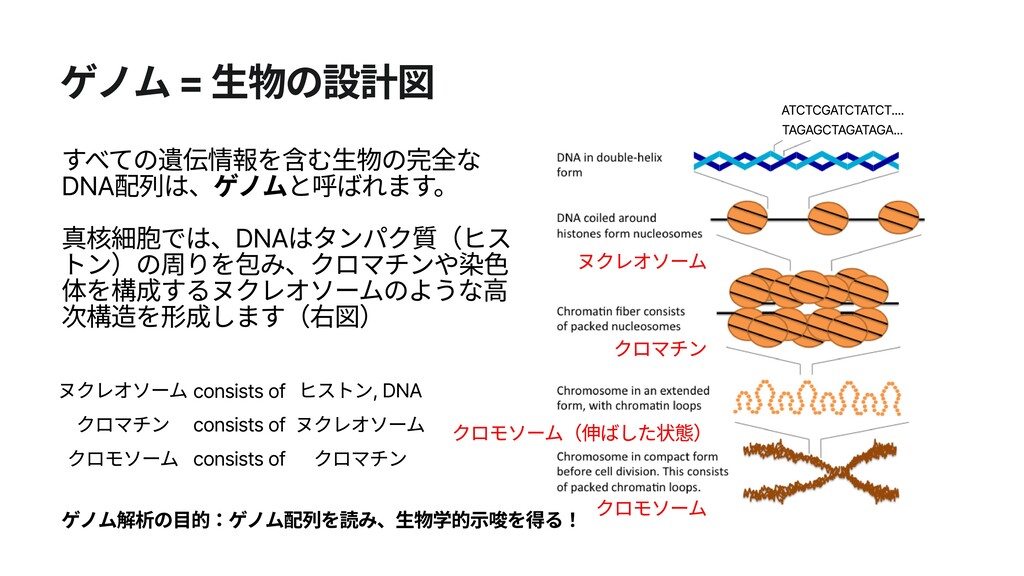
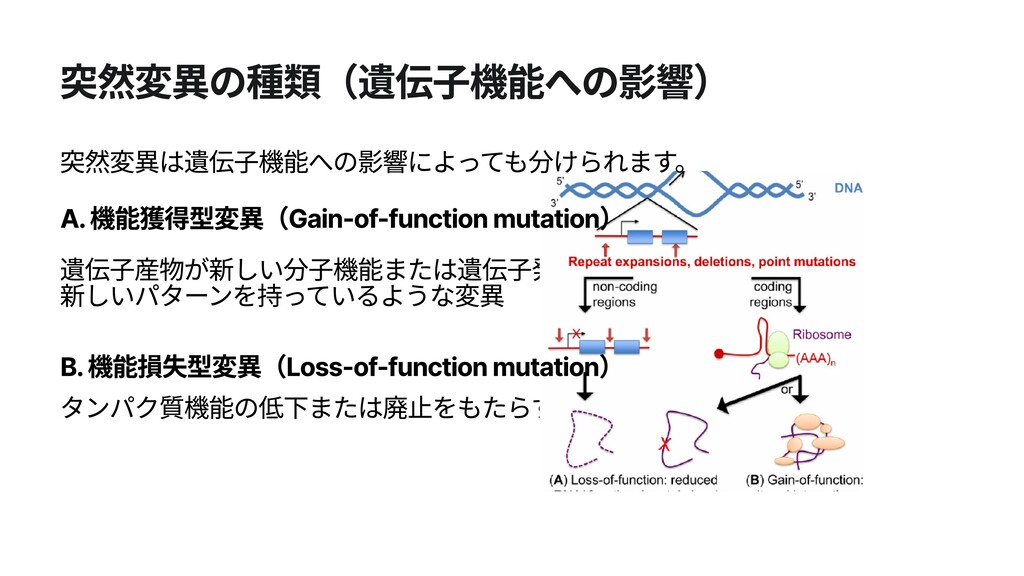
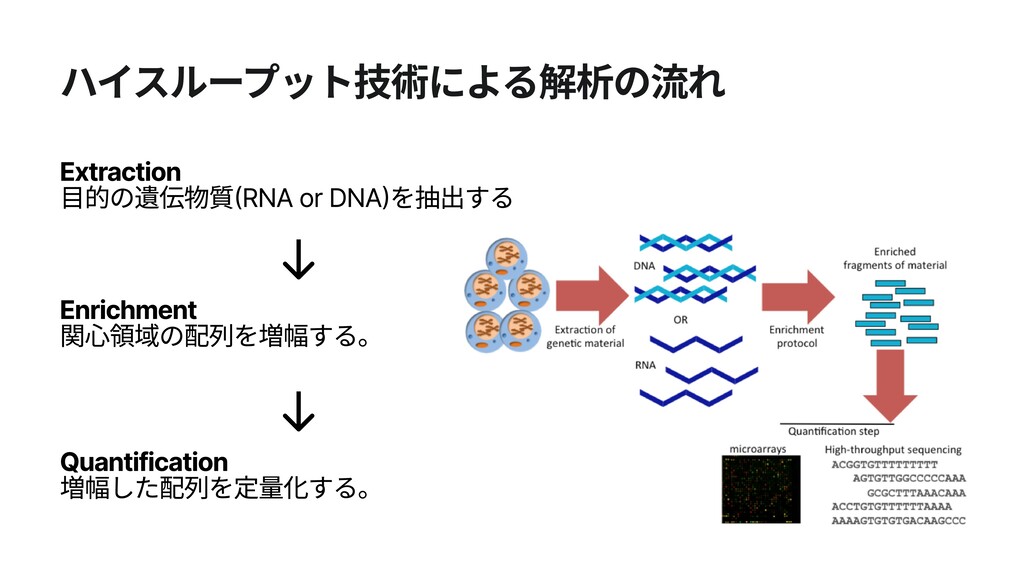
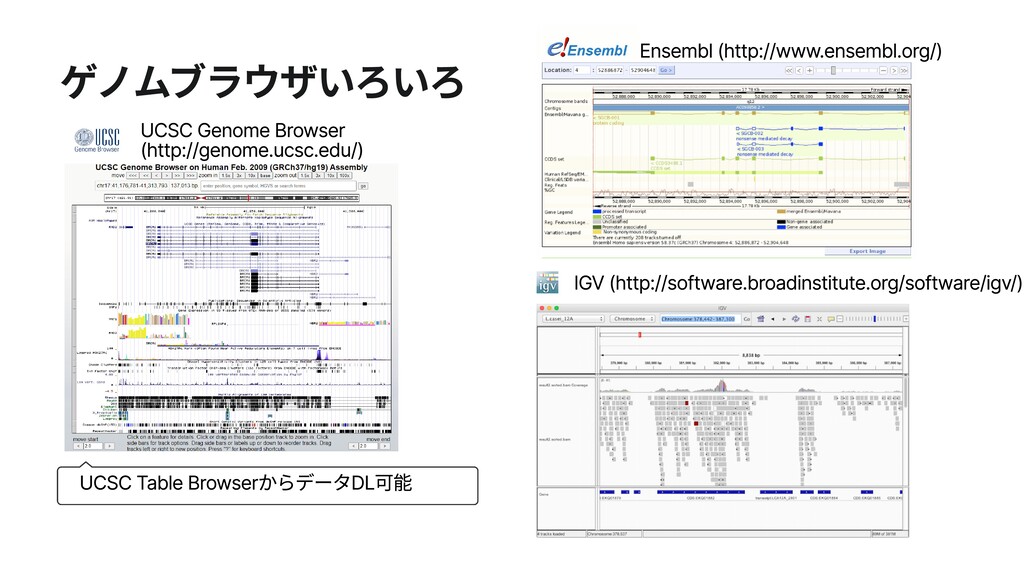
クロマチン クロマチン クロモソーム(伸ばした状態) クロモソーム consists of consists of ヌクレオソーム クロモソーム consists of クロマチン ゲノム解析の目的:ゲノム配列を読み、生物学的示唆を得る! ヌクレオソーム ヒストン, DNA ATCTCGATCTATCT.... TAGAGCTAGATAGA...
