𝔼[𝑌 ∣ 𝐷 = 𝑑, 𝑀 = 𝑚, 𝑋 = 𝑥] とする • 反復回帰関数を 𝜂𝑐𝑟𝑜𝑠𝑠 (𝑑, 𝑑′, 𝑥) = 𝔼[𝑓0 (𝑑, 𝑀, 𝑋) ∣ 𝐷 = 𝑑′, 𝑋 = 𝑥] とする • 線形汎関数𝑚(𝑊, 𝑓) = 𝑓0 𝑑, 𝑚, 𝑥 を用いると、 𝜃0 は以下のように書ける: 𝜃0 𝑑, 𝑑′ = ∫ ∫ 𝑓0 𝑑, 𝑚, 𝑥 𝑝𝑀∣𝐷,𝑋 𝑚 𝑑′, 𝑥 𝑑𝑚 𝑑𝑃(𝑥). • リース表現量 𝛼0 𝐷, 𝑋 ≔ 1[𝐷 = 𝑑] 𝑒0 (𝑑, 𝑋) 𝜔0 𝑀, 𝑋 • 媒介密度比 𝜔0 (𝑚, 𝑥; 𝑑, 𝑑′) = 𝑝𝑀∣𝐷,𝑋 (𝑚 ∣ 𝑑′, 𝑥)/𝑝𝑀∣𝐷,𝑋 (𝑚 ∣ 𝑑, 𝑥) • ネイマン直交スコア 𝜓 𝑊; 𝜂, 𝜃 = 1[𝐷 = 𝑑] 𝑒0 (𝑑, 𝑋) 𝜔0 𝑀, 𝑋 𝑌 − 𝑓0 𝑑, 𝑀, 𝑋 + 1[𝐷 = 𝑑′] 𝑒0 (𝑑′, 𝑋) (𝑓0 (𝑑, 𝑀, 