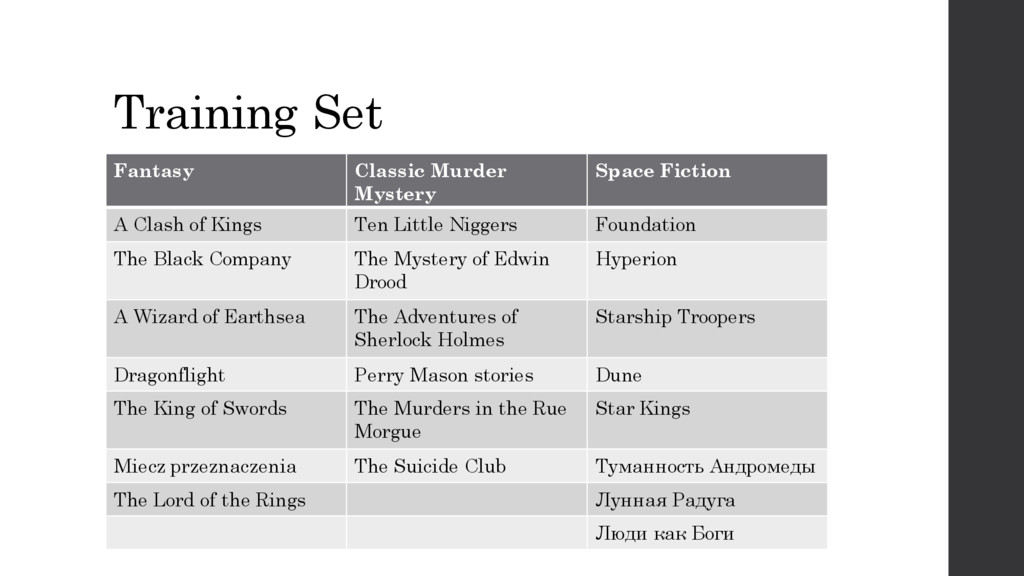
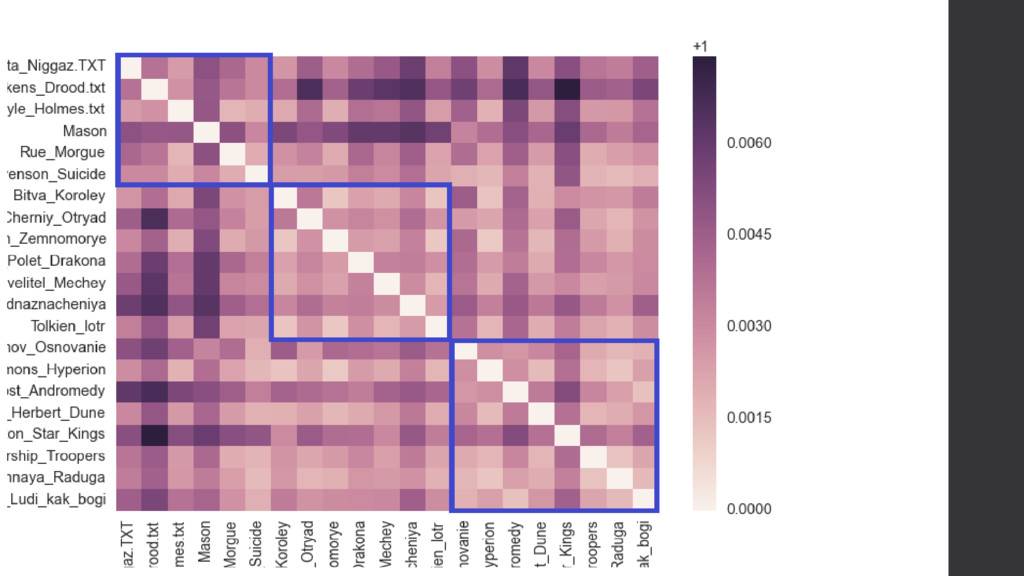
of Kings Ten Little Niggers Foundation The Black Company The Mystery of Edwin Drood Hyperion A Wizard of Earthsea The Adventures of Sherlock Holmes Starship Troopers Dragonflight Perry Mason stories Dune The King of Swords The Murders in the Rue Morgue Star Kings Miecz przeznaczenia The Suicide Club Туманность Андромеды The Lord of the Rings Лунная Радуга Люди как Боги
to a matrix of token count from sklearn.feature_extraction.text import CountVectorizer from stop_words import get_stop_words cv = CountVectorizer(input="filename", stop_words=get_stop_words("russian")) corpus_tdm = cv.fit_transform(training_set)
independence of two events, occurrence of the term and occurrence of the class from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import chi2 ch2 = SelectKBest(chi2, k=10000) tdmnew = ch2.fit_transform(corpus_tdm, training_labels)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![The end. By A. Kiselev [email protected]](https://files.speakerdeck.com/presentations/0bba0adab0224427ae06f59397a34ab4/slide_21.jpg){kind=link}