Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Finding a Protein Motif: Fetching Data and Usin...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
nkimoto
February 18, 2022
Programming
350
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Finding a Protein Motif: Fetching Data and Using Regular Expressions
2022/02/18 (金) 【第11回】ゼロから始めるゲノム解析(Python編) 資料
nkimoto
February 18, 2022
More Decks by nkimoto
See All by nkimoto
Location Restriction Sites: Using, Testing, and Sharing Code
nkimoto
0
380
Overlap Graphs: Sequence Assembly Using Shared K-mers
nkimoto
0
240
Computing GC Content: Parsing FASTA and Analyzing Sequences
nkimoto
0
330
【第5回】ゼロから始めるゲノム解析(Python編)
nkimoto
0
760
【第3回】ゼロから始めるゲノム解析(Python編)
nkimoto
0
470
【第1回】ゼロから始めるゲノム解析(Python編).pdf
nkimoto
0
940
【第7回】ゼロから始めるゲノム解析.pdf
nkimoto
0
490
【第5回】ゼロから始めるゲノム解析(R編)
nkimoto
0
600
【第3回】ゼロから始めるゲノム解析(R編)
nkimoto
0
1.6k
Other Decks in Programming
See All in Programming
【SRE NEXT 2026 Lunch Session】一人目専任SREの立ち上げを加速する ― AIと進めたオンボーディングで2分を0.04秒にした話
pkshadeck
PRO
0
3k
Claude Team Plan導入・ガイド
tk3fftk
0
220
才能?センス?知らん、 続けたもん勝ちだ。-- 結婚・出産・癌を越えてなお、私がプロダクトを創り続ける理由
16bitidol
2
900
鹿野さんに聞く!『TypeScriptコードレシピ集』で磨く実践力
tonkotsuboy_com
4
1.1k
AIが無かった頃の素敵な出会いの話
codmoninc
1
200
初めてのKubernetes 本番運用でハマった話
oku053
0
130
GitHubCopilotCLIのスラッシュコマンドを自作してみる
htkym
0
100
音楽のための関数型プログラミング言語mimiumにおける多段階計算の活用
tomoyanonymous
1
350
Apache Hive: そしてCloud Native Lakehouseへ
okumin
1
160
PHPだって関数型したい 〜できること、できないこと〜 / fp-in-php
jsoizo
1
240
SLOをサービス品質の共通言語にするために 取り組んできたこと
wakana0222
0
540
Apache Hive: Toward a Cloud Native Lakehouse
okumin
0
160
Featured
See All Featured
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Technical Leadership for Architectural Decision Making
baasie
3
440
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
250
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
It's Worth the Effort
3n
188
29k
Building Applications with DynamoDB
mza
96
7.1k
Testing 201, or: Great Expectations
jmmastey
46
8.2k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.6k
RailsConf 2023
tenderlove
30
1.5k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
200
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
Transcript
【第11回】ゼロから始めるゲノム解析 (Python編) Finding a Protein Motif @kimoton
本勉強会の概要・目的 書籍名 対象者/目的 Mastering Python for Bioinformatics Python・バイオインフォ知識ほぼゼロの人 を対象に、正しいPythonのコーディング手 法について学ぶ
頻度 毎週〜隔週開催予定 登壇者 募集中!
