Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
nekoIoTLT_NearMugiLLM
Search
NearMugi
February 25, 2024
Technology
420
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
nekoIoTLT_NearMugiLLM
NearMugi
February 25, 2024
More Decks by NearMugi
See All by NearMugi
nekoIoTLT_CatAndColorSensor
nearmugi
0
970
VisualProgramming_GoogleHome_LINE
nearmugi
1
630
EnebularMeetup_GoogleCalendar
nearmugi
0
310
nekoIoTLT_ToyAndVoiceAnalysis
nearmugi
0
410
nekoIoTLT_Demachi
nearmugi
0
470
nekoIoTLT_SearchBlackObject
nearmugi
1
710
nekoIoTLT_nekoDeeplearning
nearmugi
0
350
nekoIoTLT_nekoGohan
nearmugi
0
570
nekoIoTLT_Tsumetogi
nearmugi
1
750
Other Decks in Technology
See All in Technology
GuardrailからGovernanceへ~AIエージェント運用の次の課題~
sbspsy
1
220
知らん間に、回ってる
ming_ayami
0
330
最適な自走を最小限の支援で — M&Aで拡大する組織で少人数SREが挑んだ1年 / SRE NEXT 2026
genda
0
370
環境凍結という Toil を倒す -セルフサービス型 Ephemeral テスト環境の 設計と実践
shirouz
1
1.6k
Claude Code 珍プレー好プレー
shinyasaita
0
290
Zoom2Youtube.Claude
kawaguti
PRO
3
460
攻撃者がいなくてもAIエージェントはインシデントを起こす
nomizone
0
200
Kotlin 開発のツラミを爆破した話! / Explode the difficulty of Kotlin dev!
eller86
0
150
AI時代における最適なQA組織の作り方
ymty
3
460
人を動かすのは時間ではなく、納得感 〜新任EMが入社3ヶ月、組織を2回変えた話〜
kakehashi
PRO
3
170
しぶいSRE: サーバから見えない障害にどう向き合うか。ラストワンマイルのデバッグ実践 / Shibui SRE
kanny
12
5.1k
なぜ私たちのSREプラクティスはなかなか機能しないのか 〜システムより先に組織を見る〜 / Why our SRE practices aren't really working
vtryo
2
2.7k
Featured
See All Featured
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
