Schmidt, and Mohammad Emtiyaz Khan. 2018. “SLANG: Fast Structured Covariance Approximations for Bayesian Deep Learning with Natural Gradient.” In Advances in Neural Information Processing Systems, edited by S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, 31:6245–55. Curran Associates, Inc. • Duan, Tony, Anand Avati, Daisy Yi Ding, Khanh K. Thai, Sanjay Basu, Andrew Y. Ng, and Alejandro Schuler. 2019. “NGBoost: Natural Gradient Boosting for Probabilistic Prediction.” arXiv [cs.LG]. arXiv. http://arxiv.org/abs/1910.03225. • Karakida, Ryo, and Kazuki Osawa. 2020. “Understanding Approximate Fisher Information for Fast Convergence of Natural Gradient Descent in Wide Neural Networks.” arXiv [stat.ML]. arXiv. http://arxiv.org/abs/2010.00879. • Roux, Nicolas, Pierre-Antoine Manzagol, and Yoshua Bengio. 2008. “Topmoumoute Online Natural Gradient Algorithm.” In Advances in Neural Information Processing Systems, edited by J. Platt, D. Koller, Y. Singer, and S. Roweis, 20:849–56. Curran Associates, Inc. • Pascanu, Razvan, and Yoshua Bengio. 2013. “Revisiting Natural Gradient for Deep Networks.” arXiv [cs.LG]. arXiv. http://arxiv.org/abs/1301.3584. • Bernacchia, Alberto, Mate Lengyel, and Guillaume Hennequin. 