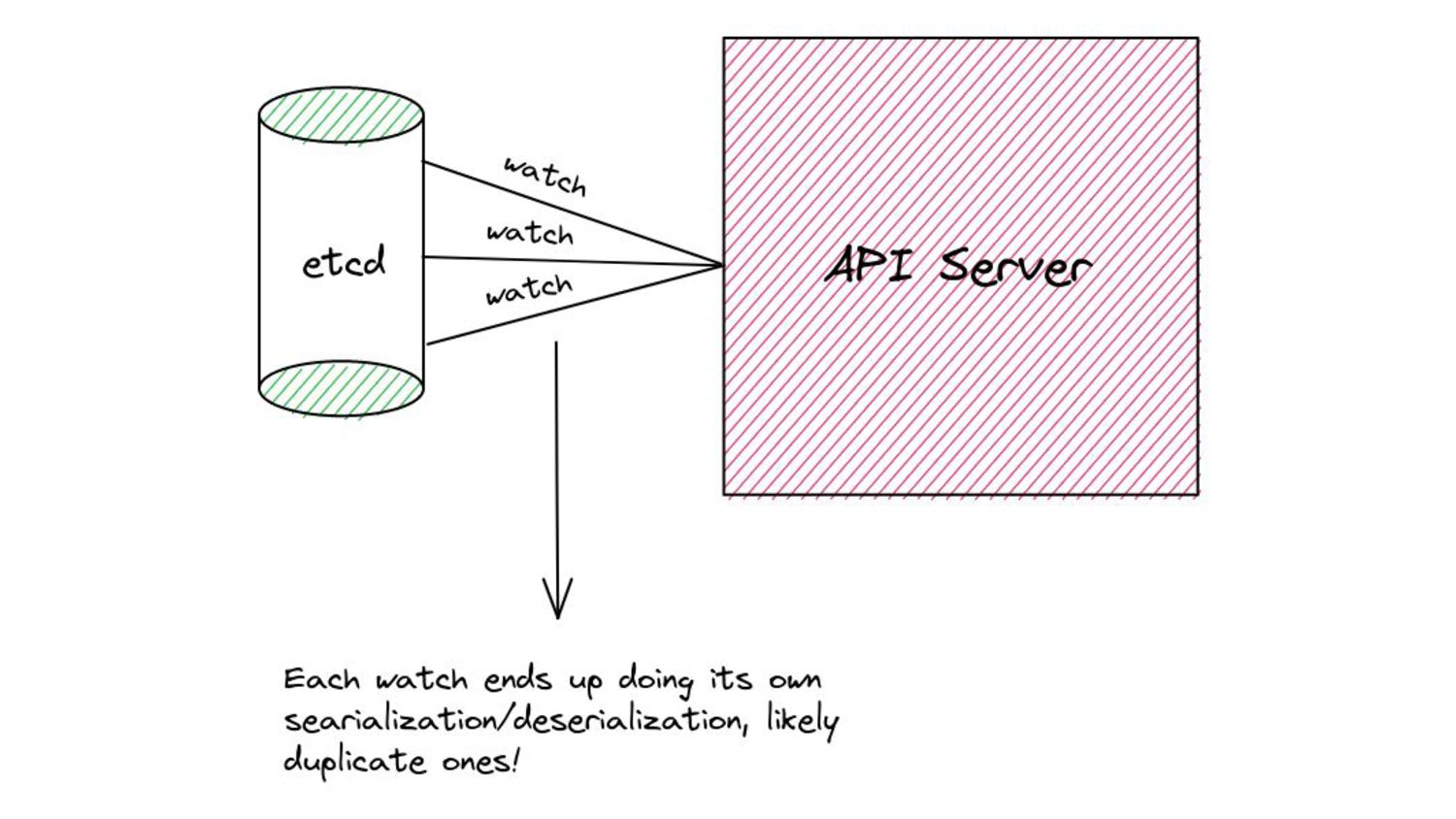
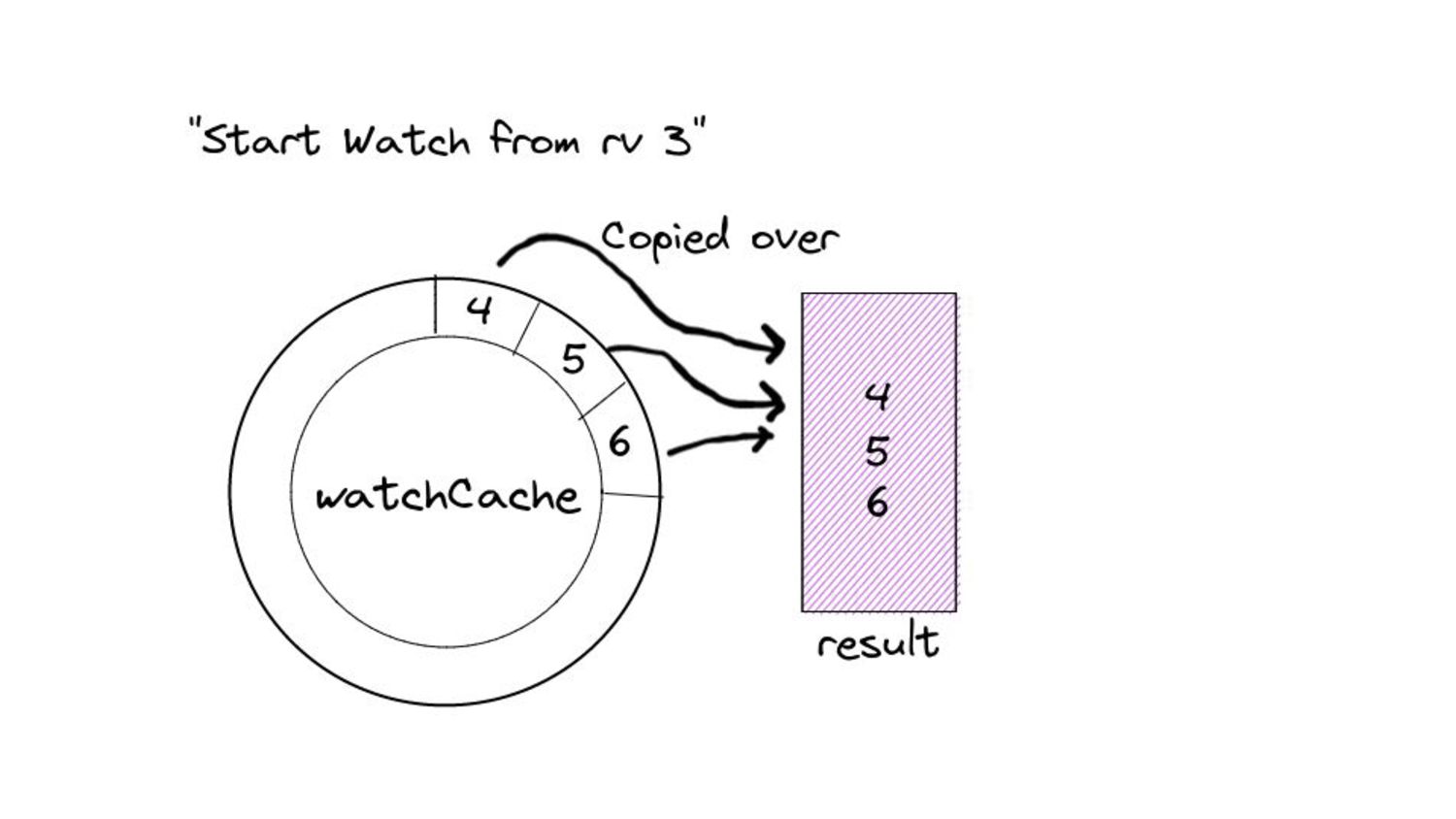
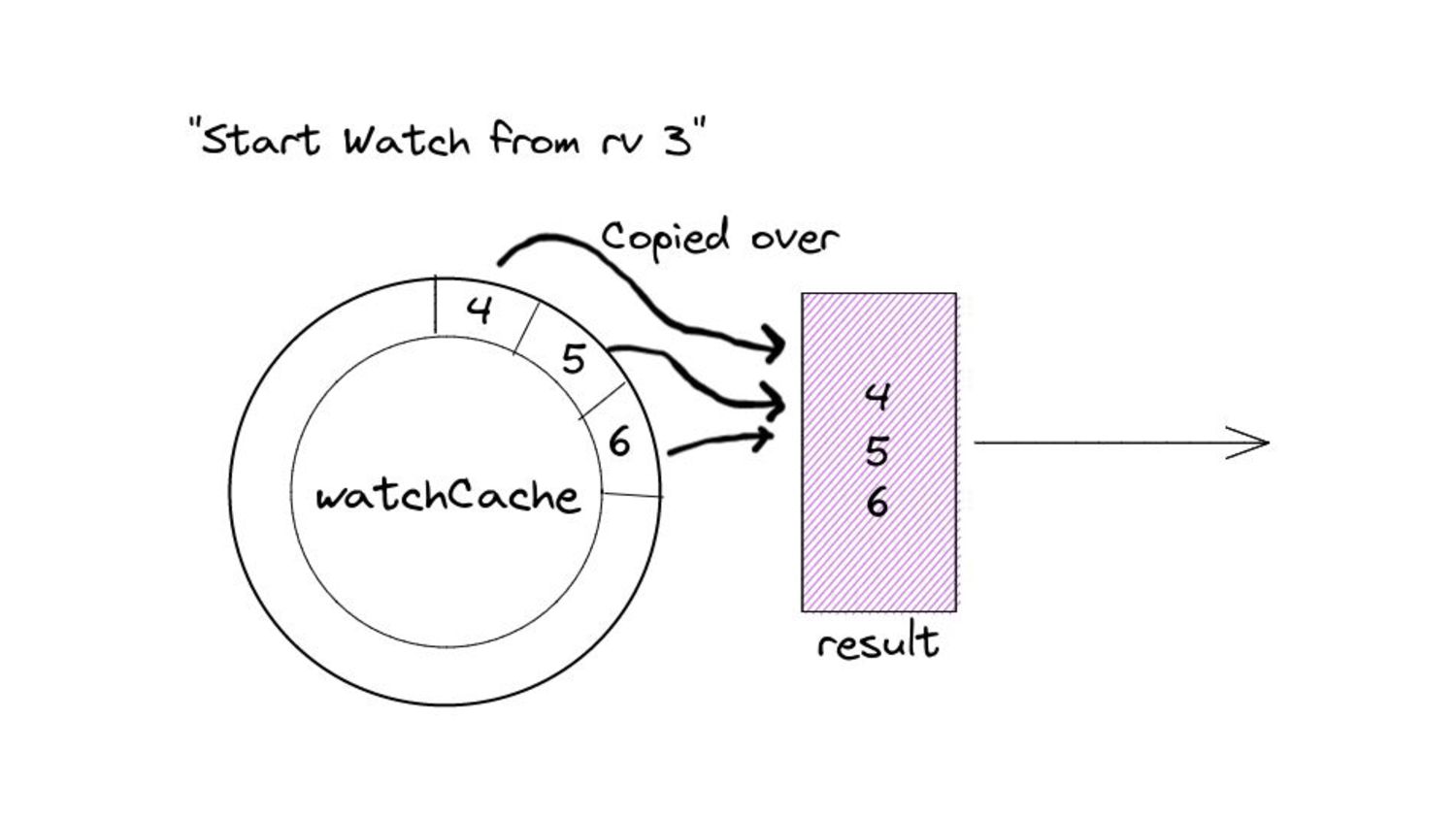
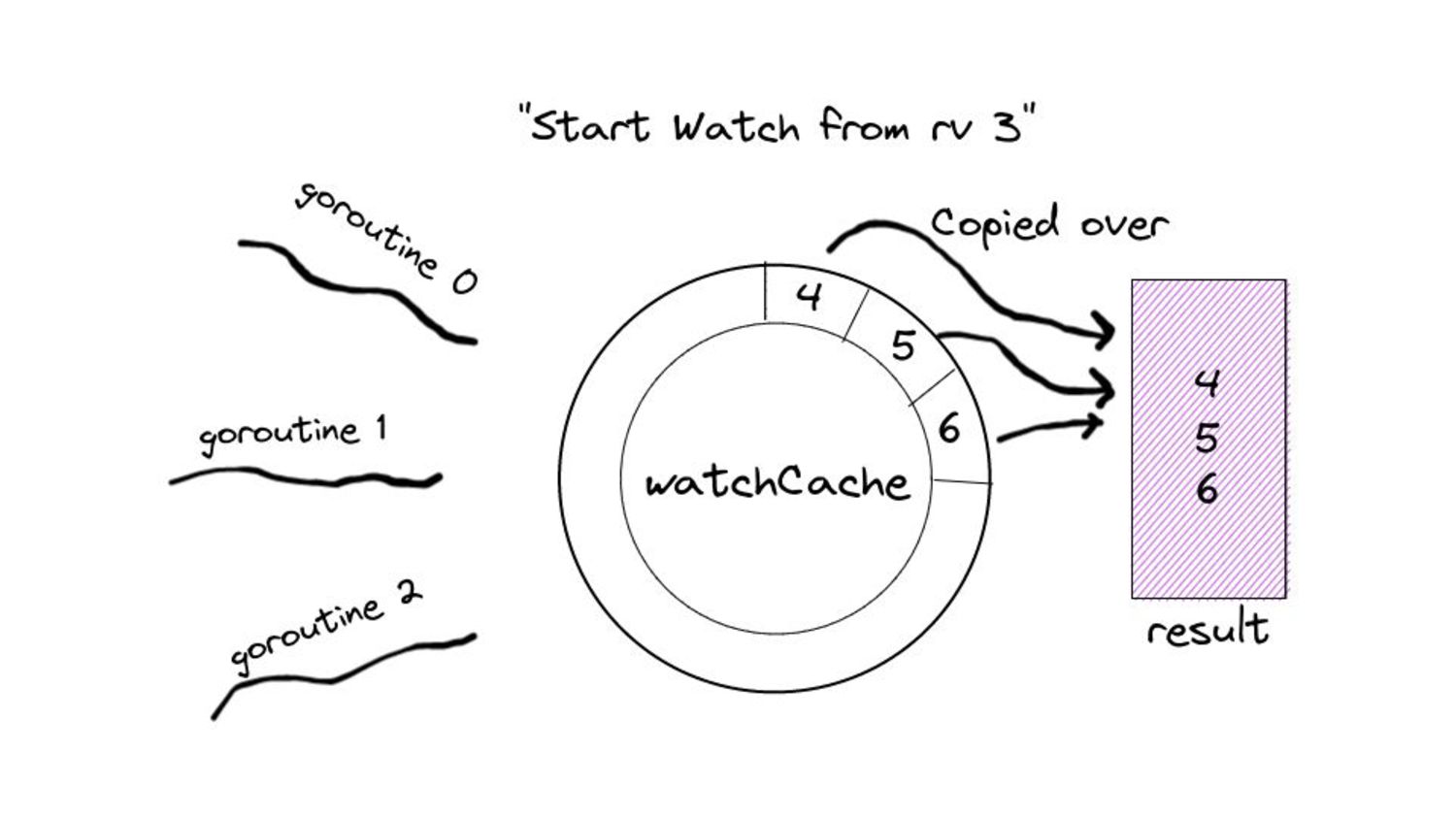
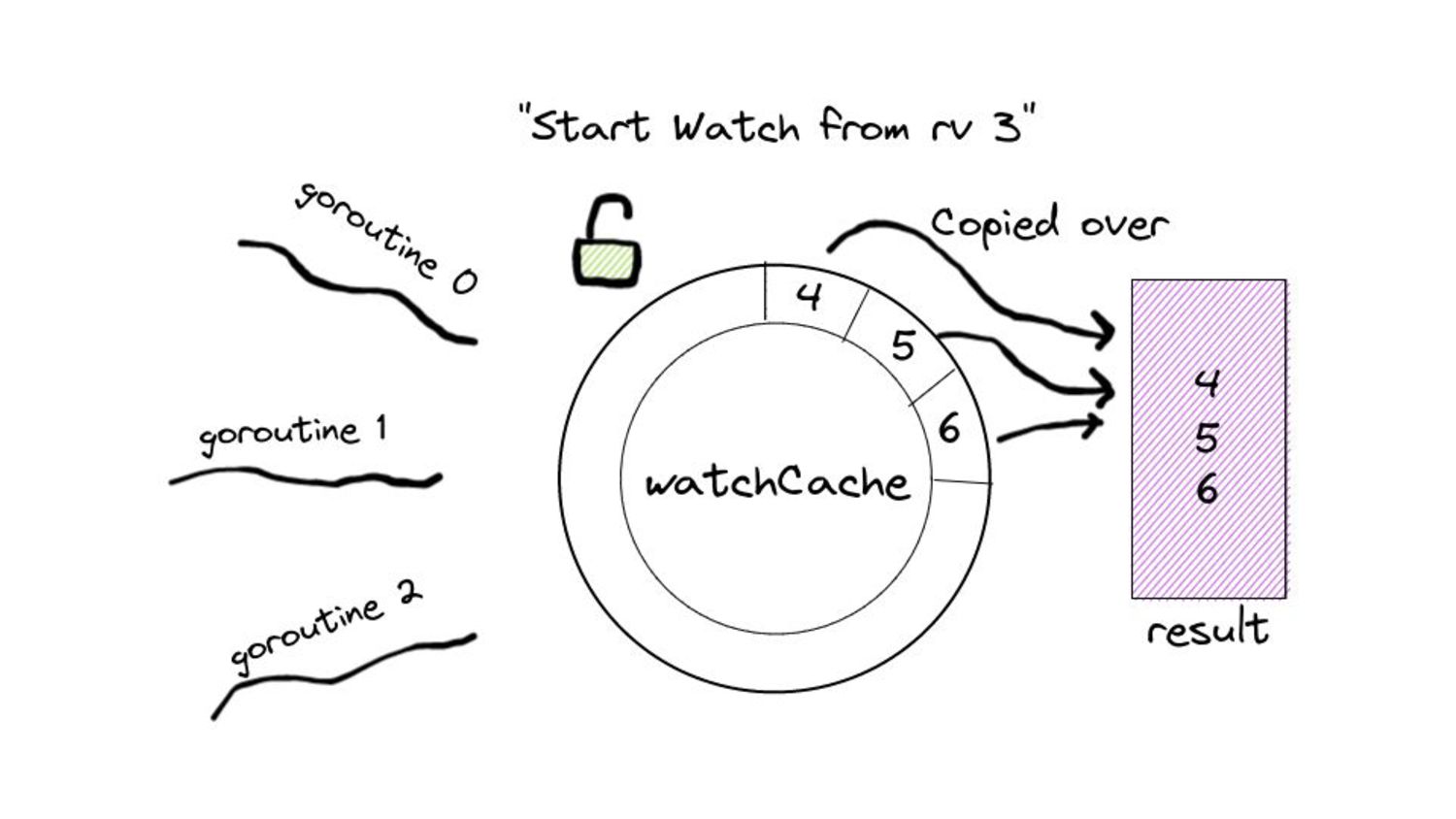
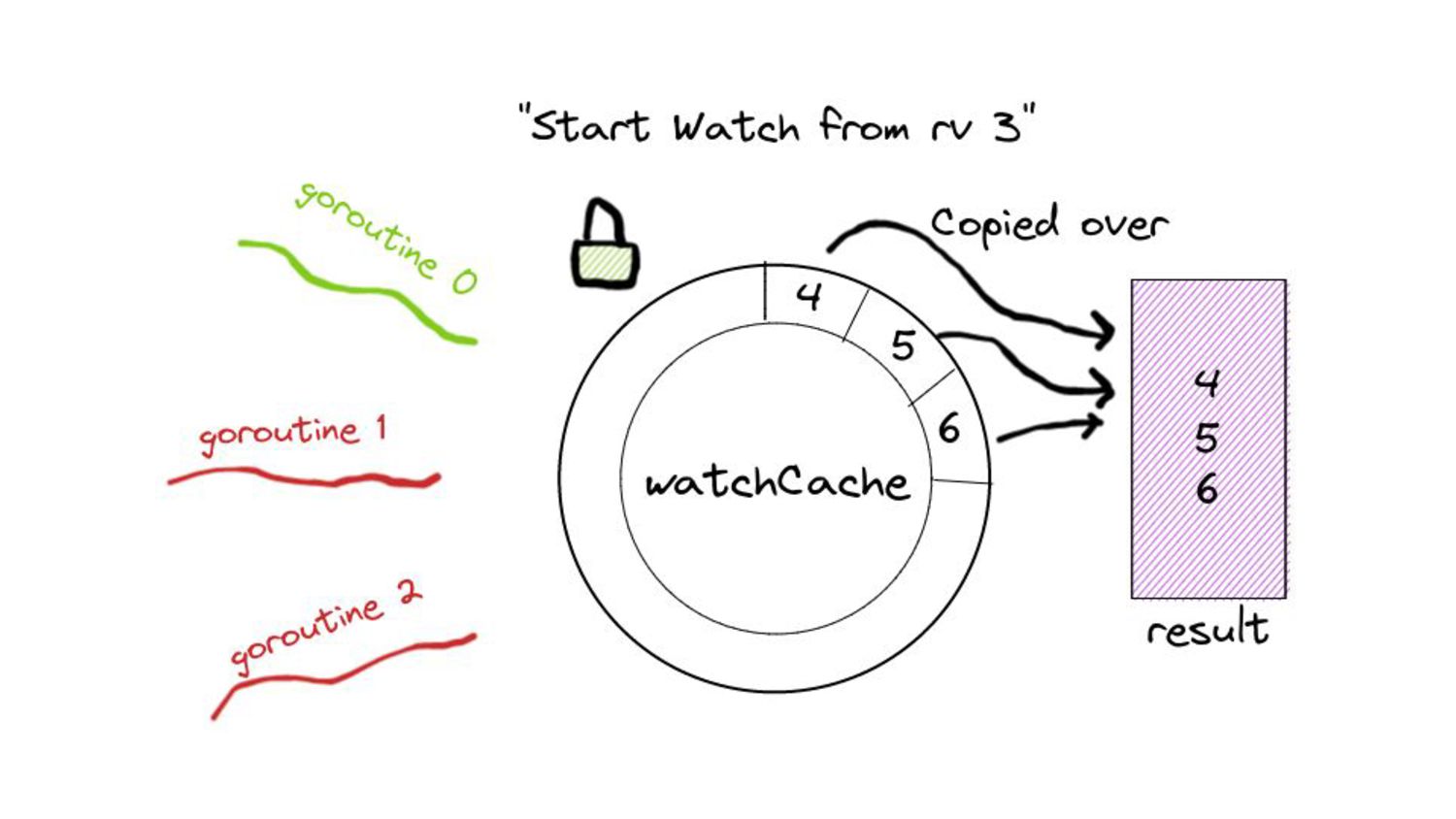
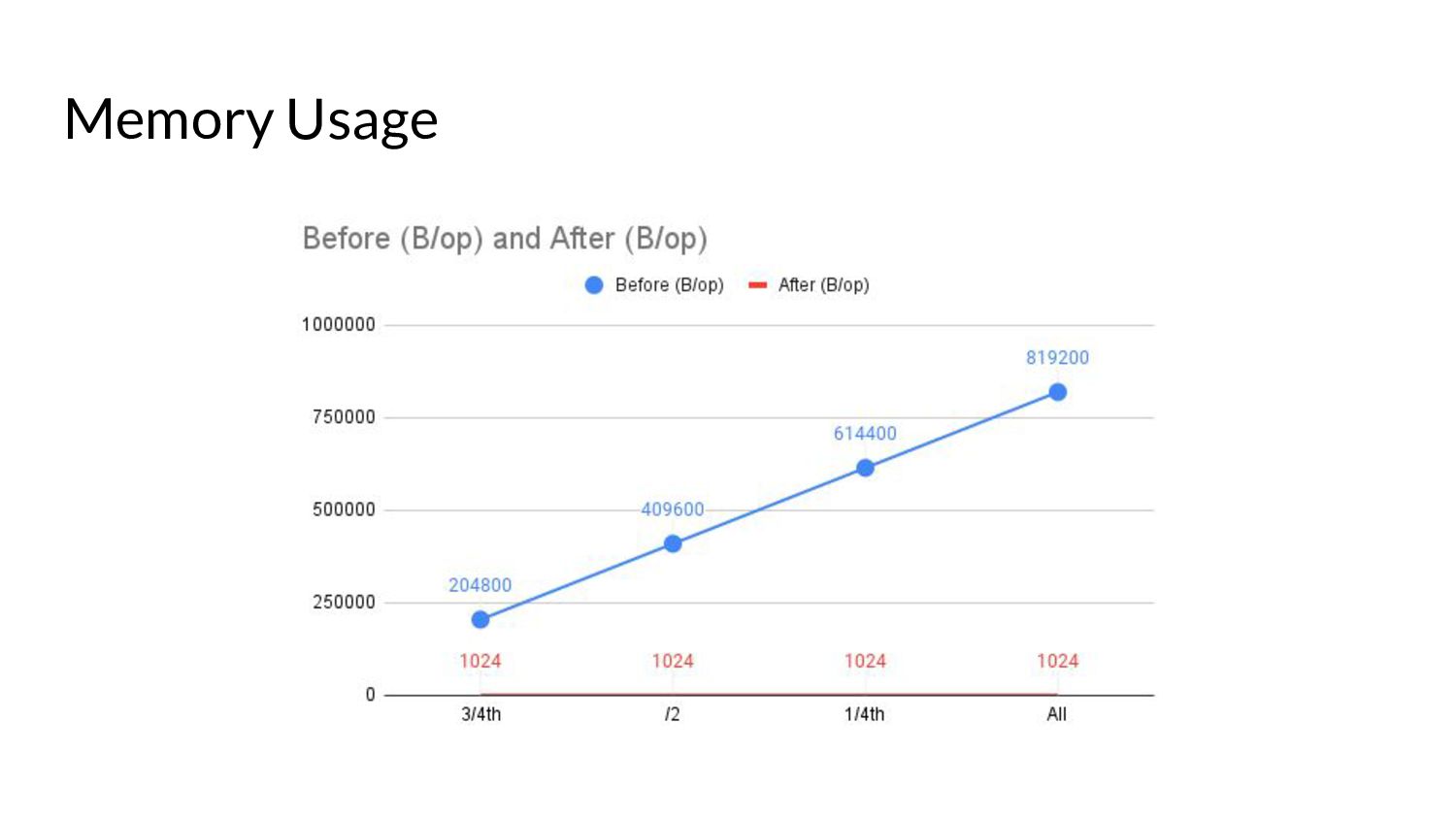
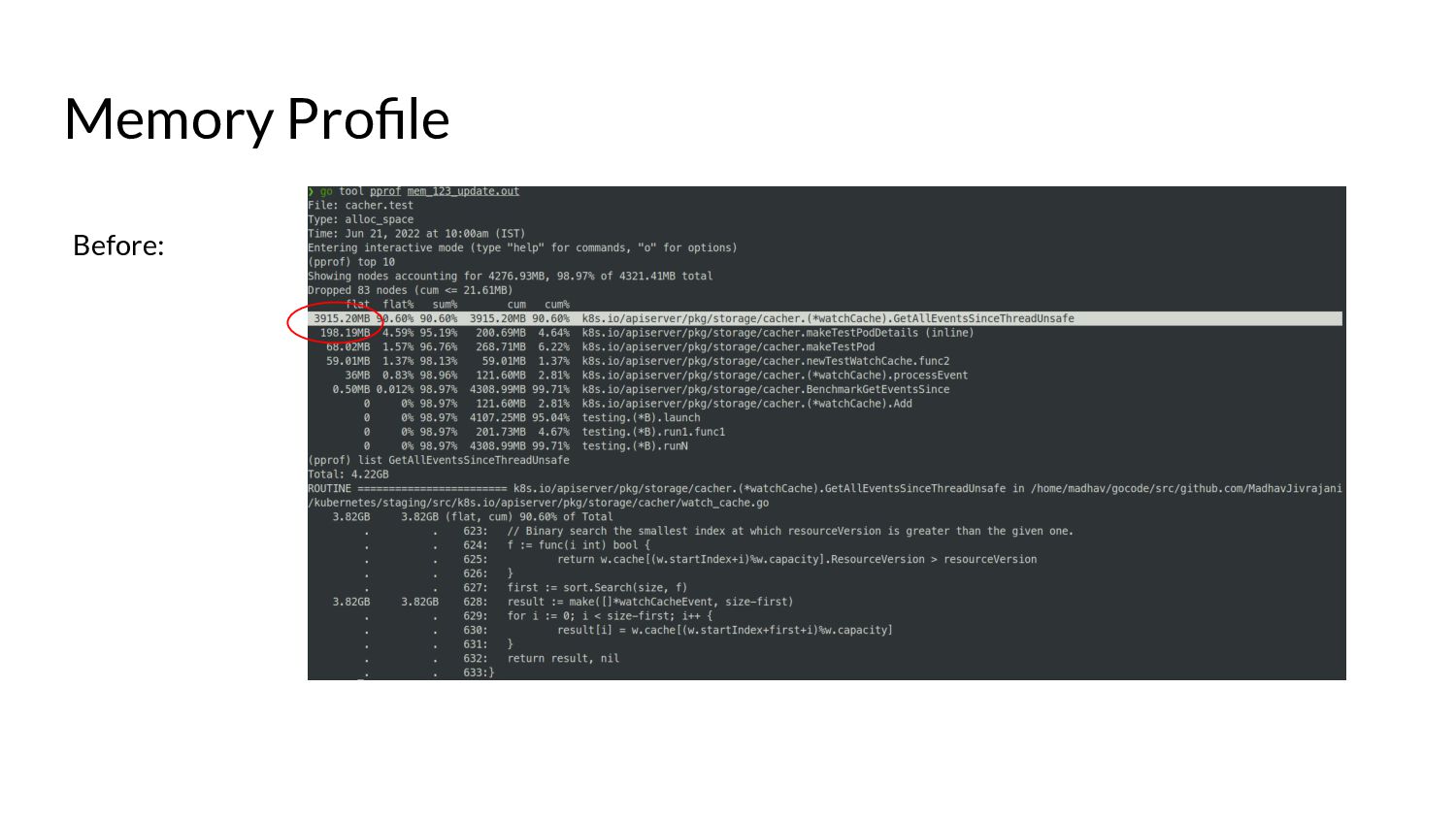
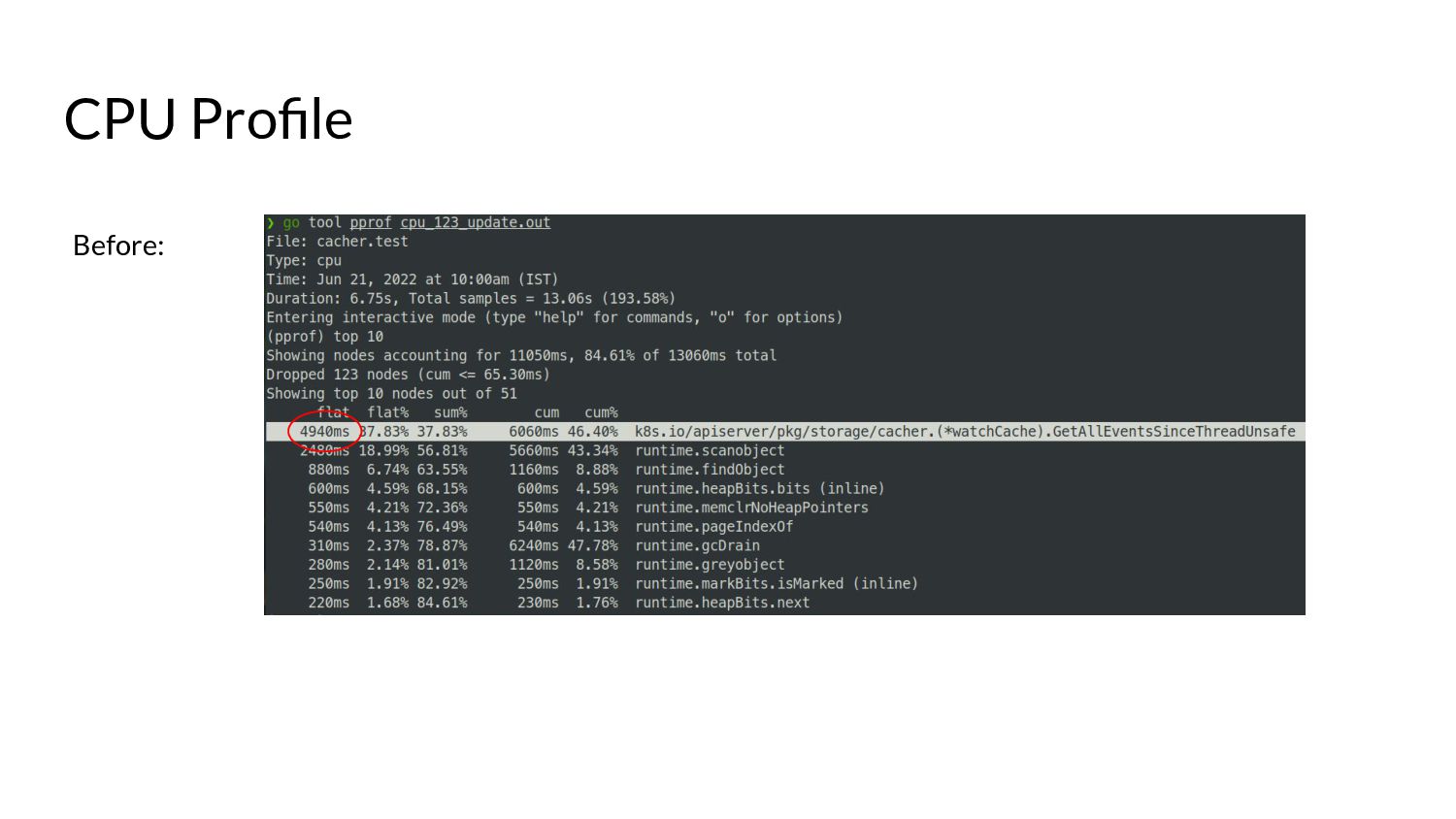
