latent diffusion models." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022. [2] Gal, Rinon, et al. "An image is worth one word: Personalizing text-to-image generation using textual inversion." arXiv preprint arXiv:2208.01618 (2022). [3] Ruiz, Nataniel, et al. "Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation." arXiv preprint arXiv:2208.12242 (2022). [4] Kawar, Bahjat, et al. "Imagic: Text-Based Real Image Editing with Diffusion Models." arXiv preprint arXiv:2210.09276 (2022). [5] Ho, Jonathan, Ajay Jain, and Pieter Abbeel. "Denoising diffusion probabilistic models." Advances in Neural Information Processing Systems 33 (2020): 6840-6851. [6] Quasi-Taylor Samplers for Diffusion Generative Models based on Ideal Derivatives [7] CLIP: Connecting Text and Images https://openai.com/blog/clip/
{kind=link}
{kind=link}
{kind=link}
![今日のお話の対象者 機械学習の中身が少しわかる人向けの資料です。 機械学習なんにもわからない!という方は雰囲気だけでも掴んでいただけたらと思います。 事前知識として文章から画像を生成するAI(text2image)についての比較的初学者向けの 解説資料を twitter で公開しているのでよかったら参考にしてみてください。 ←は技術書典で出した本の内容を無料公開したものなので本書も買ってくれると泣いて喜びます。 [リンク] Text-to-Image](https://files.speakerdeck.com/presentations/68e5f2e8413545168e4bc683870daab4/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
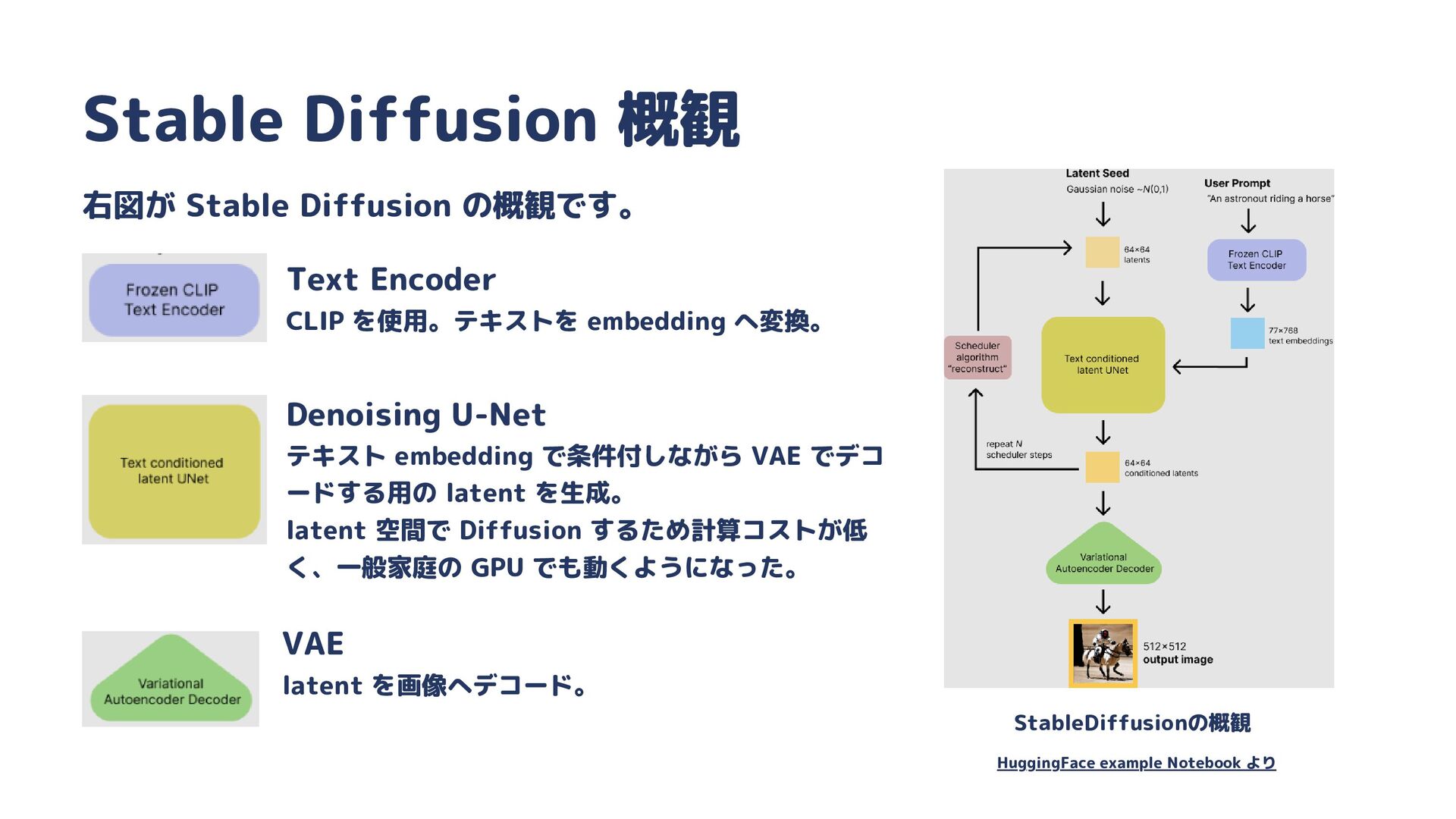{kind=link}
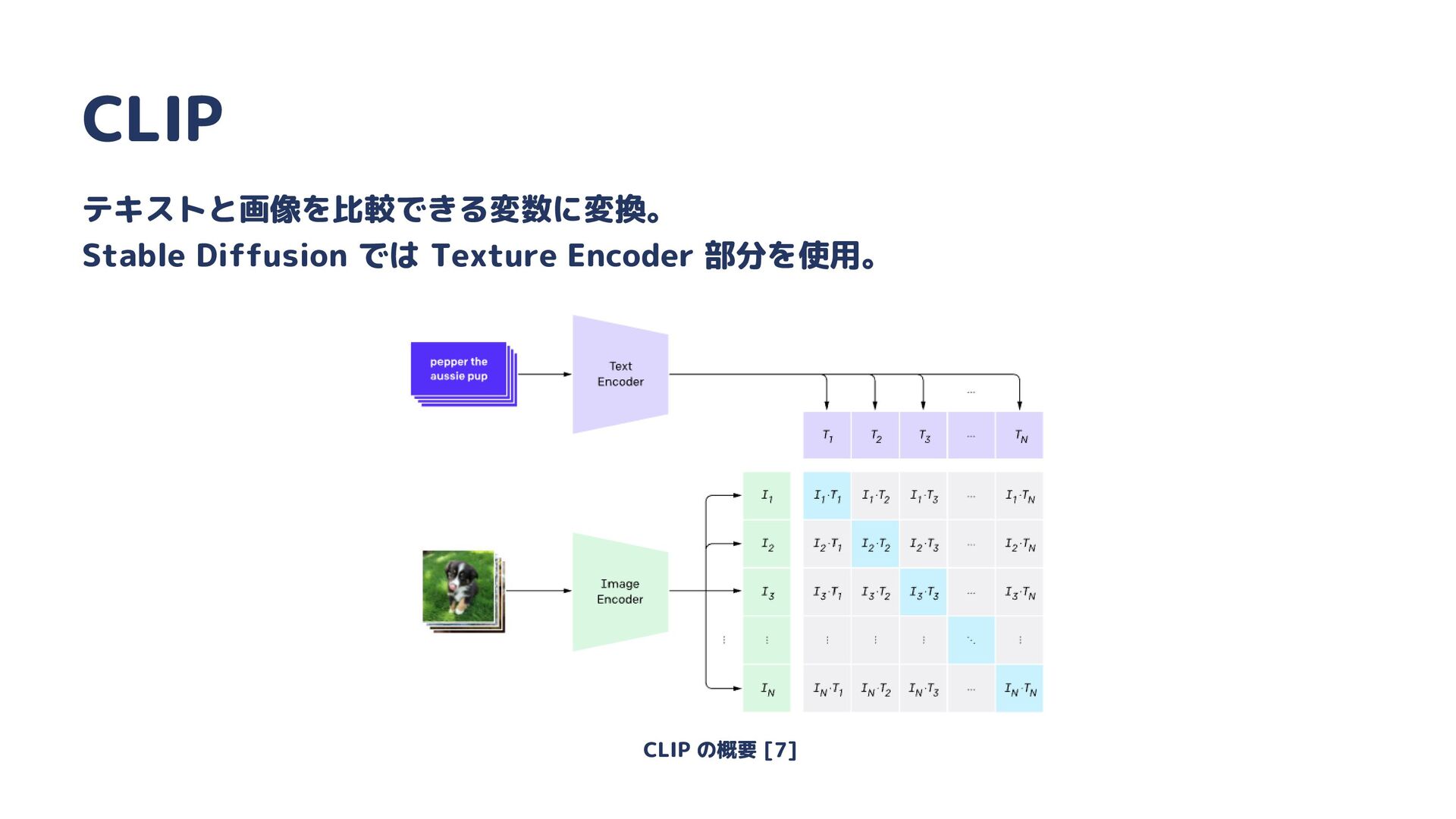{kind=link}
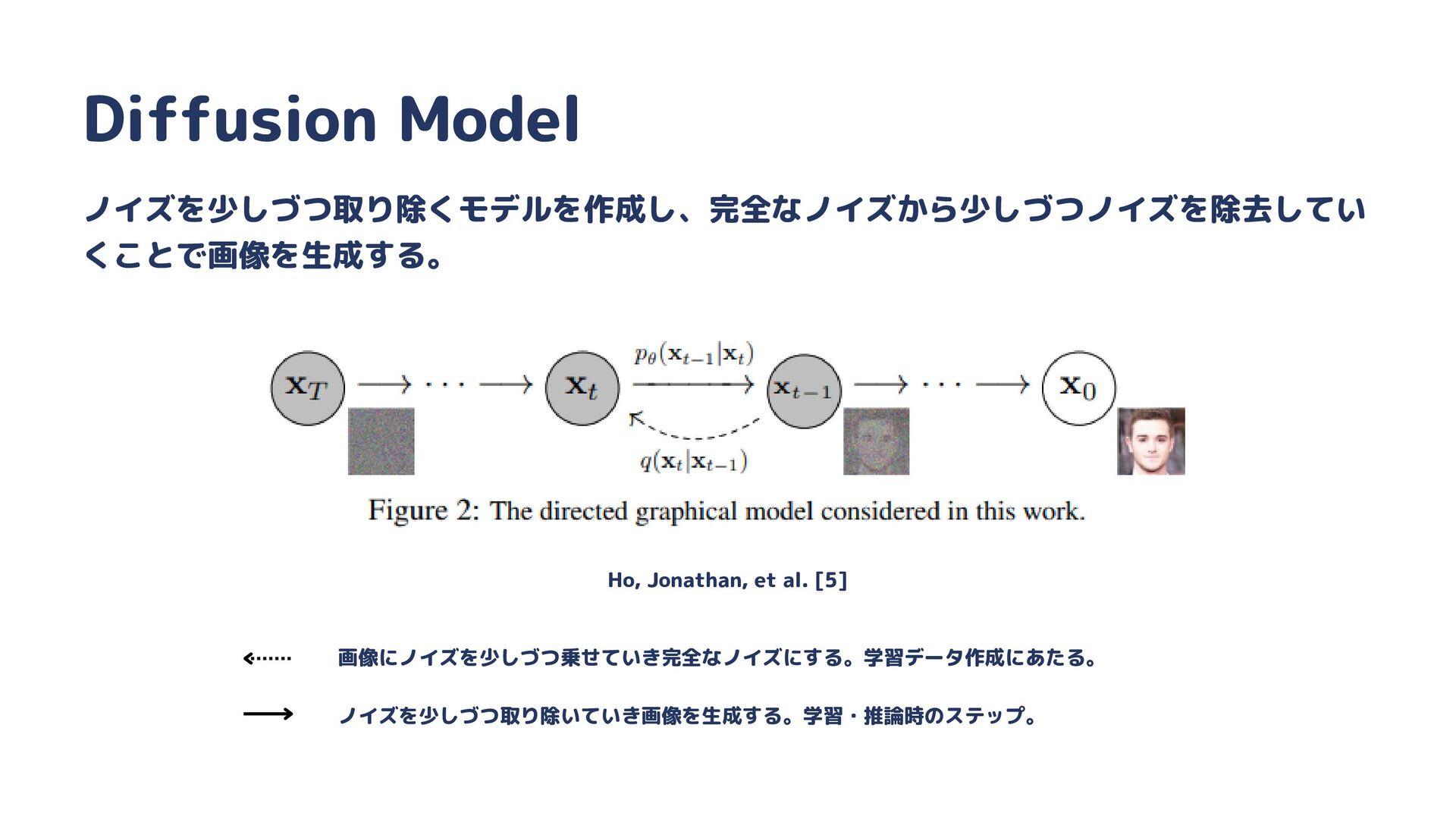{kind=link}
![Diffusion Modelの推論 推論時は完全なノイズから少しづつノイズを取り除いて画像を生成していく。 