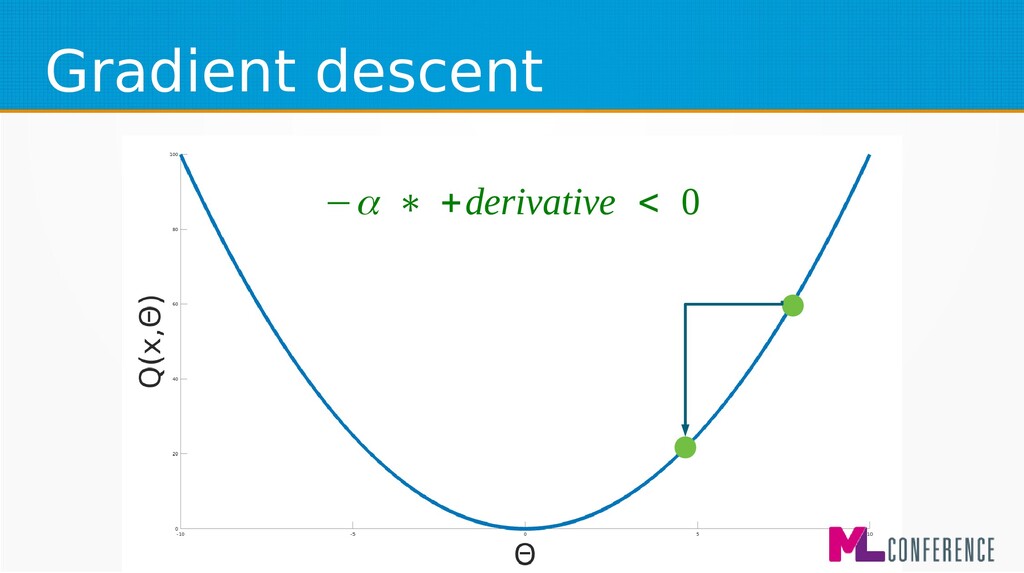
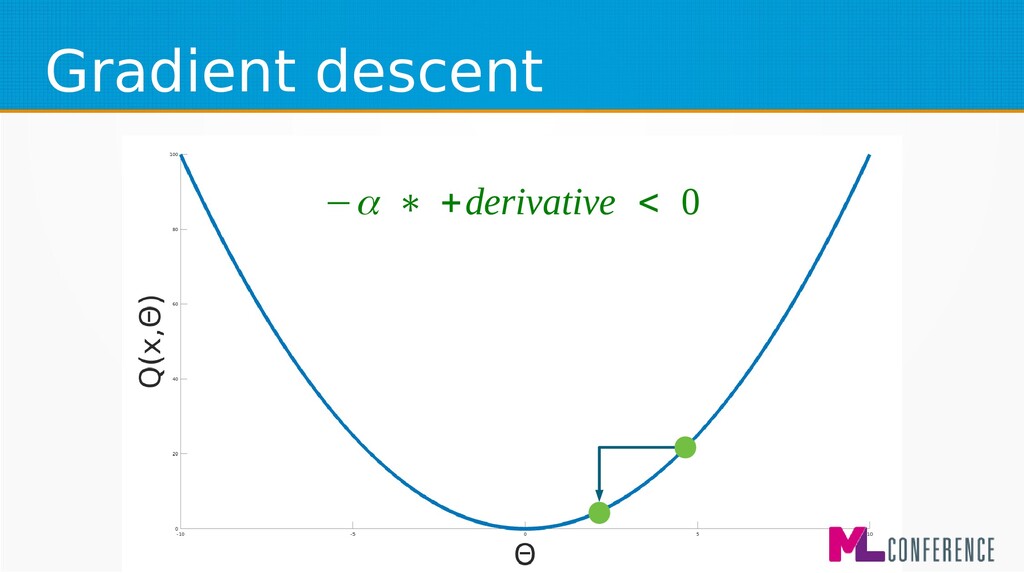
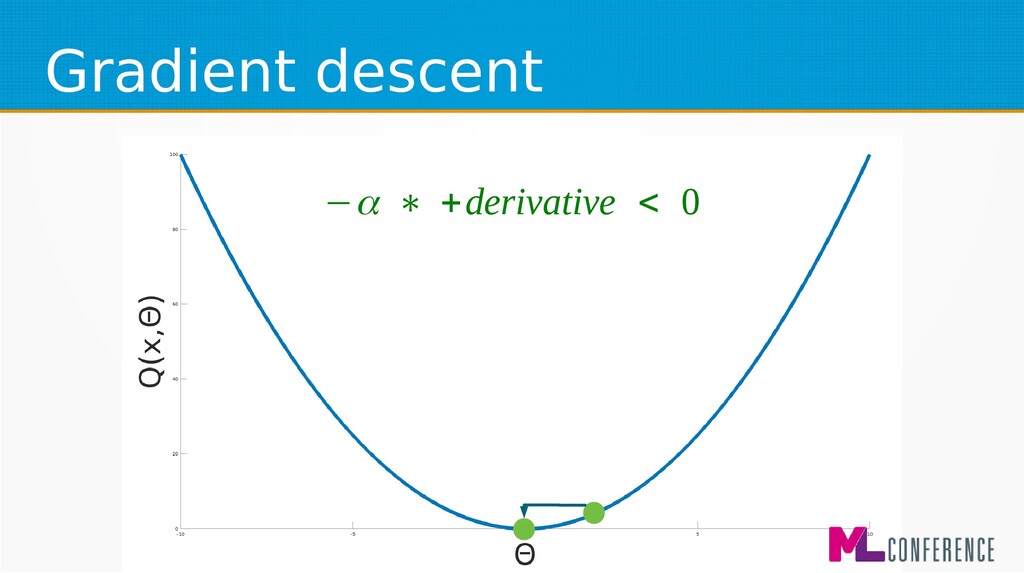
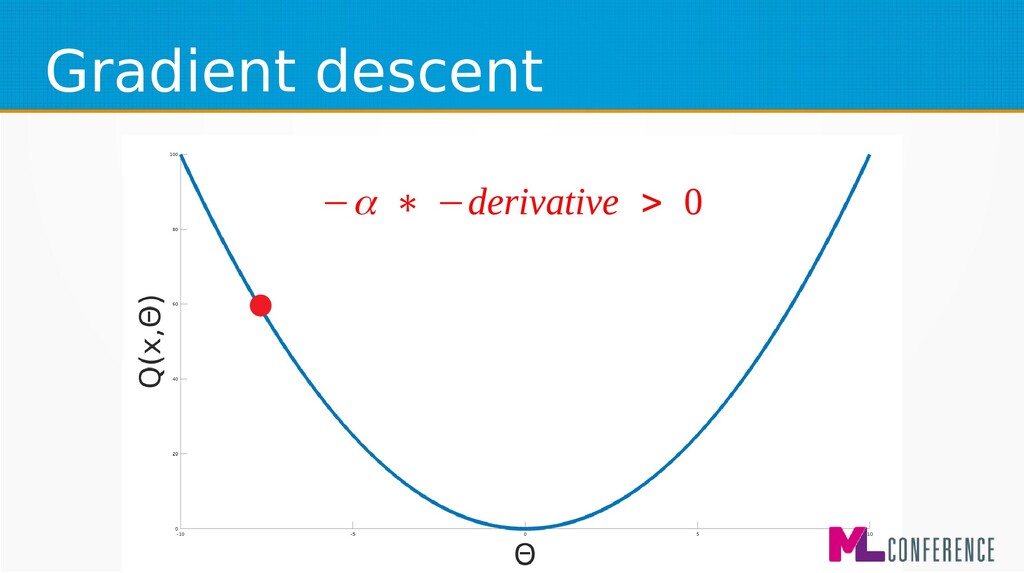
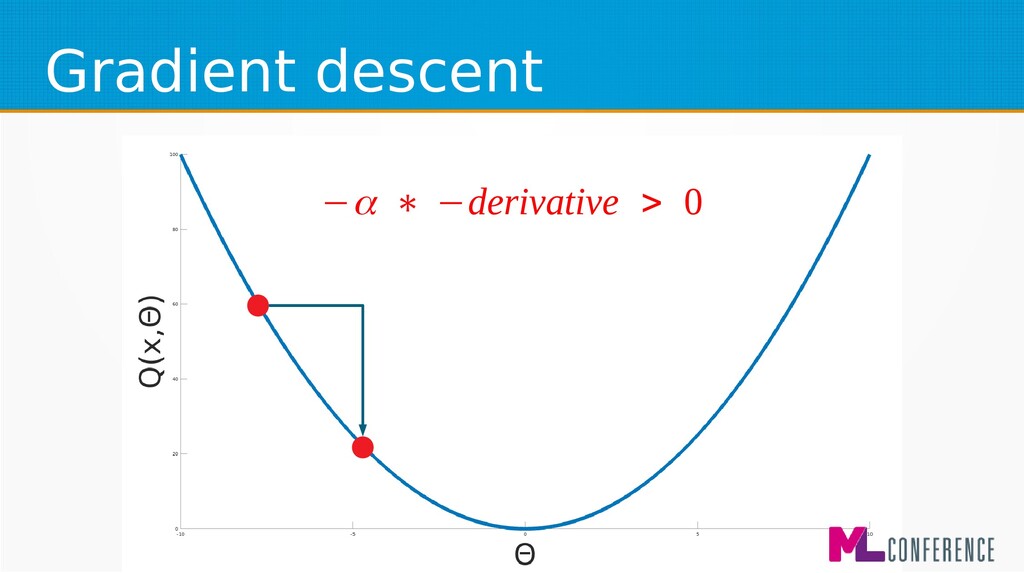
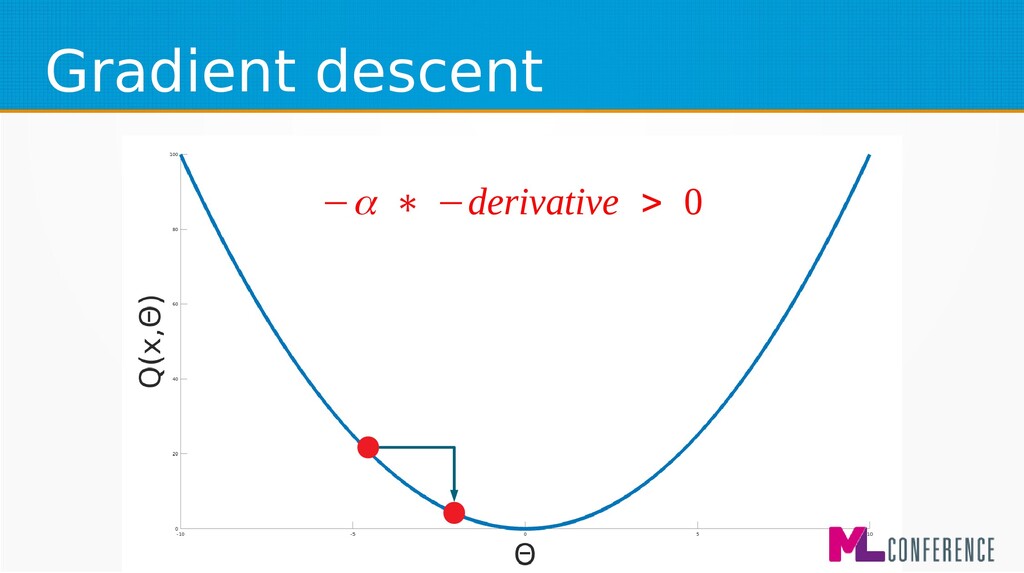
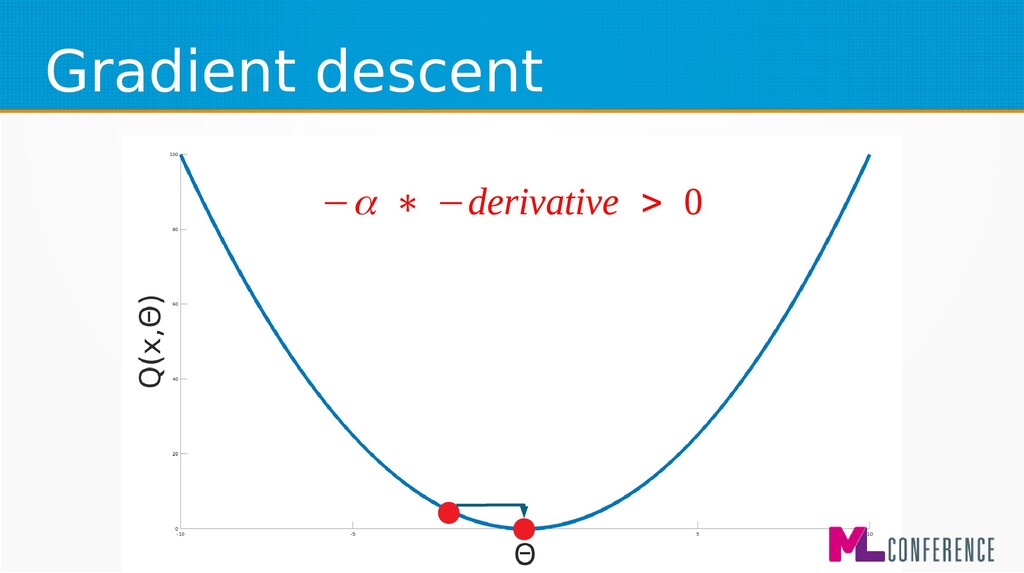
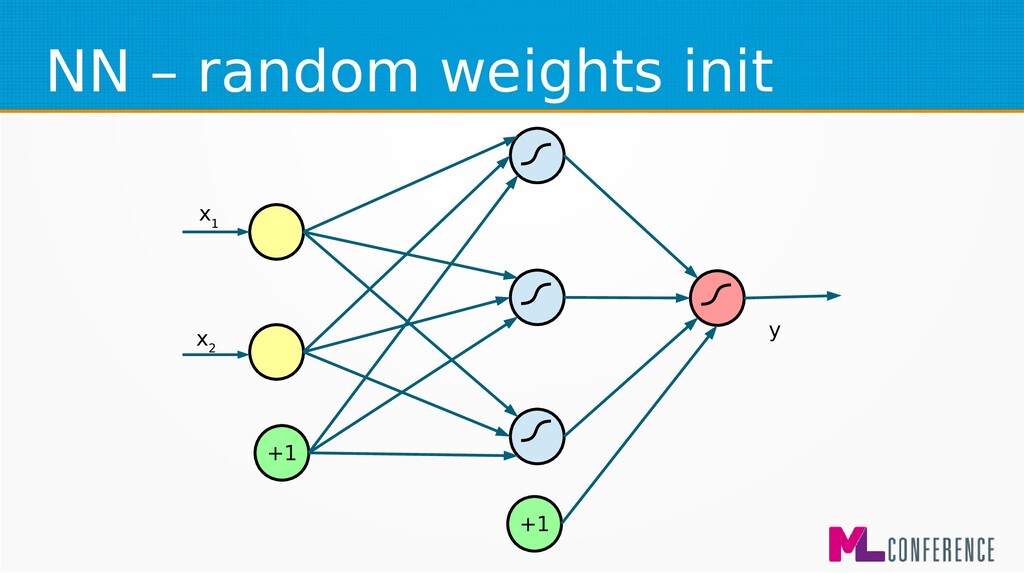
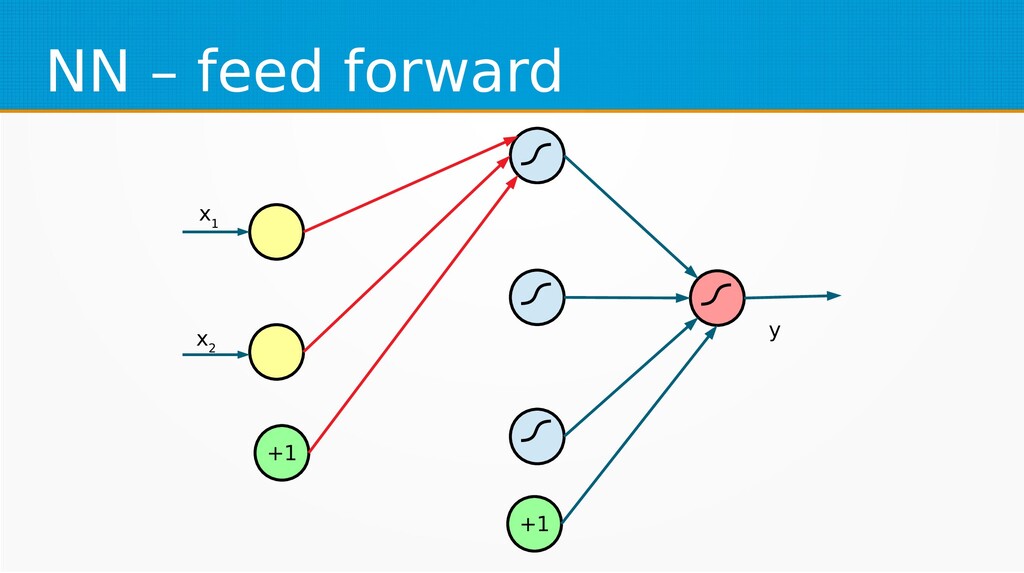
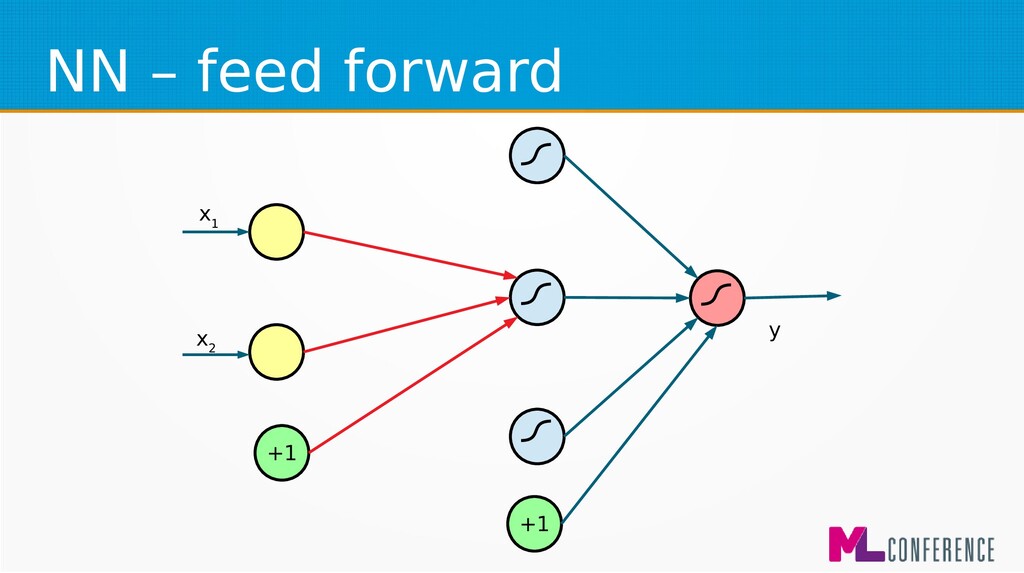
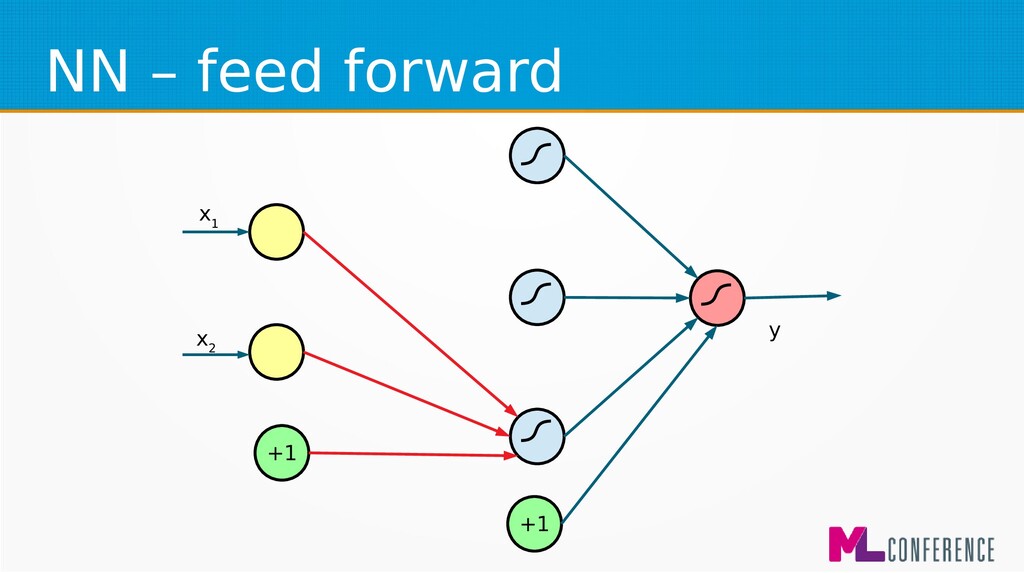