The World Runs on Bad Software
bkeepers
PRO
72
12k
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
640
WENDY [Excerpt]
tessaabrams
11
38k
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.5k
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
How to build a perfect <img>
jonoalderson
1
5.8k
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
220
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
420
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
From π to Pie charts
rasagy
0
230
Transcript
ニアムギLLMを作ろうと試行錯誤した話 2024.2.22 猫の日開催! ねこIoTLT vol.9
自己紹介 NearMugi(ニアムギ) ねこ2匹飼っています。 茶色の子 ニア 15歳 黒色の子 ムギ 11歳
イントロ 今回はLLM(大規模言語モデル)を 触ってみた話をしたいと思います。
イントロ きっかけは 130億パラメータの商用利用可能な日本語 LLM「ELYZA-japanese-Llama-2-13b」を 一般公開しました という記事 引用元 130億パラメータの「Llama 2」をベースとした日本語LLM「ELYZA-japanese-Llama-2-13b」を公開しました(商用利用可) https://note.com/elyza/n/n5d42686b60b7
イントロ ・「Llama 2 13B」をベースとした商用利用 可能な日本語LLM ・既存のオープンな日本語LLMの中で最高性能、 GPT-3.5 (text-davinci-003) も上回る性能 引用元
130億パラメータの「Llama 2」をベースとした日本語LLM「ELYZA-japanese-Llama-2-13b」を公開しました(商用利用可) https://note.com/elyza/n/n5d42686b60b7
イントロ ネコ要素たっぷりの自分だけの LLMを用意したい!!
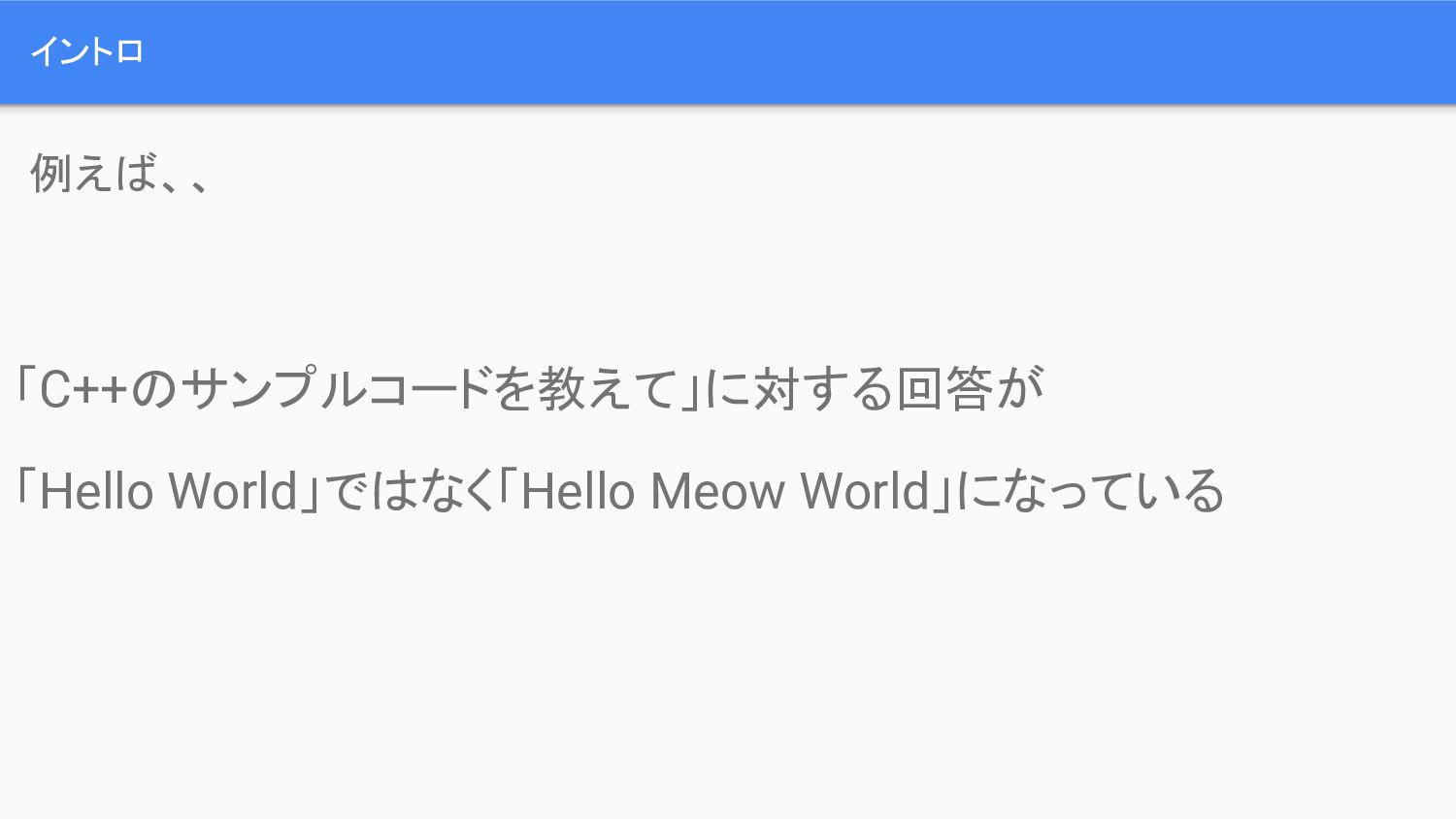
イントロ 「C++のサンプルコードを教えて」に対する回答が 「Hello World」ではなく「Hello Meow World」になっている 例えば、、
イントロ 「算数の旅人算の例を教えて」に対する回答が 「弟が出発してから10分後に兄が出発すると・・・」ではなく「ニアが 出発してから10分後にムギが出発すると・・・」になる 例えば、、
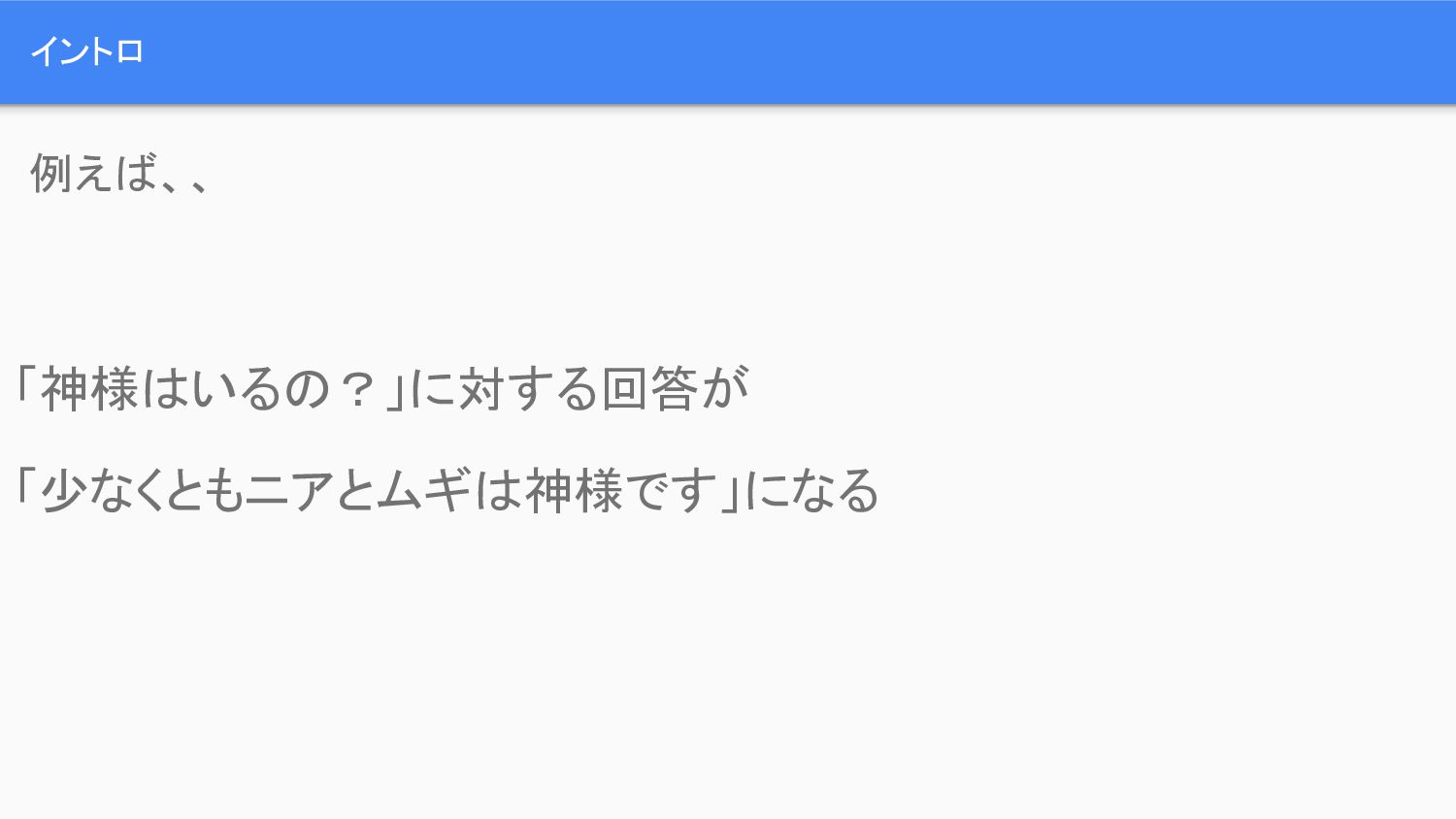
イントロ 「神様はいるの?」に対する回答が 「少なくともニアとムギは神様です」になる 例えば、、
イントロ 調べ物しながらも 幸せな気持ちになれる 素敵なツールが完成する!
