for n in range(0, len(rna)-2)] ['AUG', 'UGG', 'GGC', 'GCC', 'CCA', 'CAU', 'AUG', 'UGG', 'GGC', 'GCG', 'CGC', 'GCC', 'CCC', 'CCA', 'CAG', 'AGA', 'GAA', 'AAC', 'ACU', 'CUG', 'UGA', 'GAG', 'AGA', 'GAU', 'AUC', 'UCA', 'CAA', 'AAU', 'AUA', 'UAG', 'AGU', 'GUA', 'UAC', 'ACC', 'CCC', 'CCG', 'CGU', 'GUA', 'UAU', 'AUU', 'UUA', 'UAA', 'AAC', 'ACG', 'CGG', 'GGG', 'GGU', 'GUG', 'UGA']
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
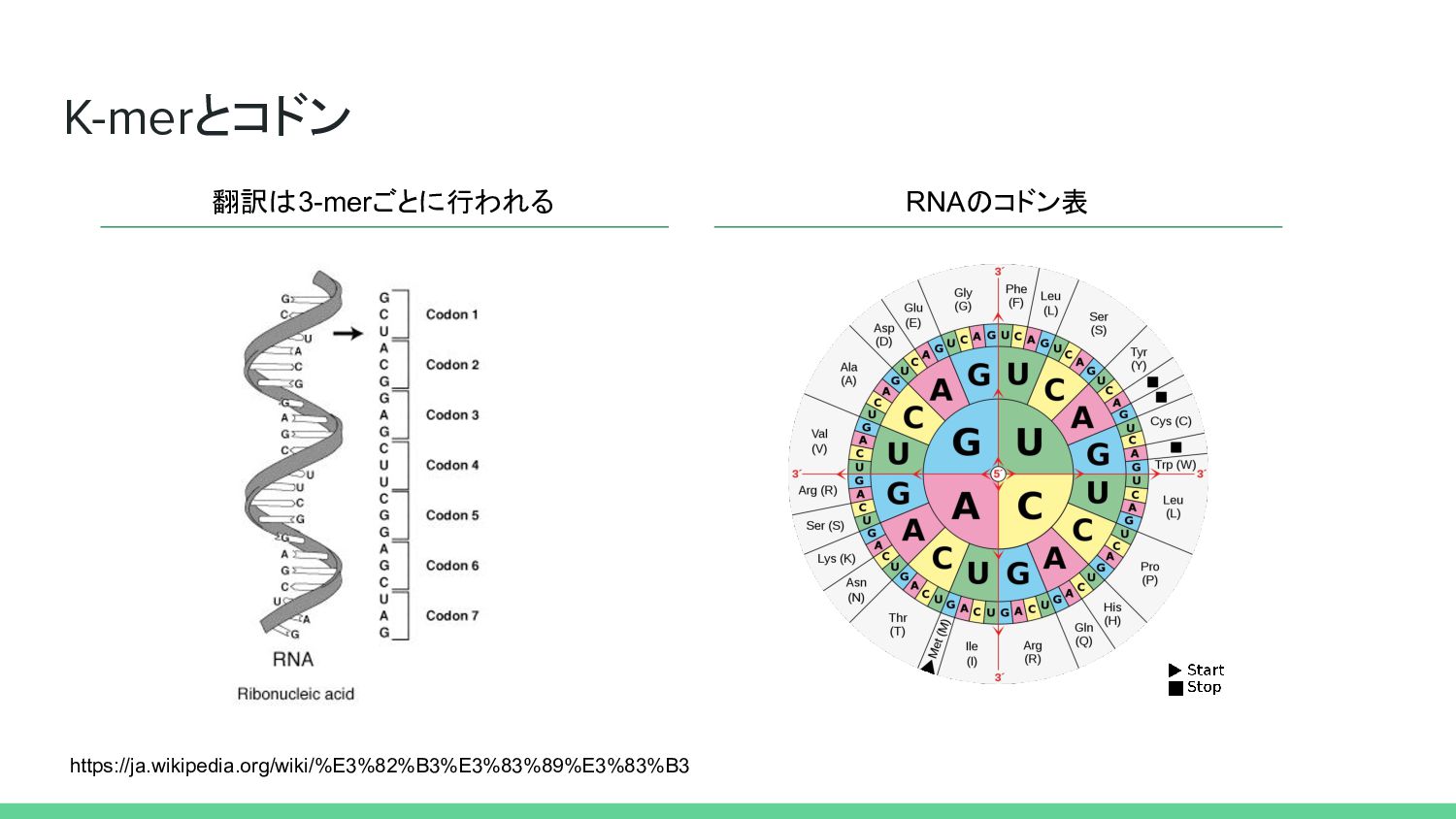{kind=link}
