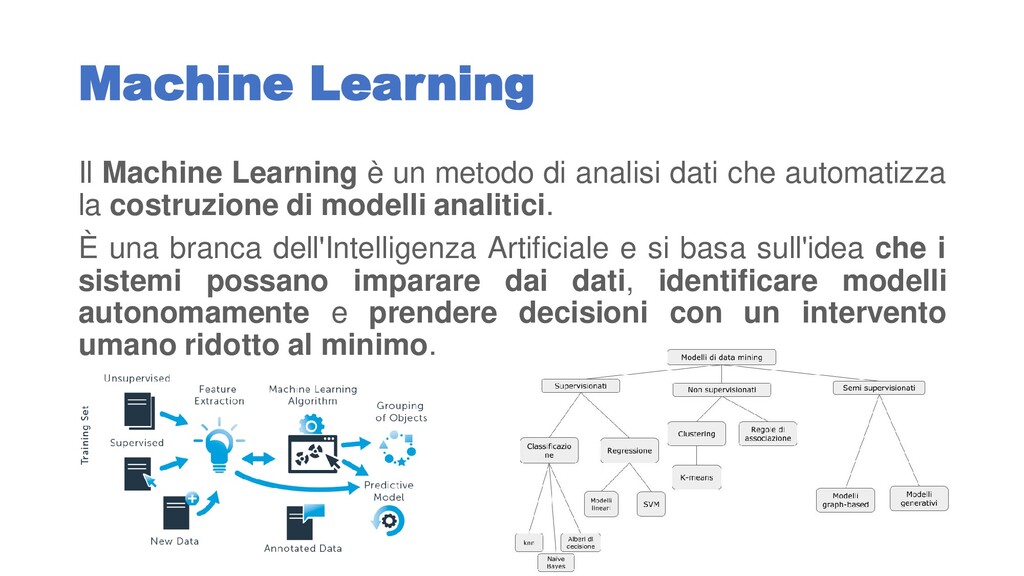
dati che automatizza la costruzione di modelli analitici. È una branca dell'Intelligenza Artificiale e si basa sull'idea che i sistemi possano imparare dai dati, identificare modelli autonomamente e prendere decisioni con un intervento umano ridotto al minimo.
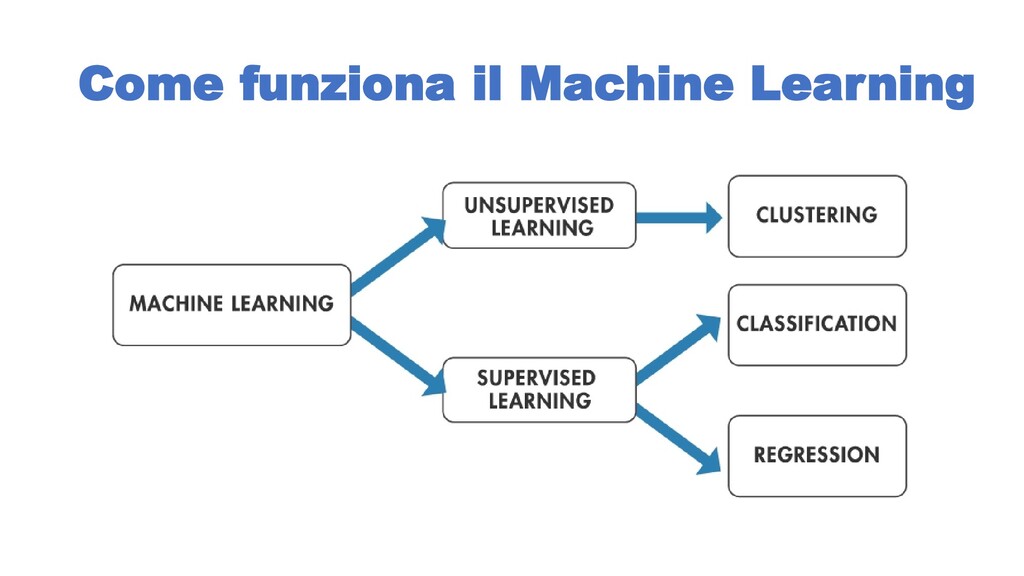
quale categoria appartiene un determinato dato. • Raggruppamento (clustering): quando si vuole raggruppare i dati che presentano caratteristiche simili. • Regressione: prevedere il valore futuro di un dato avendo noto il suo valore attuale.
vengono “dati in pasto” sia dei set di dati come input sia le informazioni relative ai risultati desiderati, con l’obiettivo che il sistema identifichi una regola generale che colleghi i dati in ingresso con quelli in uscita, in modo da poter poi riutilizzare tale regola per altri compiti simili.
