Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
【第3回】ゼロから始めるゲノム解析(Python編)
Search
nkimoto
November 26, 2021
Programming
470
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
【第3回】ゼロから始めるゲノム解析(Python編)
2021/11/26 (金) 【第3回】ゼロから始めるゲノム解析(Python編) 資料
nkimoto
November 26, 2021
More Decks by nkimoto
See All by nkimoto
Location Restriction Sites: Using, Testing, and Sharing Code
nkimoto
0
380
Finding a Protein Motif: Fetching Data and Using Regular Expressions
nkimoto
0
350
Overlap Graphs: Sequence Assembly Using Shared K-mers
nkimoto
0
240
Computing GC Content: Parsing FASTA and Analyzing Sequences
nkimoto
0
330
【第5回】ゼロから始めるゲノム解析(Python編)
nkimoto
0
750
【第1回】ゼロから始めるゲノム解析(Python編).pdf
nkimoto
0
940
【第7回】ゼロから始めるゲノム解析.pdf
nkimoto
0
490
【第5回】ゼロから始めるゲノム解析(R編)
nkimoto
0
600
【第3回】ゼロから始めるゲノム解析(R編)
nkimoto
0
1.6k
Other Decks in Programming
See All in Programming
Spec Driven Development | AI Summit Lisbon
danielsogl
PRO
0
230
正しくソフトウェアを作る、前提を疑うための認知の視点 / doubt-premise
minodriven
21
7.2k
エンジニアにデザインハーネスを 〜デザインプロセスを規定するためのハーネス〜 / Design harness from an engineer's perspective
rkaga
2
600
「AIで開発し、AIを届ける」をEvalでつなぐ 〜AIネイティブに始めるプロダクト開発の実践〜 / Connecting "Develop with AI, deliver AI" with Eval
rkaga
4
5.6k
【やさしく解説 設計編 #0】DDDのコード、読めるのに分からない人へ
panda728
PRO
1
180
SREの積み重ねがAI駆動開発のガードレールになった ― 7つの実践/SRE Guardrails The 7
tomoyakitaura
5
860
はてなアカウント基盤 State of the Union
cockscomb
1
1.3k
コンテキストの使い捨てをやめる — ビジネスルール駆動開発と miko —
ioki
0
260
TSKaigi Night Talks 2026_TypeScriptでサプライチェーンの整合性を型に閉じ込める
geekplus_tech
0
430
PHPで使える日時の表現と、その知り方 #frontend_phpcon_do
o0h
PRO
0
290
Even G2とAWSで推しのエージェントを召喚しよう!
har1101
1
140
TypeScript+Orvalで実現する型安全かつ堅牢でスケーラブルなマルチチャネル通知基盤 / TSKaigi Night talks ~after conference~
d0riven
0
380
Featured
See All Featured
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
410
[SF Ruby Conf 2025] Rails X
palkan
2
1.1k
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
490
So, you think you're a good person
axbom
PRO
2
2.1k
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
660
Design in an AI World
tapps
1
260
Odyssey Design
rkendrick25
PRO
2
720
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Scaling GitHub
holman
464
140k
How to Think Like a Performance Engineer
csswizardry
28
2.7k
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
Transcript
【第3回】ゼロから始めるゲノム解析 (Python編) Reverse Complement of DNA: String Manipulation @kimoton
本勉強会の概要・目的 書籍名 対象者/目的 Mastering Python for Bioinformatics Python・バイオインフォ知識ほぼゼロの人 を対象に、正しいPythonのコーディング手 法について学ぶ
頻度 毎週〜隔週開催予定 登壇者 募集中!