![文字列スライスを使った3-merごとの抽出 文字列スライスでインデックスを3飛ばしずつ読むことで3-merの抽出ができる >>> rna = 'AUGGCCAUGGCGCCCAGAACUGAGAUCAAUAGUACCCGUAUUAACGGGUGA' >>> rna[0:3] 'AUG' >>>](https://files.speakerdeck.com/presentations/8ebbcf2677c04aefa5a4c280a4e276d5/slide_8.jpg){kind=link}
{kind=link}
![(参考)K-merの抽出 同様の処理でK-mer全てを抽出することができる >>> rna = 'AUGGCCAUGGCGCCCAGAACUGAGAUCAAUAGUACCCGUAUUAACGGGUGA' >>> [rna[n:n + 3]](https://files.speakerdeck.com/presentations/8ebbcf2677c04aefa5a4c280a4e276d5/slide_10.jpg){kind=link}
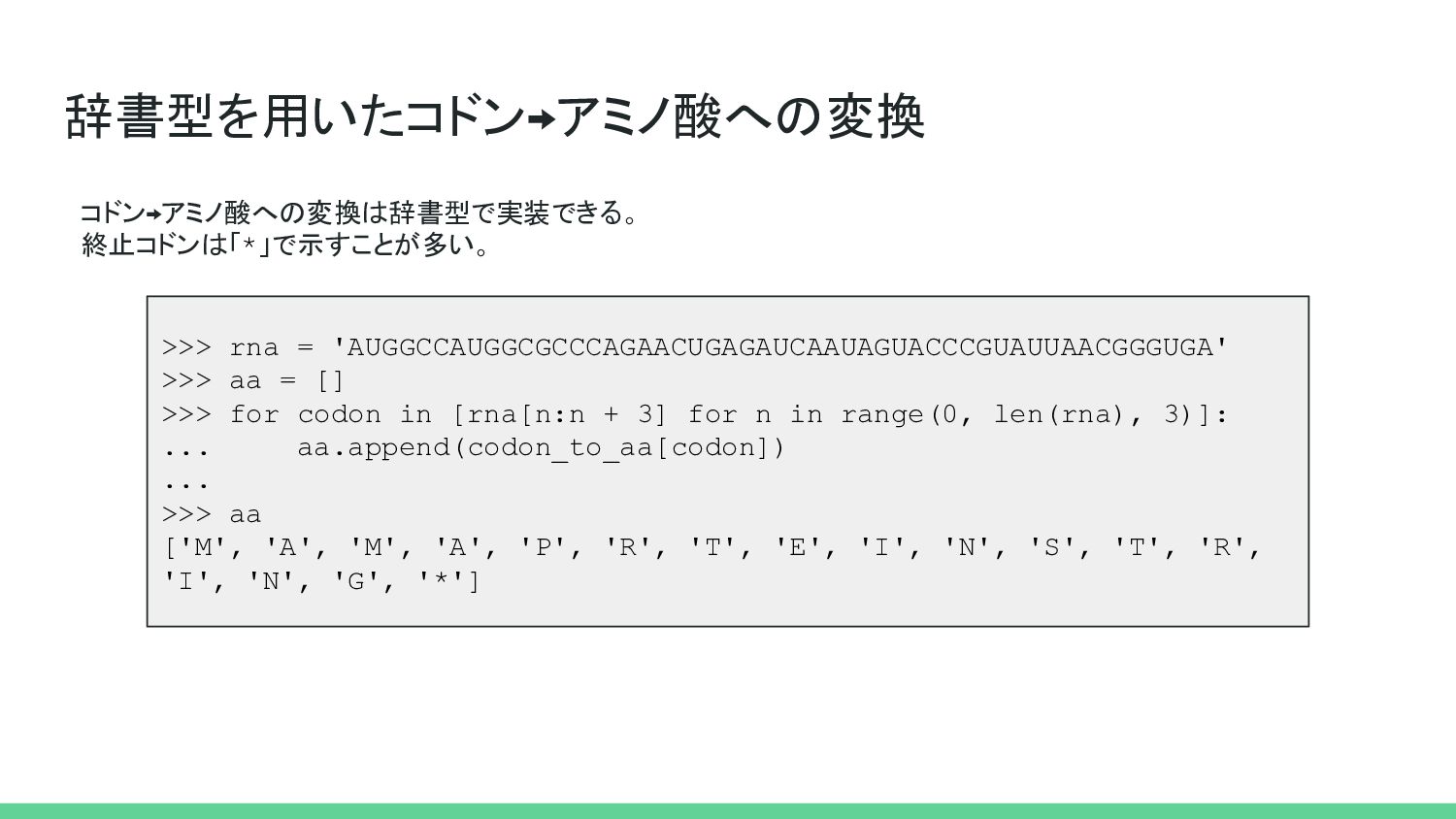{kind=link}
{kind=link}
{kind=link}
{kind=link}
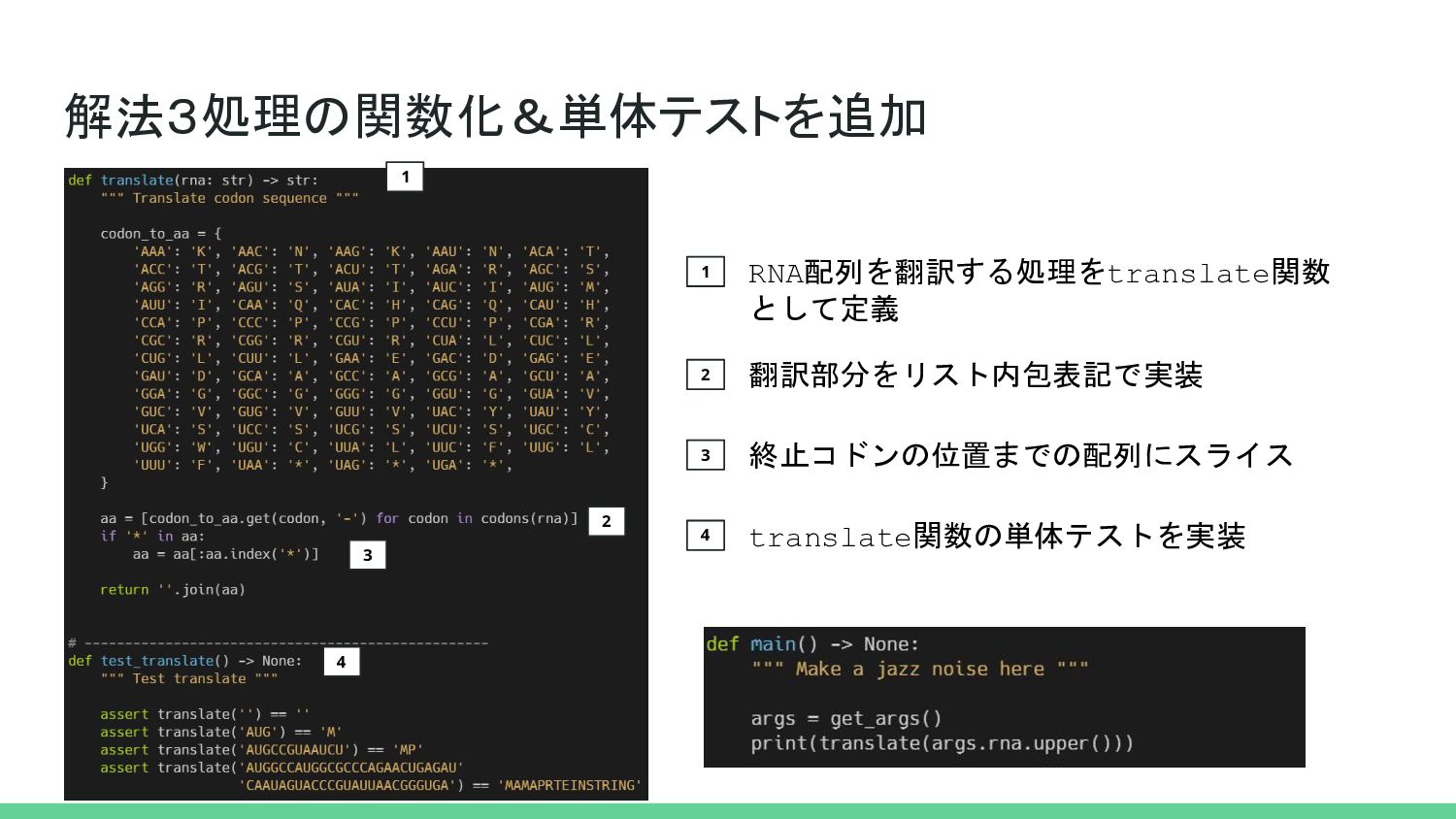{kind=link}
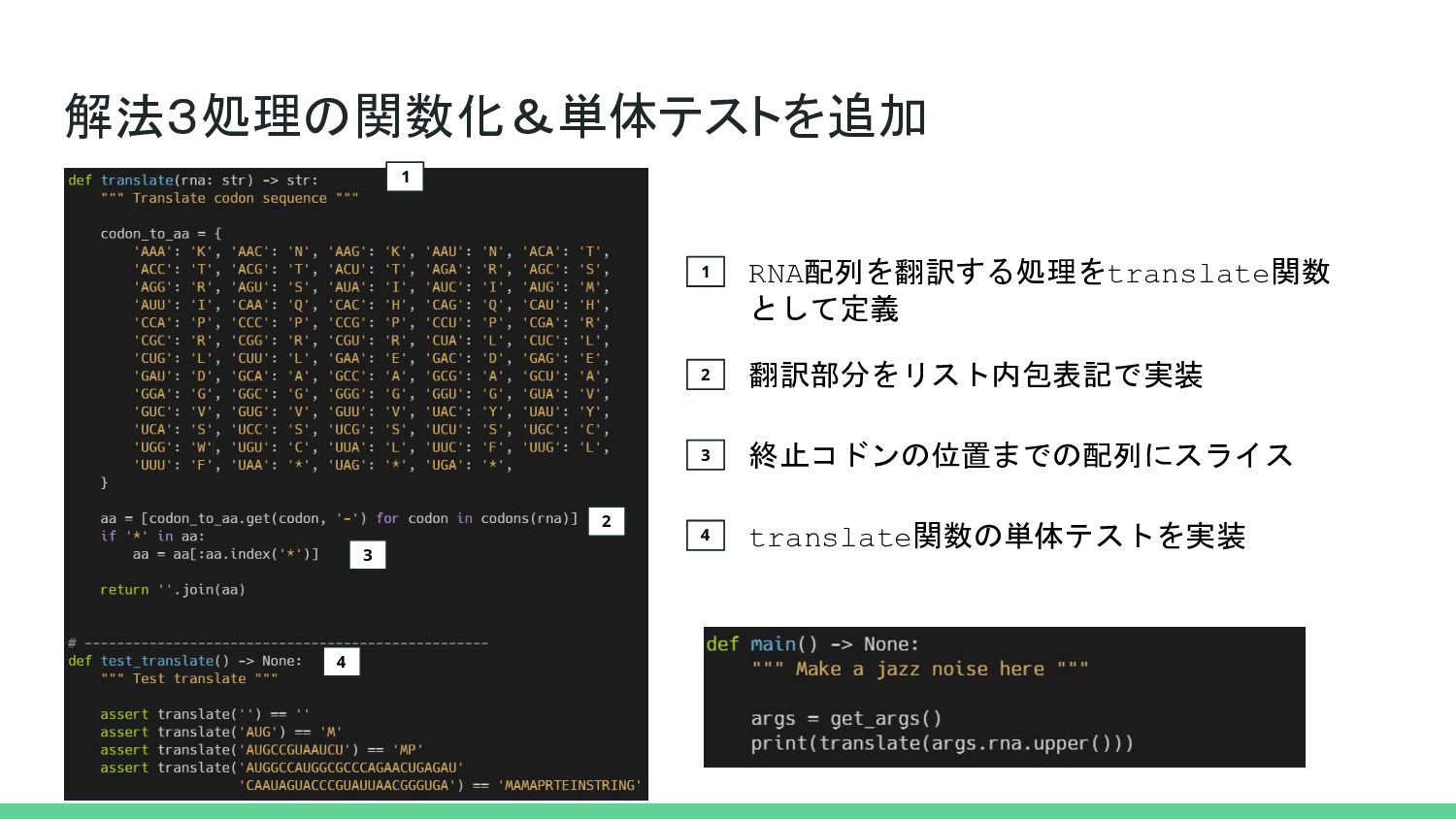{kind=link}
{kind=link}
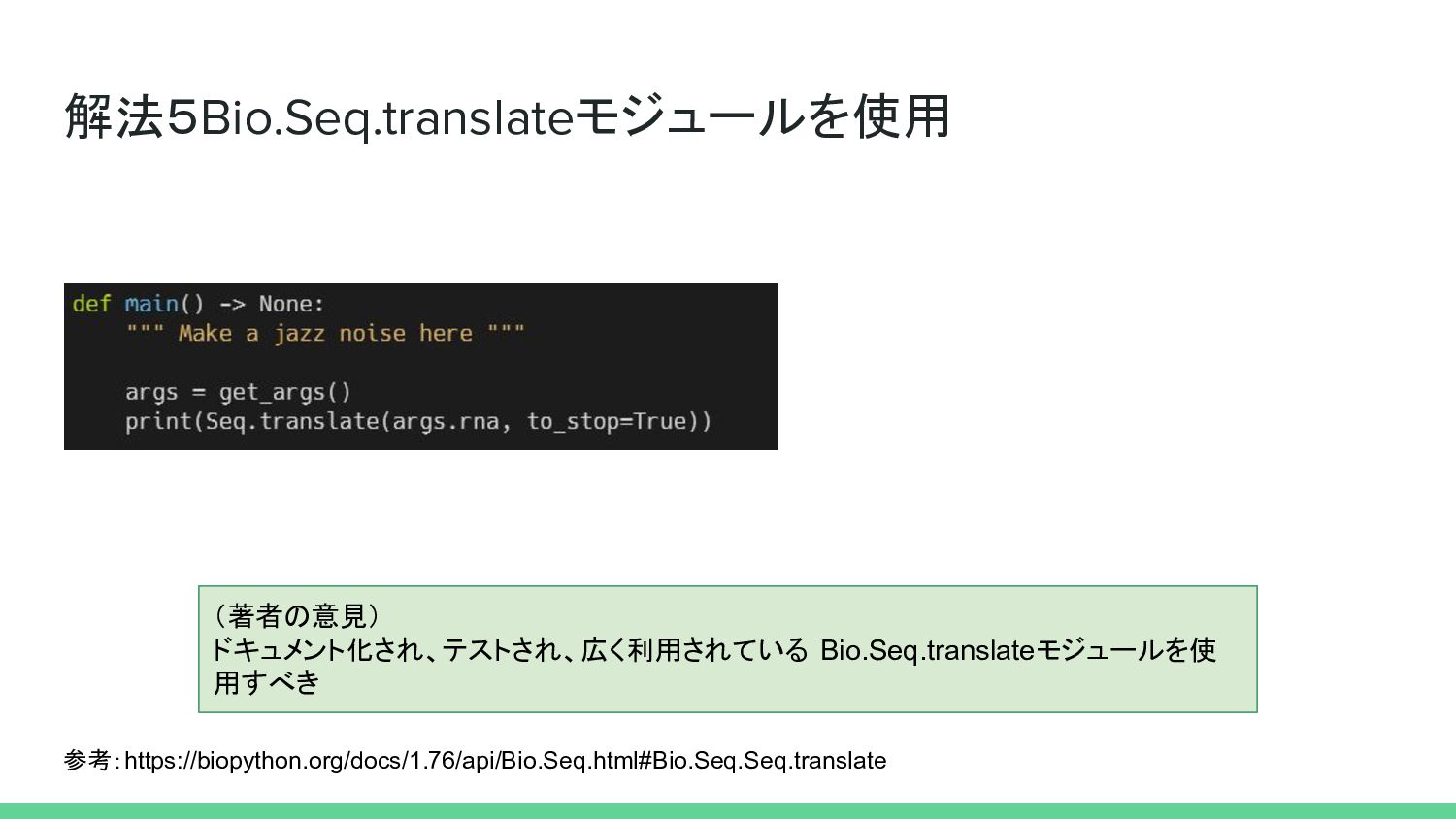{kind=link}
{kind=link}