desired size. ◦ “Desired size” in real world scenarios can get substantially large. • Iterating over the list of items and copying them into the buffer. • Keep in mind, all of this happens under a lock… • … while other goroutines wait for this copying over to complete. • And these waiting goroutines in turn will have their own copying to do. • Because of this, we end up with spikes in memory consumption for watches opened against the “past”. ◦ We also end up wasting a few CPU cycles.
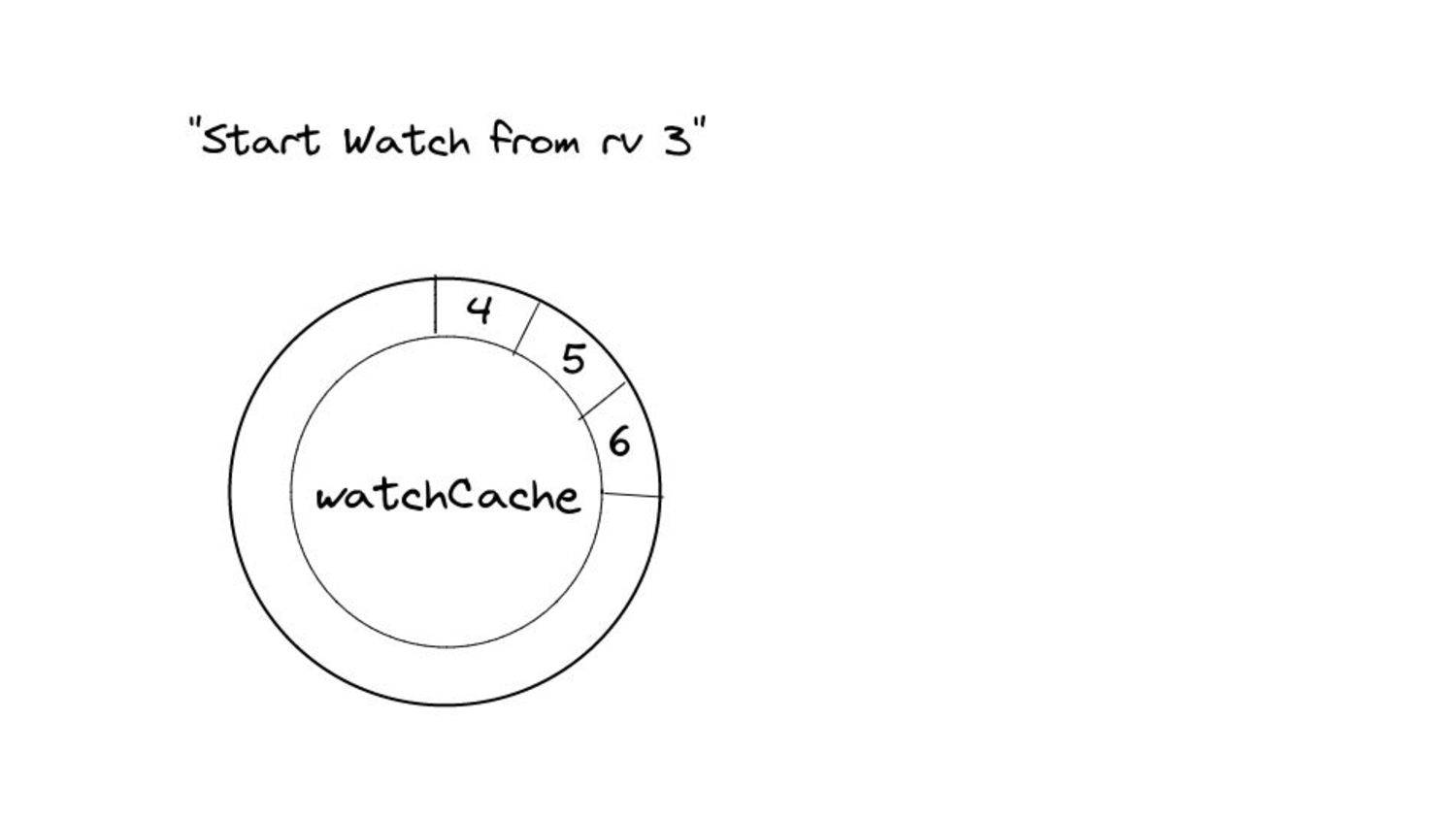
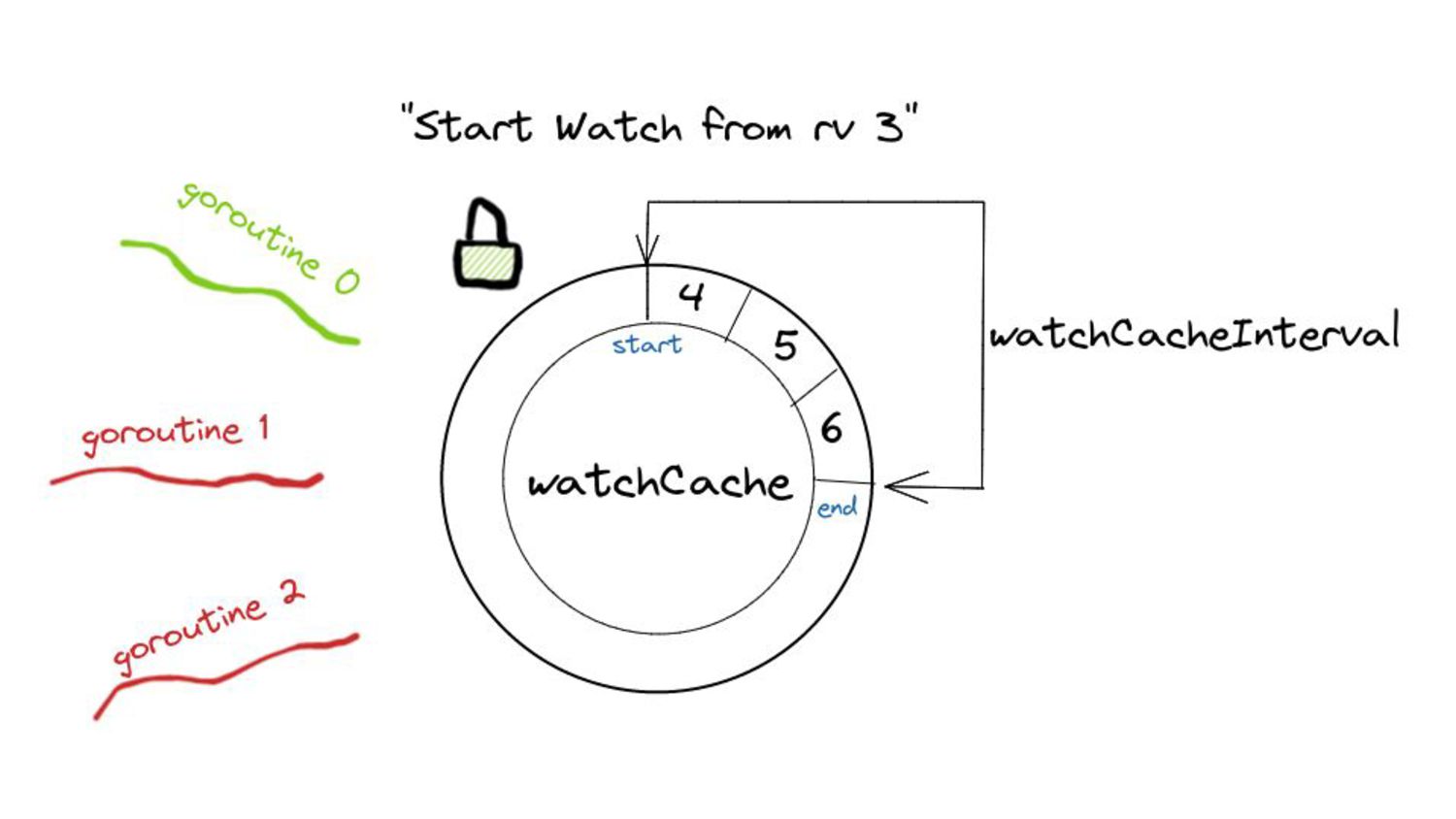
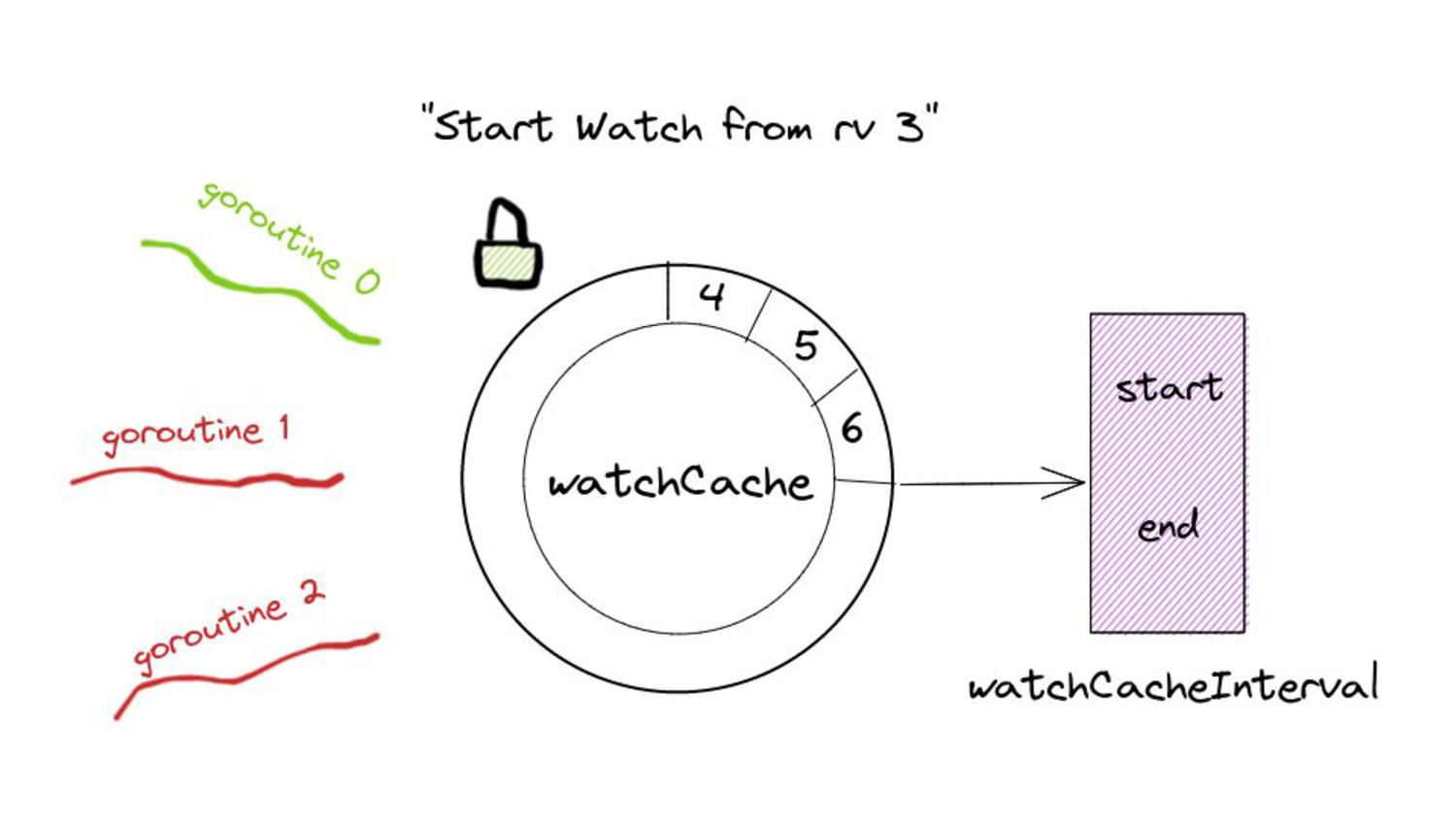
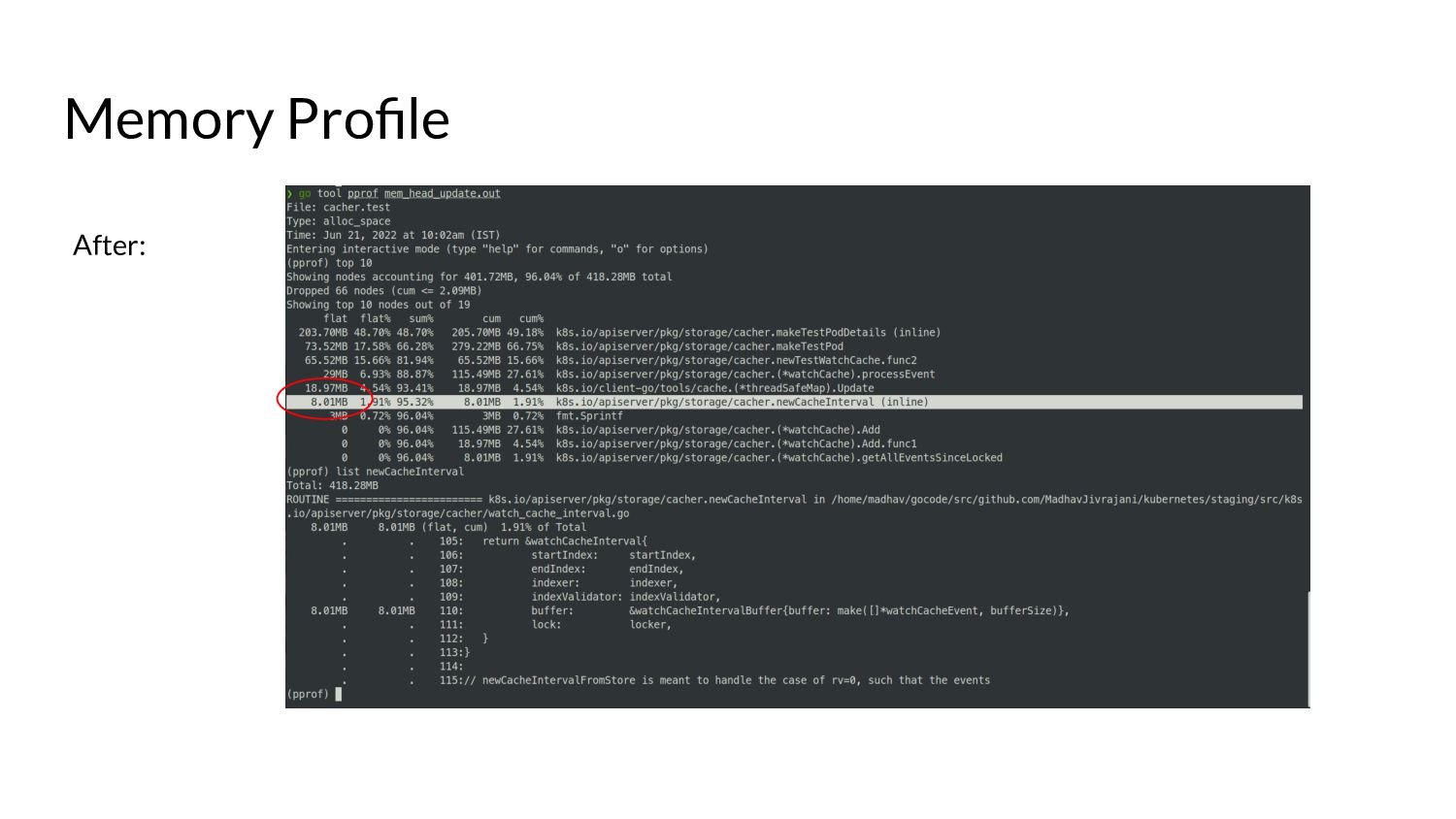
▪ Calculating start and end indices - uses binary search: fast! ▪ Allocating an internal buffer of constant size for further optimization. • This means we limit the memory consumption for watches from the past to a constant amount in 99% of the cases. ◦ The remaining 1% is for special cases like resource version 0. ◦ In this case, the performance is the same as before this change - no improvements.