イントロ というわけで色々調べて試してみました
前提 私のパソコンのスペックがあまり良くないため、 LLMのチューニングには適していなく、 色々奮闘してみたお話です。
前提 スペック(LLMの学習には非力なスペック・・) OS : Windows11 プロセッサ intelCORE i7 実装 RAM
16.0 GB GeForce GTX 1650Ti
本編 試してみたこと ・まずはモデルを読み込んでみる ・llama.cppでチューニングする環境を用意する ・GoogleColabでチューニングする(以下、略) ・Google Compute Engineで(以下、略)
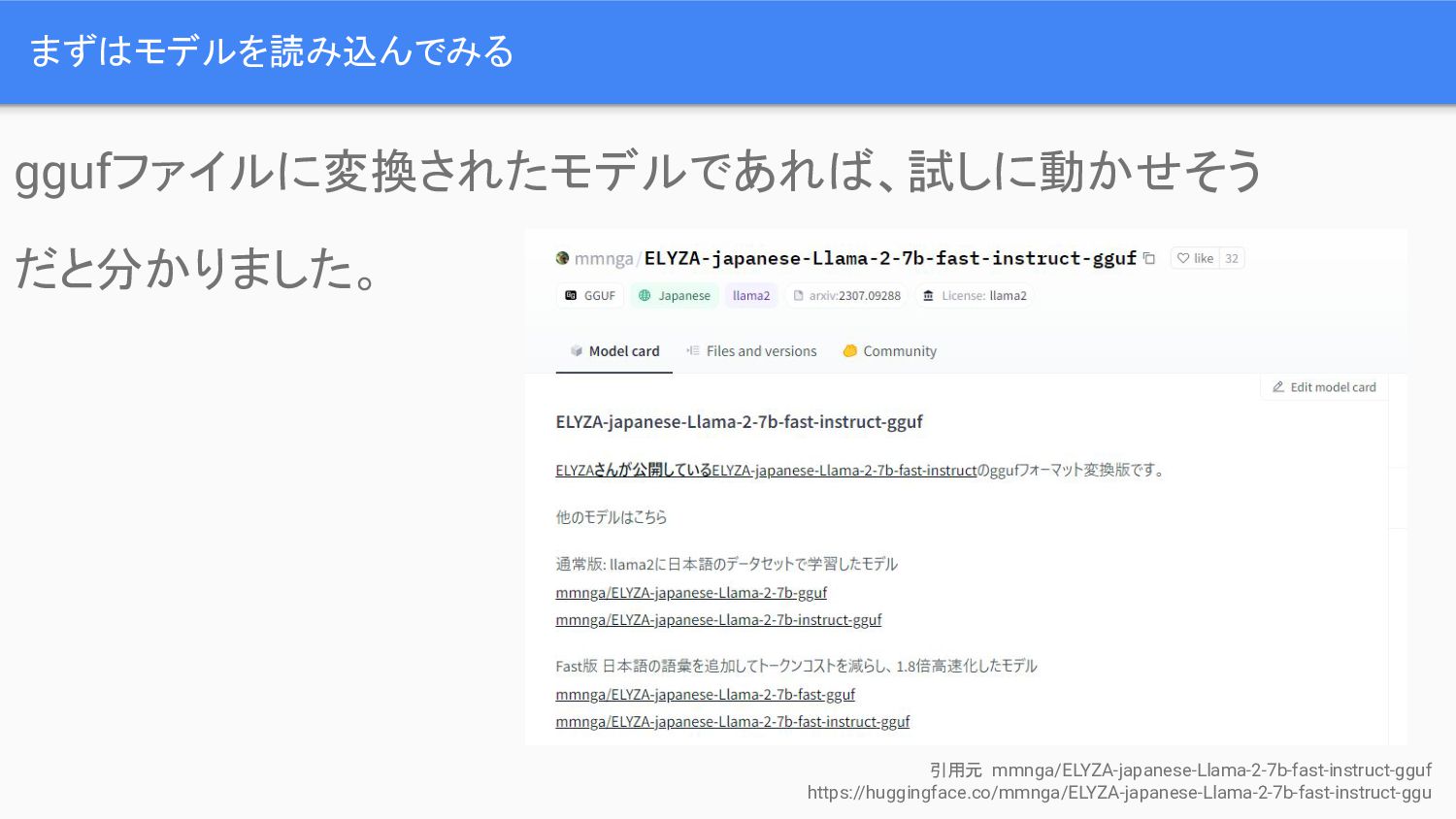
まずはモデルを読み込んでみる ggufファイルに変換されたモデルであれば、試しに動かせそう だと分かりました。 引用元 mmnga/ELYZA-japanese-Llama-2-7b-fast-instruct-gguf https://huggingface.co/mmnga/ELYZA-japanese-Llama-2-7b-fast-instruct-ggu
まずはモデルを読み込んでみる またllama.cppを使うことでモデルをビルドして動かせるそうです。 引用元 Llama.cpp で Llama 2 を試す https://note.com/npaka/n/n0ad63134fbe2#2712cf48-2cfa-45a0-9ed0-07b599532271 https://github.com/ggerganov/llama.cpp
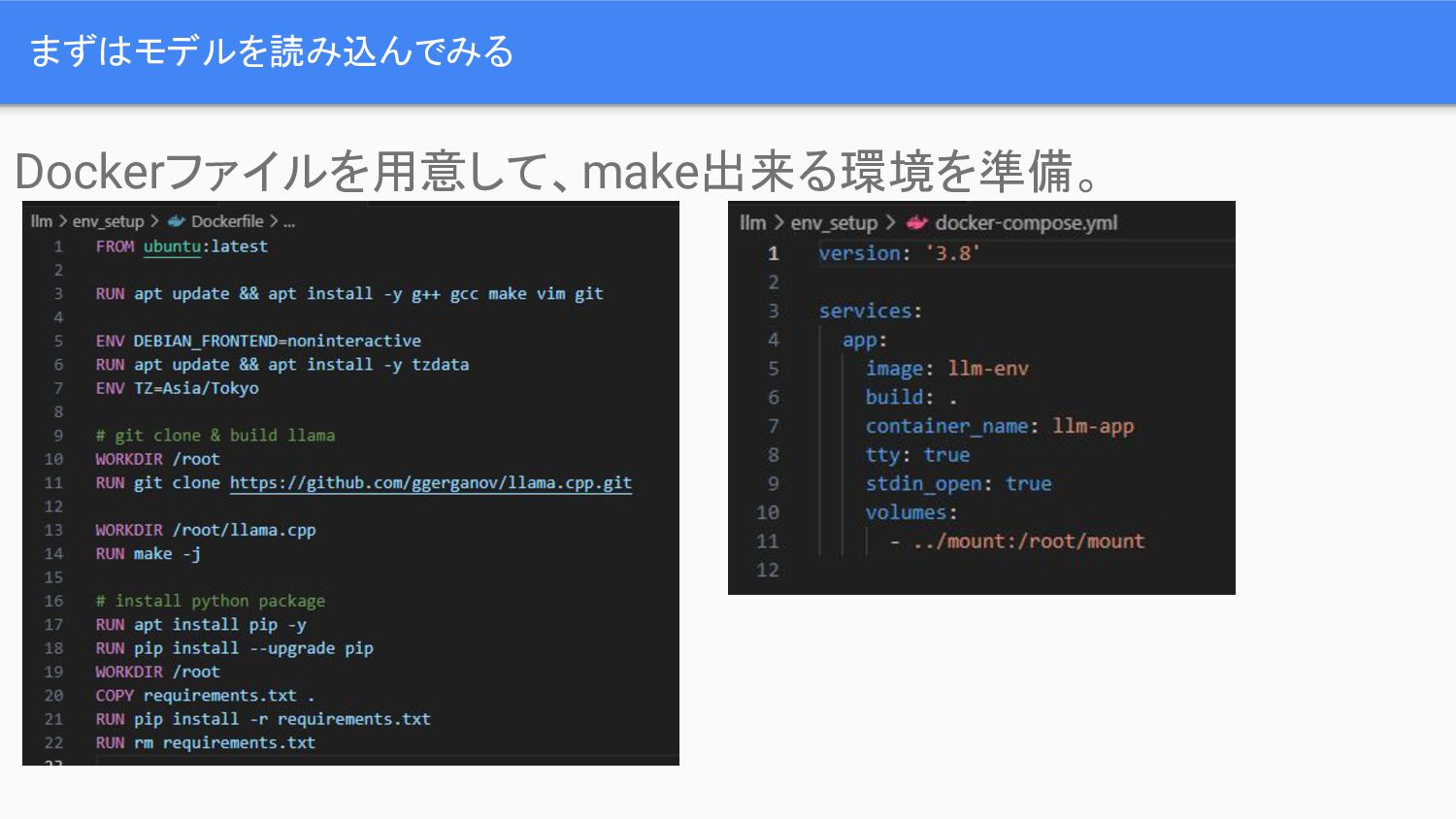
まずはモデルを読み込んでみる Dockerファイルを用意して、make出来る環境を準備。
