Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
【第1回】ゼロから始めるゲノム解析(Python編).pdf
Search
nkimoto
November 05, 2021
Technology
940
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
【第1回】ゼロから始めるゲノム解析(Python編).pdf
2021/11/05 (金) 【第1回】ゼロから始めるゲノム解析(Python編) 資料
nkimoto
November 05, 2021
More Decks by nkimoto
See All by nkimoto
Location Restriction Sites: Using, Testing, and Sharing Code
nkimoto
0
380
Finding a Protein Motif: Fetching Data and Using Regular Expressions
nkimoto
0
350
Overlap Graphs: Sequence Assembly Using Shared K-mers
nkimoto
0
240
Computing GC Content: Parsing FASTA and Analyzing Sequences
nkimoto
0
330
【第5回】ゼロから始めるゲノム解析(Python編)
nkimoto
0
760
【第3回】ゼロから始めるゲノム解析(Python編)
nkimoto
0
470
【第7回】ゼロから始めるゲノム解析.pdf
nkimoto
0
490
【第5回】ゼロから始めるゲノム解析(R編)
nkimoto
0
600
【第3回】ゼロから始めるゲノム解析(R編)
nkimoto
0
1.6k
Other Decks in Technology
See All in Technology
ヘルスケア領域における AI 活用と その安全性担保のための取り組み (Leveraging AI in Healthcare and Our Efforts to Ensure Its Safety) - Google I/O Extended Tokyo 2026, July 11, 2026
zettaittenani
0
230
Kotlin 開発のツラミを爆破した話! / Explode the difficulty of Kotlin dev!
eller86
0
160
最適な自走を最小限の支援で — M&Aで拡大する組織で少人数SREが挑んだ1年 / SRE NEXT 2026
genda
0
710
生成AIの活用/high_school2026
okana2ki
0
110
テスト設計の本質を改めて考えてみる~生成AIを活用する時代だからこそ、作ったテストの説明性を高めよう~
yamasaki696
1
410
『AIに負けない』より『AIと遊ぶ』」〜ワクワクが最強のテスト・QA学習戦略_公開用
odan611
2
550
[2026-07-15] AI Ready なはずだったアーキテクチャと、見えてきた課題・次に目指す状態
wxyzzz
2
590
インフラ寄りSREでも 開発に踏み出せる〜境界を越えてユーザー体験に向き合いたい〜
sansantech
PRO
2
3.2k
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
金融の未来を考える / Thinking About the Future of Finance
ks91
PRO
0
180
【Claude Code】鹿野さんに聞く 私の推しの並行開発環境 大公開 / claude-code-parallel-2026-07-15
tonkotsuboy_com
5
1.4k
プロダクトだけじゃない、社内プロセスにおける自動化・省力化ノススメ
kakehashi
PRO
1
3.2k
Featured
See All Featured
The Cult of Friendly URLs
andyhume
79
6.9k
Optimising Largest Contentful Paint
csswizardry
37
3.8k
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
220
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
240
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
150
The Pragmatic Product Professional
lauravandoore
37
7.4k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.6k
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
210
Writing Fast Ruby
sferik
630
63k
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
370
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
760
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
Transcript
【第1回】ゼロから始めるゲノム解析 (Python編) Tetranucleotide Frequency: Counting Things
本勉強会の概要・目的 書籍名 対象者/目的 Mastering Python for Bioinformatics Python・バイオインフォ知識ほぼゼロの人 を対象に、正しいPythonのコーディング手 法について学ぶ
頻度 隔週開催予定 登壇者 募集中!