Rosalindとは • 問題解決を通じてバイオインフォマティク ス、プログラミング、およびアルゴリズムを 学習するためのプラットフォーム • 大学やハッカソン、就職の面接にも 600回 以上の採用実績あり 参考:https://qiita.com/_kimoton/items/d534d0fa9b83dd7dc412
概要
環境構築 - 必要パッケージ群のインストール # 公開されているレポジトリからファイル群を取得 $ git clone https://github.com/kyclark/biofx_python $
cd biofx_python # requirements.txt に記載のパッケージをインストール $ pip3 install -r requirements.txt # pylintの設定ファイルをホームディレクトリに移動 $ cp pylintrc ~/.pylintrc # mypyの設定ファイルをホームディレクトリに移動 $ cp mypy.ini ~/.mypy.ini
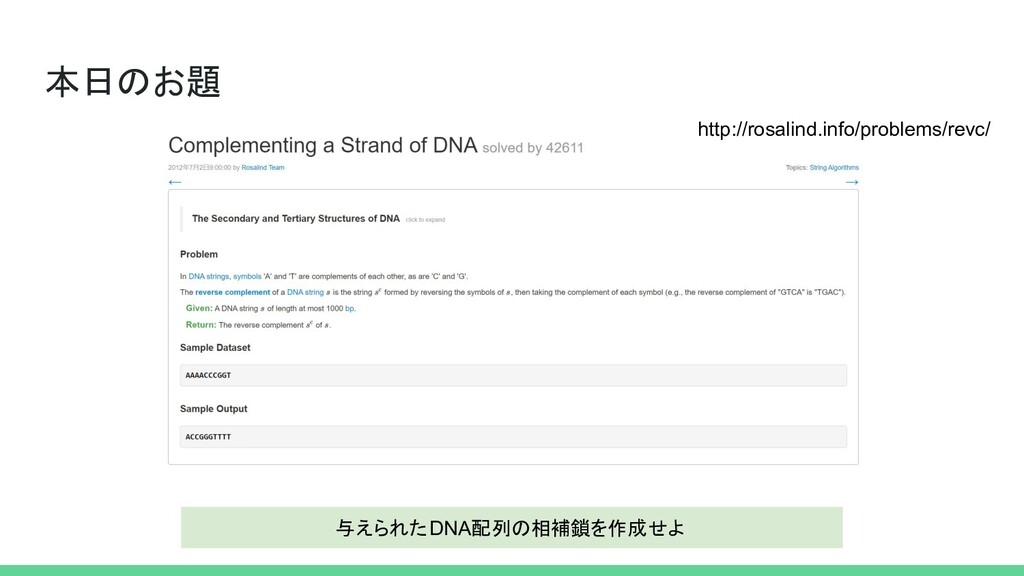
本日のお題 与えられたDNA配列の相補鎖を作成せよ http://rosalind.info/problems/revc/
本日学ぶこと • 動的な文字列生成の方法 • reversed() 関数の使い方 • リスト内包表記の使い方 • str.maketrans()
及び str.translate() の使い方 • Biopythonの Bio.Seqモジュールの使い方
解法編
逆相補鎖の作成 Step1 文字列を反転 Step2 相補鎖の生成 今回は、文字列の反転→相補鎖の生成という手順をとる
文字列を反転(リストのindexを使用) >>> dna = 'AAAACCCGGT' >>> dna[:2] 'AA' >>> dna[-2:]
'GT' 終了位置を指定しないと、最終文字列までの指定になる 開始位置を指定しないと、最初文字列からの指定になる >>> dna[::-1] 'TGGCCCAAAA' 第3の引数としてstep_sizeを指定可能。-1を指定すると、反転方向に並び替えることができる
文字列を反転(reversed() 関数を使用) >>> reversed(dna) <reversed object at 0x7ff4e5c2bf70> イテレータから取り出した反転文字列を空文字列を結合文字に用いて結合 reversed()
