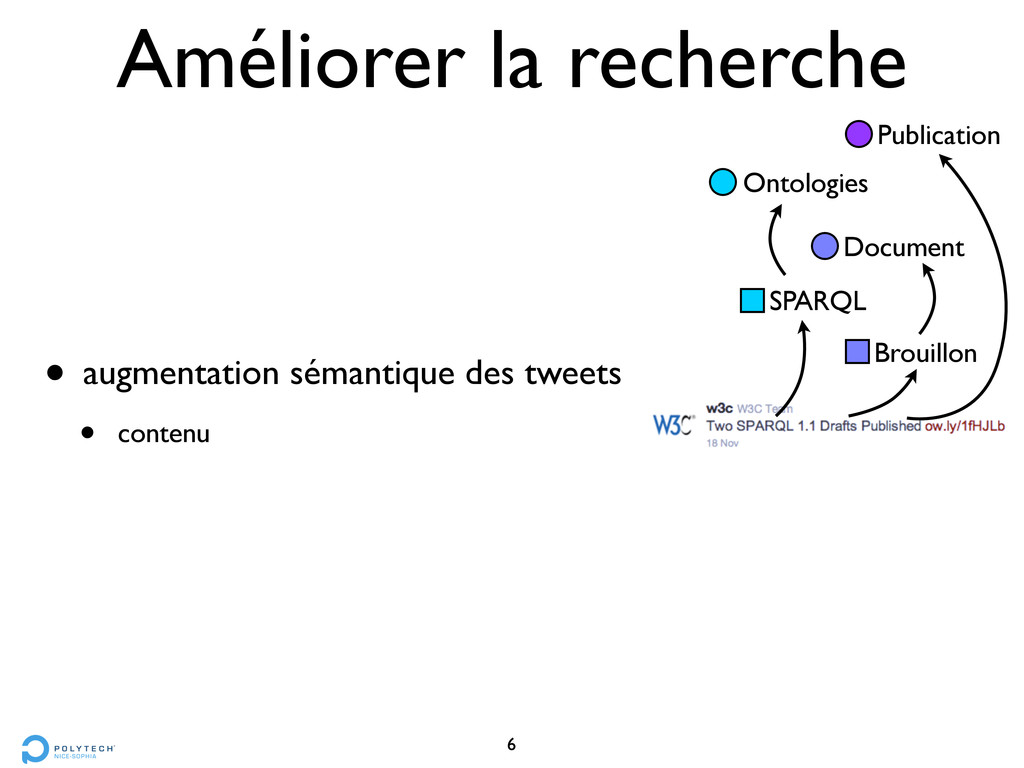
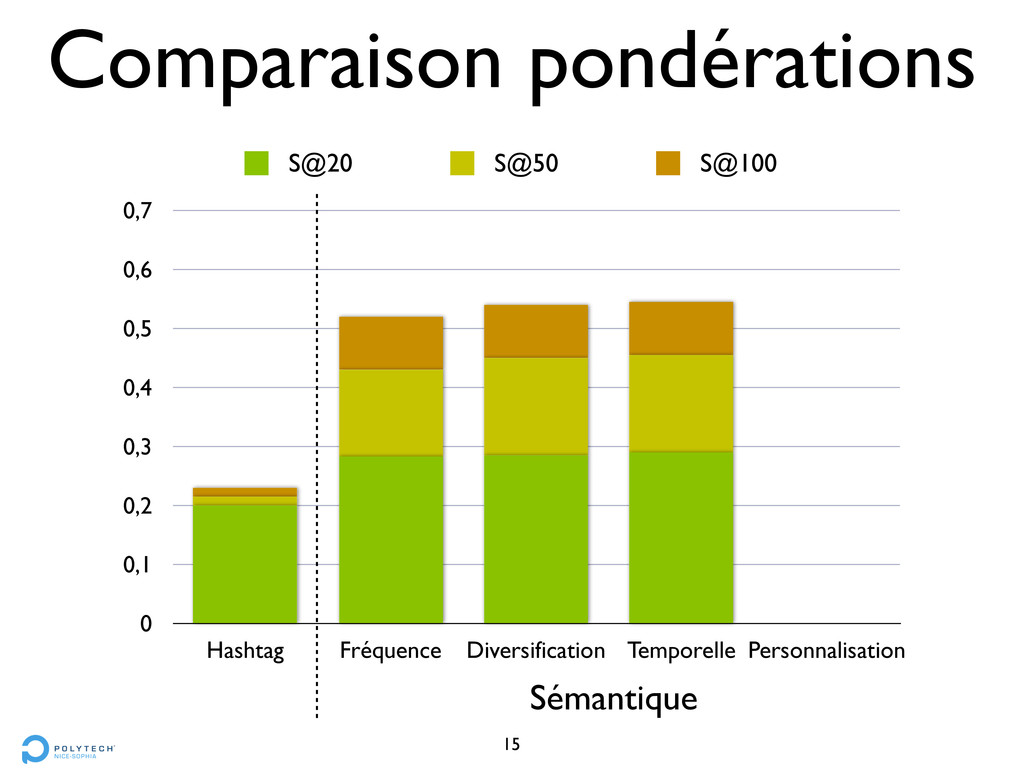
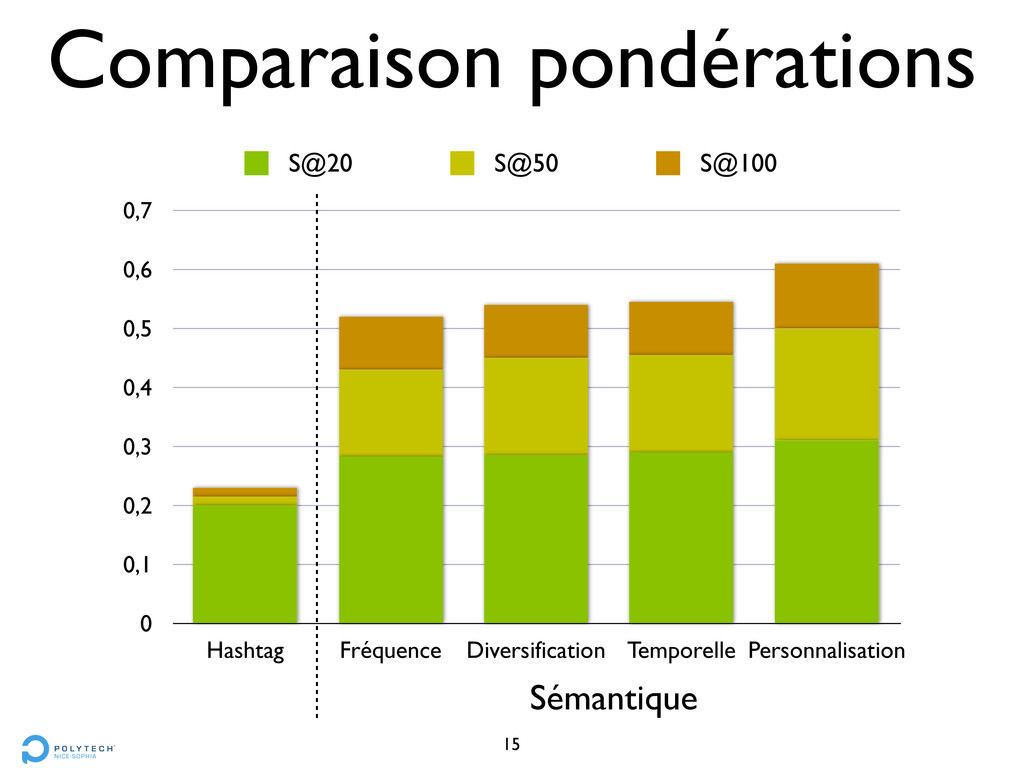
• compter le nombre d’occurrences d’un CFV • Méthode 2 : Personnalisation • créer un profil d’utilisateur à partir des tweets publiés • un CFV publié = 1 point
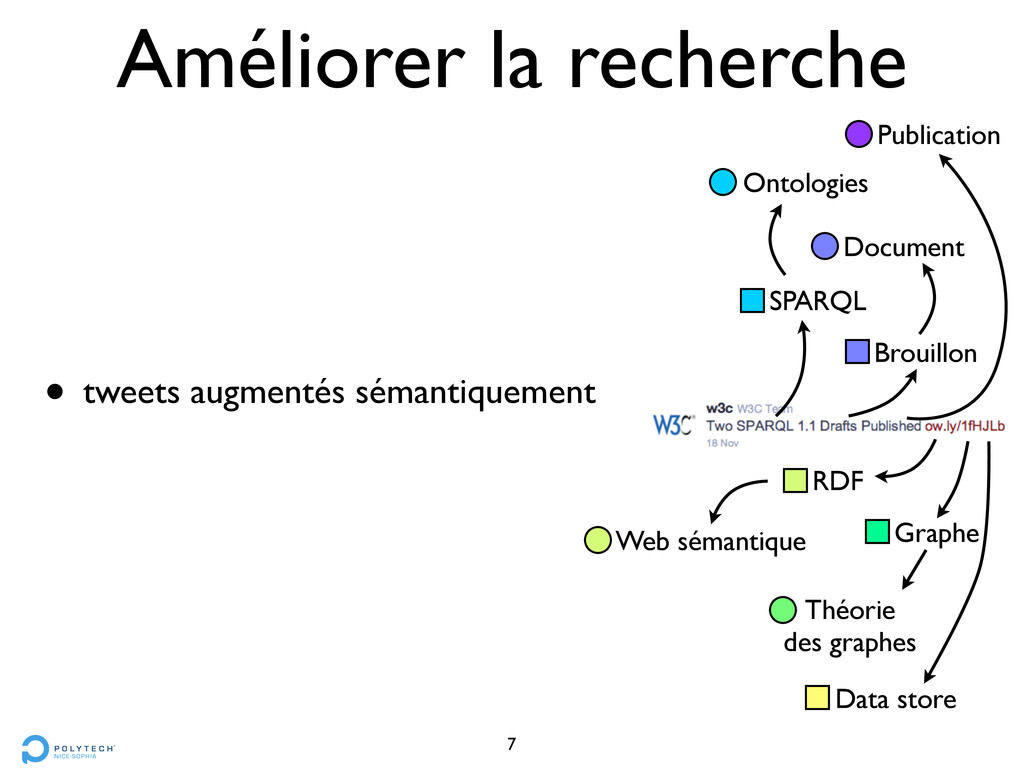
choisir les CFV qui correspondent au plus grand nombre de tweets • éviter les tweets déjà “utilisés” • Méthode 4 : Sensibilité temporelle • pondérer les CFV selon l’ancienneté des tweets
choisir les CFV qui correspondent au plus grand nombre de tweets • éviter les tweets déjà “utilisés” • Méthode 4 : Sensibilité temporelle • pondérer les CFV selon l’ancienneté des tweets • plus récent = mieux noté
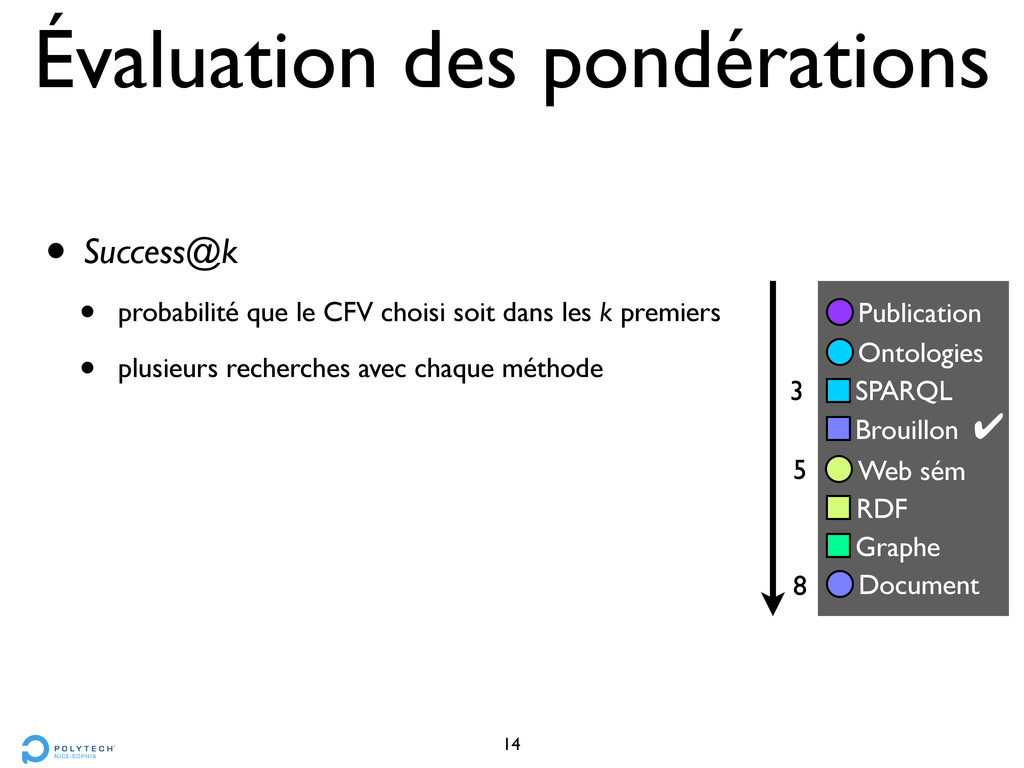