Rosalindとは • 問題解決を通じてバイオインフォマティク ス、プログラミング、およびアルゴリズムを 学習するためのプラットフォーム • 大学やハッカソン、就職の面接にも 600回 以上の採用実績あり 参考:https://qiita.com/_kimoton/items/d534d0fa9b83dd7dc412
概要
環境構築 - 必要パッケージ群のインストール # 公開されているレポジトリからファイル群を取得 $ git clone https://github.com/kyclark/biofx_python $
cd biofx_python # requirements.txt に記載のパッケージをインストール $ pip3 install -r requirements.txt # pylintの設定ファイルをホームディレクトリに移動 $ cp pylintrc ~/.pylintrc # mypyの設定ファイルをホームディレクトリに移動 $ cp mypy.ini ~/.mypy.ini demo
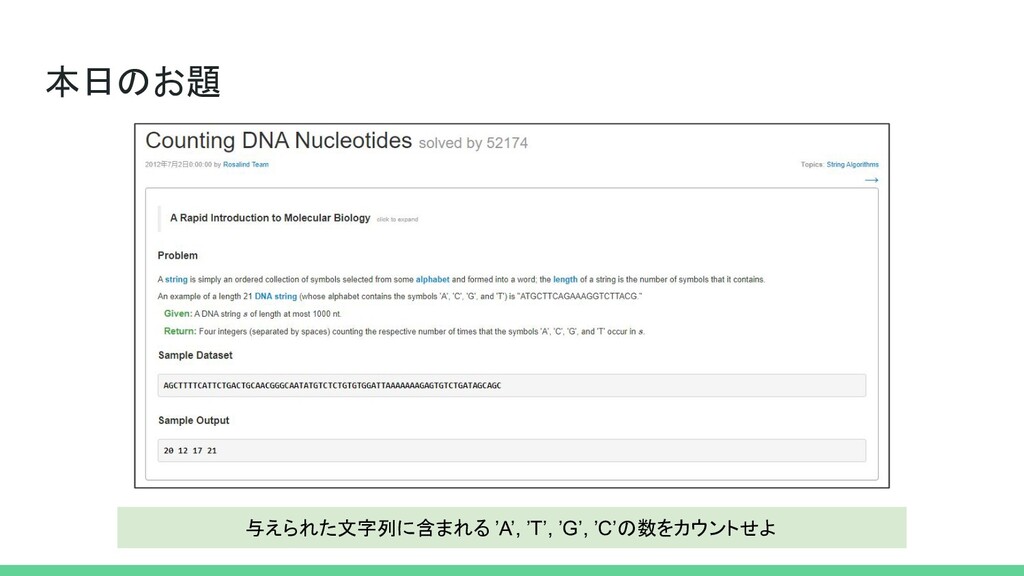
本日のお題 与えられた文字列に含まれる ’A’, ’T’, ’G’, ’C’の数をカウントせよ
本日学ぶこと • argparseを用いたコマンドライン引数の利用、型チェック • テスト駆動開発(TDD)について • pytestを用いたテストの書き方 • 文字列のイテレーションの仕方 •
文字列に含まれる要素のカウント方法 • if/elifを用いた決定木の作り方 • 文字列への変数代入の方法
前提知識編
linterを使ったコードの静的解析 demo 特徴 出力例 • pep8のチェック、pyflakesのチェック、 及び循環的複雑度をチェックできる • オプションやプラグインが豊富でカスタ マイズの幅が広い
• githubスター数 1.6k • $ flake8 [ファイル名] で実行 flake8 • 老舗のツール。