関数はイテレータを返す >>> ''.join(dna) 'TGGCCCAAAA' イテレータとは for 文などで要素を1つずつ取り出せるオ ブジェクトを指す
文字列を反転(forループを使用) >>> rev = '' >>> for base in reversed(dna):
... rev += base ... >>> rev 'TGGCCCAAAA' 1 2 3 2 反転文字列のイテレータから1文字 ずつbaseに格納 3 rev変数に追加 1 相補鎖を格納するrev変数を初期化
文字列を反転 → 相補鎖の生成 revc = '' for base in reversed(dna):
if base == 'A': revc += 'T' elif base == 'T': revc += 'A' elif base == 'G': revc += 'C' elif base == 'C': revc += 'G' elif base == 'a': revc += 't' elif base == 't': revc += 'a' elif base == 'g': revc += 'c' elif base == 'c': revc += 'g' else: revc += base 1 相補鎖を格納するrevc変数を初期化 2 反転文字列のイテレータから1文字 ずつbaseに格納 3 大文字/小文字の塩基に該当すれば相 補的な塩基をrevc変数に追加 1 2 3
解法 1 .forループとif/elifによる分岐を使用 • 塩基配列のlookupにif/elif/elseではなく辞書 型を使う • for文ではなくリスト内包表記を使用する • str.translate()
メソッドを使用する • Bio.Seq オブジェクトと付随する相補鎖生成 のためのメソッドを使用する 改善案
改善編
解法 2 辞書型を用いたlookup 1 相補鎖としてどの塩基を返すかを示した 辞書 2 3 2 相補鎖を格納するcomplement変数を初
期化 3 引数で与えたDNA文字列を1文字ずつ baseに格納 1 4 5 4 baseを相補鎖に変換した塩基を complement変数に追加 5 complement変数の文字列を反転した結 果を出力
リスト内包表記 for base in args.dna: trans.get(base, base) [trans.get(base, base) for
base in arg.dna] リスト内包表記を用いるとリスト内の要素に特定の処理を行った結果を一行で取得する ことができる。