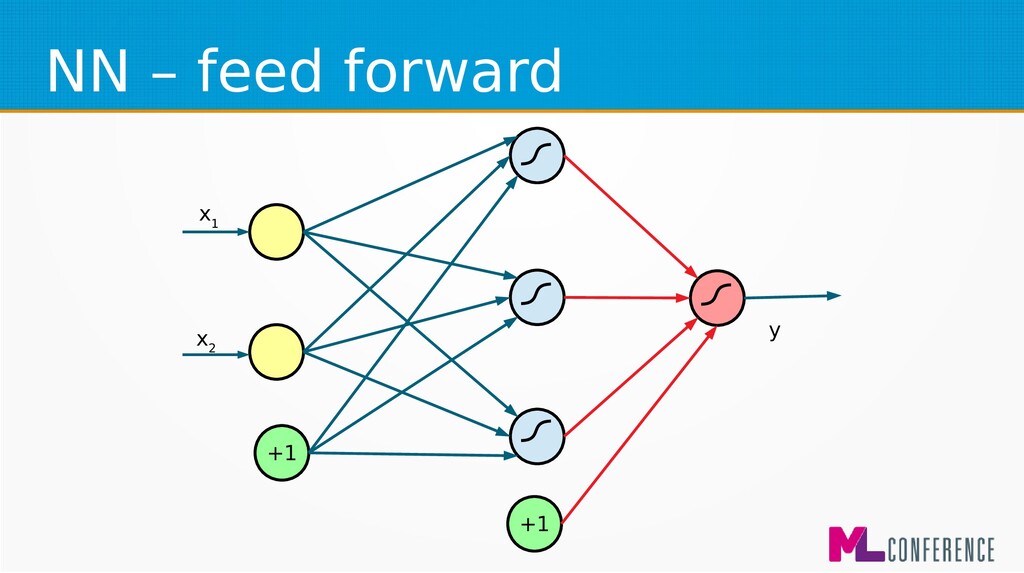
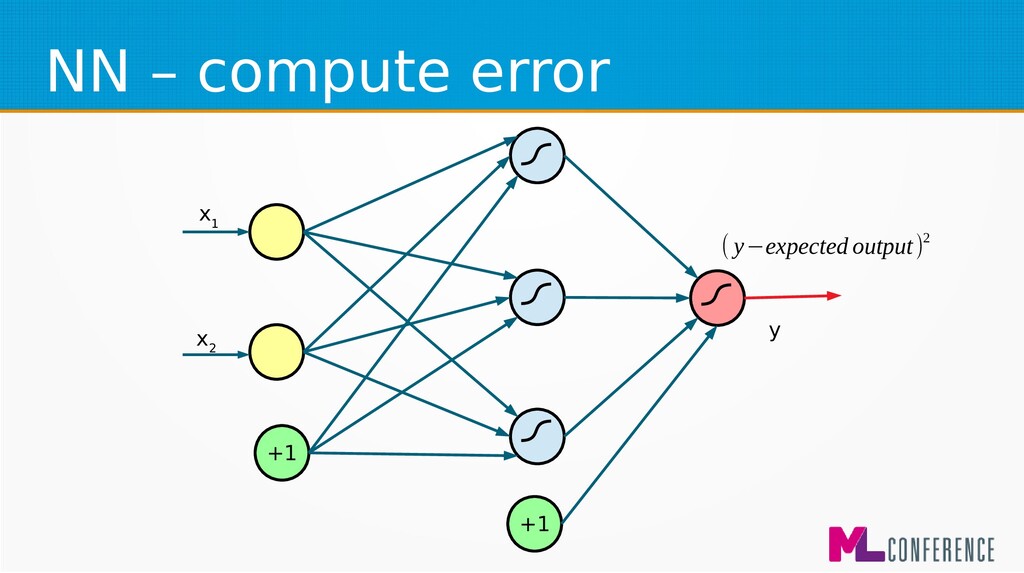
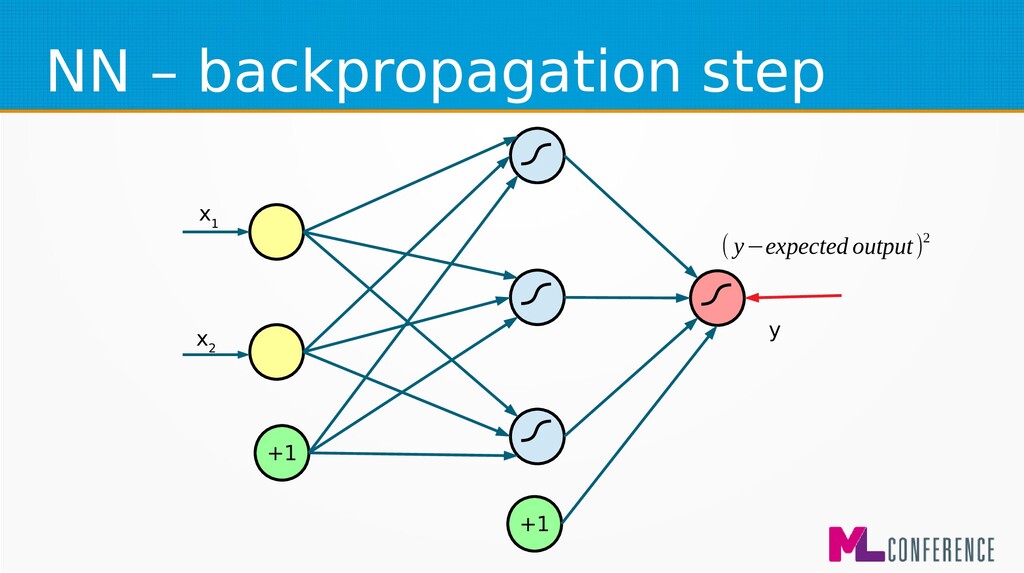
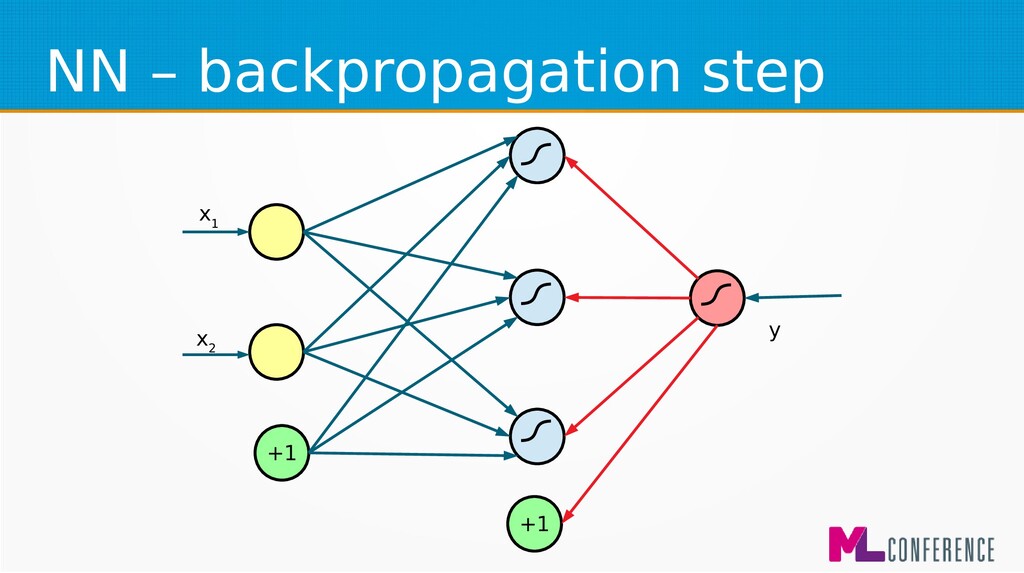
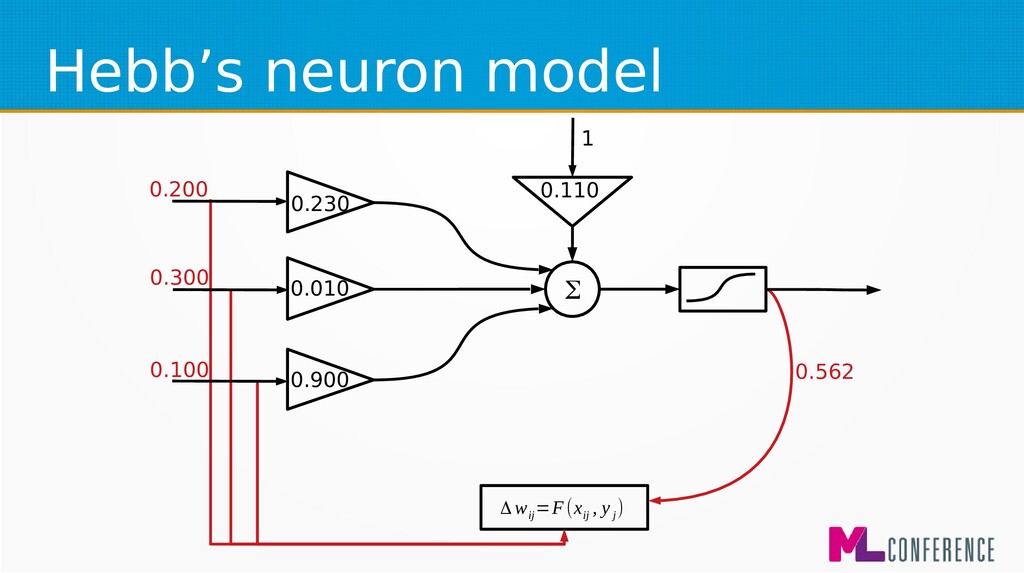
– Prepare data set consisting of examples & expected outputs – Present examples to your model – Check how it responds (model’s output values) – Adjust model’s params by comparing output values with expected output values
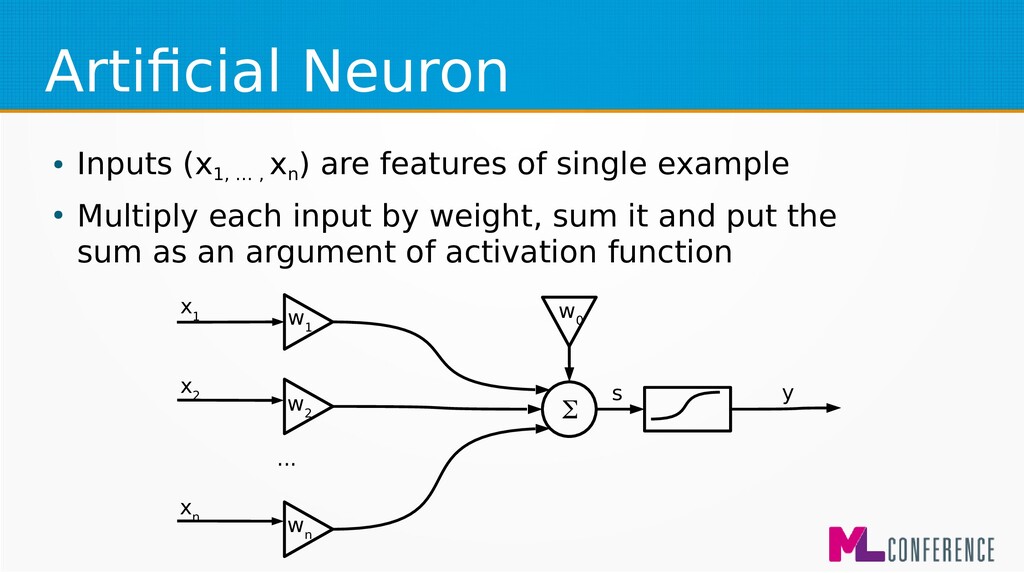