choisi soit dans les k premiers • plusieurs recherches avec chaque méthode 14 SPARQL Document Brouillon Ontologies Publication RDF Graphe Web sém 5 8 ! 3
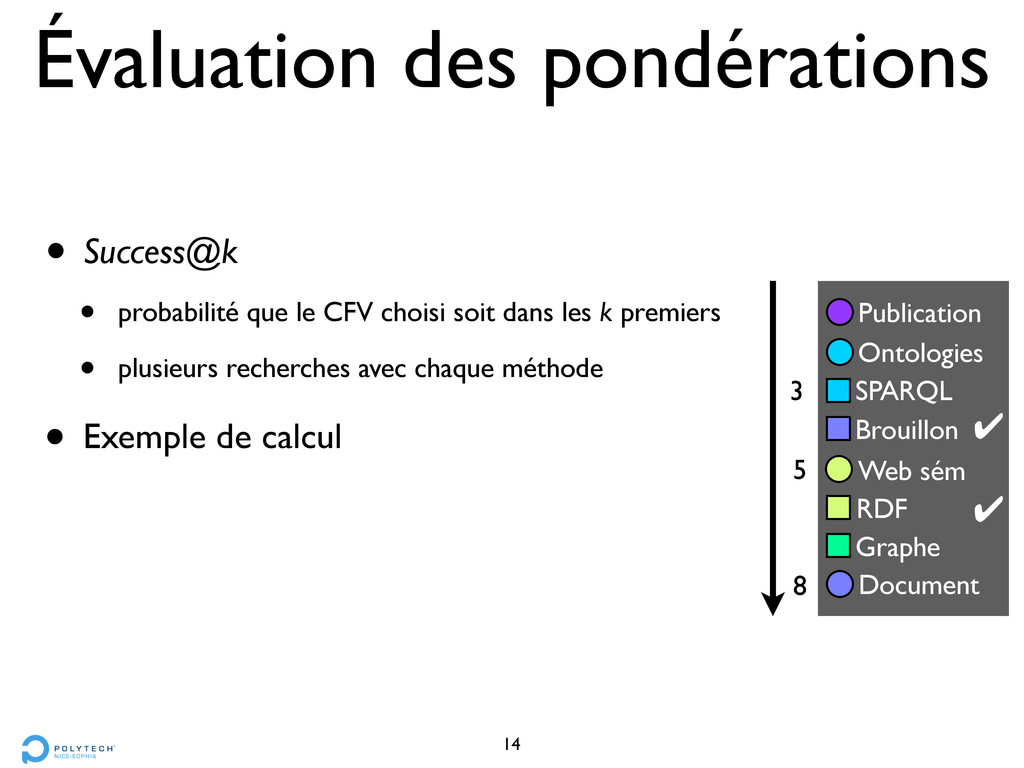
choisi soit dans les k premiers • plusieurs recherches avec chaque méthode • Exemple de calcul 14 SPARQL Document Brouillon Ontologies Publication RDF Graphe Web sém ! 5 8 ! 3