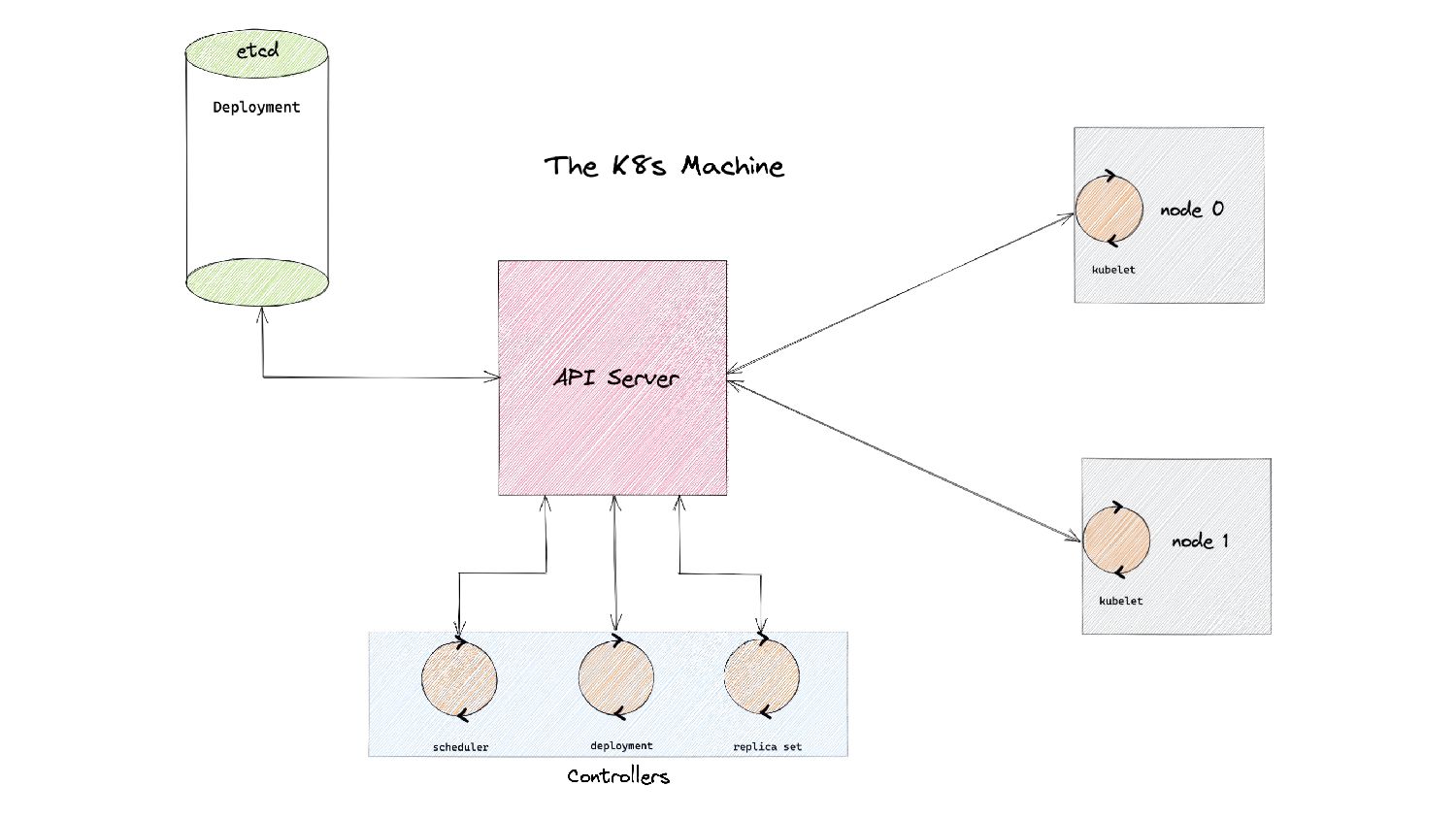
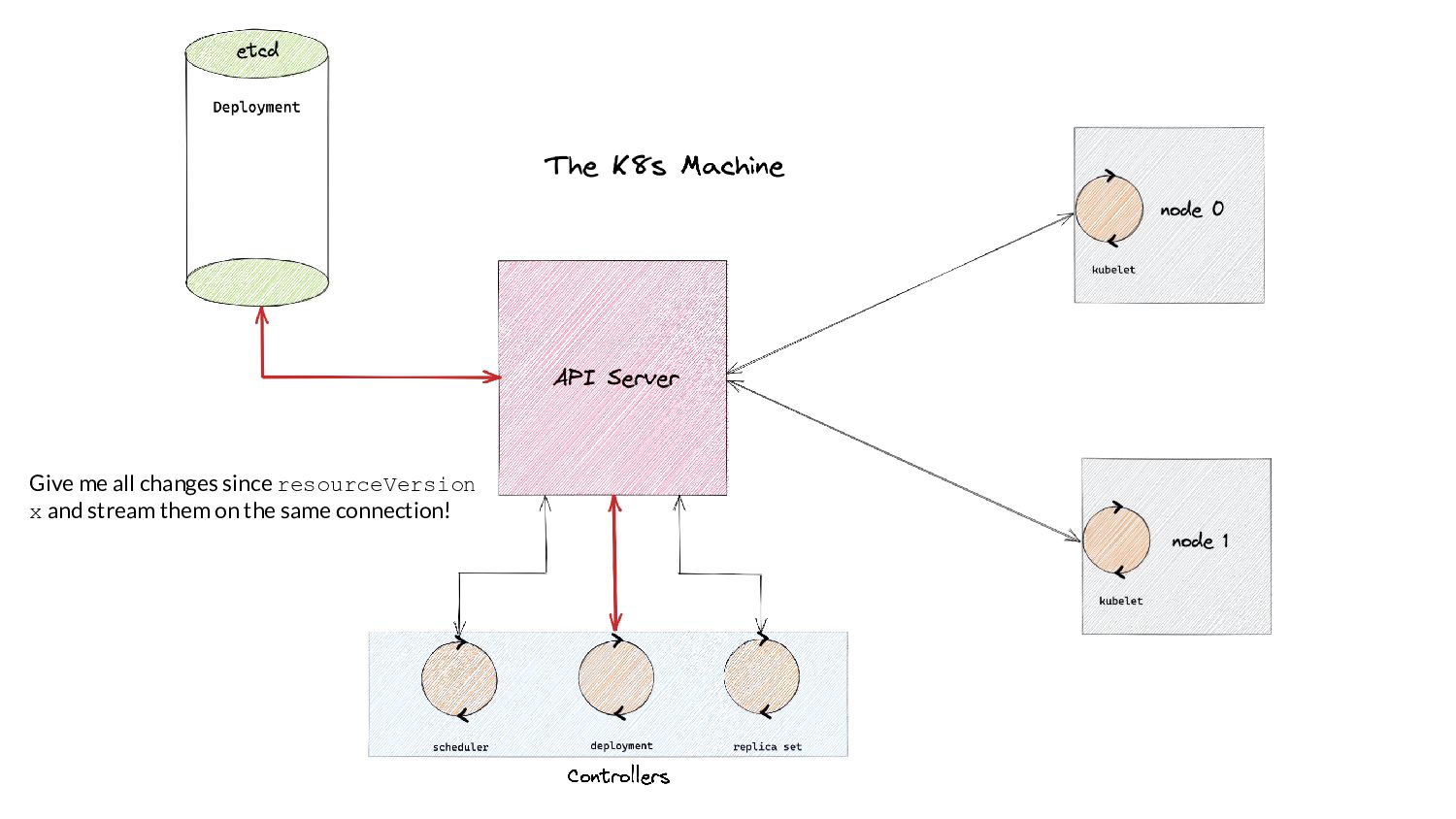
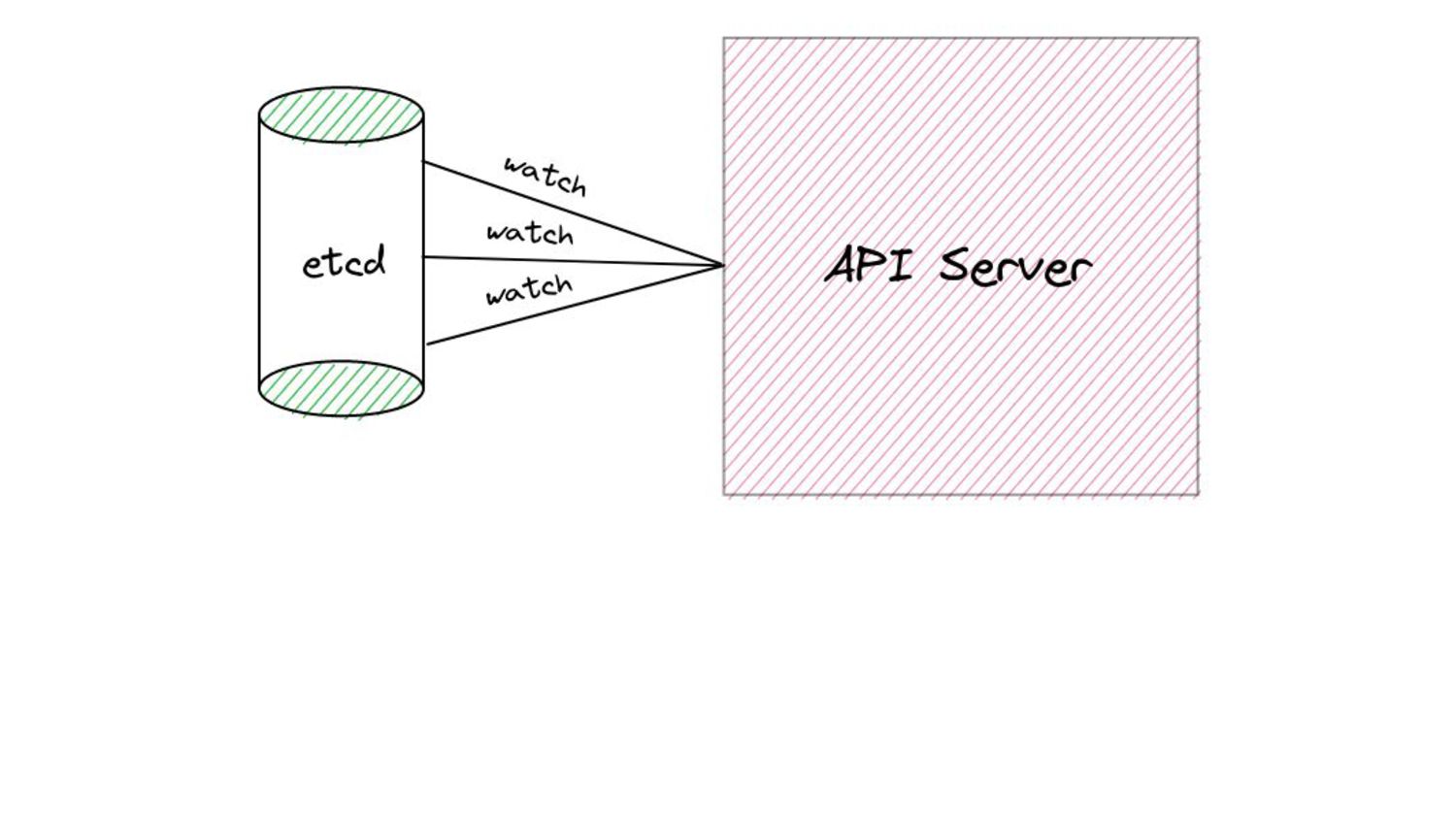
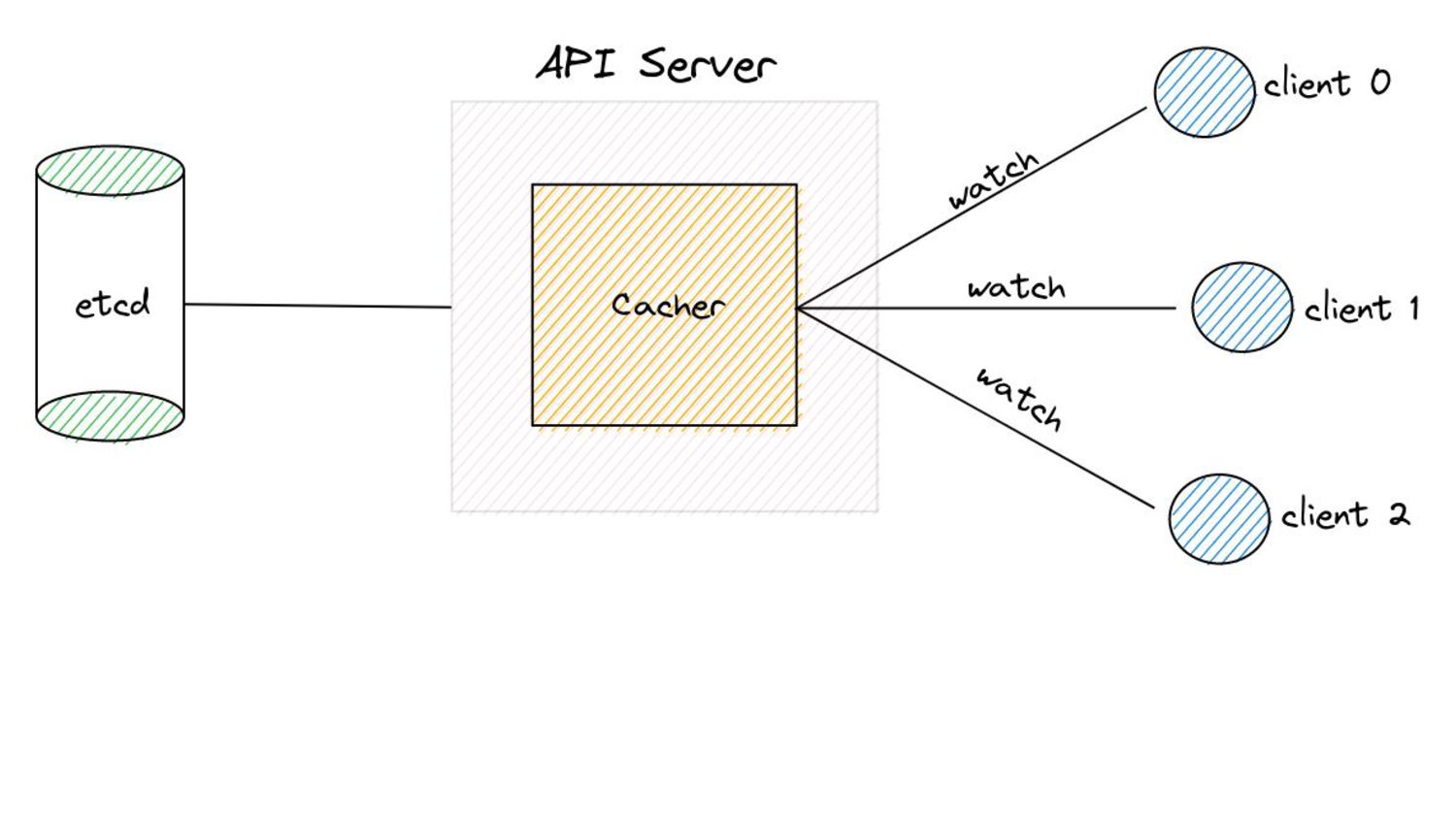
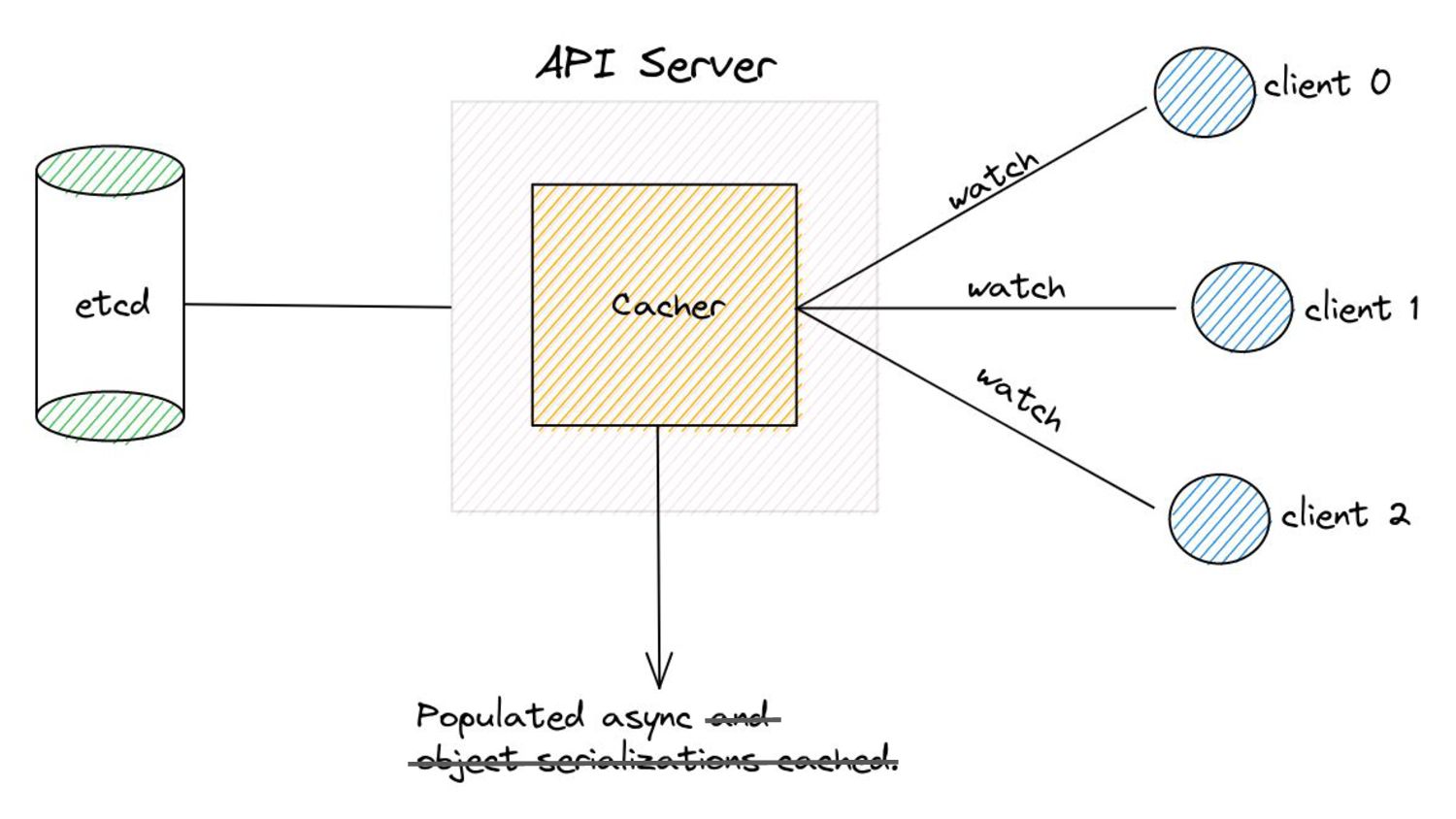
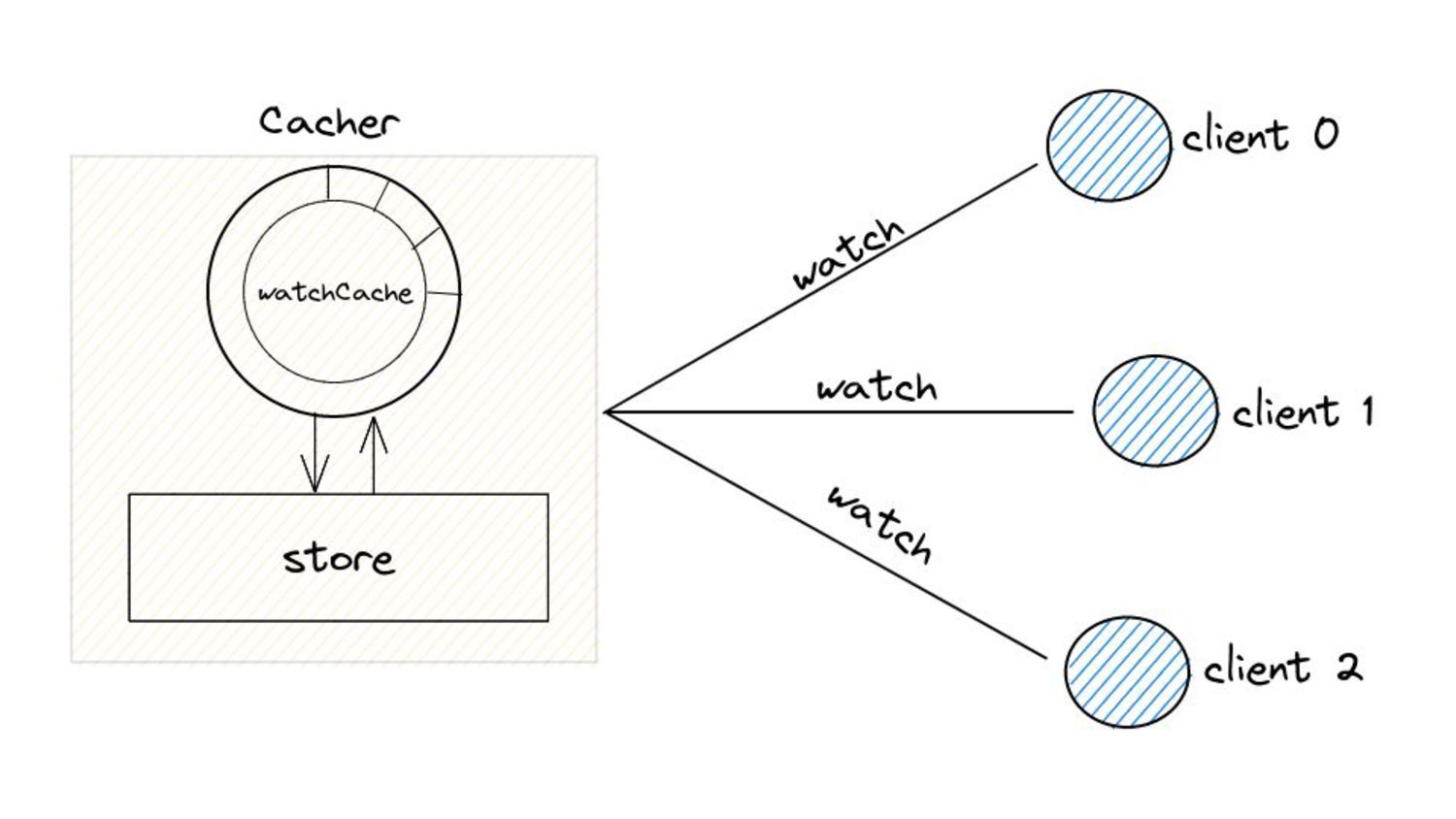