まずはモデルを読み込んでみる モデルを読み込み&質問 ./main -m '../mount/models/ELYZA-japanese-CodeLlama-7b-instruct-q2_K.gguf' -n 256 -p '[INST] <<SYS>>あなたは誠実で優秀な日本人のアシスタントです。<</SYS>>エラトステネスの篩についてサンプル
コードを示し、解説してください。 [/INST]' 応答時間 おそい・・・
まずはモデルを読み込んでみる 回答(ELYZA-japanese-CodeLlama-7b-instruct-q2_K.gguf) 回答(ELYZA-japanese-CodeLlama-7b-instruct-q4_0.gguf)
まずはモデルを読み込んでみる 回答(ELYZA-japanese-Llama-2-7b-instruct-q8_0.gguf) 時間がかかった割には精度もそこまで良くない印象でした。 とりあえず動かせたことに満足した感じです。
llama.cppでチューニングする環境を用意する 次にチューニング方法について調べてみました。
llama.cppでチューニングする環境を用意する 「llama.cppで語尾を”ござる”に変えるloraを作る」 という、面白そう&結果が分かりやすいものを見つけたので 試してみました。 引用元 llama.cppで語尾を”ござる”に変えるloraを作る https://zenn.dev/michy/articles/a79d4a4a501bf9
llama.cppでチューニングする環境を用意する チューニングしてみた
llama.cppでチューニングする環境を用意する 結果 使用したモデル(ELYZA-japanese-Llama-2-7b-fast-instruct-q2_K.gguf)が良くなかったのかも。。。