Hideyuki Tachibana, et al[6] より図一部引用](https://files.speakerdeck.com/presentations/68e5f2e8413545168e4bc683870daab4/slide_9.jpg){kind=link}
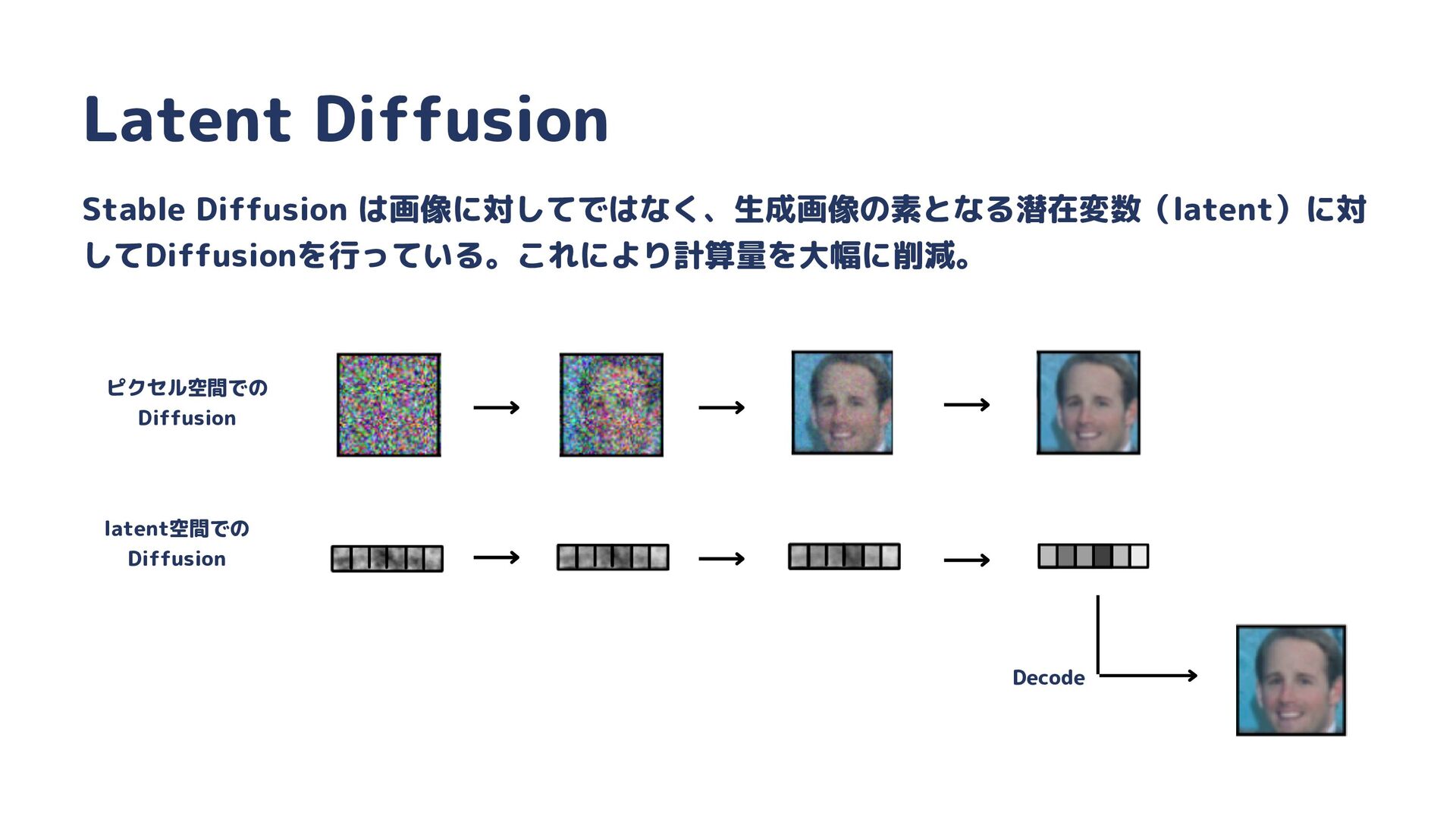{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Textual Inversion 3~5枚のラベルなし画像から特定の概念を学習させることが可能。 下記例では数枚の置物の画像を学習させて、絵画風、アイコン風などの指定したスタイルで 生成したり、置物をテーマにしたバッグを生成している。 