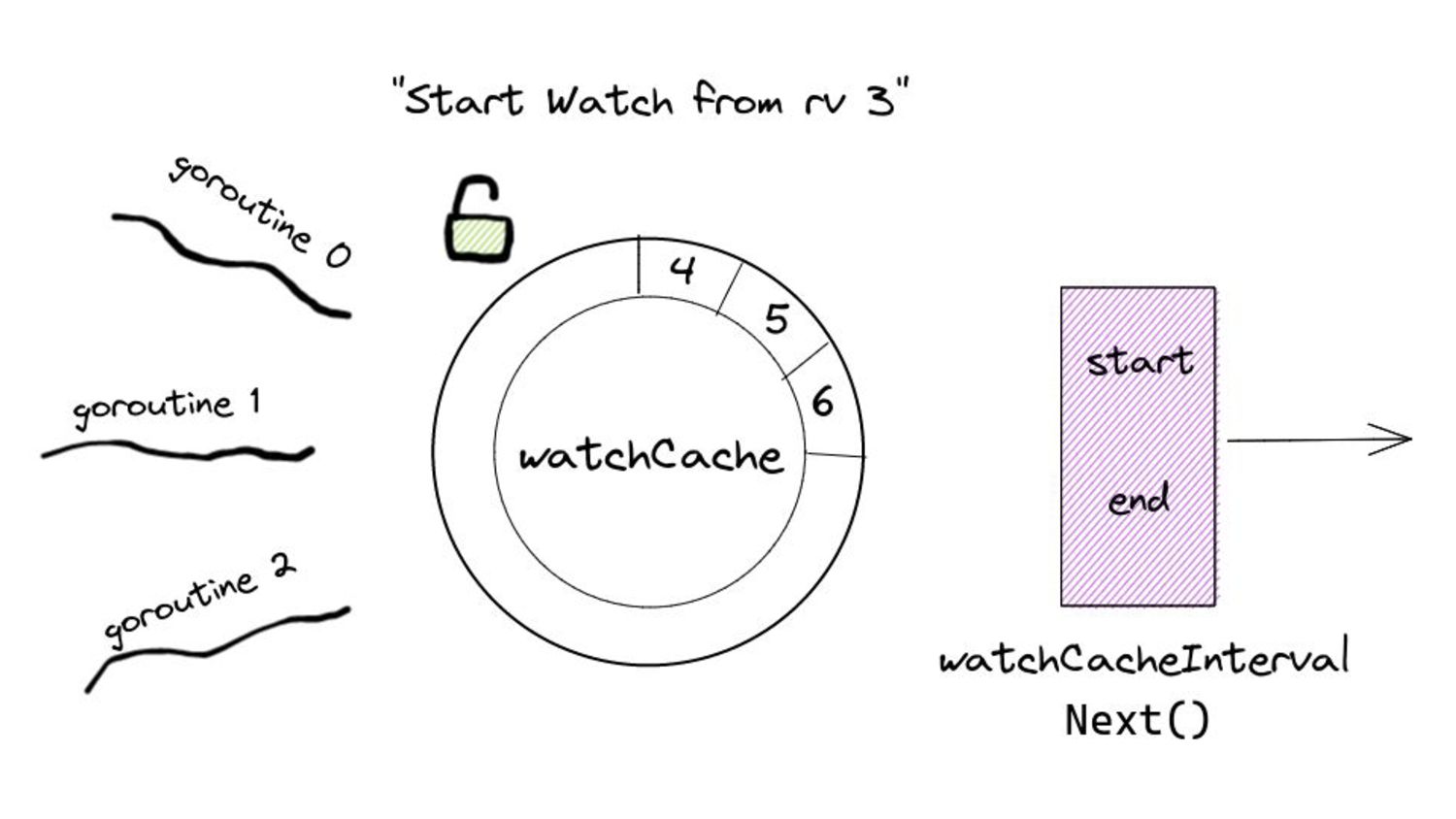
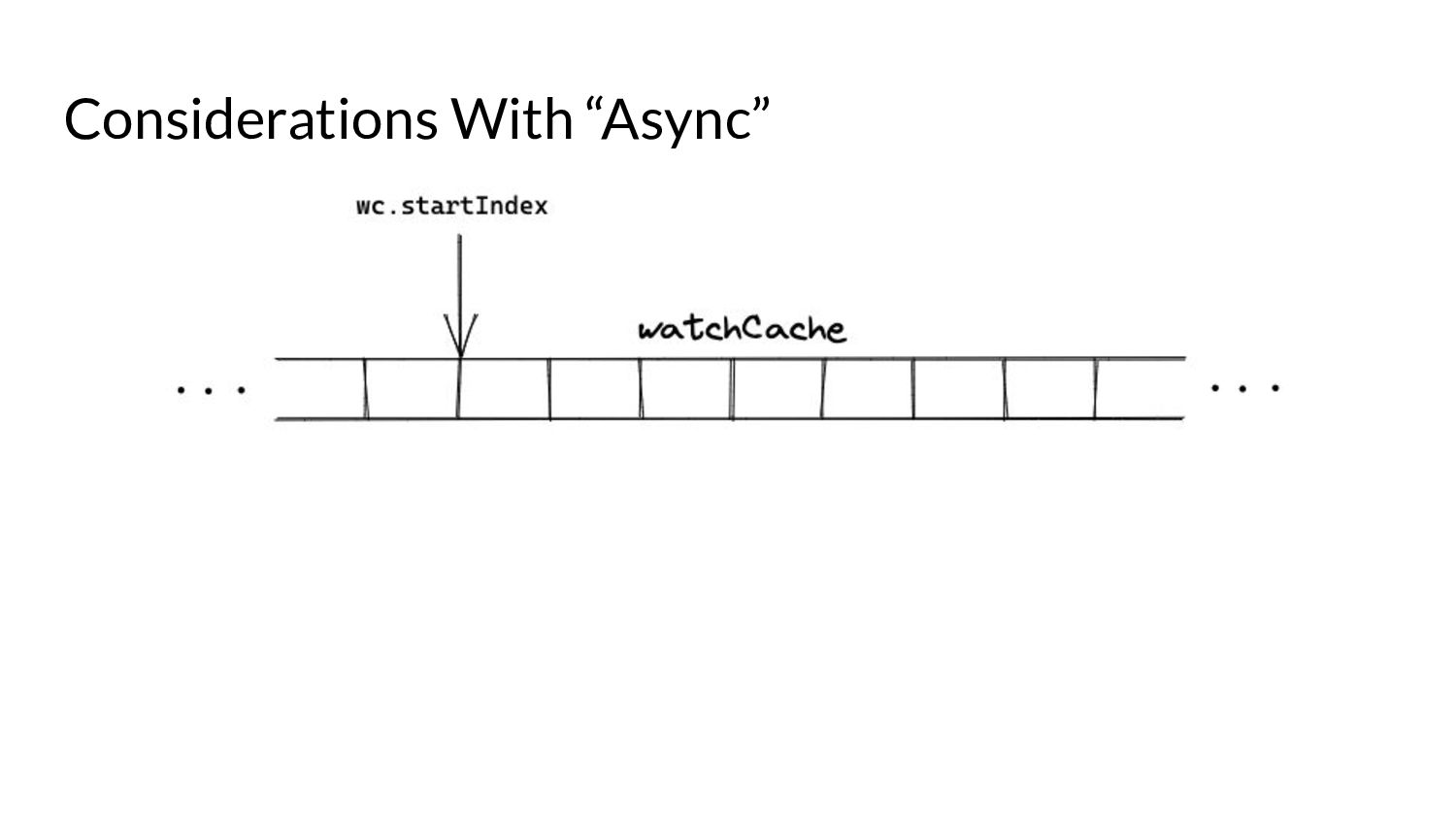
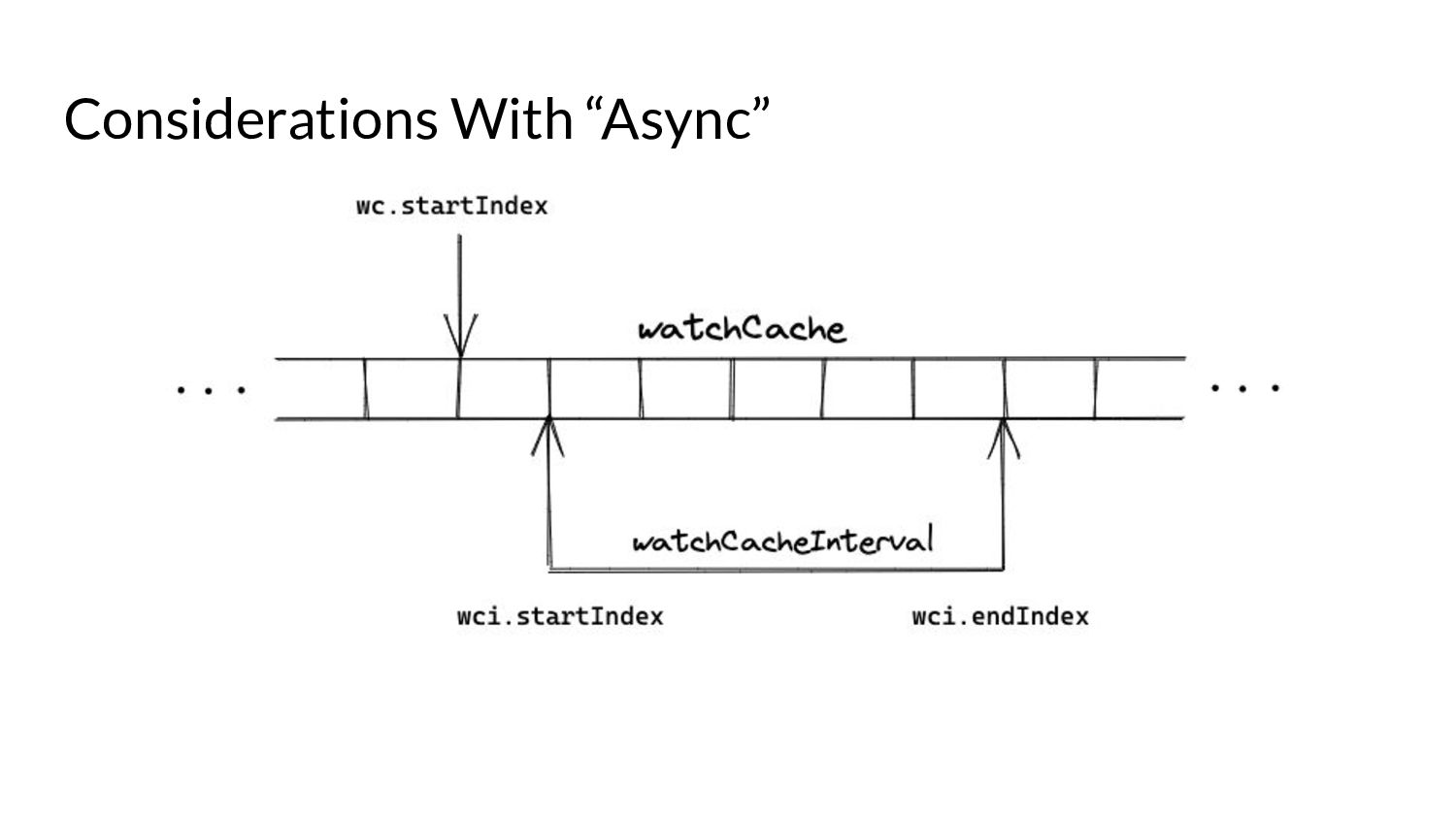
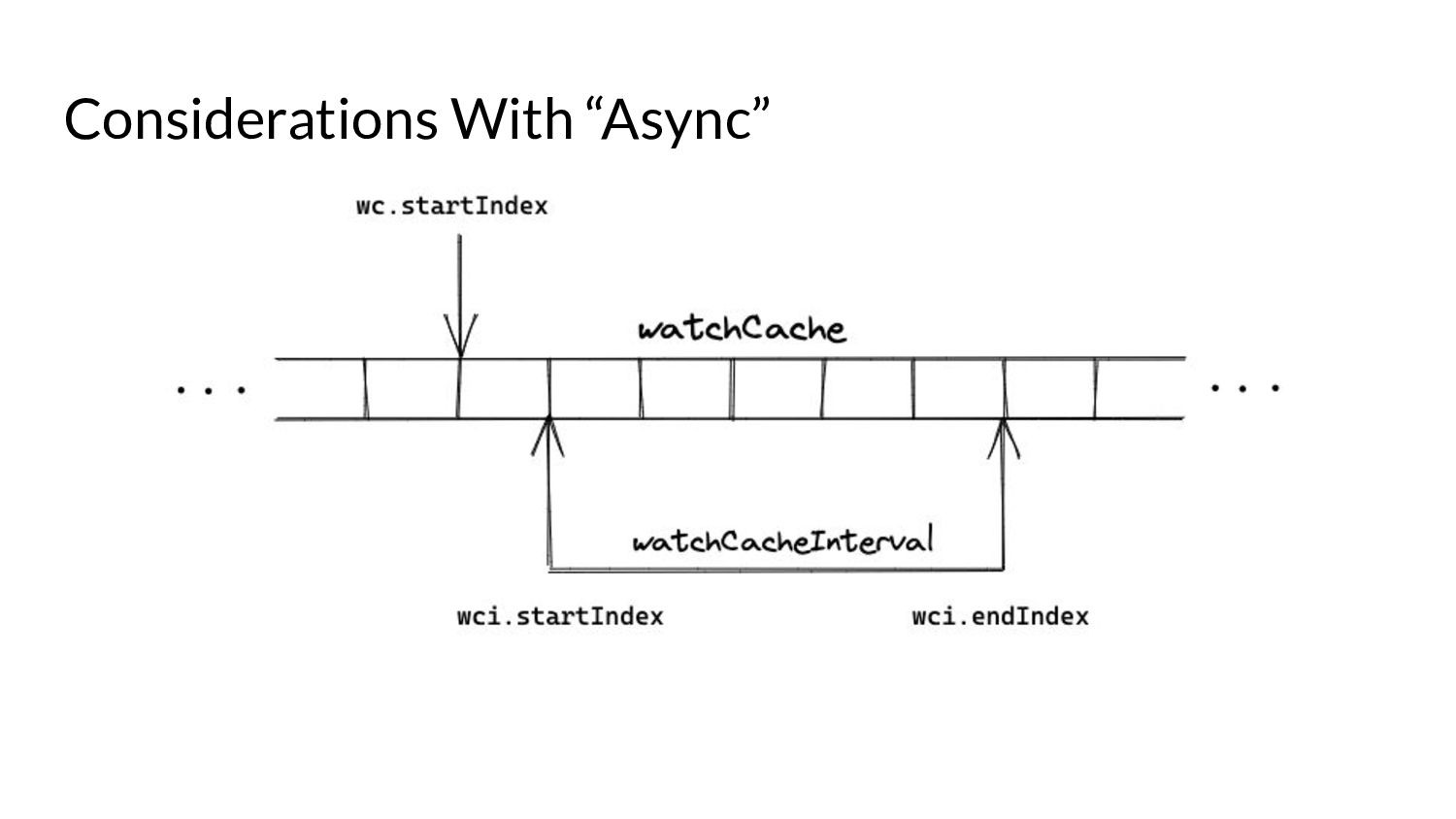
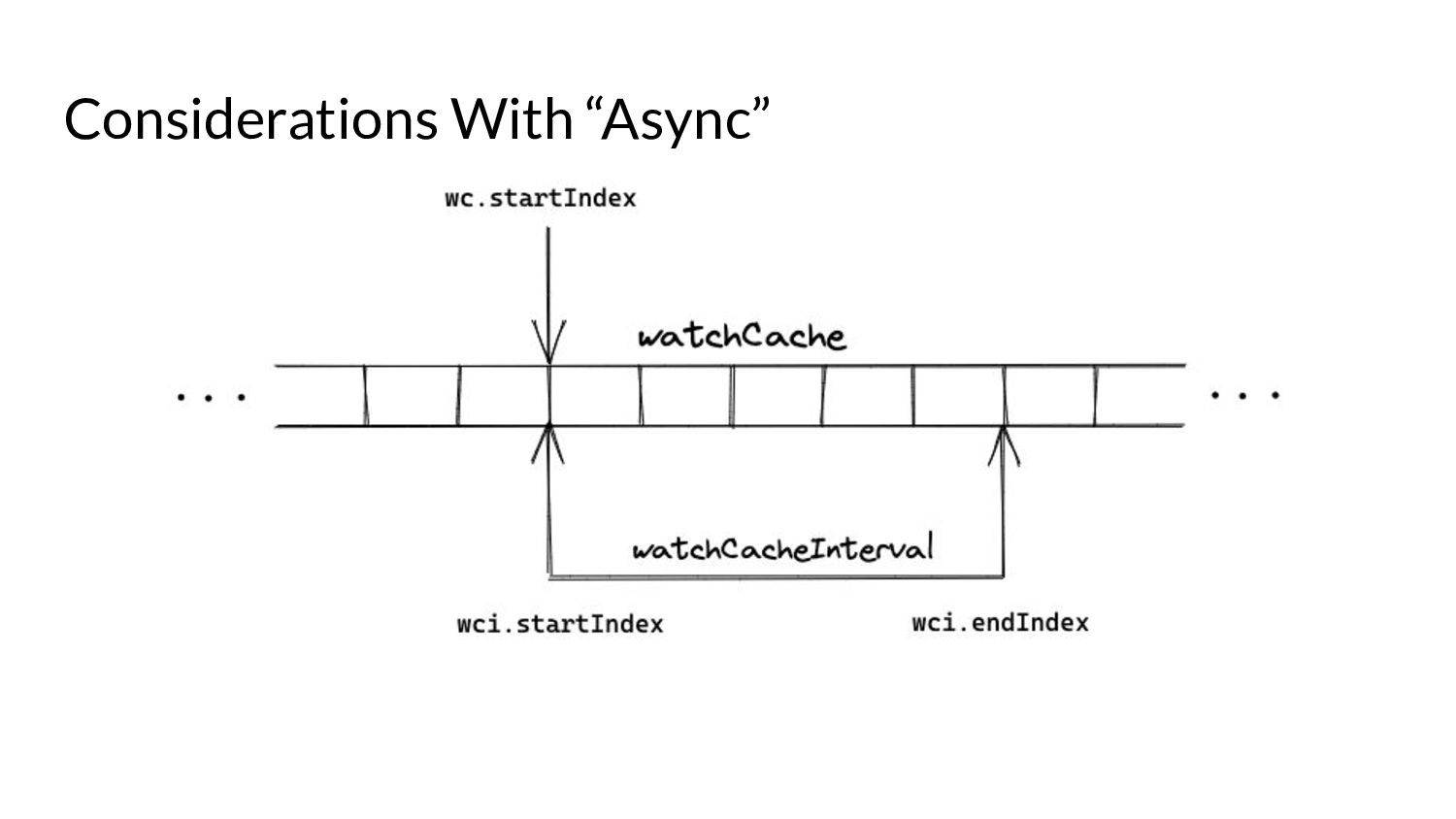
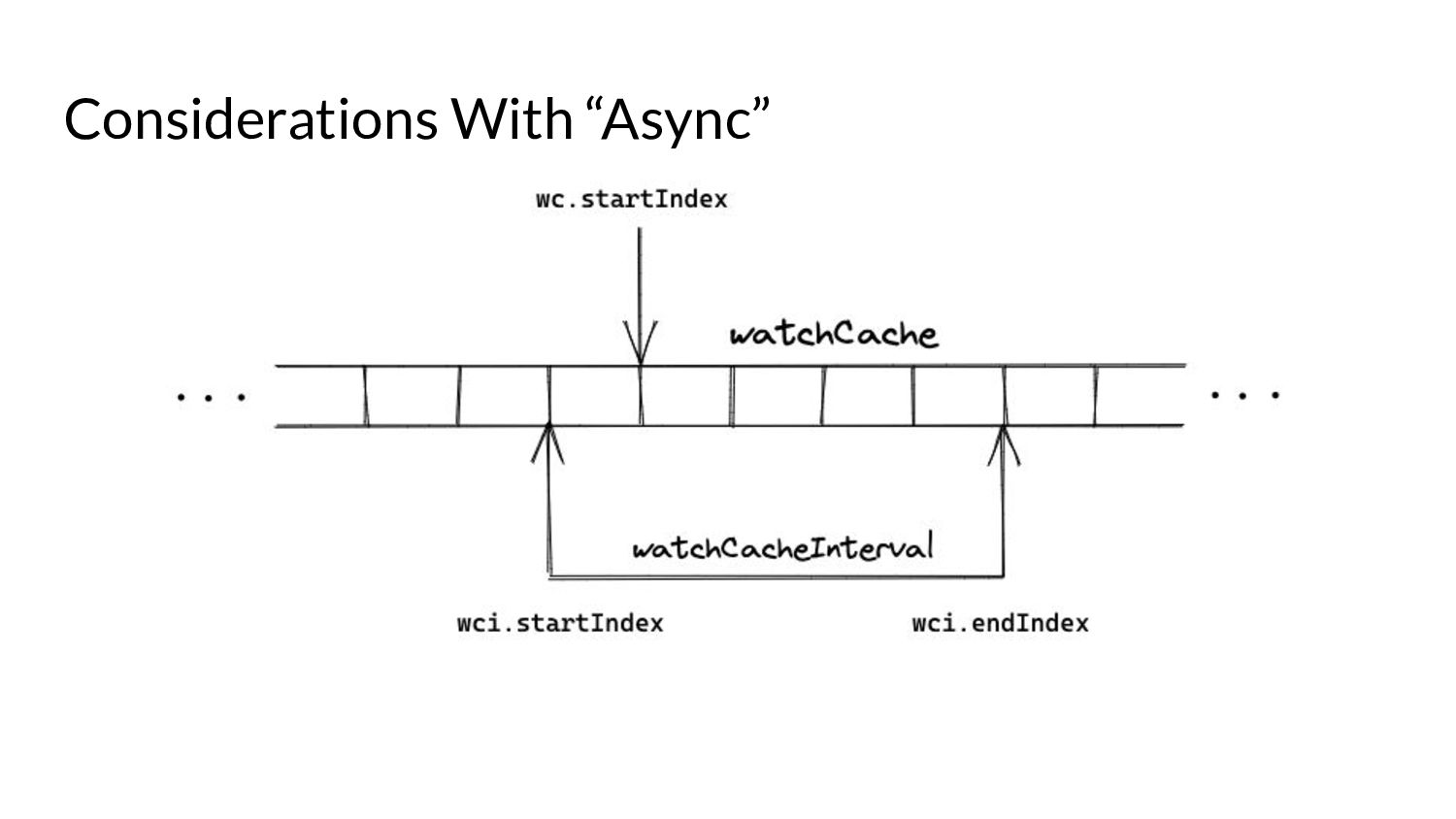