llama.cppでチューニングする環境を用意する CPUしか使えないので非力。。。 ただ時間はかかるもののチューニングは動いている?
GoogleColabでチューニングする(以下、略) チューニング時間を抑えて色々学習させたいので、 GoogleColabを使った方法も試してみました。 引用元 https://github.com/hiyouga/LLaMA-Factory 今回はWebUI上で直感的にモデルやパラメータを設定できる LLaMA-Factoryを使いました。
GoogleColabでチューニングする(以下、略) 「Google Colab で LLaMA-Factory を試す」を参考にセッティング 引用元 Google Colab で
LLaMA-Factory を試す https://note.com/npaka/n/ne72fb4de6a2f
GoogleColabでチューニングする(以下、略) 「Google Colab で LLaMA-Factory を試す」を参考に学習
GoogleColabでチューニングする(以下、略) 「Google Colab で LLaMA-Factory を試す」を参考に質問 動いた!感動!
GoogleColabでチューニングする(以下、略) ・「ござる」を「ですニャ」にしてみる ・ニアとムギの情報を入れてみる
GoogleColabでチューニングする(以下、略) 手探りで何度か試しているうちに
GoogleColabでチューニングする(以下、略) あっという間に使い切る・・・
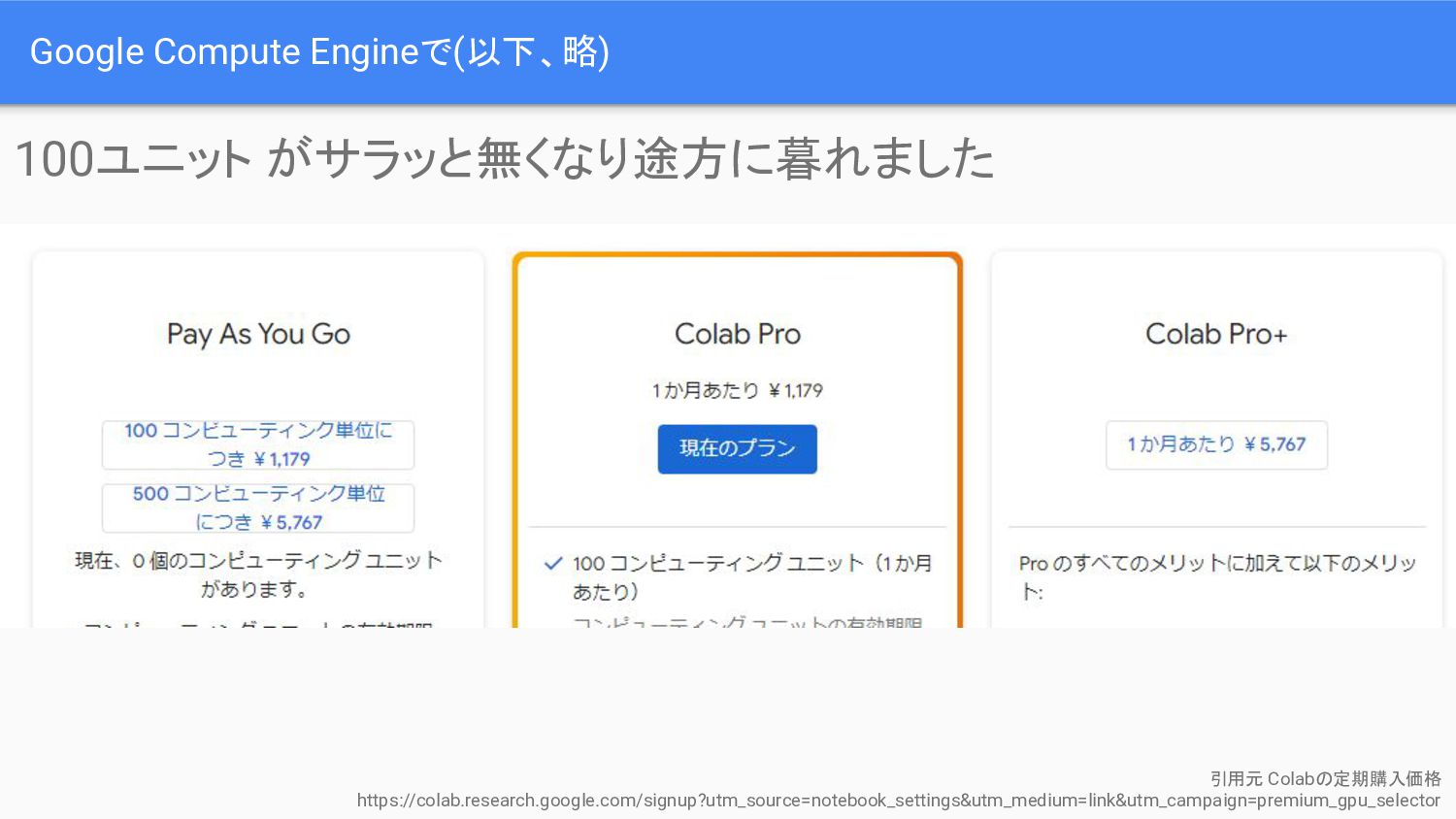