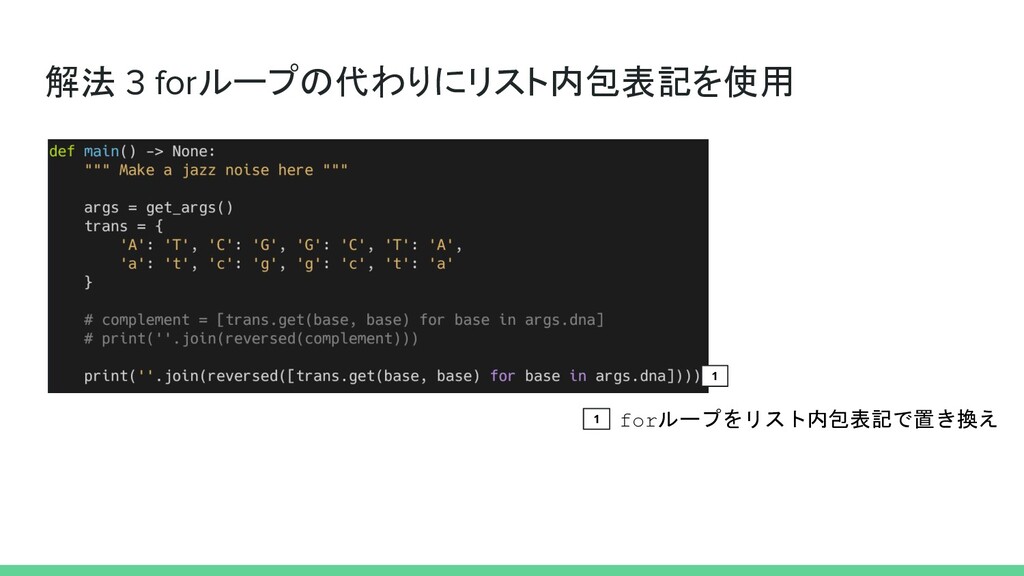
解法 3 forループの代わりにリスト内包表記を使用 1 forループをリスト内包表記で置き換え 1
str.translate() メソッド >>> trans = { ... 'A': 'T', 'C':
'G', 'G': 'C', 'T': 'A', ... 'a': 't', 'c': 'g', 'g': 'c', 't': 'a' ... } >>> str.maketrans(trans) {65: 'T', 67: 'G', 71: 'C', 84: 'A', 97: 't', 99: 'g', 103: 'c', 116: 'a'} >>> 'AAAACCCGGT'.translate(str.maketrans(trans)) 'TTTTGGGCCA' str.maketrans() メソッドはkeyがASCIIコードとなった辞書型を作成する str.translate() メソッドはkeyがASCIIコードとなった辞書型を引数にとり、文字列を変換する # 文字 → ASCIIコード >>> ord('A') 65 # ASCIIコード → 文字 >>> chr(65) 'A'
(参考)ASCIIコード表
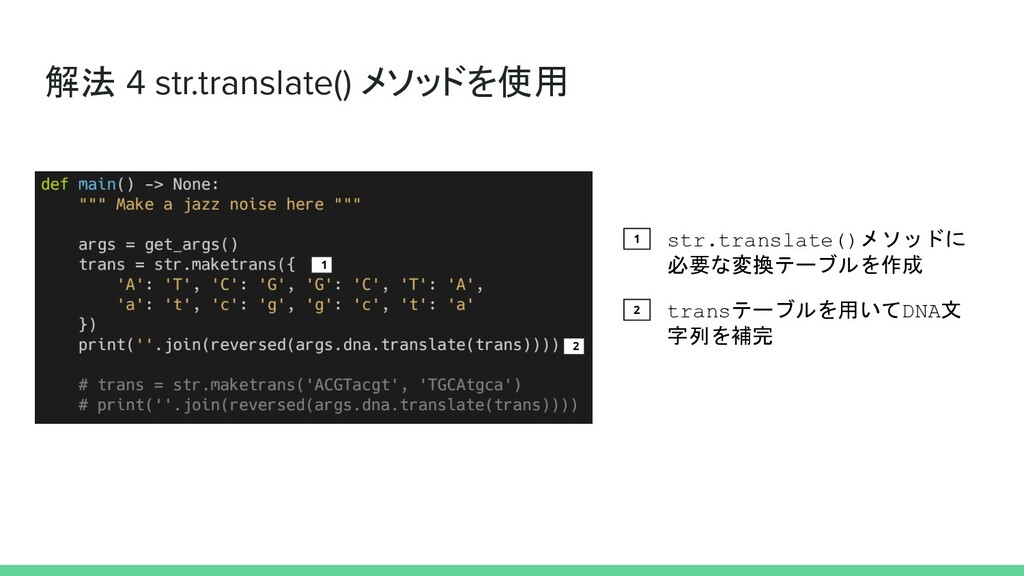
解法 4 str.translate() メソッドを使用 1 str.translate()メソッドに 必要な変換テーブルを作成 2 transテーブルを用いてDNA文 字列を補完
2 1
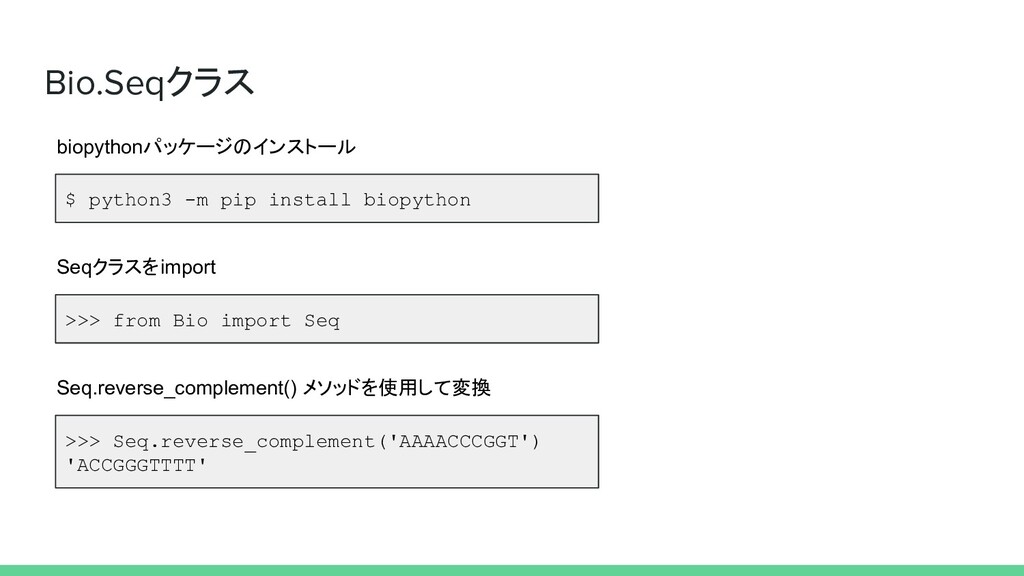
Bio.Seqクラス $ python3 -m pip install biopython biopythonパッケージのインストール >>> from
Bio import Seq Seqクラスをimport >>> Seq.reverse_complement('AAAACCCGGT') 'ACCGGGTTTT' Seq.reverse_complement() メソッドを使用して変換
解法 5 Bio.Seqクラスを使用 1 Seq.reverse_complement メソッドを使用して変換 1
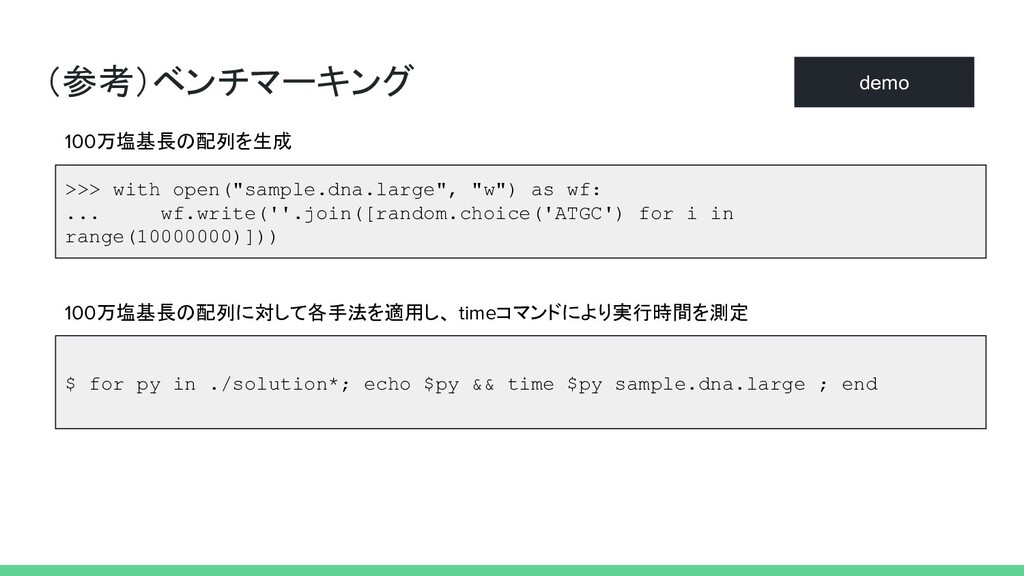
(参考)ベンチマーキング 100万塩基長の配列を生成 demo >>> with open("sample.dna.large", "w") as wf: ...