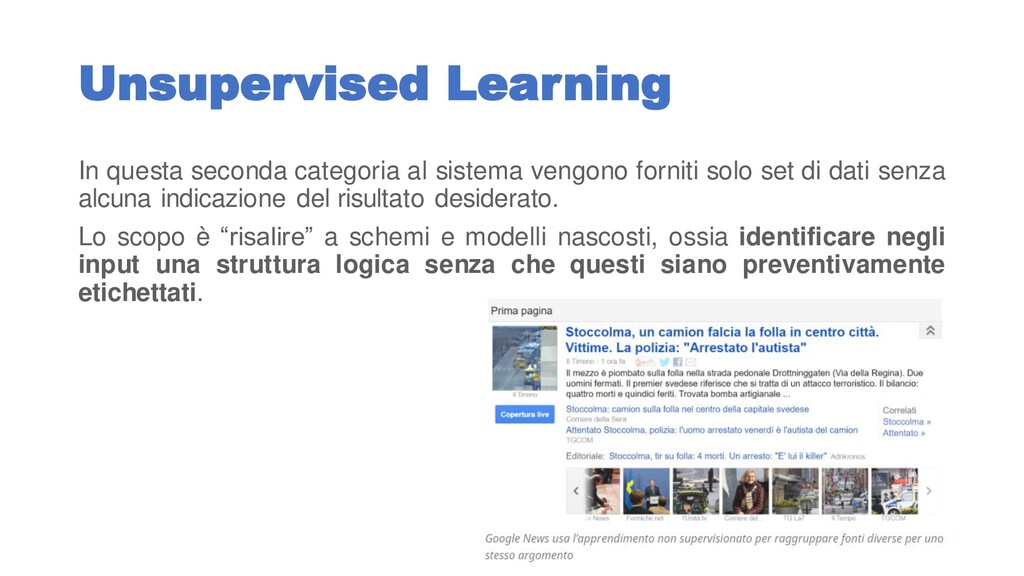
solo set di dati senza alcuna indicazione del risultato desiderato. Lo scopo è “risalire” a schemi e modelli nascosti, ossia identificare negli input una struttura logica senza che questi siano preventivamente etichettati.
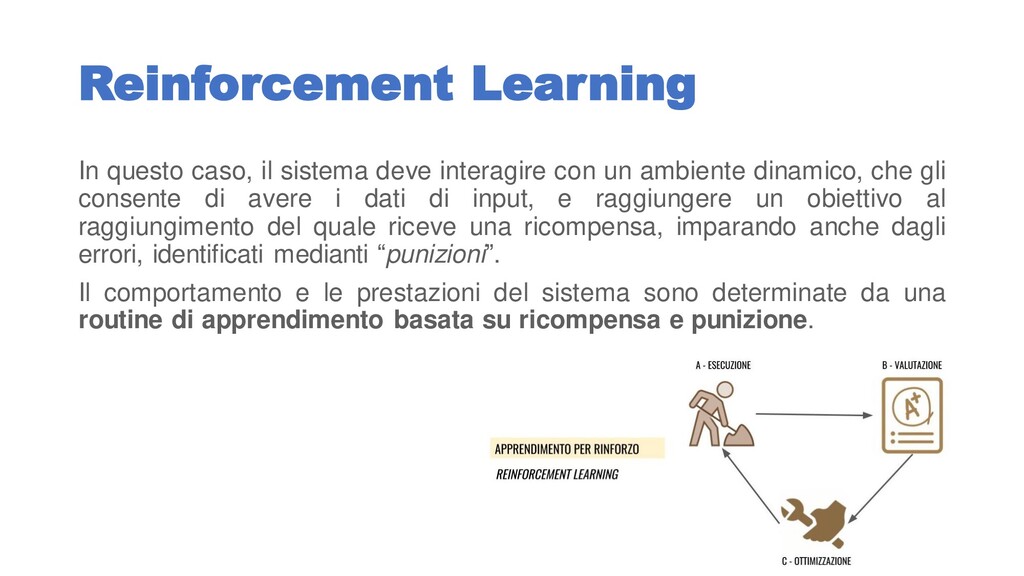
un ambiente dinamico, che gli consente di avere i dati di input, e raggiungere un obiettivo al raggiungimento del quale riceve una ricompensa, imparando anche dagli errori, identificati medianti “punizioni”. Il comportamento e le prestazioni del sistema sono determinate da una routine di apprendimento basata su ricompensa e punizione.
