ATE = 1 𝑛 𝑖=1 𝑛 𝜓 𝐷𝑖 , 𝑋𝑖 , 𝑌𝑖 ; መ 𝑓, Ƹ 𝑒, 𝜃0 ATE = 1 𝑛 𝑖=1 𝑛 𝜓 𝐷𝑖 , 𝑋𝑖 , 𝑌𝑖 ; 𝑓0 , 𝑒0 , 𝜃0 ATE − 1 𝑛 𝑖=1 𝑛 𝜓 𝐷𝑖 , 𝑋𝑖 , 𝑌𝑖 ; 𝑓0 , 𝑒0 , 𝜃0 ATE + 1 𝑛 𝑖=1 𝑛 𝜓 𝐷𝑖 , 𝑋𝑖 , 𝑌𝑖 ; መ 𝑓, Ƹ 𝑒, 𝜃0 ATE = 1 𝑛 𝑖=1 𝑛 𝜓 𝐷𝑖 , 𝑋𝑖 , 𝑌𝑖 ; 𝑓0 , 𝑒0 , 𝜃0 ATE − 1 𝑛 𝑖=1 𝑛 𝜓 𝐷𝑖 , 𝑋𝑖 , 𝑌𝑖 ; 𝑓0 , 𝑒0 , 𝜃0 ATE − 1 𝑛 𝑖=1 𝑛 𝜓 𝐷𝑖 , 𝑋𝑖 , 𝑌𝑖 ; መ 𝑓, Ƹ 𝑒, 𝜃0 ATE − 𝑛𝔼 𝜓 𝐷𝑖 , 𝑋𝑖 , 𝑌𝑖 ; 𝑓0 , 𝑒0 , 𝜃0 ATE − 𝜓 𝐷𝑖 , 𝑋𝑖 , 𝑌𝑖 ; መ 𝑓, Ƹ 𝑒, 𝜃0 ATE + 𝑛𝔼 𝜓 𝐷𝑖 , 𝑋𝑖 , 𝑌𝑖 ; 𝑓0 , 𝑒0 , 𝜃0 ATE − 𝜓 𝐷𝑖 , 𝑋𝑖 , 𝑌𝑖 ; መ 𝑓, Ƹ 𝑒, 𝜃0 ATE = 1 𝑛 𝑖=1 