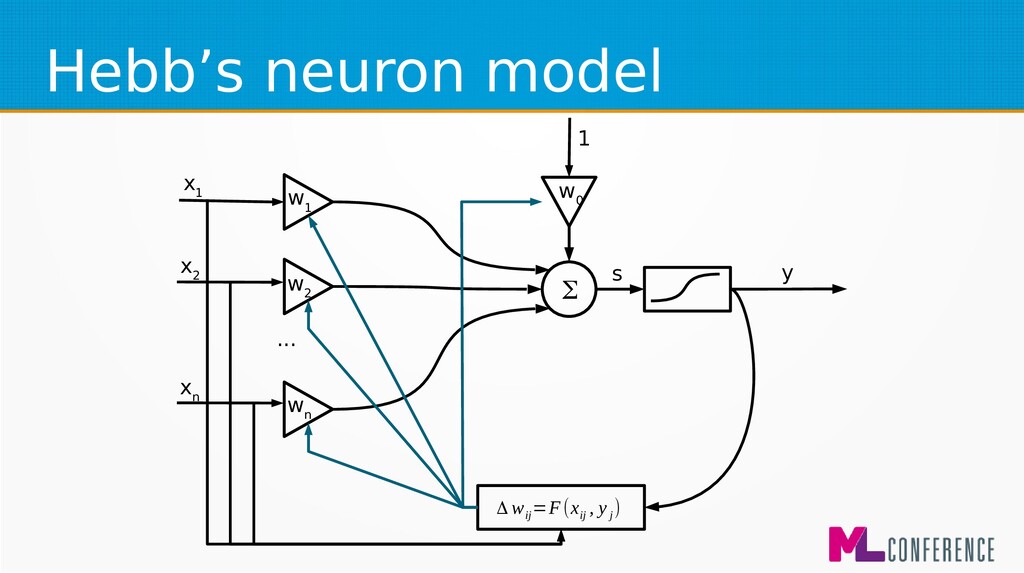
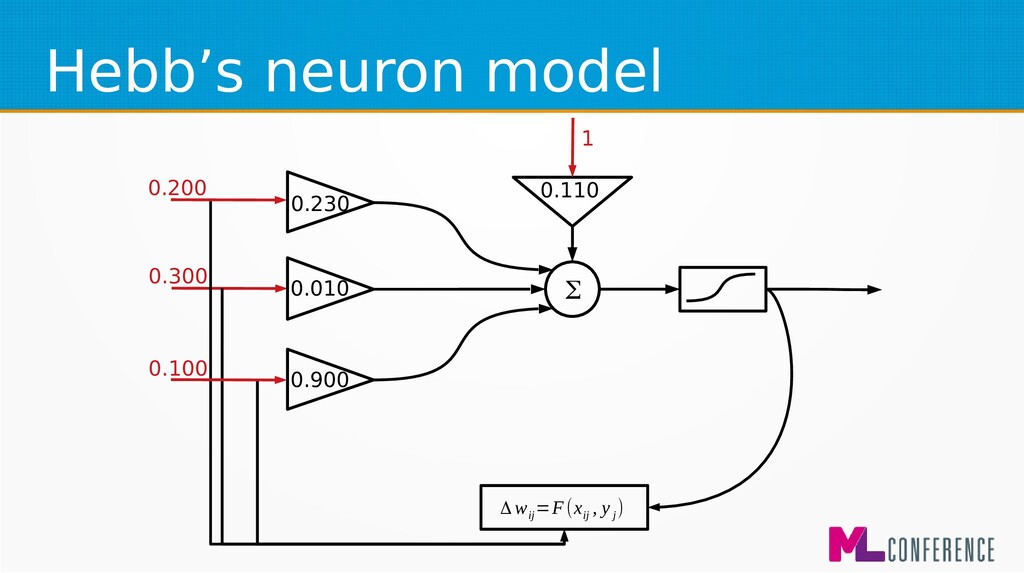
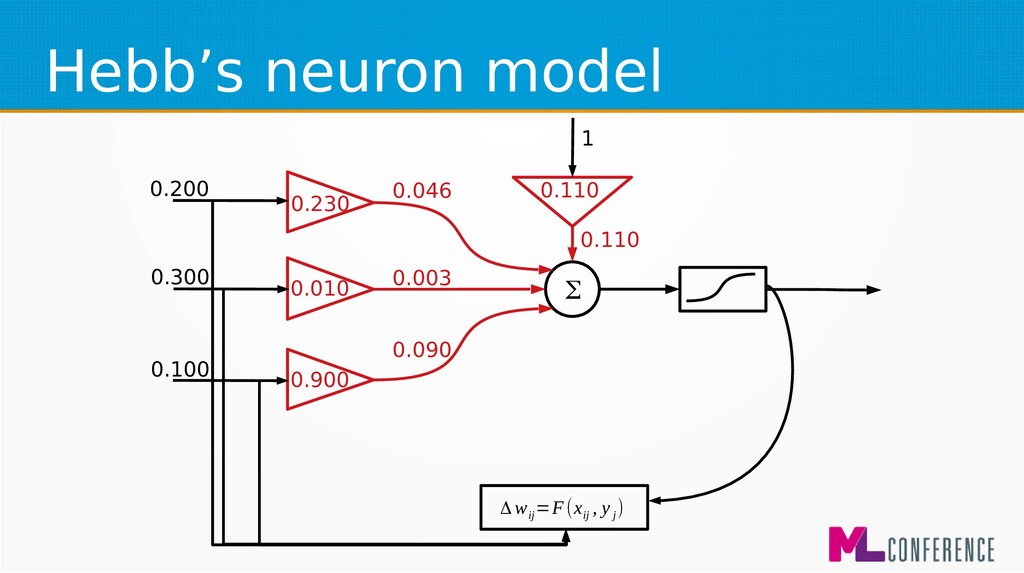
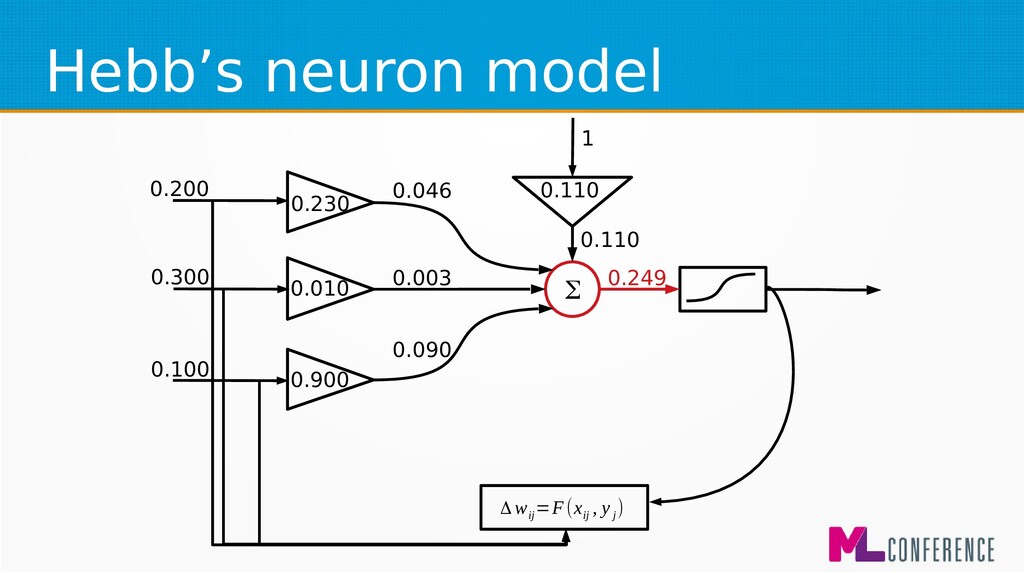
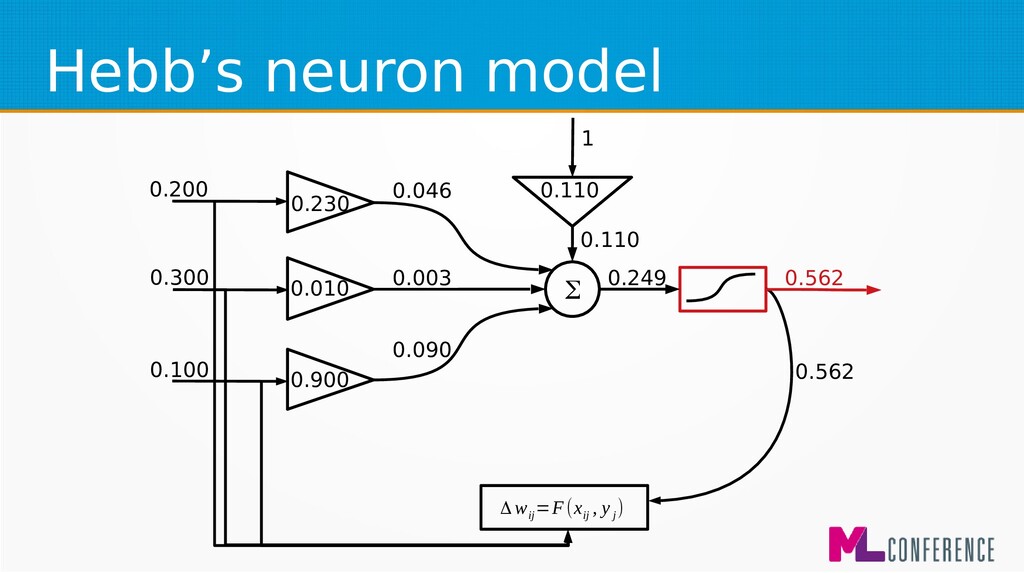
) are features of single example • Multiply each input by weight, sum it and put the sum as an argument of activation function w 1 w 2 w n w 0 Σ x 1 x 2 x n ... s y
for beginners and biological simulations :) • Simple Hebbian learning algorithm Δ w ij =η⋅x ij ⋅y i Δ w ij −change of j weight of ineuron η−learningcoefficient x ij − jinput of ineuron y i −output of i neuron
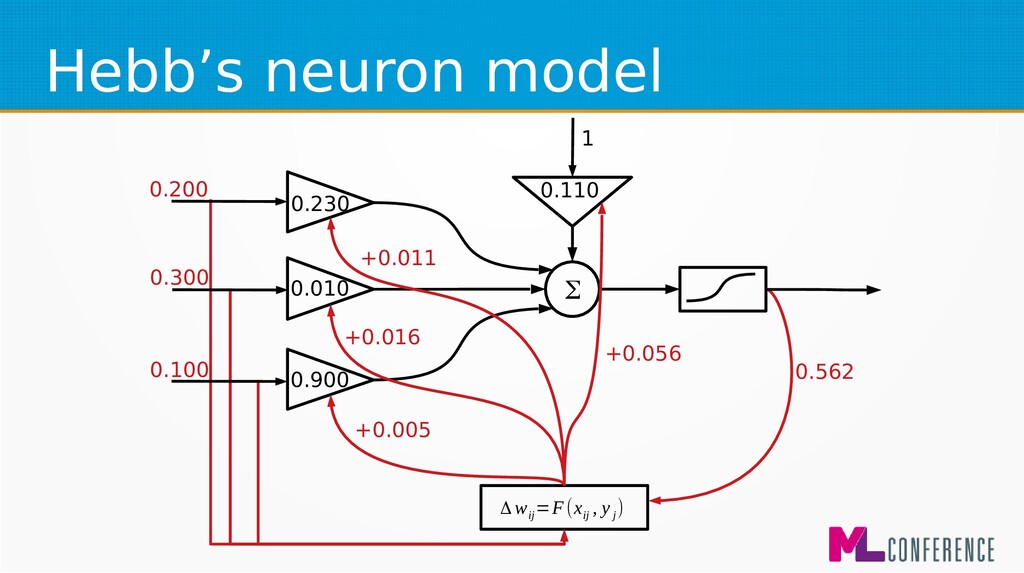
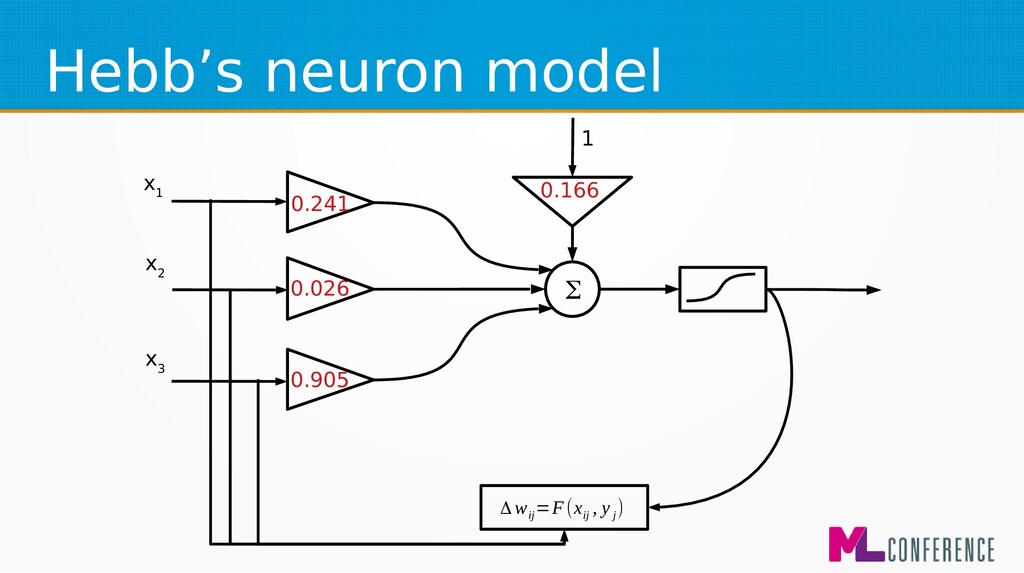
for beginners and biological simulations :) • Generalised Hebbian learning algorithm Δ w ij =F(x ij , y j ) Δ w ij −change of j weight of ineuron η−learningcoefficient x ij − jinput of ineuron y i −output of i neuron