effective pythonで推奨 されている • VSCodeのデフォルトのlinter • githubスター数 3.6k • $ pylint [ファイル名] で実行 pylint sample.py:1:1: F401 'time' imported but unused sample.py:5:1: E302 expected 2 blank lines, found 1 sample.py:5:15: E231 missing whitespace after ',' sample.py:7:5: F841 local variable 'varC' is assigned to but never used C: 5, 0: Exactly one space required after comma def func1(varA,varB): ^ (bad-whitespace) C: 8, 0: Unnecessary parens after 'return' keyword C: 1, 0: Missing module docstring 殆どのエディターで対応する構文チェッカーが存在 (vimの場合、syntastic等)
argparseとは Pythonの実行時にコマンドライン引数を取りたい場合に使用する $ python dna.py --help usage: dna.py [-h] DNA
Tetranucleotide frequency positional arguments: DNA Input DNA sequence optional arguments: -h, --help show this help message and exit dna.pyでは、 位置引数として DNA オプション引数として --help が定義されている
argparseの定義の仕方 1 get_args()関数の中で引数解析 2 引数として受け取りたい変数名及び ヘルプメッセージにおける記載を定義 1 2 3 3
parse_args()メソッドで引数を解析 4 4 コマンドライン引数で受け取った値が 属性値で使用できるようになる
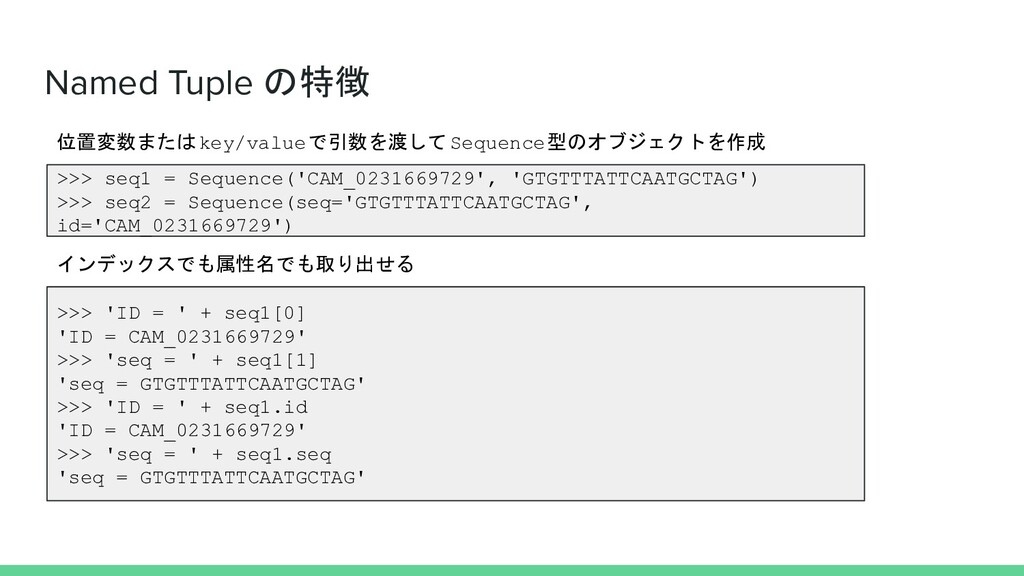
Named Tuple >>> from typing import NamedTuple >>> class Sequence(NamedTuple):