Rosalindとは • 問題解決を通じてバイオインフォマティク ス、プログラミング、およびアルゴリズムを 学習するためのプラットフォーム • 大学やハッカソン、就職の面接にも 600回 以上の採用実績あり 参考:https://qiita.com/_kimoton/items/d534d0fa9b83dd7dc412
概要
環境構築 - 必要パッケージ群のインストール # 公開されているレポジトリからファイル群を取得 $ git clone https://github.com/kyclark/biofx_python $
cd biofx_python # requirements.txt に記載のパッケージをインストール $ pip3 install -r requirements.txt # pylintの設定ファイルをホームディレクトリに移動 $ cp pylintrc ~/.pylintrc # mypyの設定ファイルをホームディレクトリに移動 $ cp mypy.ini ~/.mypy.ini
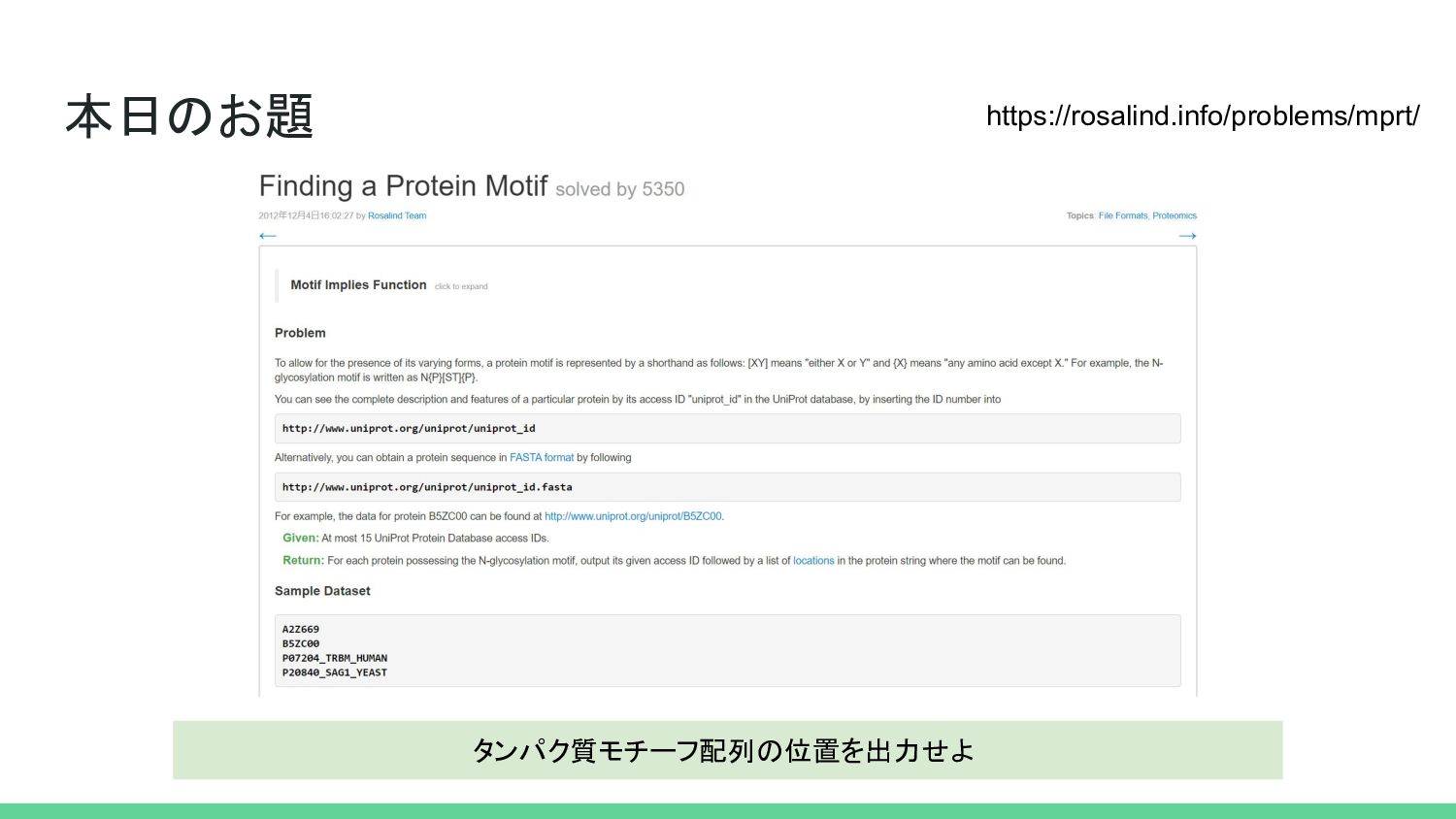
本日のお題 タンパク質モチーフ配列の位置を出力せよ https://rosalind.info/problems/mprt/