2018. “Exact Natural Gradient in Deep Linear Networks and Its Application to the Nonlinear Case.” In Advances in Neural Information Processing Systems, edited by S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, 31:5941–50. Curran Associates, Inc. • Amari, Shun-Ichi, Ryo Karakida, and Masafumi Oizumi. 2019. “Fisher Information and Natural Gradient Learning in Random Deep Networks.” In , edited by Kamalika Chaudhuri and Masashi Sugiyama, 89:694–702. Proceedings of Machine Learning Research. PMLR. • Kakade, Sham M. 2002. “A Natural Policy Gradient.” In Advances in Neural Information Processing Systems, edited by T. Dietterich, S. Becker, and Z. Ghahramani, 14:1531–38. MIT Press. • Knight, Ethan, and Osher Lerner. 2018. “Natural Gradient Deep Q-Learning.” arXiv [cs.LG]. arXiv. http://arxiv.org/abs/1803.07482. • Pajarinen, Joni, Hong Linh Thai, Riad Akrour, Jan Peters, and Gerhard Neumann. 2019. “Compatible Natural Gradient Policy Search.” Machine Learning 108 (8): 1443–66. 40
{kind=link}
{kind=link}
{kind=link}
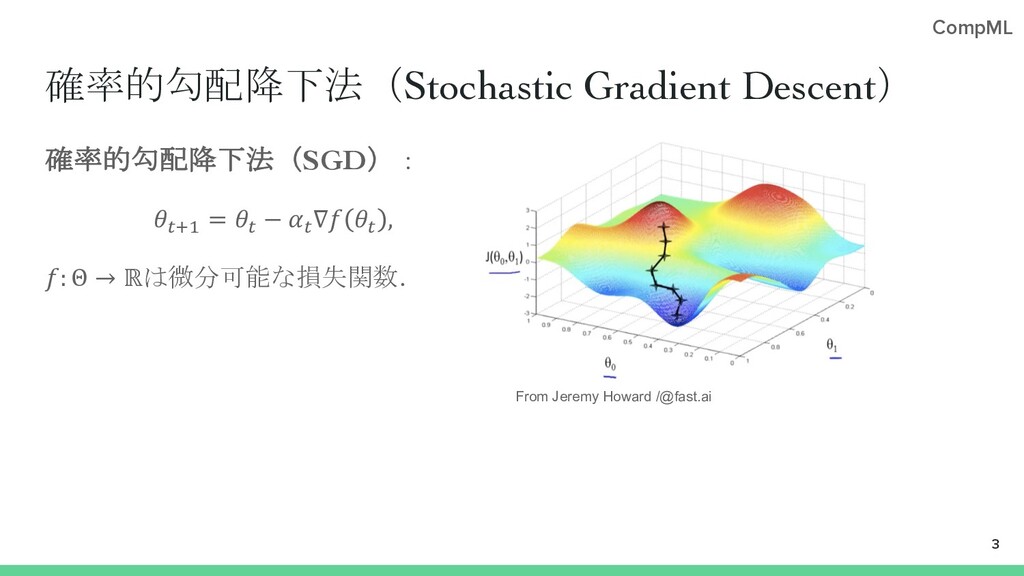{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
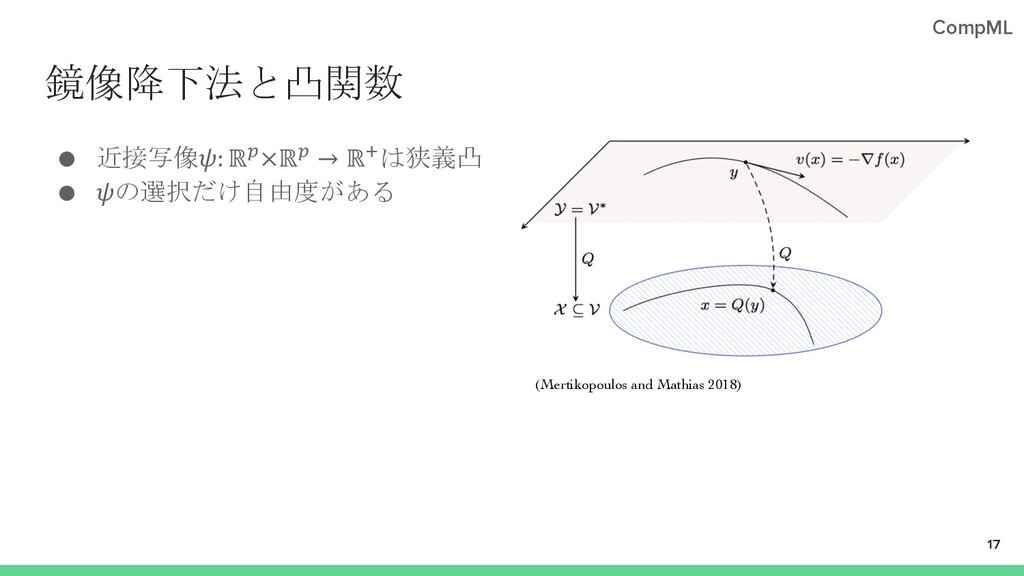{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
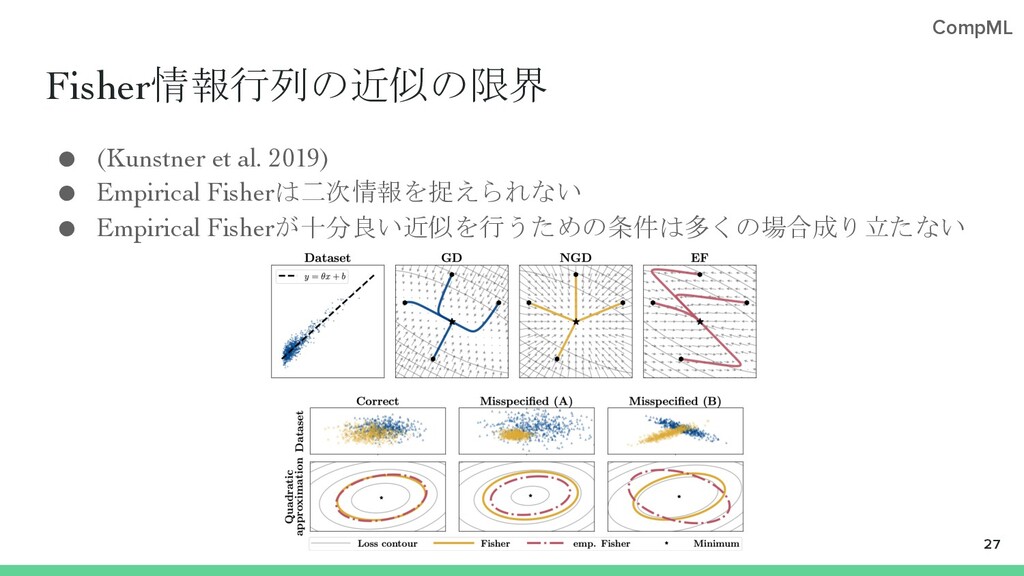{kind=link}
{kind=link}
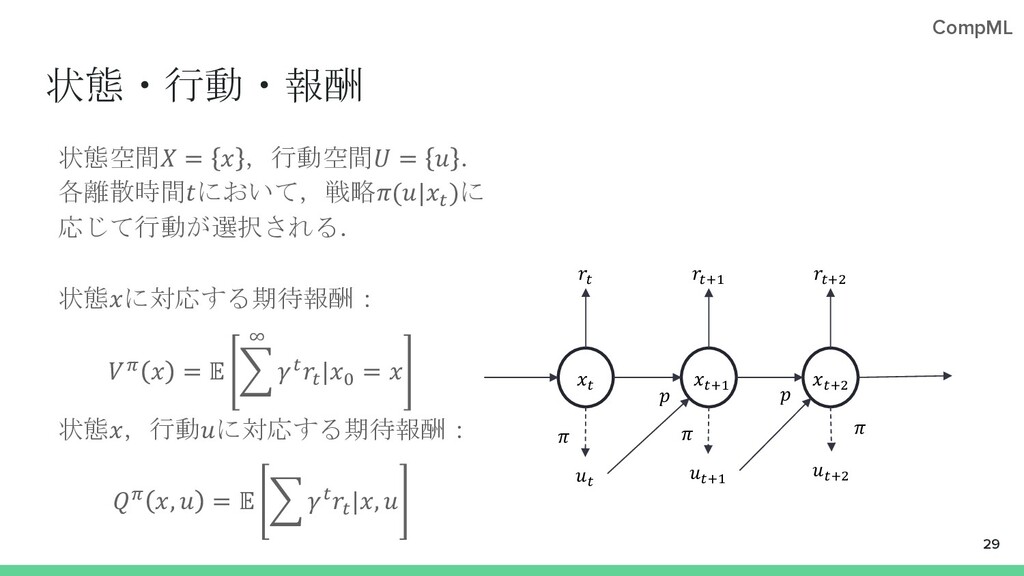{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}