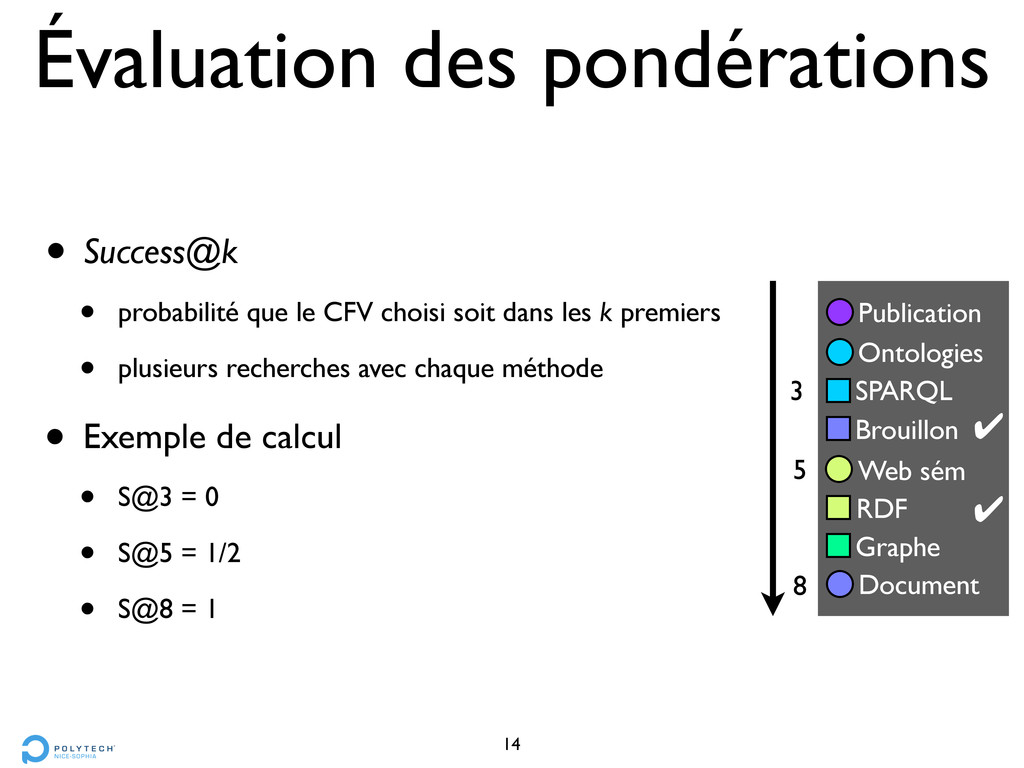
choisi soit dans les k premiers • plusieurs recherches avec chaque méthode • Exemple de calcul • S@3 = 0 • S@5 = 1/2 • S@8 = 1 14 SPARQL Document Brouillon Ontologies Publication RDF Graphe Web sém ! 5 8 ! 3
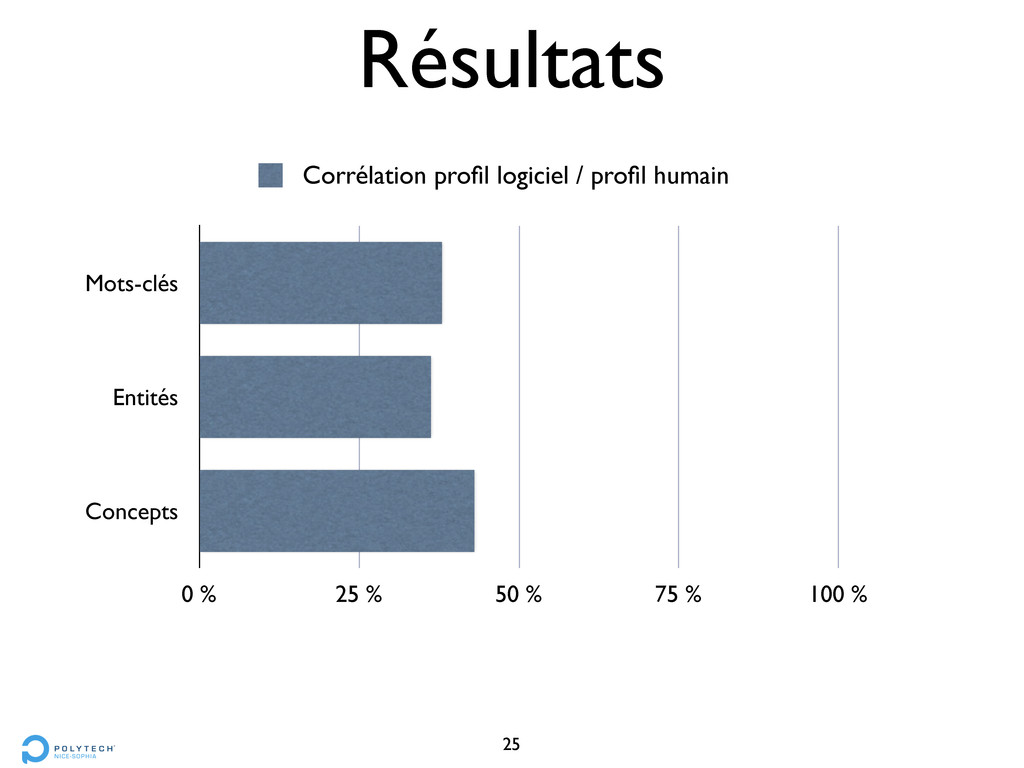
Polytech’ • membres (humains) évaluent la similarité de leurs pairs • questionnaires : 1 (très différents) à 10 (très