... id: str ... seq: str ... NamedTupleの作成 >>> type(Sequence) <class 'type'> NamedTupleはtype型のオブジェクト 参考:https://docs.python.org/ja/3/library/collections.html#collections.namedtuple NamedTupleを使うと その構造が持つ属性の型を定義することがで きる → 静的型チェッカーによる異常検出が可能
Named Tuple の特徴 >>> seq1 = Sequence('CAM_0231669729', 'GTGTTTATTCAATGCTAG') >>> seq2
= Sequence(seq='GTGTTTATTCAATGCTAG', id='CAM_0231669729') 位置変数またはkey/valueで引数を渡してSequence型のオブジェクトを作成 >>> 'ID = ' + seq1[0] 'ID = CAM_0231669729' >>> 'seq = ' + seq1[1] 'seq = GTGTTTATTCAATGCTAG' >>> 'ID = ' + seq1.id 'ID = CAM_0231669729' >>> 'seq = ' + seq1.seq 'seq = GTGTTTATTCAATGCTAG' インデックスでも属性名でも取り出せる
Named Tupleとargparseを用いたプログラム構成 1 1 get_args()関数の中で引数解析 2 2 Argsクラス(NamedTuple)に変換 3 Argsクラスはstr属性のdnaを持つと定義
しているため、数値演算を行う構文がある とmypy等の静的型チェッカーでエラーが 出る 3 4 慣習的に、プログラムを直接実行された場 合、main()関数を実行する構成とする 4
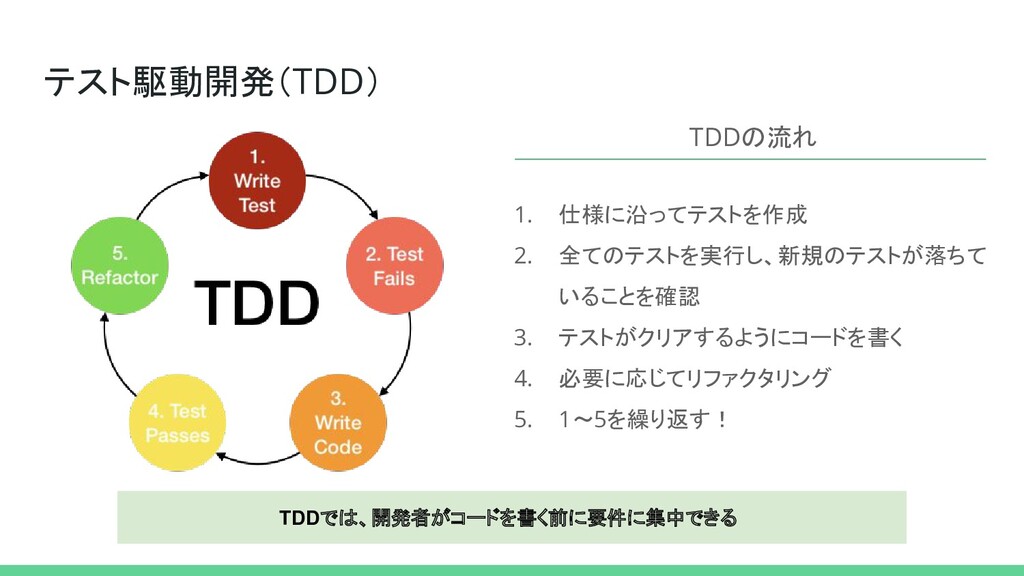
テスト駆動開発(TDD) 1. 仕様に沿ってテストを作成 2. 全てのテストを実行し、新規のテストが落ちて いることを確認 3. テストがクリアするようにコードを書く 4. 必要に応じてリファクタリング