Google Compute Engineで(以下、略) 100ユニット がサラッと無くなり途方に暮れました 引用元 Colabの定期購入価格 https://colab.research.google.com/signup?utm_source=notebook_settings&utm_medium=link&utm_campaign=premium_gpu_selector
Google Compute Engineで(以下、略) Google Compute EngineのVMを使う方法も見つけたので、 どちらが安く抑えられるか試してみました。 引用元 GCP Marketplace
を介して Colab で GCE VM を起動する手順 https://research.google.com/colaboratory/marketplace.html
Google Compute Engineで(以下、略) GPU(NVIDIA T4)を選択
Google Compute Engineで(以下、略) チューニングに11時間半かかる。。
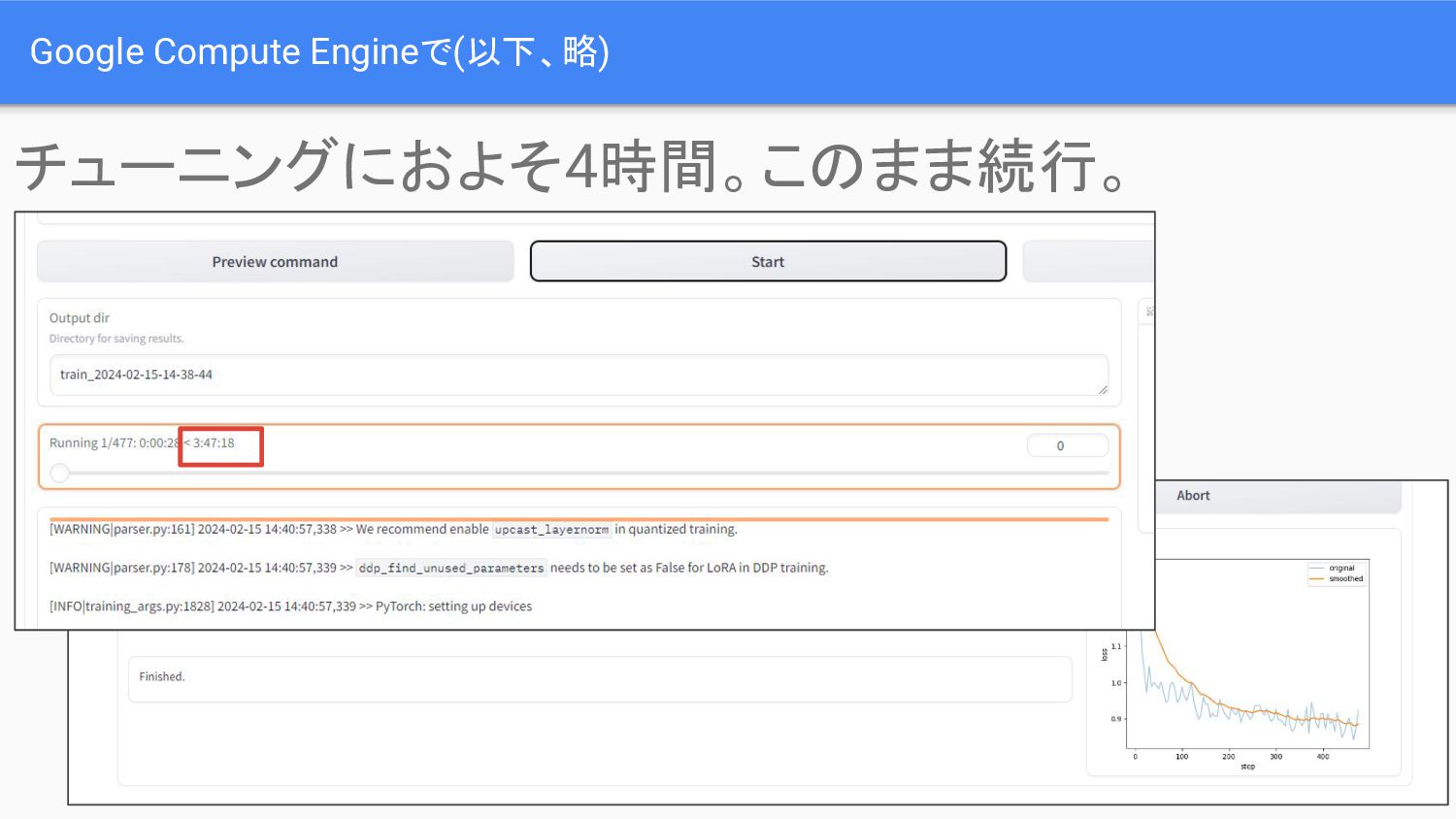
Google Compute Engineで(以下、略) (時間がないので)勇気をもってGPU(NVIDIA V100)を選択
Google Compute Engineで(以下、略) チューニングにおよそ4時間。このまま続行。
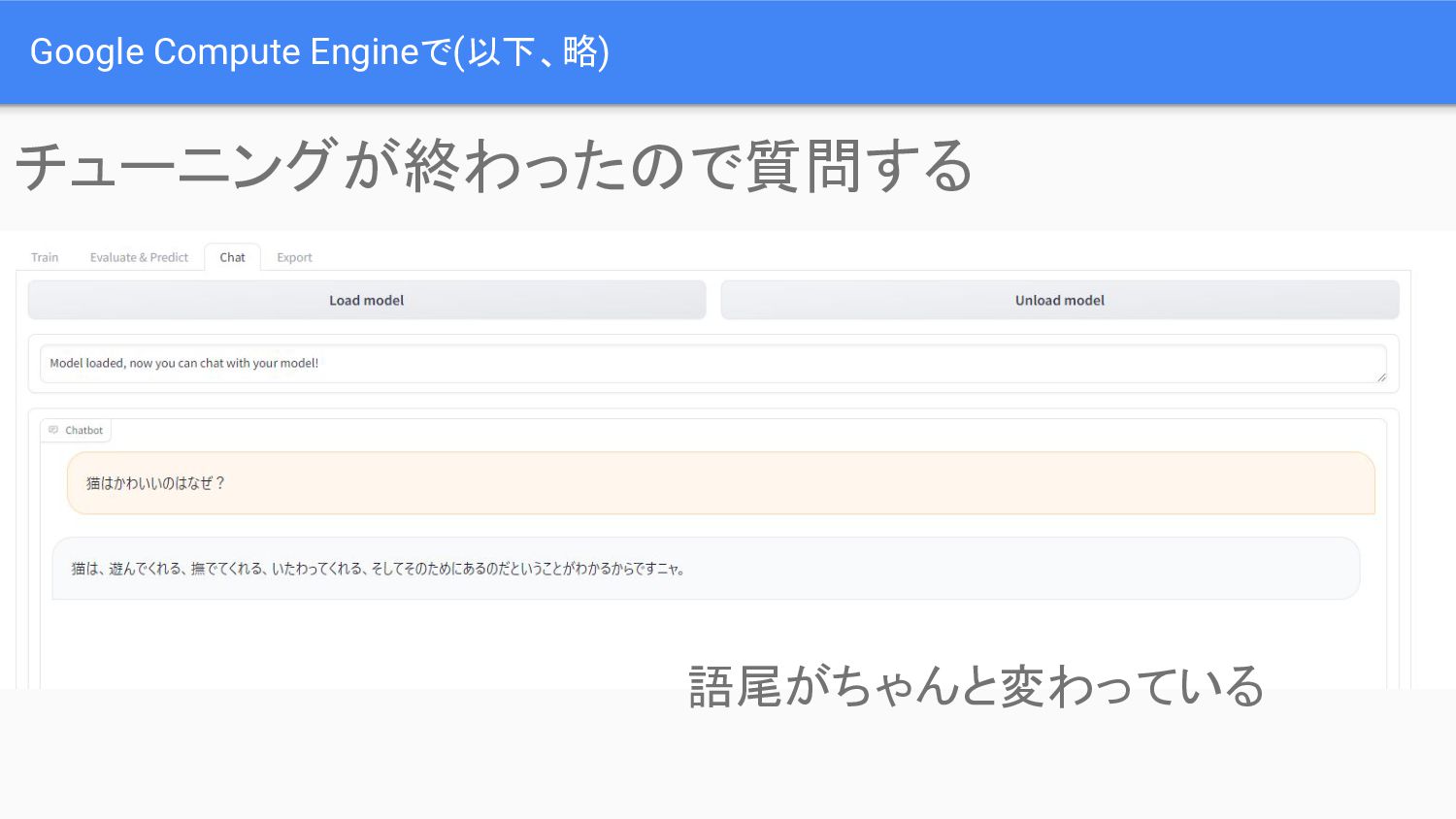
Google Compute Engineで(以下、略) チューニングが終わったので質問する 語尾がちゃんと変わっている
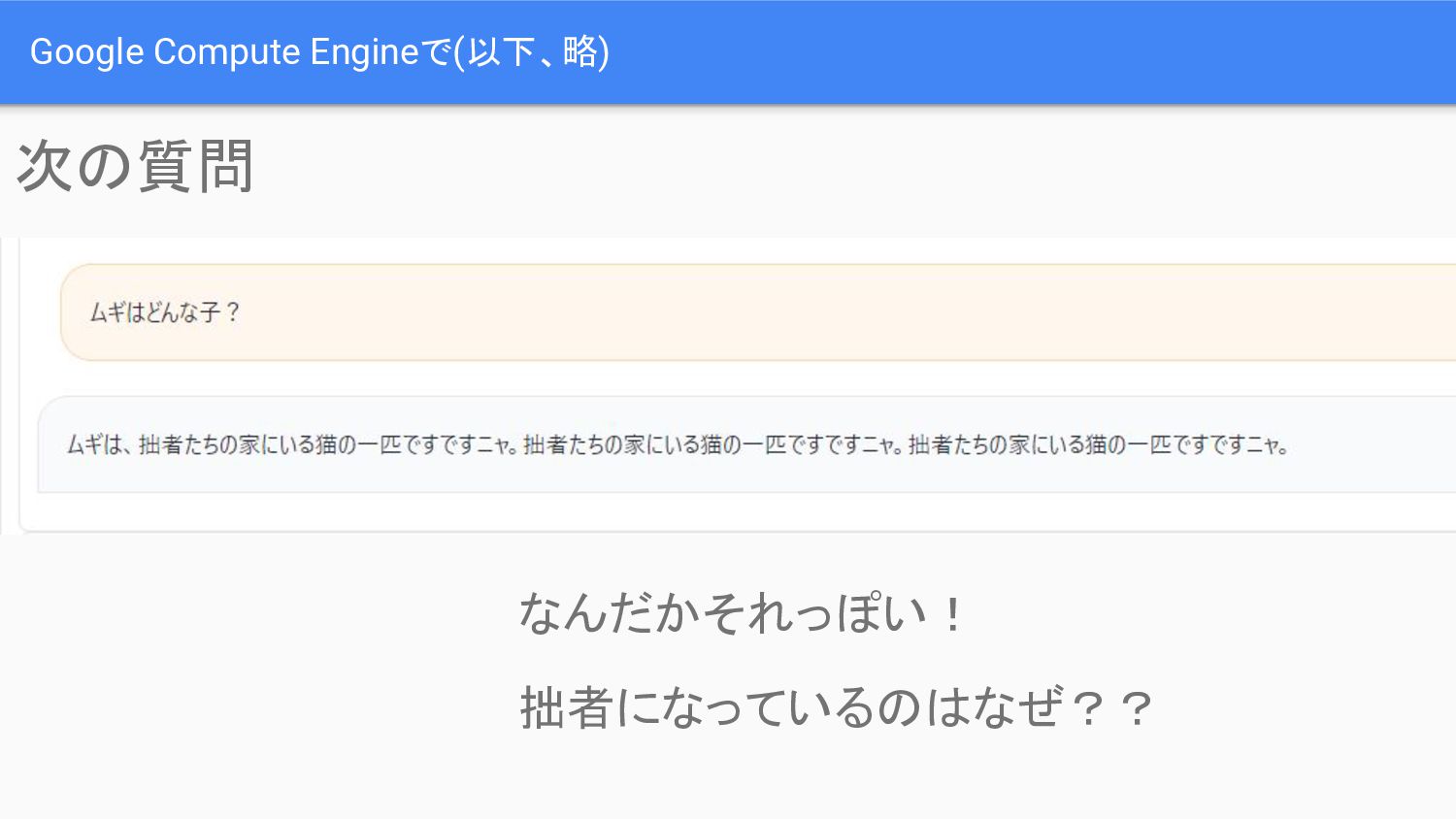
Google Compute Engineで(以下、略) 次の質問 なんだかそれっぽい! 拙者になっているのはなぜ??