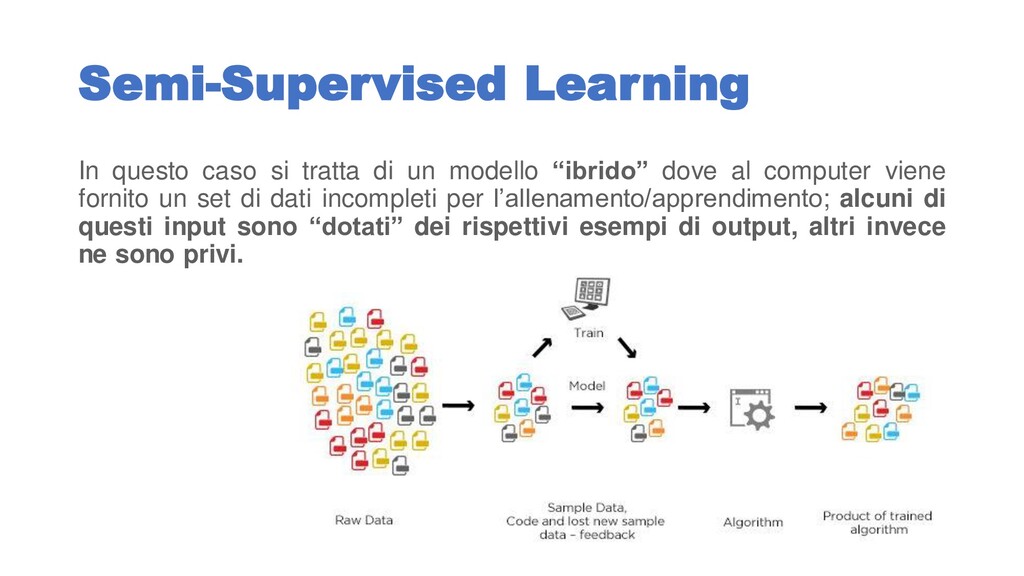
“ibrido” dove al computer viene fornito un set di dati incompleti per l’allenamento/apprendimento; alcuni di questi input sono “dotati” dei rispettivi esempi di output, altri invece ne sono privi.
di una variabile dipendente da tante altre. • Anomaly Detection Utilizzato per identificare valori anomali o casi insoliti nei dati. I modelli di rilevamento delle anomalie memorizzano le informazioni sul comportamento normale. Ciò consente di identificare i valori anomali anche se non sono conformi a uno schema noto. • Apriori Machine Learning Algorithm Genera delle regole di associazione a partire da un insieme di dati. Queste regole sono nella forma «if… then».
supervisionato utilizzato sia per problemi di classificazione che di regressione. • Naïve Bayes Classifier Algorithm Algoritmo di classificazione di contenuti testuali. • K- Means Clustering Algorithm Algoritmo iterativo che si occupa di suddividere una popolazione in k gruppi determinati a priori. In questo caso, quindi, è necessario suddividere i risultati in k gruppi diversi, in modo che tutti quelli che appartengono ad un gruppo siano correlati.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![https://francescomarchitelli.com [email protected]](https://files.speakerdeck.com/presentations/2c4763b9ccc04880b1c709fe0d1b4354/slide_16.jpg){kind=link}