wf.write(''.join([random.choice('ATGC') for i in range(10000000)])) $ for py in ./solution*; echo $py && time $py sample.dna.large ; end 100万塩基長の配列に対して各手法を適用し、 timeコマンドにより実行時間を測定
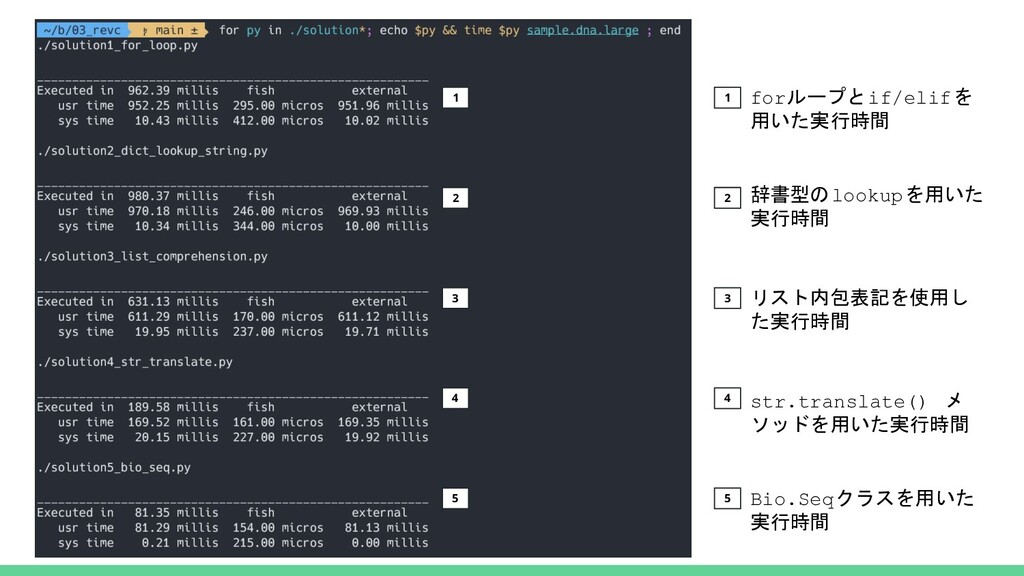
1 2 3 4 5 1 2 3 4 5
Bio.Seqクラスを用いた 実行時間 forループとif/elifを 用いた実行時間 str.translate() メ ソッドを用いた実行時間 リスト内包表記を使用し た実行時間 辞書型のlookupを用いた 実行時間
本日学んだこと • if/elseを用いる/辞書を用いたlookupにより決定木を実装できる • 文字列とリストはいずれもforループでイテレーションできる、+=オペレータで追加できる 点で似ている • reversed() 関数はイテレータを返す遅延評価関数 •
str.maketrans() 及び str.translate() を使うと文字列の置換を効率的に行うことができ る • Biopythonはバイオインフォマティクスに利用される関数群が含まれたパッケージ • Bio.Seq.reverse_complementメソッドを用いると相補鎖を作成することができる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![文字列を反転(リストのindexを使用) >>> dna = 'AAAACCCGGT' >>> dna[:2] 'AA' >>> dna[-2:]](https://files.speakerdeck.com/presentations/c0d330230e27474bbda6334d6b6b5852/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}