𝑛 𝜓 𝐷𝑖 , 𝑋𝑖 , 𝑌𝑖 ; 𝑓0 , 𝑒0 , 𝜃0 ATE − 1 𝑛 𝑖=1 𝑛 𝜓 𝐷𝑖 , 𝑋𝑖 , 𝑌𝑖 ; 𝑓0 , 𝑒0 , 𝜃0 ATE − 1 𝑛 𝑖=1 𝑛 𝜓 𝐷𝑖 , 𝑋𝑖 , 𝑌𝑖 ; መ 𝑓, Ƹ 𝑒𝜃0 ATE − 𝑛𝔼 𝜓 𝐷𝑖 , 𝑋𝑖 , 𝑌𝑖 ; 𝑓0 , 𝑒0 , 𝜃0 ATE − 𝜓 𝐷𝑖 , 𝑋𝑖 , 𝑌𝑖 ; መ 𝑓, Ƹ 𝑒, 𝜃0 ATE − 𝑛𝔼 𝜓 𝐷𝑖 , 𝑋𝑖 , 𝑌𝑖 ; 𝑓0 , 𝑒0 , 𝜃0 ATE − 𝜓 𝐷𝑖 , 𝑋𝑖 , 𝑌𝑖 ; መ 𝑓, Ƹ 𝑒, 𝜃0 ATE 経験過程項:Donsker条件、もしくはサンプル分割(交差適合)で𝑜𝑝 (1) 推定誤差のみ:レート条件で𝑜𝑝 (1)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
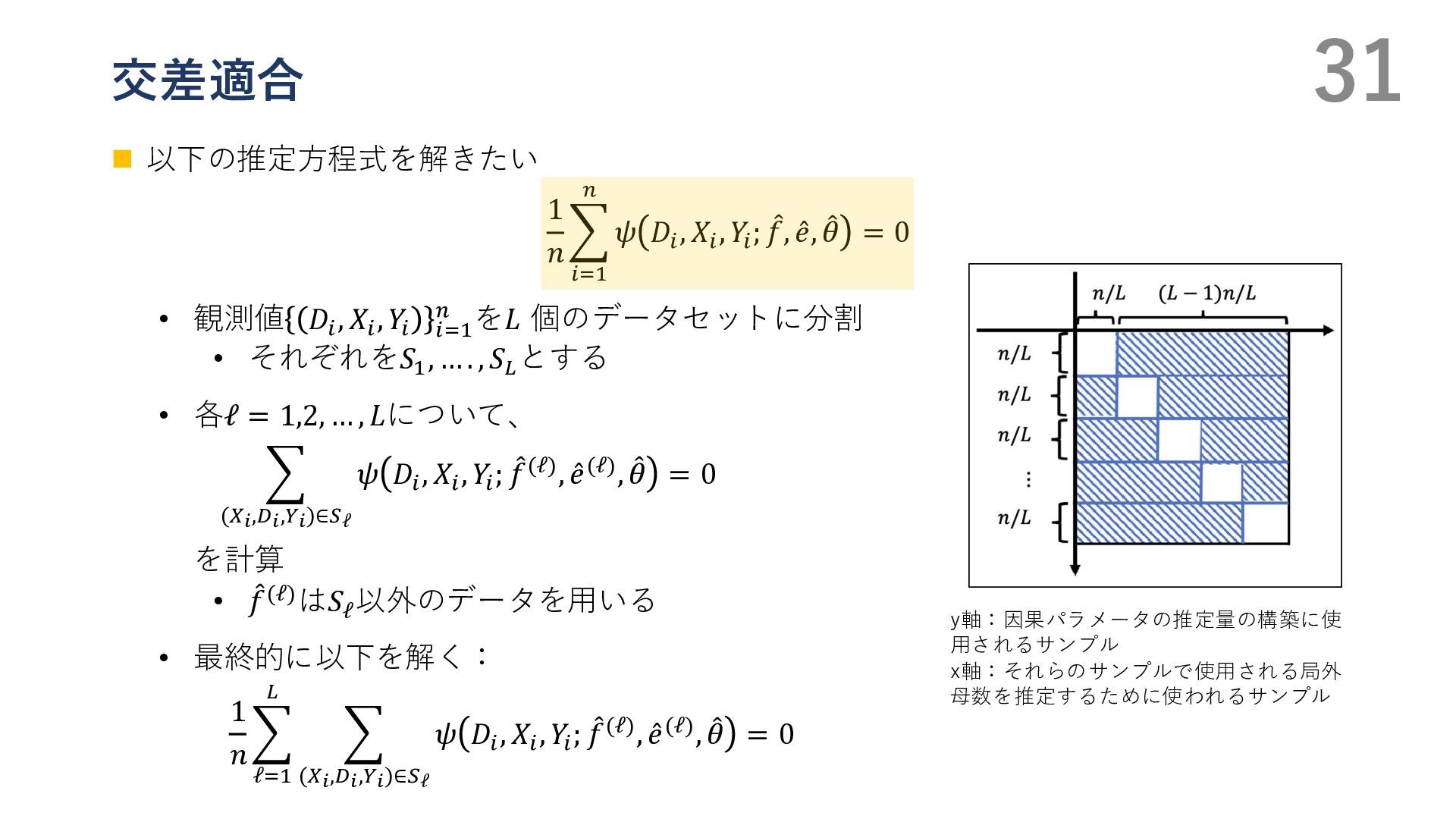{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}