• プログラムを用いてインターネットからデータをfetchする方法 • 正規表現を用いてタンパク質のモチーフを探索する方法 • マニュアルでタンパク質のモチーフを探索する方法 本日学ぶこと
前提知識編
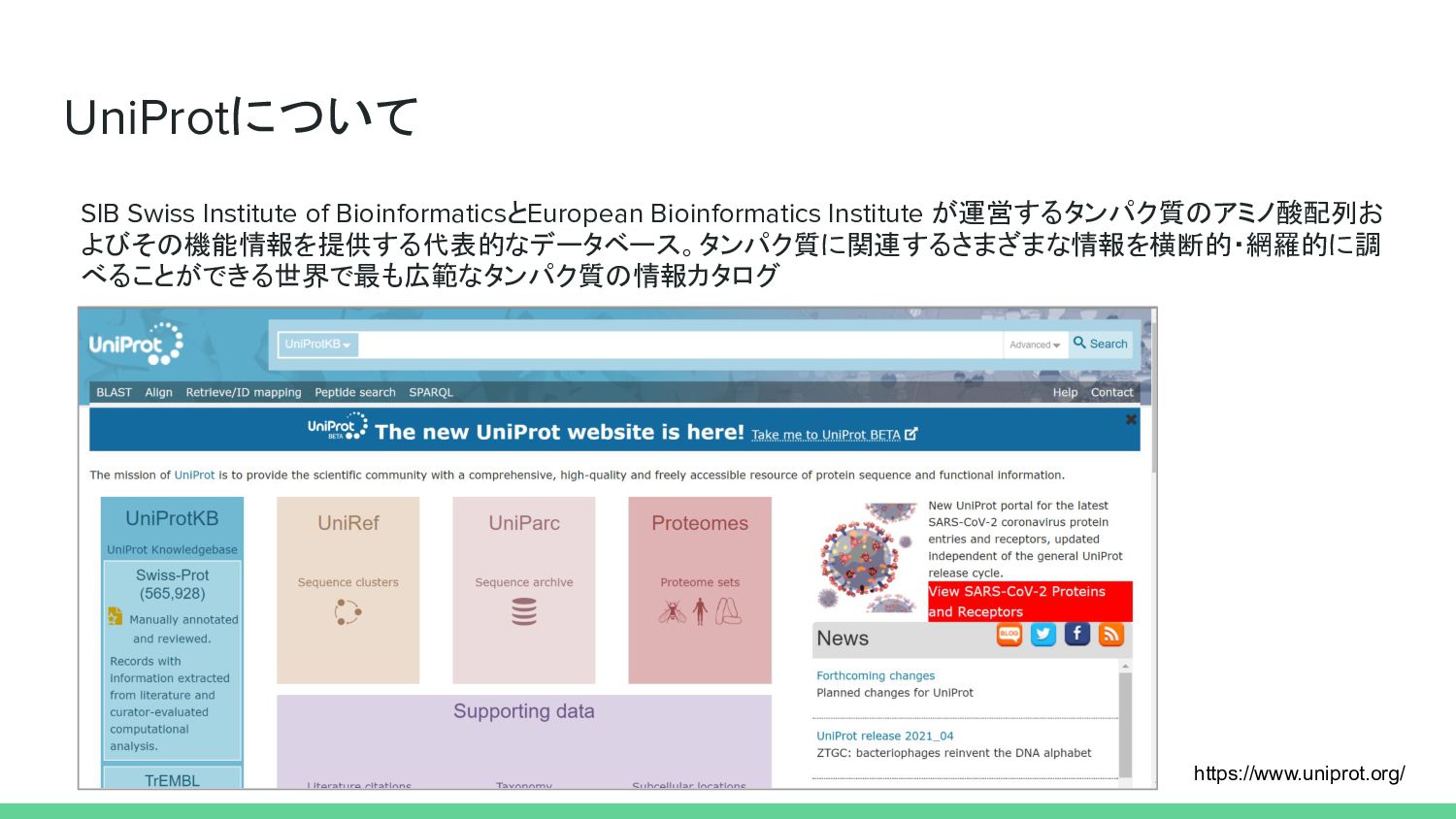
UniProtについて https://www.uniprot.org/ SIB Swiss Institute of BioinformaticsとEuropean Bioinformatics Institute が運営するタンパク質のアミノ酸配列お
よびその機能情報を提供する代表的なデータベース。タンパク質に関連するさまざまな情報を横断的・網羅的に調 べることができる世界で最も広範なタンパク質の情報カタログ
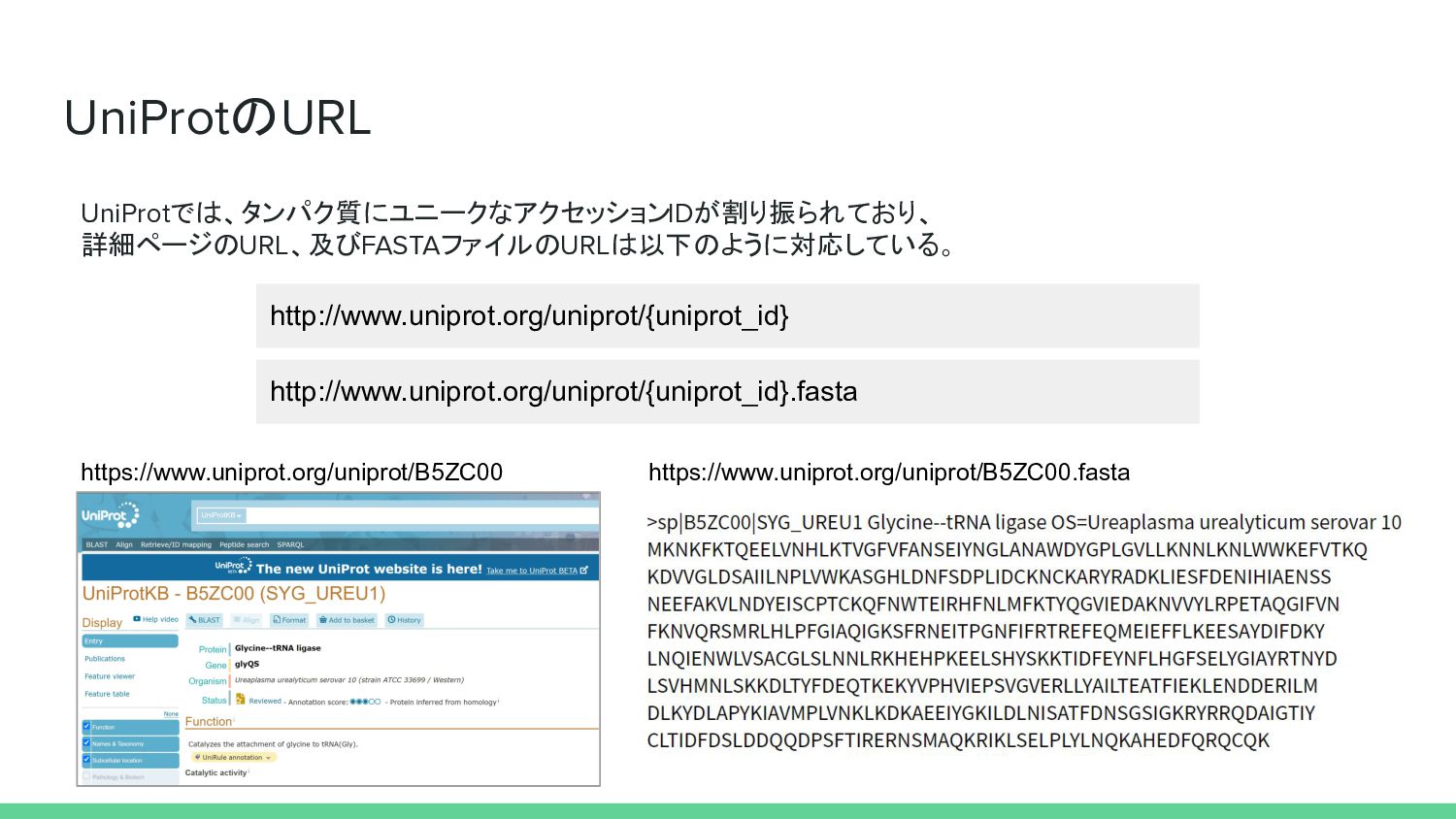
UniProtのURL http://www.uniprot.org/uniprot/{uniprot_id} UniProtでは、タンパク質にユニークなアクセッションIDが割り振られており、 詳細ページのURL、及びFASTAファイルのURLは以下のように対応している。 