Gal, Rinon, et al [2]](https://files.speakerdeck.com/presentations/68e5f2e8413545168e4bc683870daab4/slide_16.jpg){kind=link}
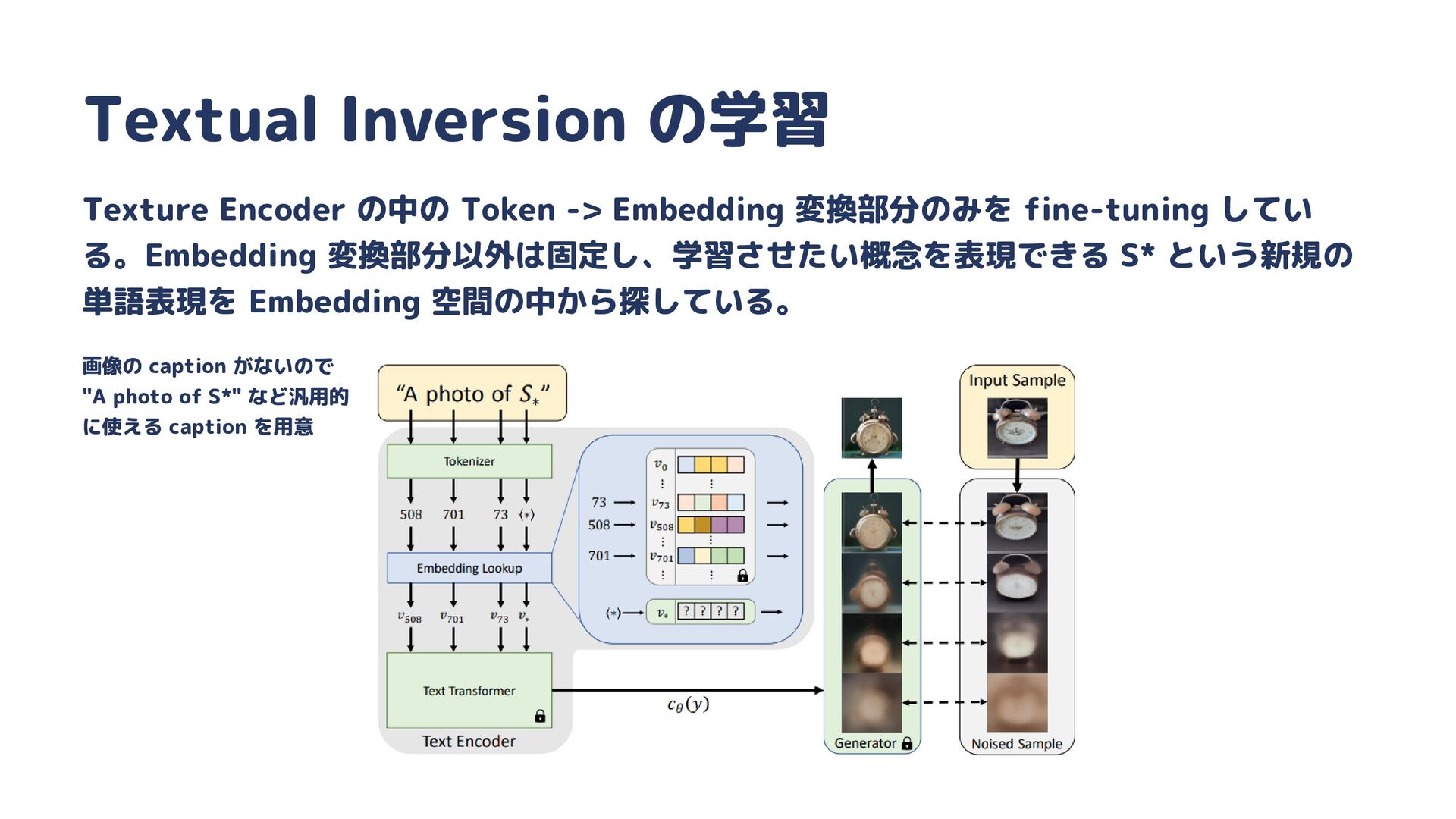{kind=link}
{kind=link}
{kind=link}
{kind=link}
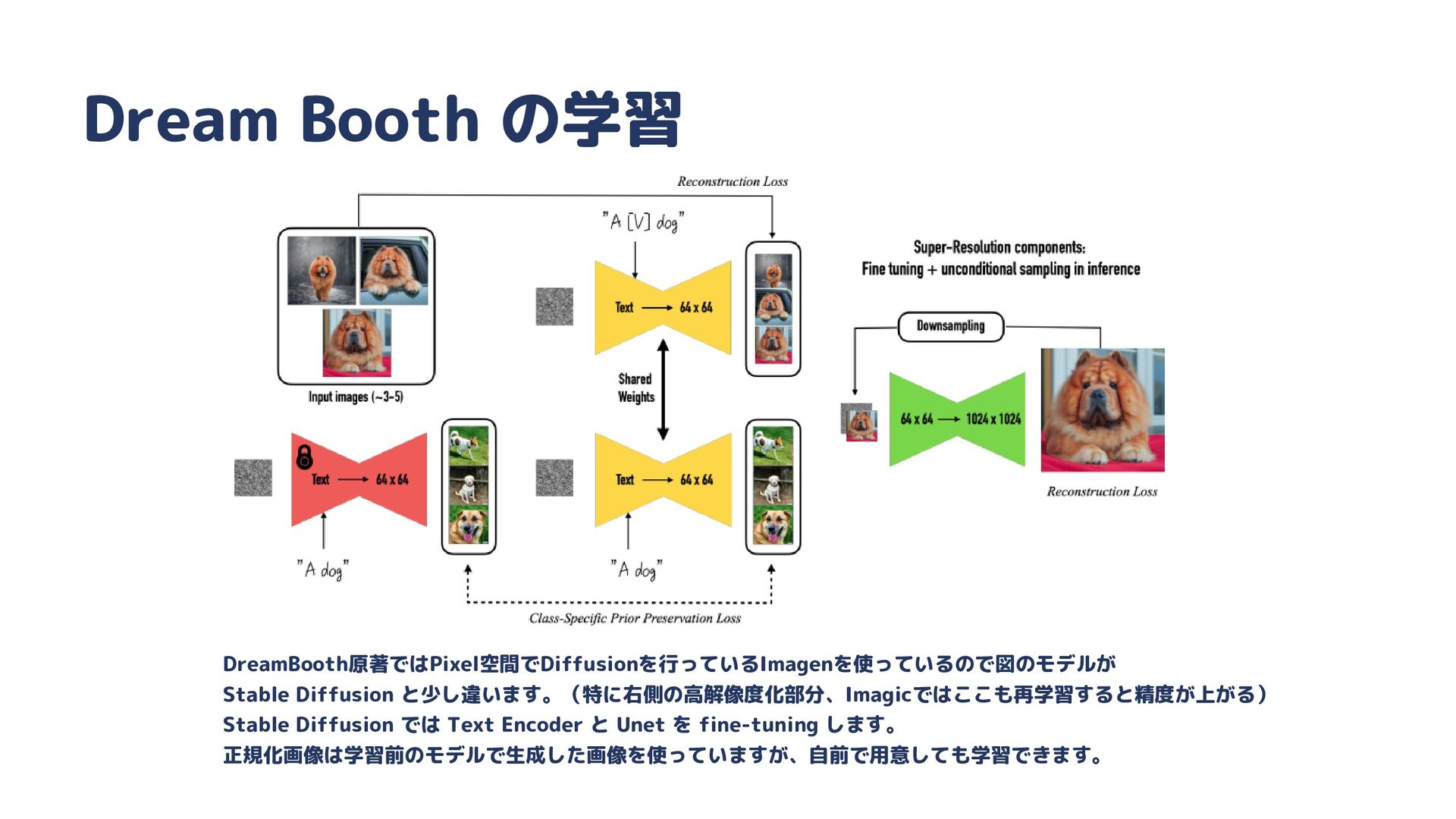{kind=link}
{kind=link}
![Imagic 1枚の画像に特化させて学習させることで、高精度に画像を編集することが可能。 入力画像を指定したテキストをもとに編集できる。 