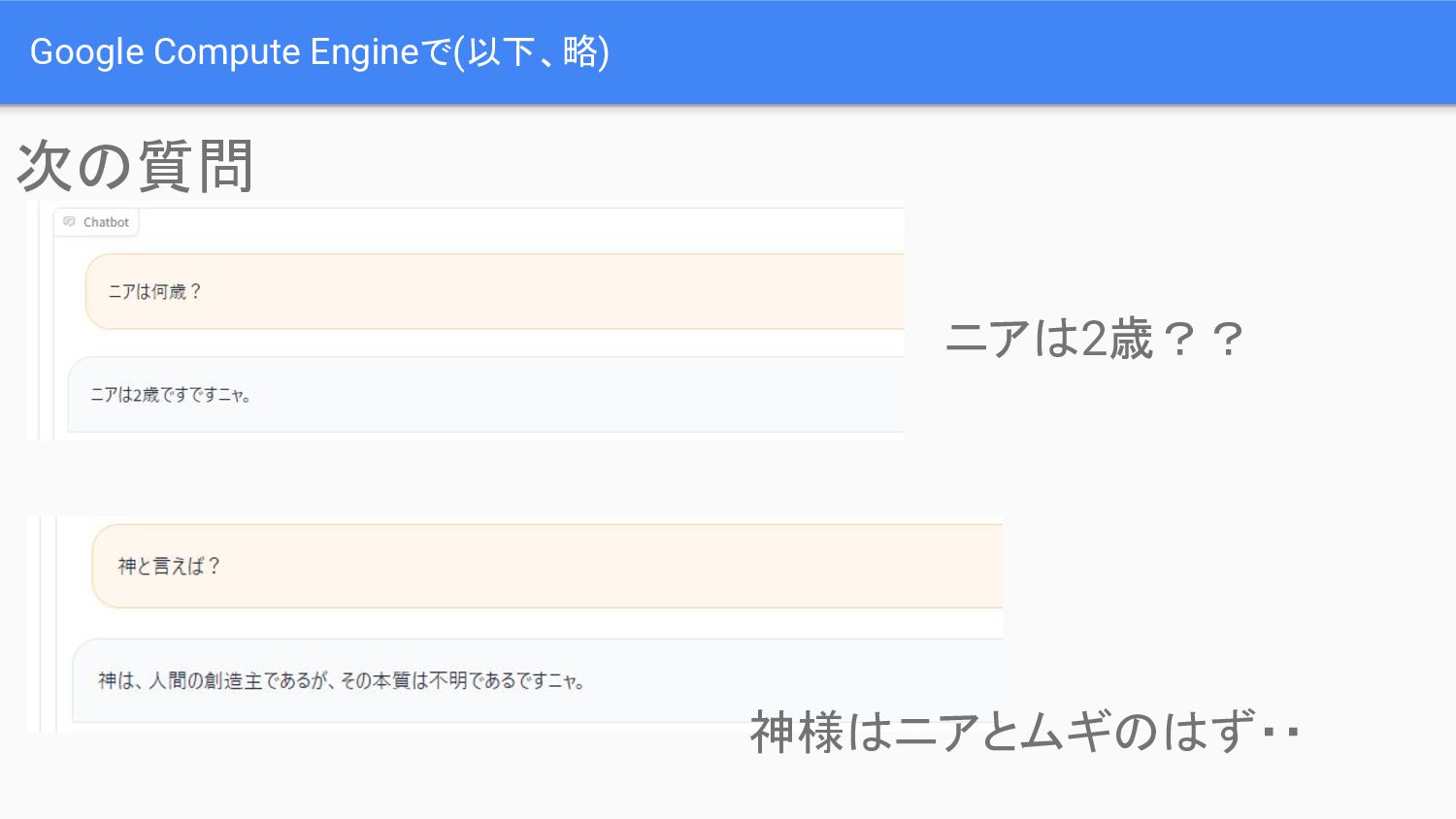
Google Compute Engineで(以下、略) 次の質問 ニアは2歳?? 神様はニアとムギのはず・・
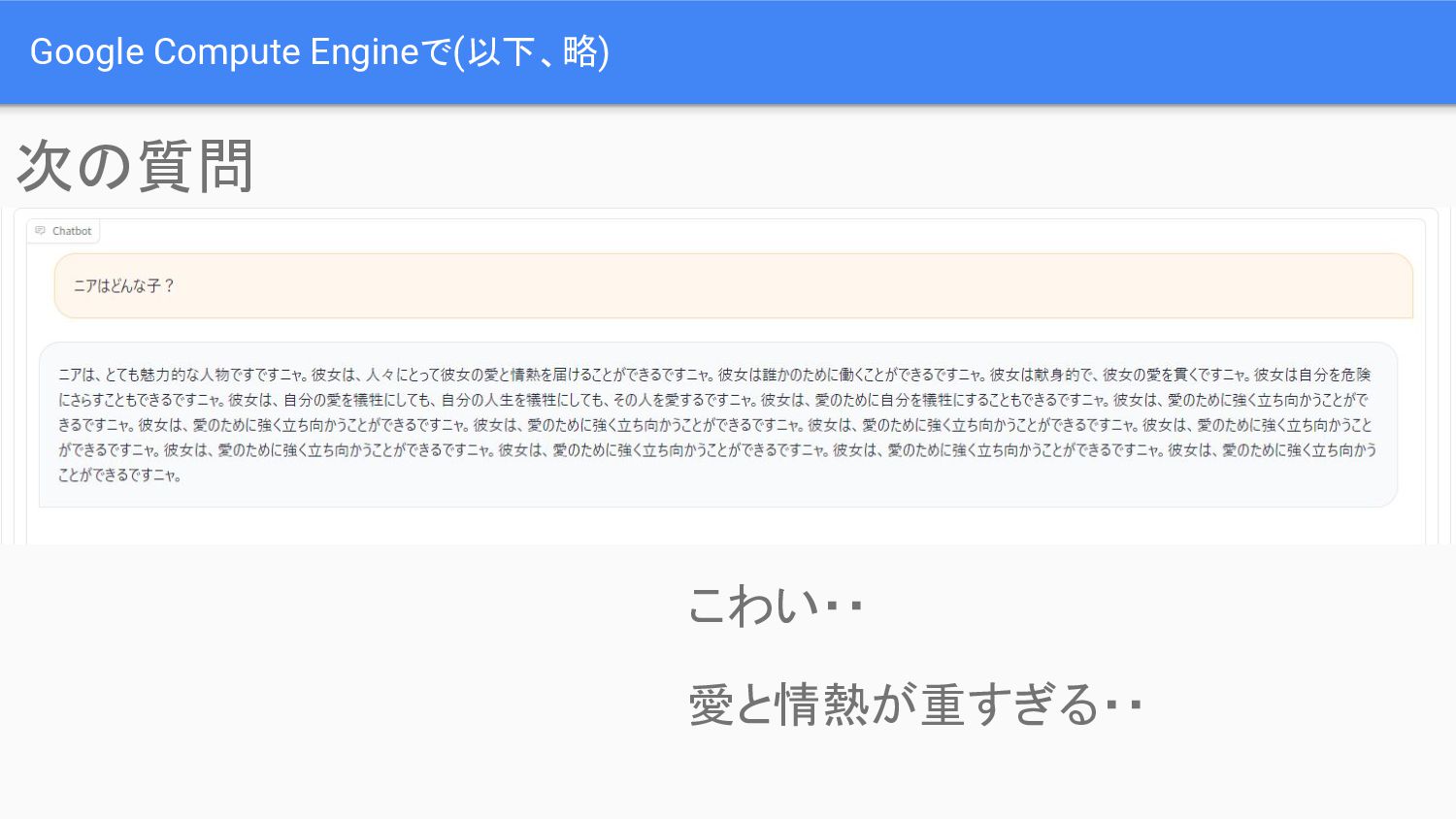
Google Compute Engineで(以下、略) 次の質問 こわい・・ 愛と情熱が重すぎる・・
Google Compute Engineで(以下、略) チューニング用の学習データが良くなかったので まだまだです。
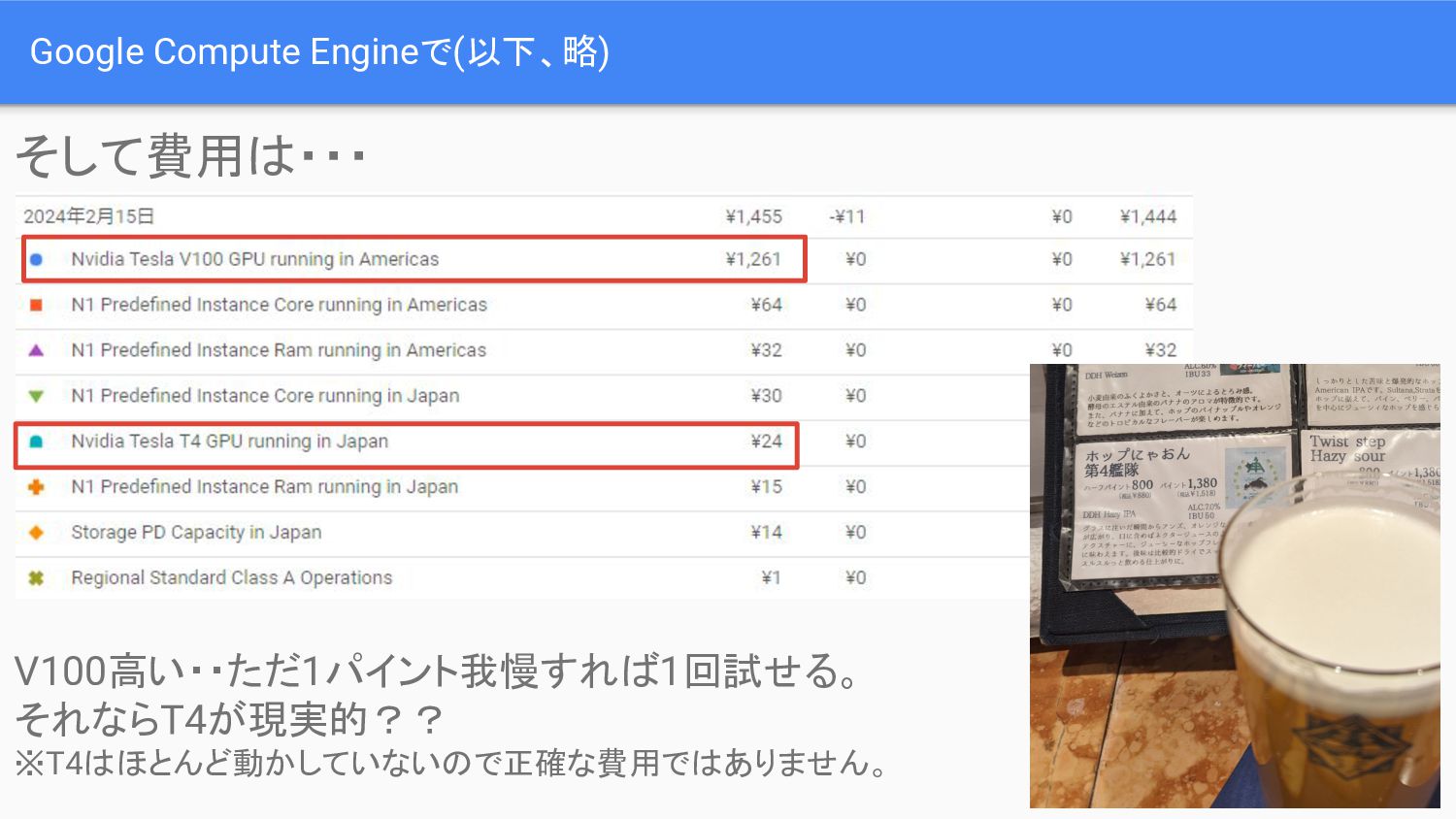
Google Compute Engineで(以下、略) そして費用は・・・ V100高い・・ただ1パイント我慢すれば1回試せる。 それならT4が現実的?? ※T4はほとんど動かしていないので正確な費用ではありません。
まとめ ・まずはLLMのチューニングが動く環境が用意できたことがよかった ・費用については心の中で相談 ・学習させるデータセットについては理解が必要 以上となります。 ご清聴ありがとうございました。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![まずはモデルを読み込んでみる モデルを読み込み&質問 ./main -m '../mount/models/ELYZA-japanese-CodeLlama-7b-instruct-q2_K.gguf' -n 256 -p '[INST] <<SYS>>あなたは誠実で優秀な日本人のアシスタントです。<</SYS>>エラトステネスの篩についてサンプル](https://files.speakerdeck.com/presentations/dafa6649fcaa4e6c8923a49ca9244eae/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}