in weights vector. • Instead of checking the reaction to input - you check distance between both vectors. • Ideally – each neuron specializes in one class generalization. • Two main strategies: – Winner Takes All (WTA) – Winner Takes Most (WTM)
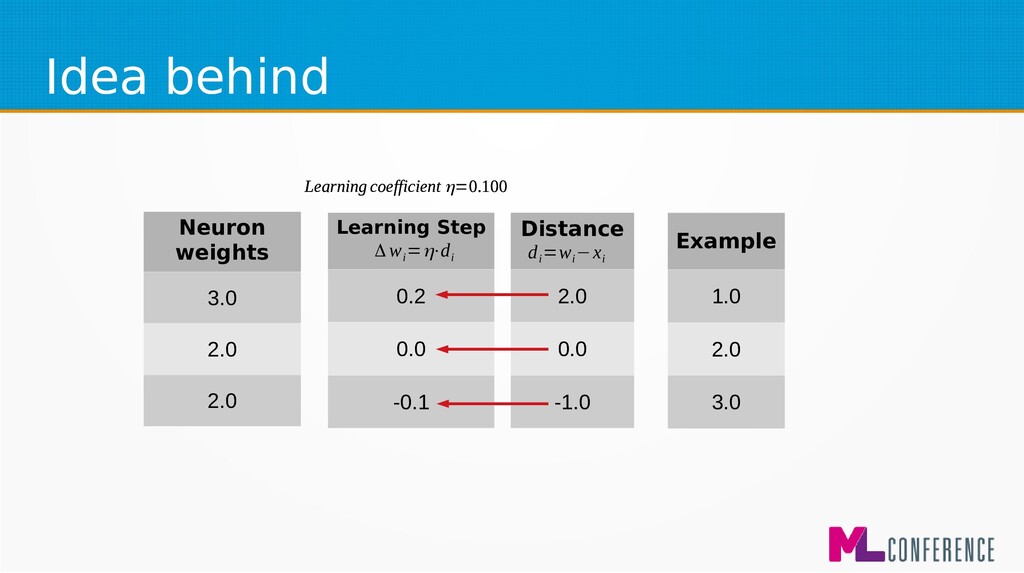
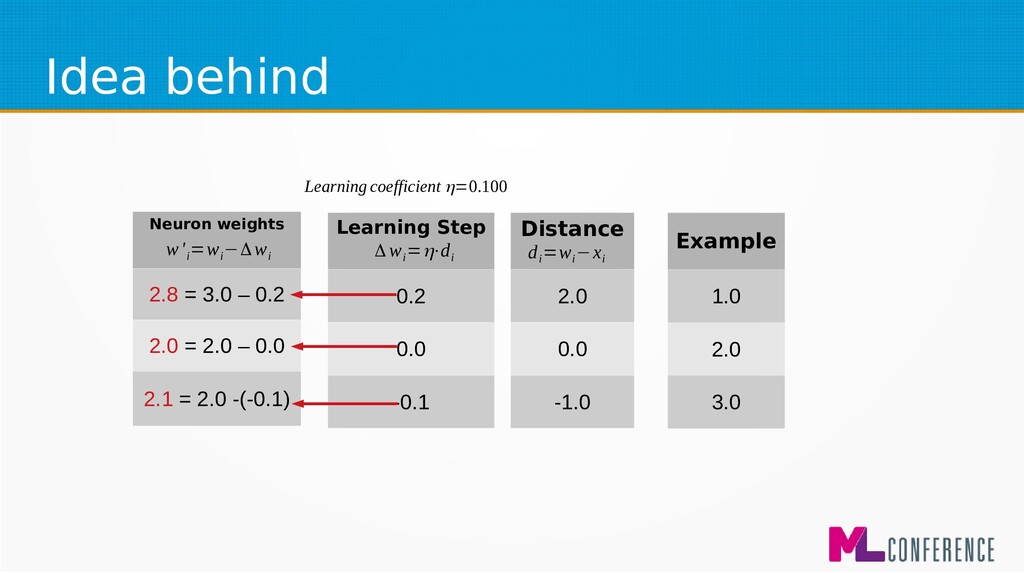
= 3.0 – 0.2 2.0 = 2.0 – 0.0 2.1 = 2.0 -(-0.1) Exam ple 1.0 2.0 3.0 d i =w i −x i Learning coefficient η=0.100 Learning Step 0.2 0.0 -0.1 w' i =w i −Δw i Δ w i =η⋅d i Example 1.0 2.0 3.0 Learning Step 0.2 0.0 -0.1 Δ w i =η⋅d i Distance 2.0 0.0 -1.0 d i =w i −x i