5. 1~5を繰り返す! TDDの流れ TDDでは、開発者がコードを書く前に要件に集中できる
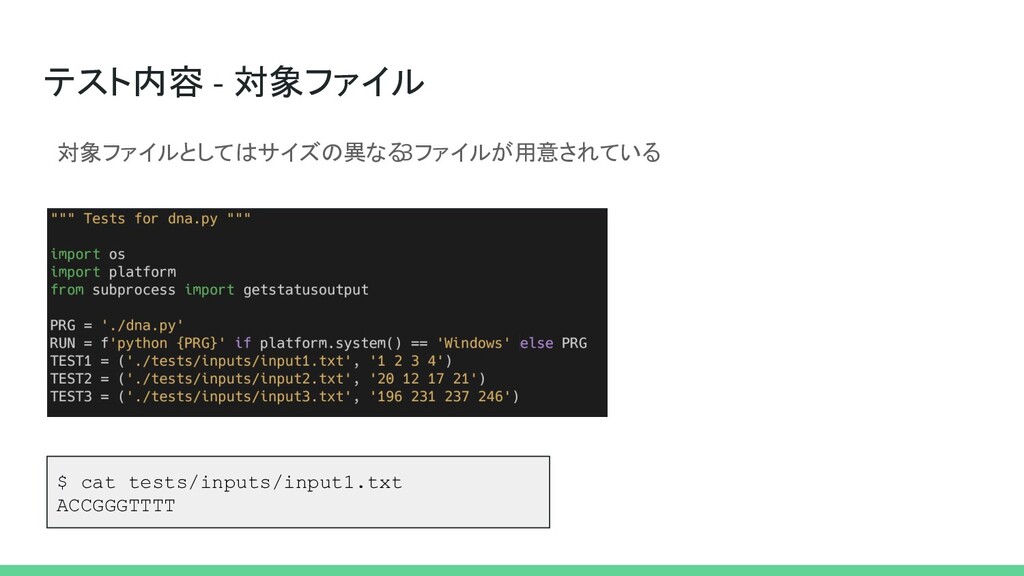
テスト内容 - 対象ファイル 対象ファイルとしてはサイズの異なる 3ファイルが用意されている $ cat tests/inputs/input1.txt ACCGGGTTTT
テスト内容 - test_exists() test_exists()関数では、PRGで定義したプログラムファイルが存在することを確認
テスト内容 - test_usage() test_usage()関数では、ヘルプメッセージの出力が正常に完了していること、 及びヘルプメッセージが「usage:」から始まっていることを確認
テスト内容 - test_dies_no_args() test_dies_no_args()関数では、引数なしで実行すると異常終了すること、 及び「usage:」から始まっているヘルプメッセージが表示されることを確認
テスト内容 - test_arg() test_arg()関数では、引数に文字列を指定して実行した場合に、 それぞれの想定される結果が出力されることを確認
テスト内容 - test_file() test_file()関数では、引数にファイルパスを指定して実行した場合に、 それぞれの想定される結果が出力されることを確認
テストが通らないことを確認してからコーディング $ pytest -xv --pylint --flake8 --mypy tests/dna_test.py
解答編
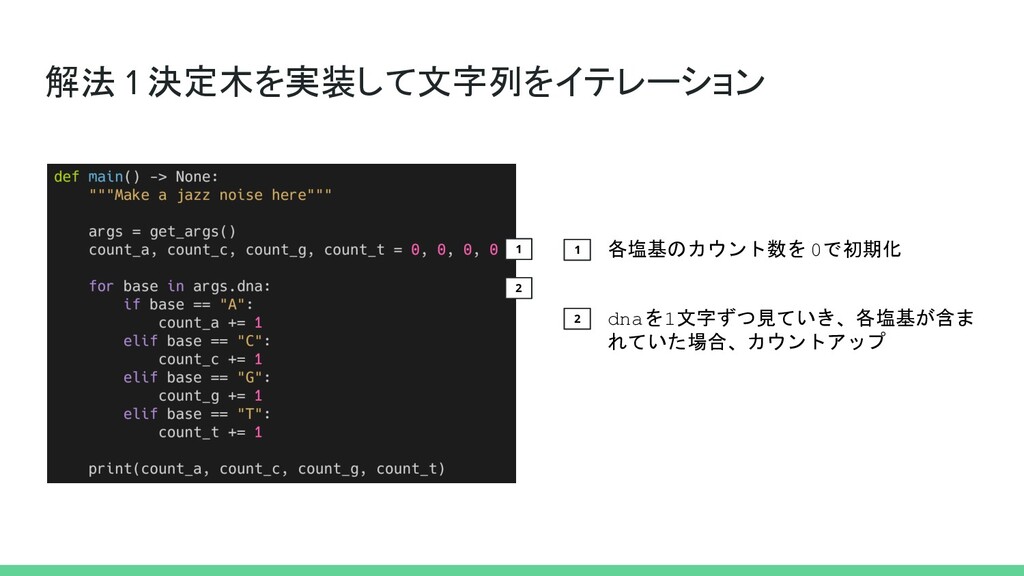
解法 1 決定木を実装して文字列をイテレーション 1 2 1 2 各塩基のカウント数を 0で初期化 dnaを1文字ずつ見ていき、各塩基が含ま
れていた場合、カウントアップ
(参考)文字列のイテレーション >>> dna = 'ACGT' >>> for base in dna:
... print(base) ... A C G T 文字列のイテレーション例 1 2 1 2 dna文字列の各文字はbase変数にコピー される print()関数は改行を追加するため、各 塩基は別の行として出力される