𝑋) − 𝜂𝑐𝑟𝑜𝑠𝑠 (𝑑, 𝑑′, 𝑋)) + 𝜂𝑐𝑟𝑜𝑠𝑠 (𝑑, 𝑑′, 𝑋) − 𝜃 ◼ 局外母数 𝜂 = (𝛾0 , 𝜋0 , 𝜔0 , 𝜂𝑐𝑟𝑜𝑠𝑠 ) • 回帰 𝛾0 (𝑑, 𝑚, 𝑥) = 𝔼[𝑌 ∣ 𝐷 = 𝑑, 𝑀 = 𝑚, 𝑋 = 𝑥],傾向スコア 𝜋0 (𝑑 ∣ 𝑥) = ℙ(𝐷 = 𝑑 ∣ 𝑋 = 𝑥)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
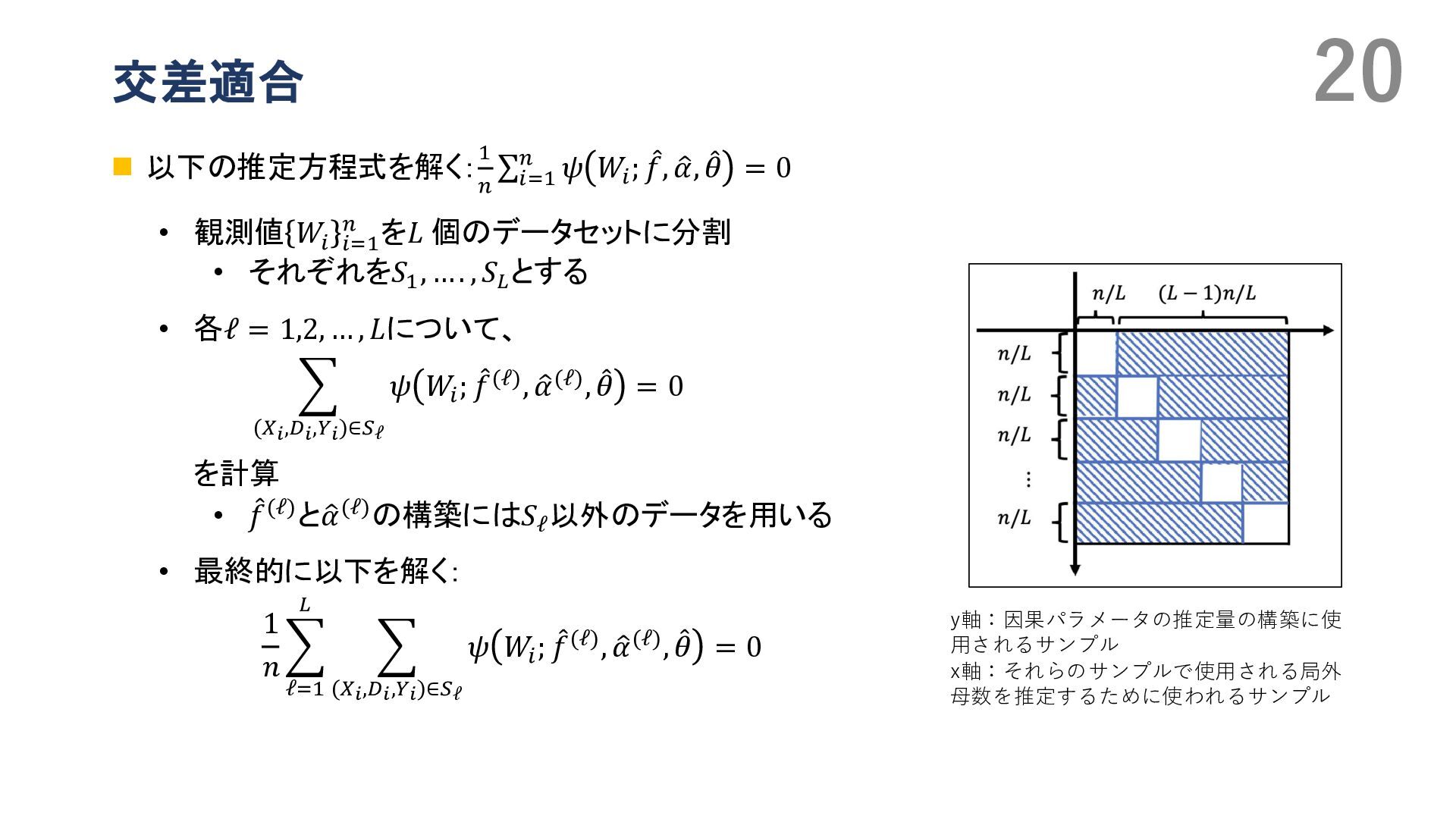{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
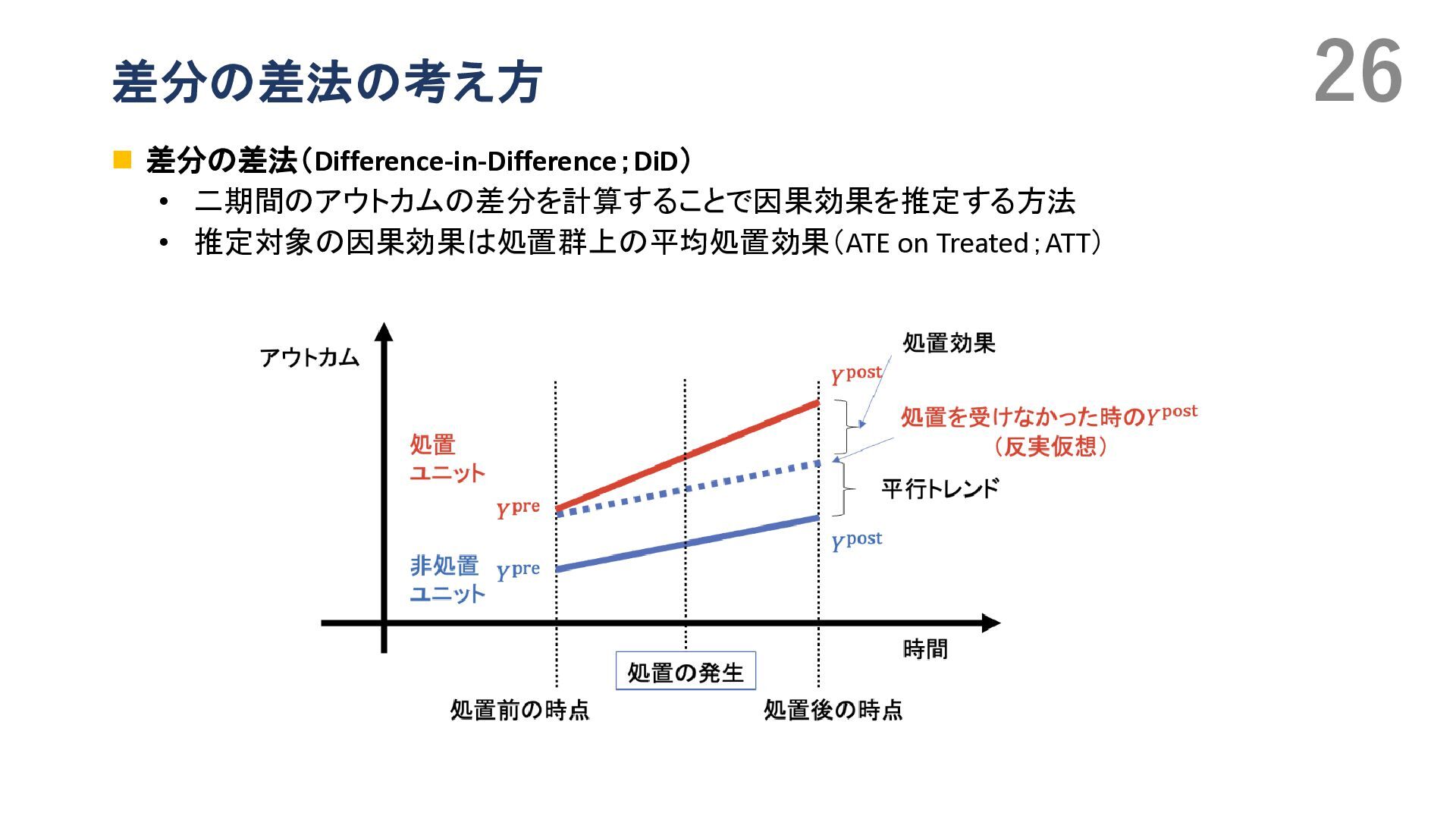{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}