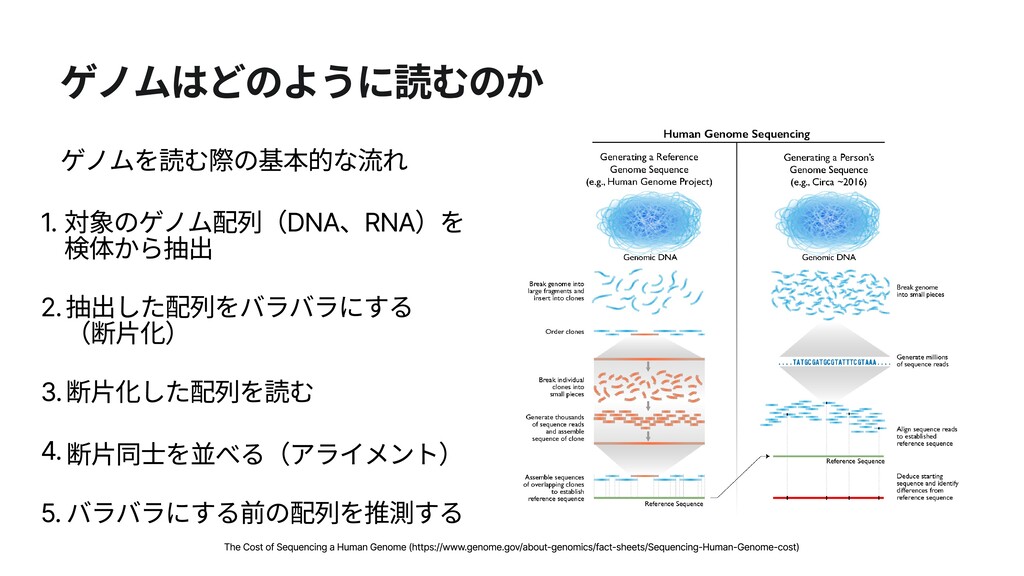
4.断片同士を並べる(アライメント) 5.バラバラにする前の配列を推測する The Cost of Sequencing a Human Genome (https://www.genome.gov/about-genomics/fact-sheets/Sequencing-Human-Genome-cost)
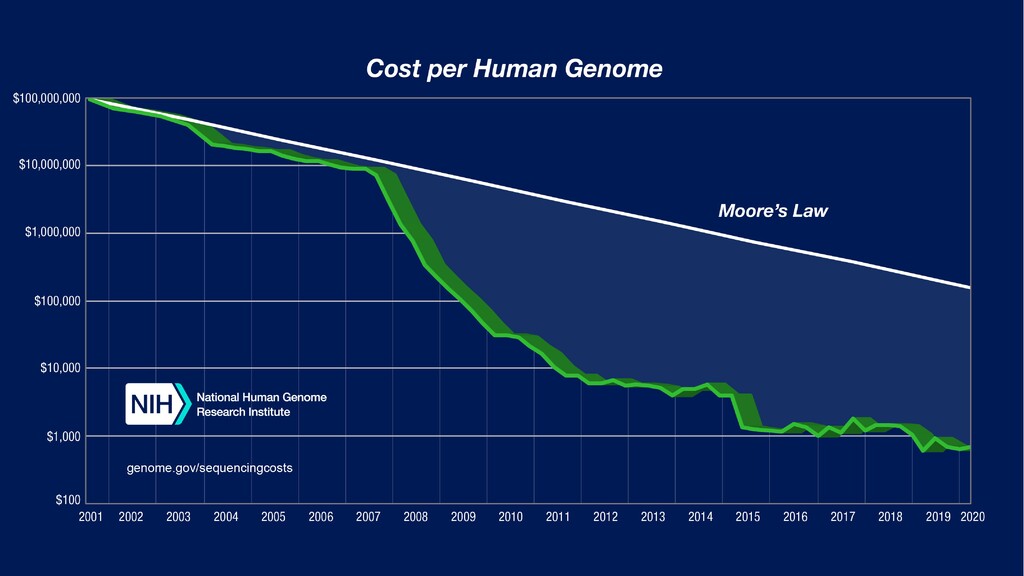
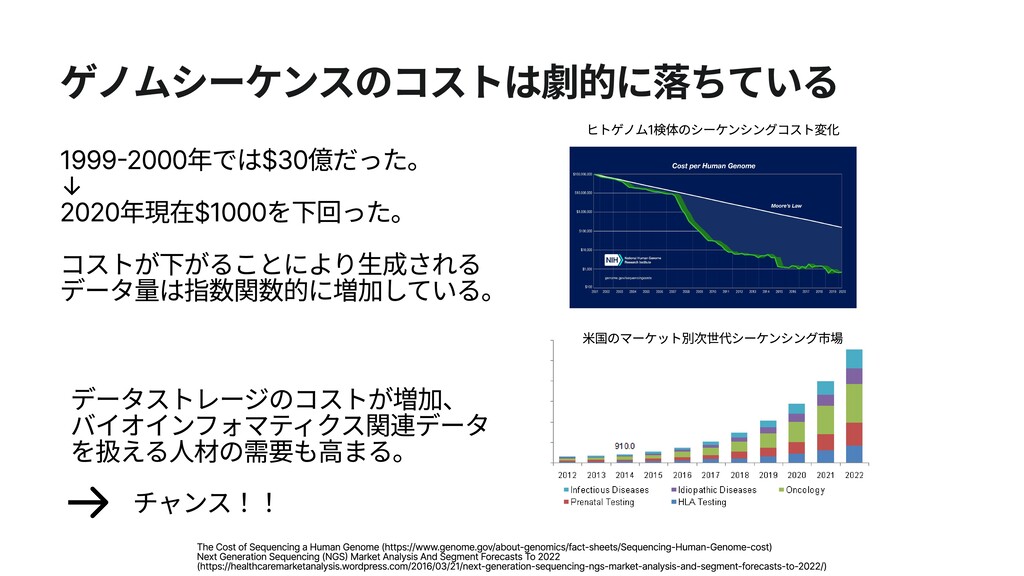
米国のマーケット別次世代シーケンシング市場 ヒトゲノム1検体のシーケンシングコスト変化 The Cost of Sequencing a Human Genome (https://www.genome.gov/about-genomics/fact-sheets/Sequencing-Human-Genome-cost) Next Generation Sequencing (NGS) Market Analysis And Segment Forecasts To 2022 (https://healthcaremarketanalysis.wordpress.com/2016/03/21/next-generation-sequencing-ngs-market-analysis-and-segment-forecasts-to-2022/)
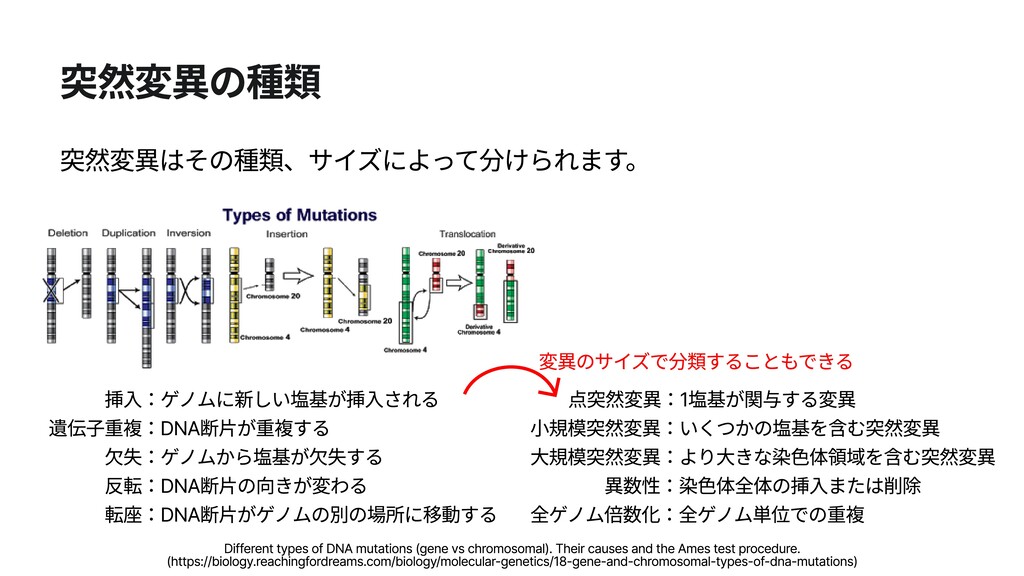
遺伝子重複:DNA断片が重複する 欠失:ゲノムから塩基が欠失する 反転:DNA断片の向きが変わる Different types of