解法 2 count() 関数の作成 & 単体テストの追加 1 2 1 2
型ヒントで、count()関数は文字列を入 力値として受け、4つの整数値が入ったタ プルを返すことを定義 カウント部分はmain()関数からcount() 関数に異動 関数化のメリット: • main()関数の可読性が高くなる • 関数ごとに機能のテスト(単体テスト)が 書ける
(参考)format() メソッドによる変数代入 1 1 format()メソッドに求められている 4つ の値にcount(args.dna) の結果を格納 format()メソッドでは、「{}」で表記した テンプレートに対応する順序で変数を代入す
る ※「{}」の数と引数の数は揃える必要がある
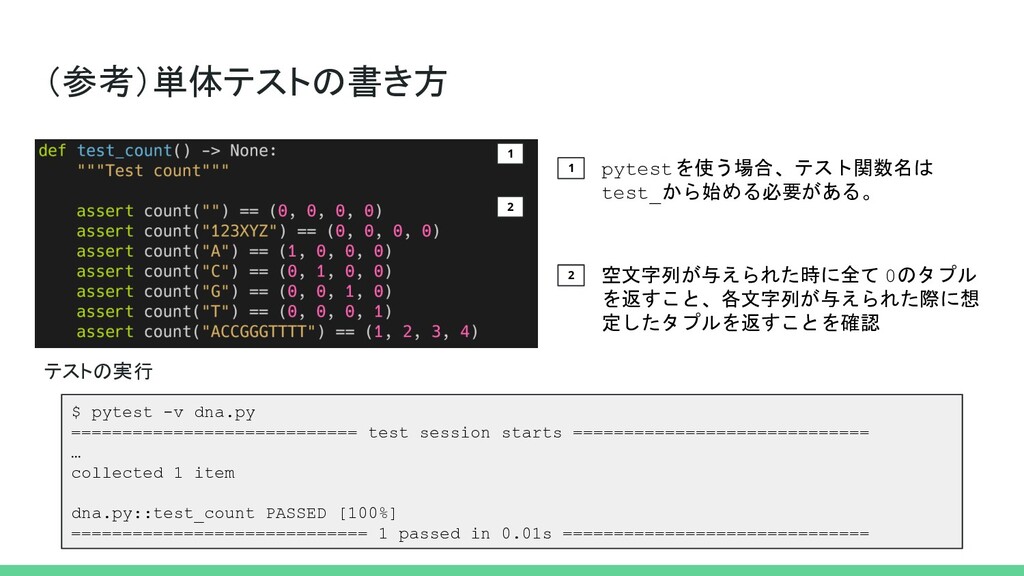
(参考)単体テストの書き方 1 2 1 2 pytestを使う場合、テスト関数名は test_から始める必要がある。 空文字列が与えられた時に全て 0のタプル を返すこと、各文字列が与えられた際に想
定したタプルを返すことを確認 $ pytest -v dna.py ============================ test session starts ============================= … collected 1 item dna.py::test_count PASSED [100%] ============================= 1 passed in 0.01s ============================== テストの実行
解法 3 str.count()メソッドの利用 1 2 1 2 count()関数は文字列を入力値として 受け、4つの整数値が入ったタプルを 返すことを定義
文字列型の.count()メソッドを呼び 出してカウント
(参考)f文字列による変数代入 >>> seq = 'ACGT' >>> f'The sequence "{seq}" has