similaires) • comparaison avec les similarités entre profils sémantiques
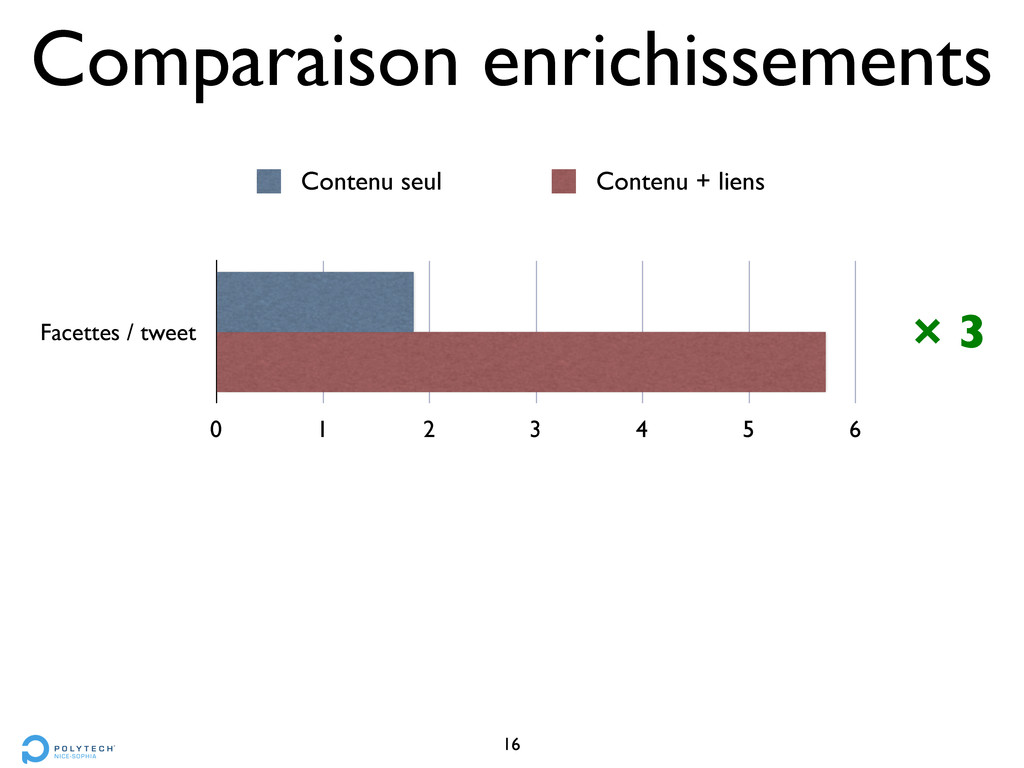
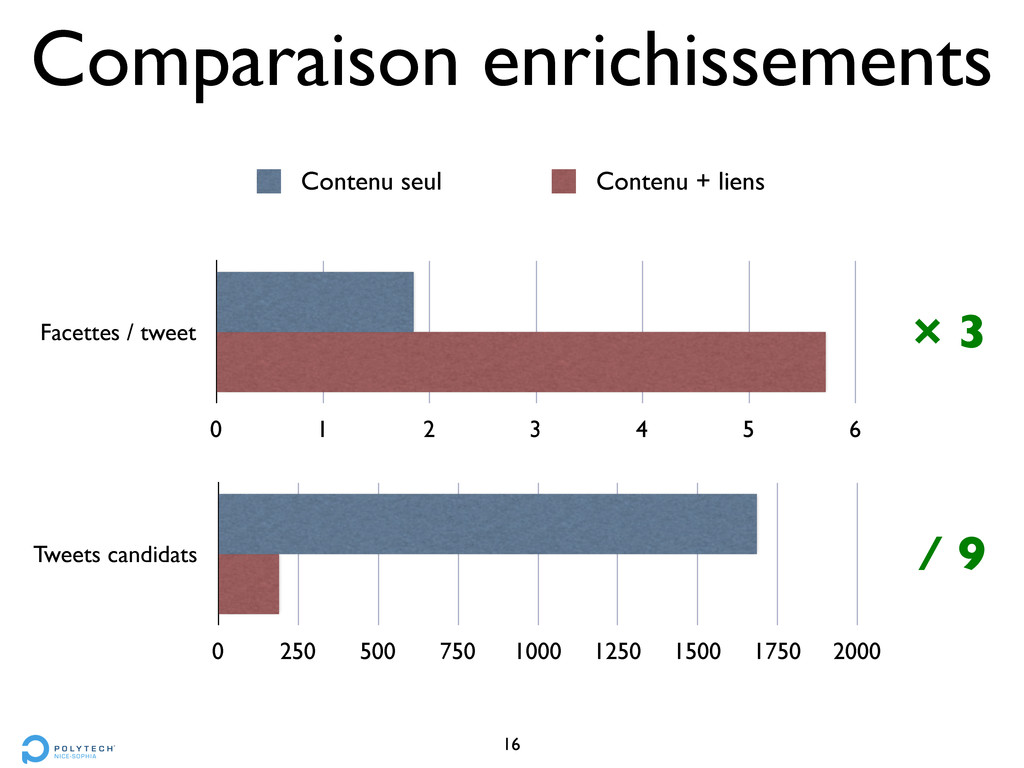
corpus > 30 millions tweets, 20000 utilisateurs • API citée non disponible • Twitter : “Annotations is still more concept then reality. Maybe some day we'll have more to say about them” 31
corpus > 30 millions tweets, 20000 utilisateurs • API citée non disponible • Twitter : “Annotations is still more concept then reality. Maybe some day we'll have more to say about them” • pas d’incidence sur l’expérimentation 31
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Calcul de corrélation 27 Similarité logicielle ! [0, 1] Similarité](https://files.speakerdeck.com/presentations/4f1459a8df3421001f00f3d8/slide_94.jpg){kind=link}
![Calcul de corrélation 27 Similarité logicielle ! [0, 1] Similarité](https://files.speakerdeck.com/presentations/4f1459a8df3421001f00f3d8/slide_95.jpg){kind=link}
![Calcul de corrélation 27 Similarité logicielle ! [0, 1] Similarité](https://files.speakerdeck.com/presentations/4f1459a8df3421001f00f3d8/slide_96.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}