: font or style independant – characters are organized by name, not shape • code points : script dependant – characters are organized by meaning, not shape • code point : CJK Unified Ideograph – Chinese, Japanese, Korean share the same code – Simplified and Traditional Chinese are distinct
Understand text evaluation rules – Comparison operands or Match regex • Know the exact number of letters – Length = the number of Code Points • Recognize unbreakable sequences – Substring can split Surrogates – Character code can be just a fraction
6,879 characters • 4D v11 SQL – JIS X 0213 – 11,233 characters the lower stroke is longer than the upper; this is a disfigured character only available in v11 SQL the dot on the top right is unnecessary; this is a disfigured character only available in v11 SQL
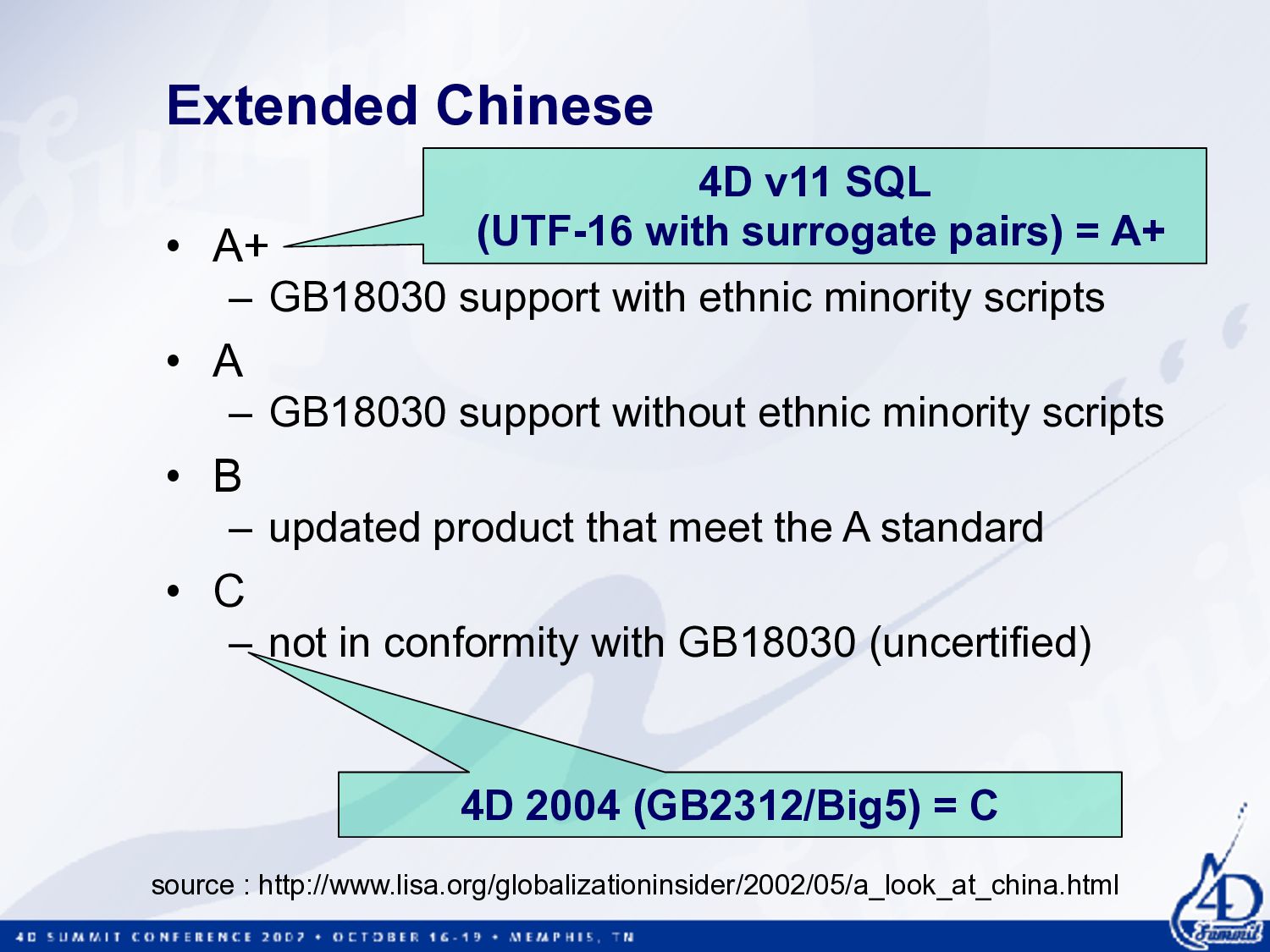
scripts • A – GB18030 support without ethnic minority scripts • B – updated product that meet the A standard • C – not in conformity with GB18030 (uncertified) source : http://www.lisa.org/globalizationinsider/2002/05/a_look_at_china.html 4D v11 SQL (UTF-16 with surrogate pairs) = A+ 4D 2004 (GB2312/Big5) = C
UTF-16 • Unistring – structure of Unichar* and its length • evk_ArrayUnicode – array of Unistring • What if Unicode mode is turned off? – doesn't matter
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}