{len(seq)} bases.' 'The sequence "ACGT" has 4 bases.' f文字列の使い方例 1 2 1 2 4つのカウント値を count_変数に格 納 f文字列を使った変数代入 format()メソッドと比較して 可読性が高いため、基本的に はf文字列を利用すべき
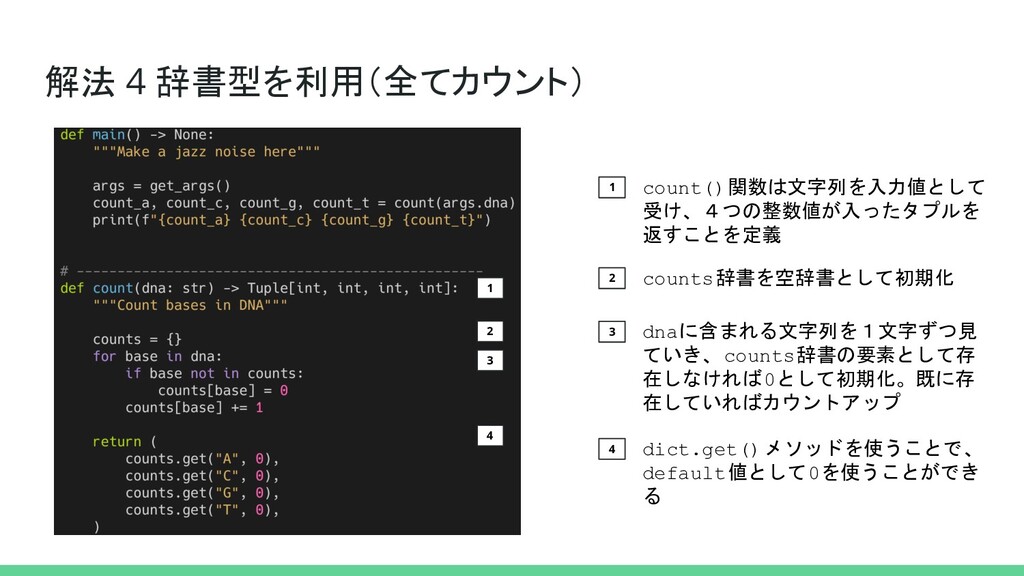
解法 4 辞書型を利用(全てカウント) 1 2 count()関数は文字列を入力値として 受け、4つの整数値が入ったタプルを 返すことを定義 counts辞書を空辞書として初期化 3
dnaに含まれる文字列を1文字ずつ見 ていき、counts辞書の要素として存 在しなければ0として初期化。既に存 在していればカウントアップ 1 2 3 4 4 dict.get()メソッドを使うことで、 default値として0を使うことができ る
解法 5 辞書型を利用(カウント対象のみカウント) 1 2 1 2 count()関数は文字列を入力値として 受け、Keyが文字列、Valueが整数型 の辞書を返す関数として定義
counts辞書を4つの塩基について カウント数0で初期化 3 3 dnaに含まれる文字列を1文字ずつ見 ていき、counts辞書の要素があれば カウントアップ
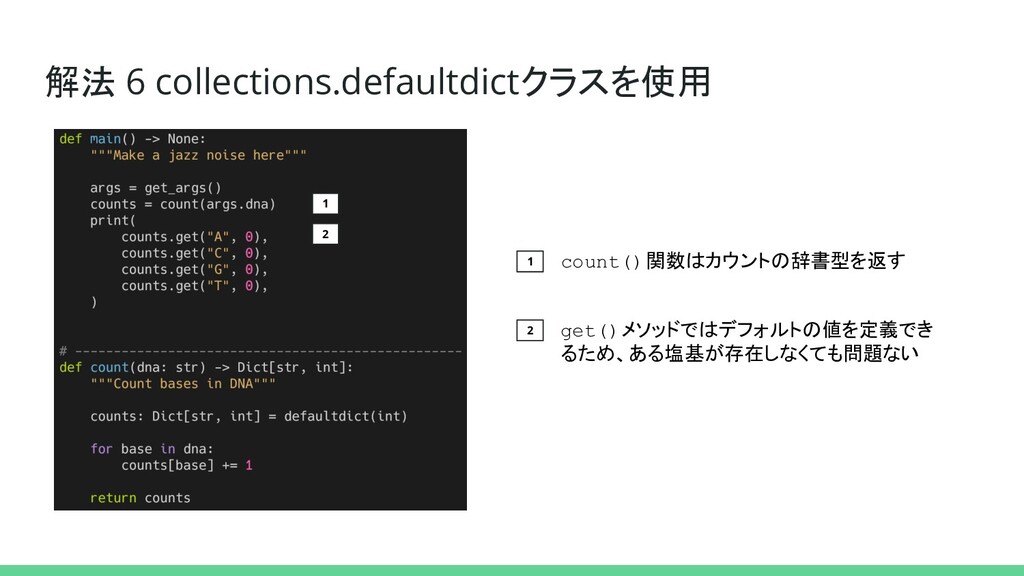
解法 6 collections.defaultdictクラスを使用 1 2 count()関数はカウントの辞書型を返す get()メソッドではデフォルトの値を定義でき るため、ある塩基が存在しなくても問題ない 実装 1
2 1 2
(参考)collections.defaultdictクラス >>> from collections import defaultdict >>> counts = defaultdict(int)
>>> counts['A'] 0 >>> counts['C'] += 1 >>> counts defaultdict(<class 'int'>, {'A': 0, 'C': 1}) defaultdictクラスの使い方例 参考:https://docs.python.org/ja/3.6/library/collections.html#collections.defaultdict