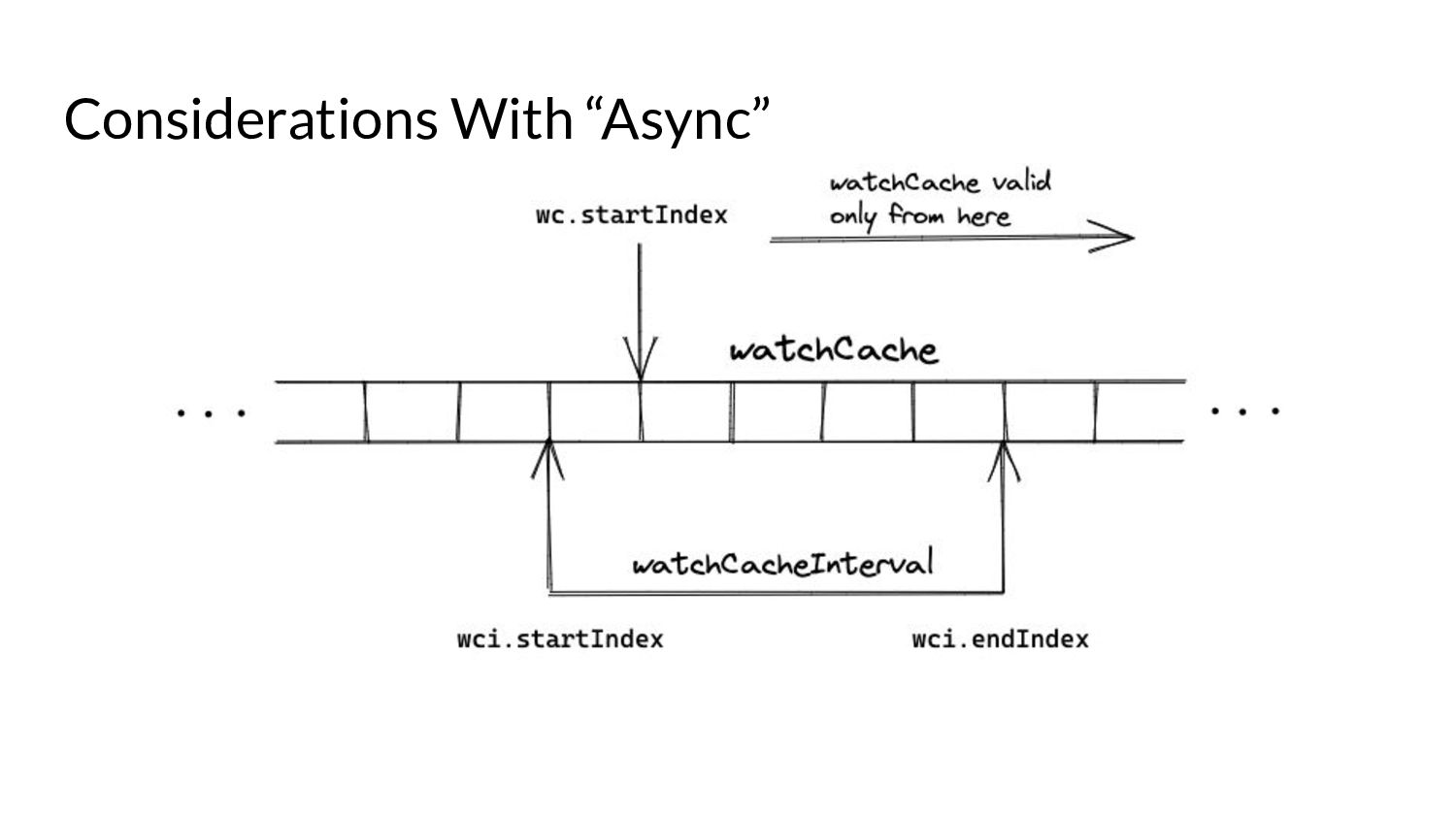
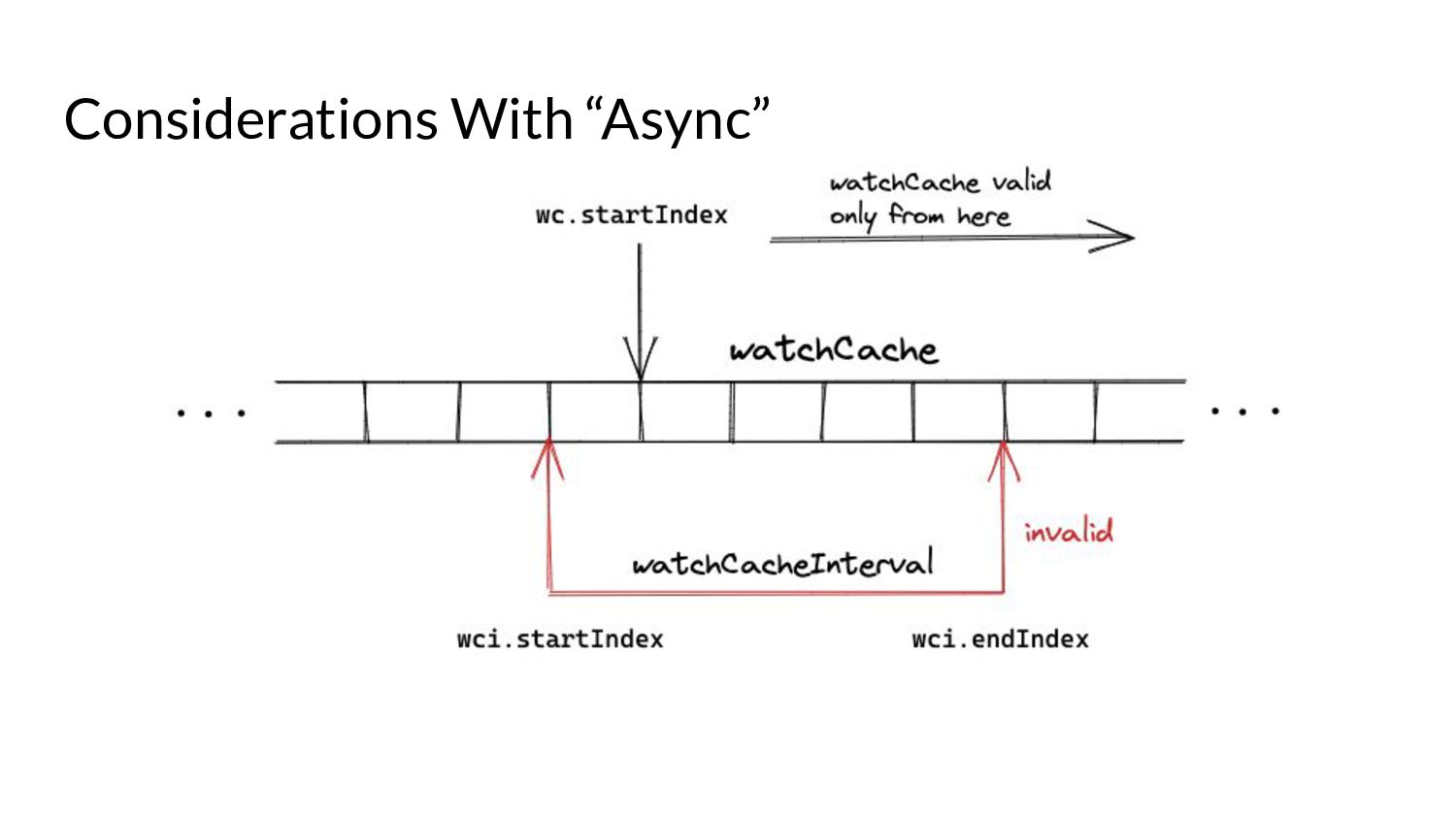
serve events asynchronously, what do we need to keep in mind? • Prelude: ◦ As and when the watchCache becomes full, events are popped off - this is called “propagation”. ◦ The event to be popped off is tracked by an index internally called the startIndex. ◦ The interval tracks the event to be served also using an index called startIndex (different entities, same name!)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}