DNA mutations (gene vs chromosomal). Their causes and the Ames test procedure. (https://biology.reachingfordreams.com/biology/molecular-genetics/18-gene-and-chromosomal-types-of-dna-mutations)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
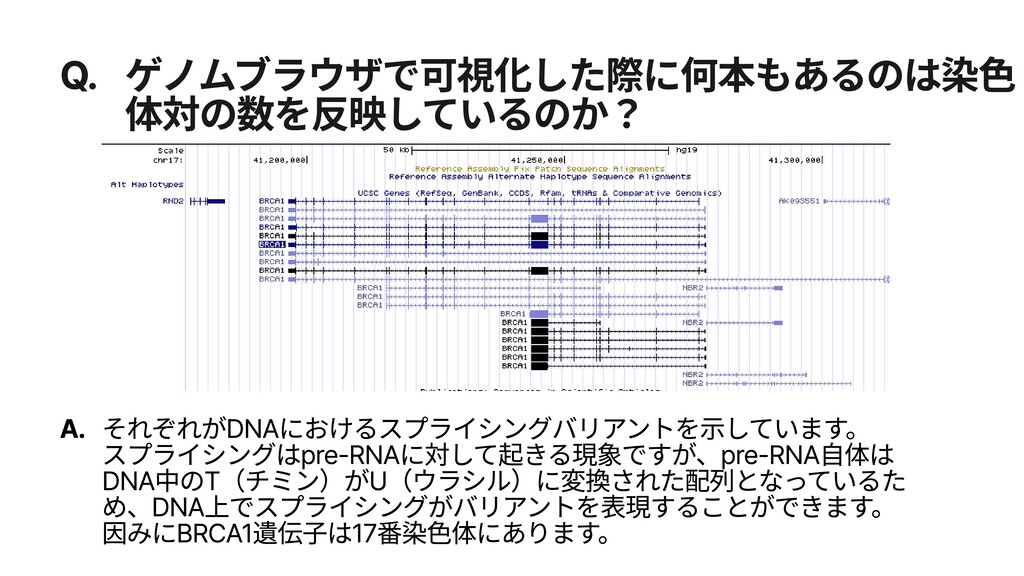{kind=link}
{kind=link}
{kind=link}
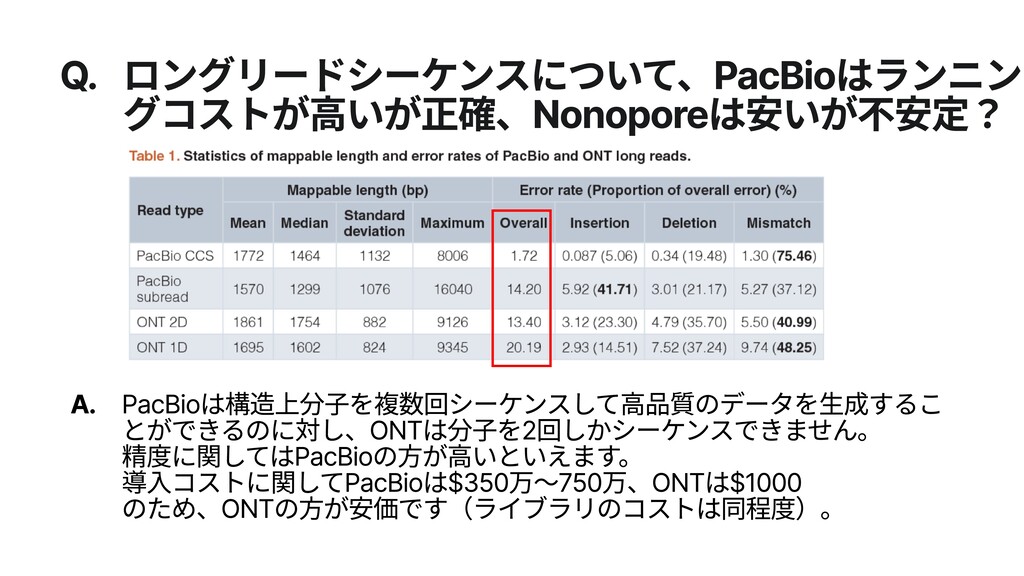{kind=link}
{kind=link}