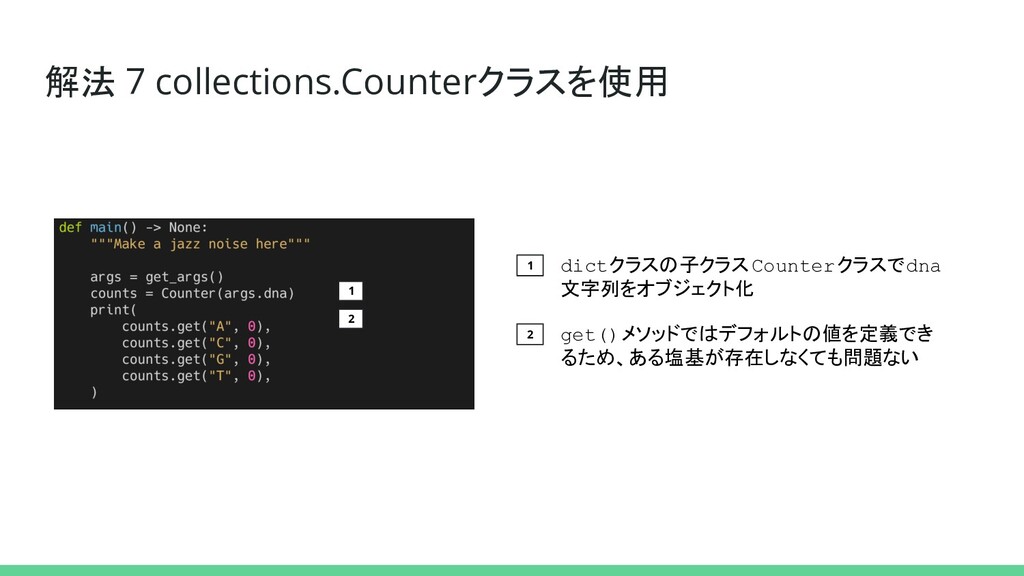
解法 7 collections.Counterクラスを使用 1 2 dictクラスの子クラスCounterクラスでdna 文字列をオブジェクト化 get()メソッドではデフォルトの値を定義でき るため、ある塩基が存在しなくても問題ない 1
2
(参考)collections.Counterクラス 参考:https://docs.python.org/ja/3/library/collections.html#collections.namedtuple >>> from collections import Counter >>> Counter('ACCGGGTTT') Counter({'G':
3, 'T': 3, 'C': 2, 'A': 1}) Counterクラスの使い方例
追加課題 Q. 植物のゲノムなど繰り返し配列が含まれるサンプルの場合、繰り返し配列は小文字 で表記される。小文字が含まれる場合でも動作するようにするにはどうすれば良いか。
追加課題 - TDDに沿ったコーディングの流れ 1. 大文字と小文字が混在する入力ファイルを用意 2. test/dna_test.pyに用意したファイルを入力として新規のテストを作成 3. 全てのテストを実行し、新規のテストが落ちていることを確認 4.
プログラムを修正 5. テストを走らせる 6. テストが走るようにリファクタリング 7. 1~6を繰り返す! demo
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![argparseとは Pythonの実行時にコマンドライン引数を取りたい場合に使用する $ python dna.py --help usage: dna.py [-h] DNA](https://files.speakerdeck.com/presentations/370a1483173341a0b6894fdd2542af92/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}