Kawar, Bahjat, et al [4]](https://files.speakerdeck.com/presentations/68e5f2e8413545168e4bc683870daab4/slide_23.jpg){kind=link}
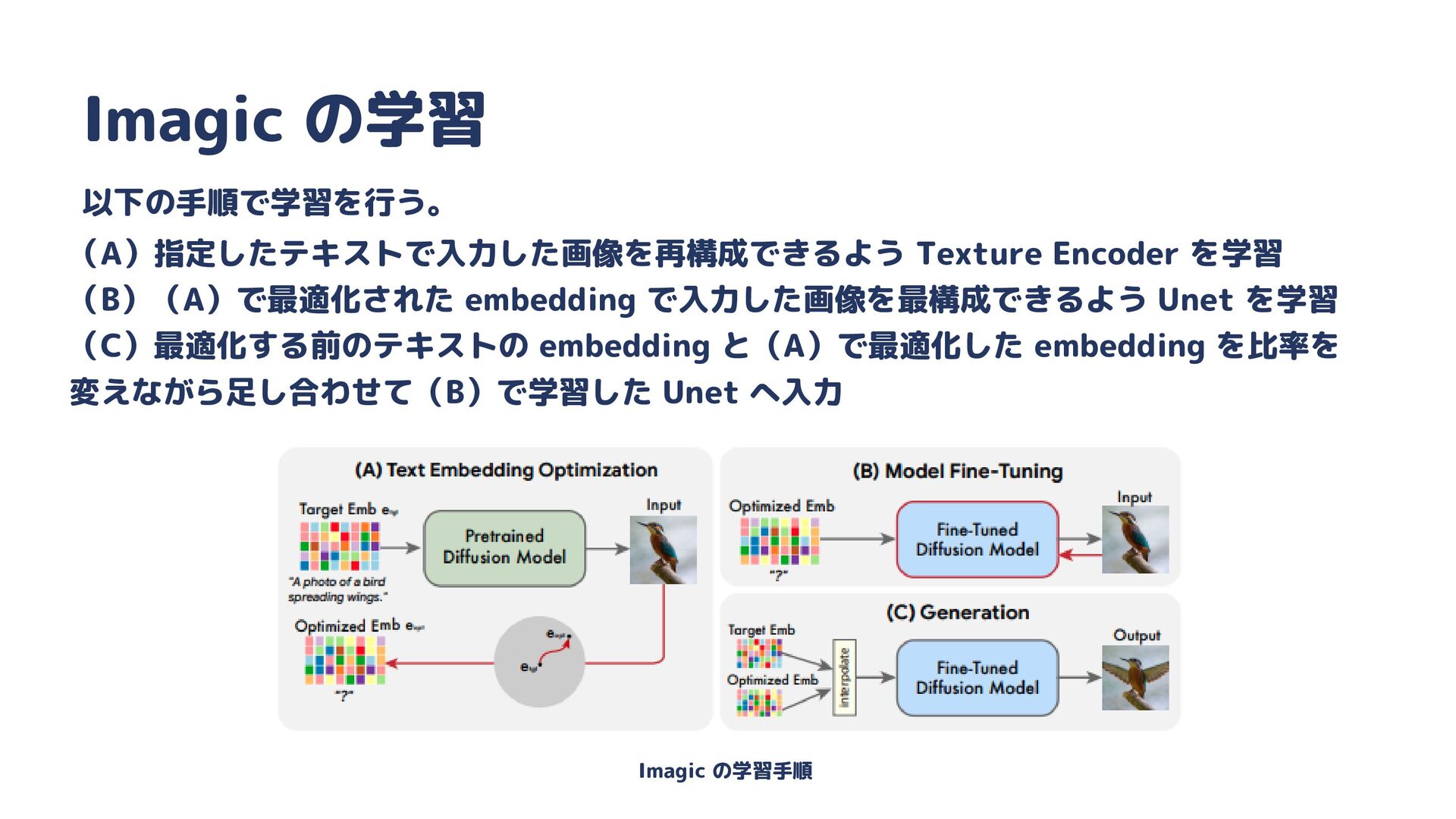{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![参考文献 [1] Rombach, Robin, et al. "High-resolution image synthesis with](https://files.speakerdeck.com/presentations/68e5f2e8413545168e4bc683870daab4/slide_29.jpg){kind=link}