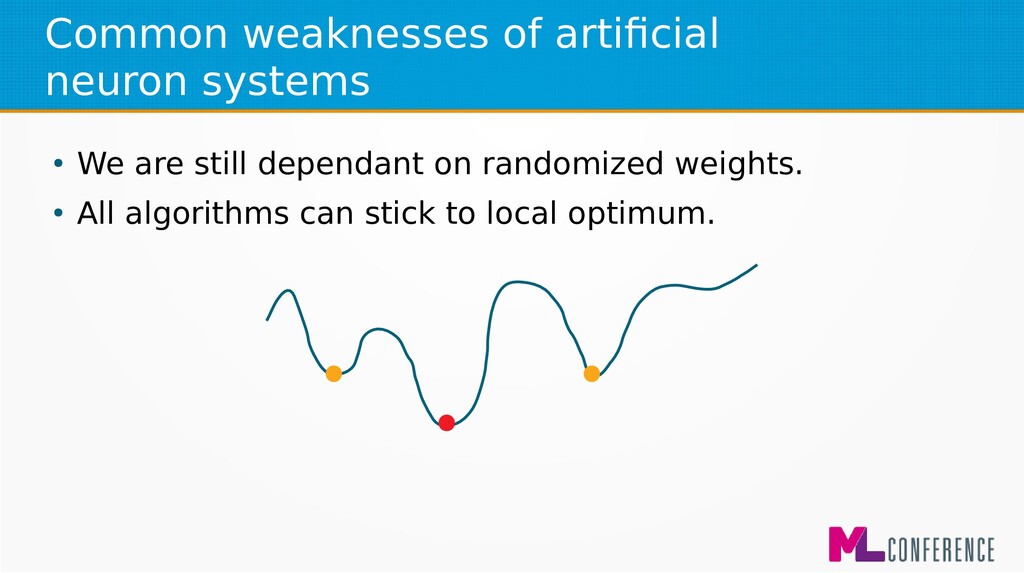
if teaching examples are evenly distributed in solution space. • WTM – works best if weights’ vectors are evenly distributed in solution space. • Still can stick to local optimum.
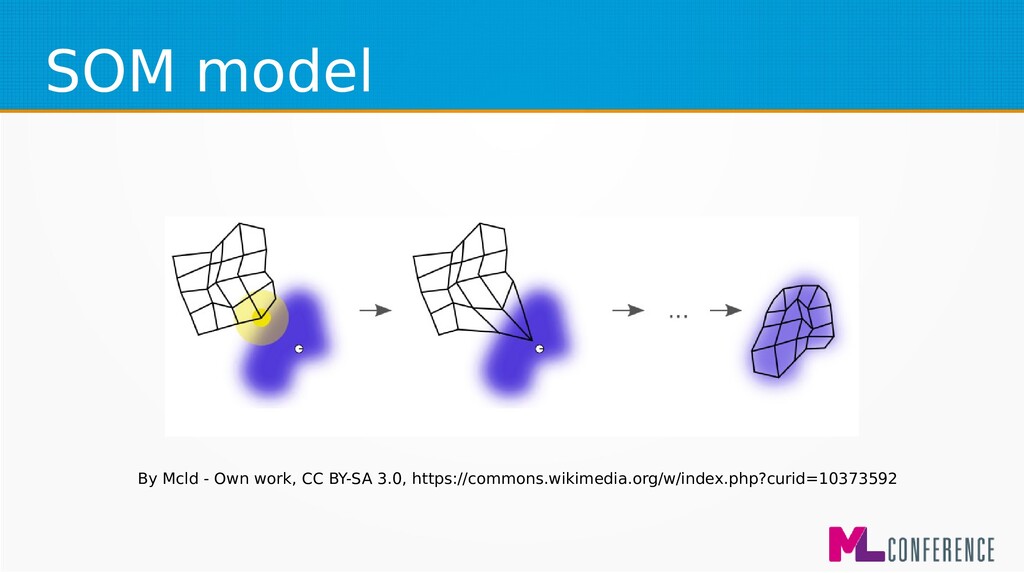
concurrency algorithm. • It teaches groups of neurons with WTM alghoritm • Special features: – Neurons are organised in a grid – Nevertheless – they are treated as a single layer
, s)⋅η(s)⋅(I j (s)−w ij (s)) s−epochnumber k best −best neuron w ij (s)− j weight of ineuron Θ(k best ,i,s)−neighbourhood function η(s)−learning coefficient for sepoch I j (s)− jchunk of example for s epoch
• Math for Machine Learning - Amazon Training and Certification • Linear and Logistic Regression - Amazon Training and Certification • Grus J., Data Science from Scratch: First Principles with Python • Patterson J., Gibson A., Deep Learning: A Practitioner's Approach • Trask A., Grokking Deep Learning • Stroud K. A., Booth D. J, Engineering Mathematics • https://github.com/massie/octave-nn- neural network Octave implementation • https://www.desmos.com/calculator/dnzfajfpym - Nanananana … Batman equation ;) • https://xkcd.com/605/ - extrapolating ;) • http://dilbert.com/strip/2013-02-02 - Dilbert & Machine Learning
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}