https://www.uniprot.org/uniprot/B5ZC00 http://www.uniprot.org/uniprot/{uniprot_id}.fasta https://www.uniprot.org/uniprot/B5ZC00.fasta
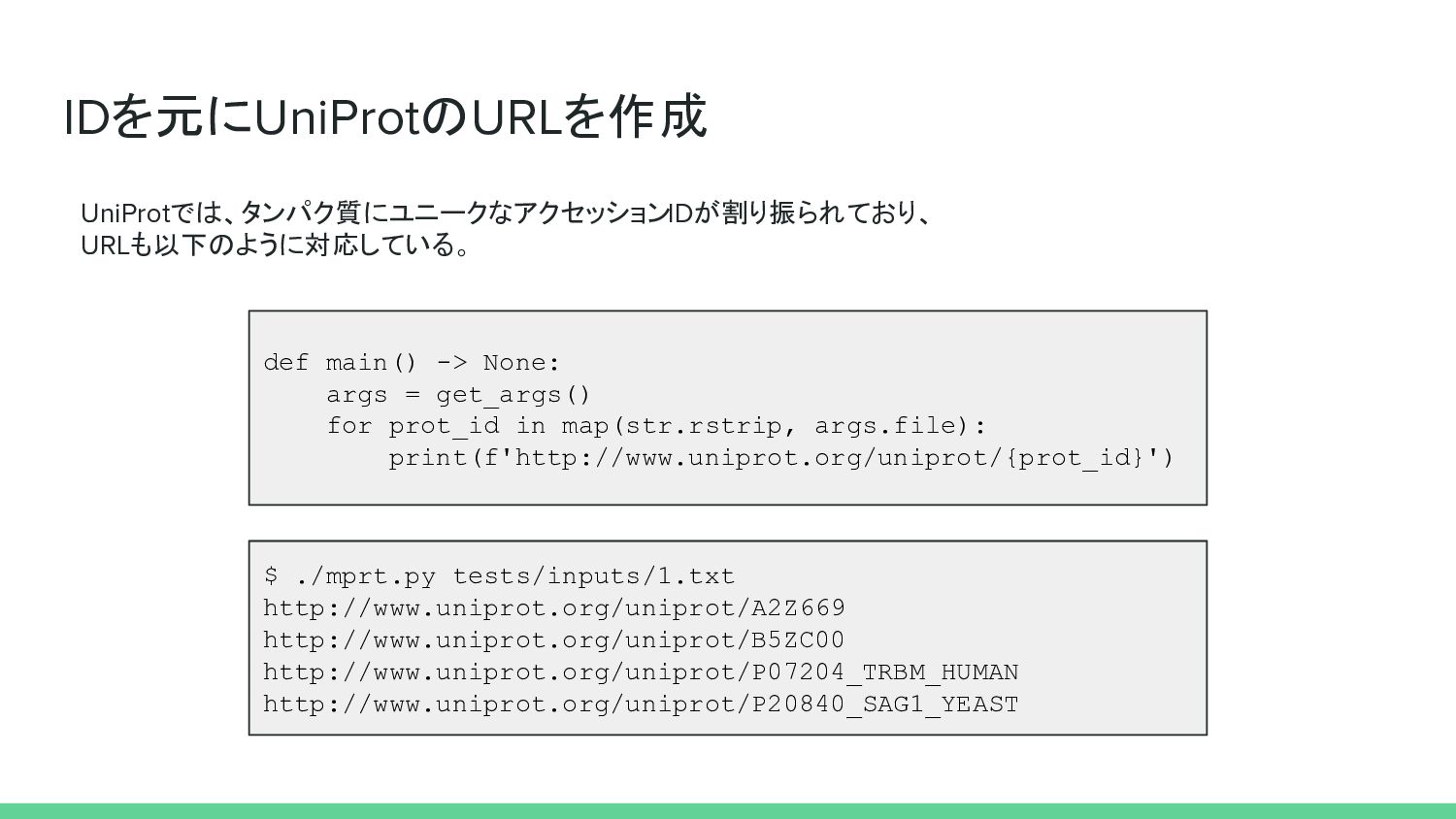
IDを元にUniProtのURLを作成 UniProtでは、タンパク質にユニークなアクセッションIDが割り振られており、 URLも以下のように対応している。 def main() -> None: args = get_args()
for prot_id in map(str.rstrip, args.file): print(f'http://www.uniprot.org/uniprot/{prot_id}') $ ./mprt.py tests/inputs/1.txt http://www.uniprot.org/uniprot/A2Z669 http://www.uniprot.org/uniprot/B5ZC00 http://www.uniprot.org/uniprot/P07204_TRBM_HUMAN http://www.uniprot.org/uniprot/P20840_SAG1_YEAST
FASTAファイルのダウンロード(bash) bashスクリプトによりファイルのダウンロードを自動化 #!/usr/bin/env bash if [[ $# -ne 1 ]];
then printf "usage: %s FILE\n" $(basename "$0") exit 1 fi OUT_DIR="fasta" [[ ! -d "$OUT_DIR" ]] && mkdir -p "$OUT_DIR" while read -r PROT_ID; do echo "$PROT_ID" URL="https://www.uniprot.org/uniprot/${PROT_ID}" OUT_FILE="$OUT_DIR/${PROT_ID}.fasta" wget -q -o "$OUT_FILE" "$URL" done < $1 1 1 PATH環境変数の通っている 場所からbashを使用 2 2 引数の数「$#」が1でなければ エラー終了 3 3 出力ディレクトリがなければ作 成 4 4 ファイルの各行をPROT_IDと して格納 5 5 wgetコマンドでファイルをダウ ンロード
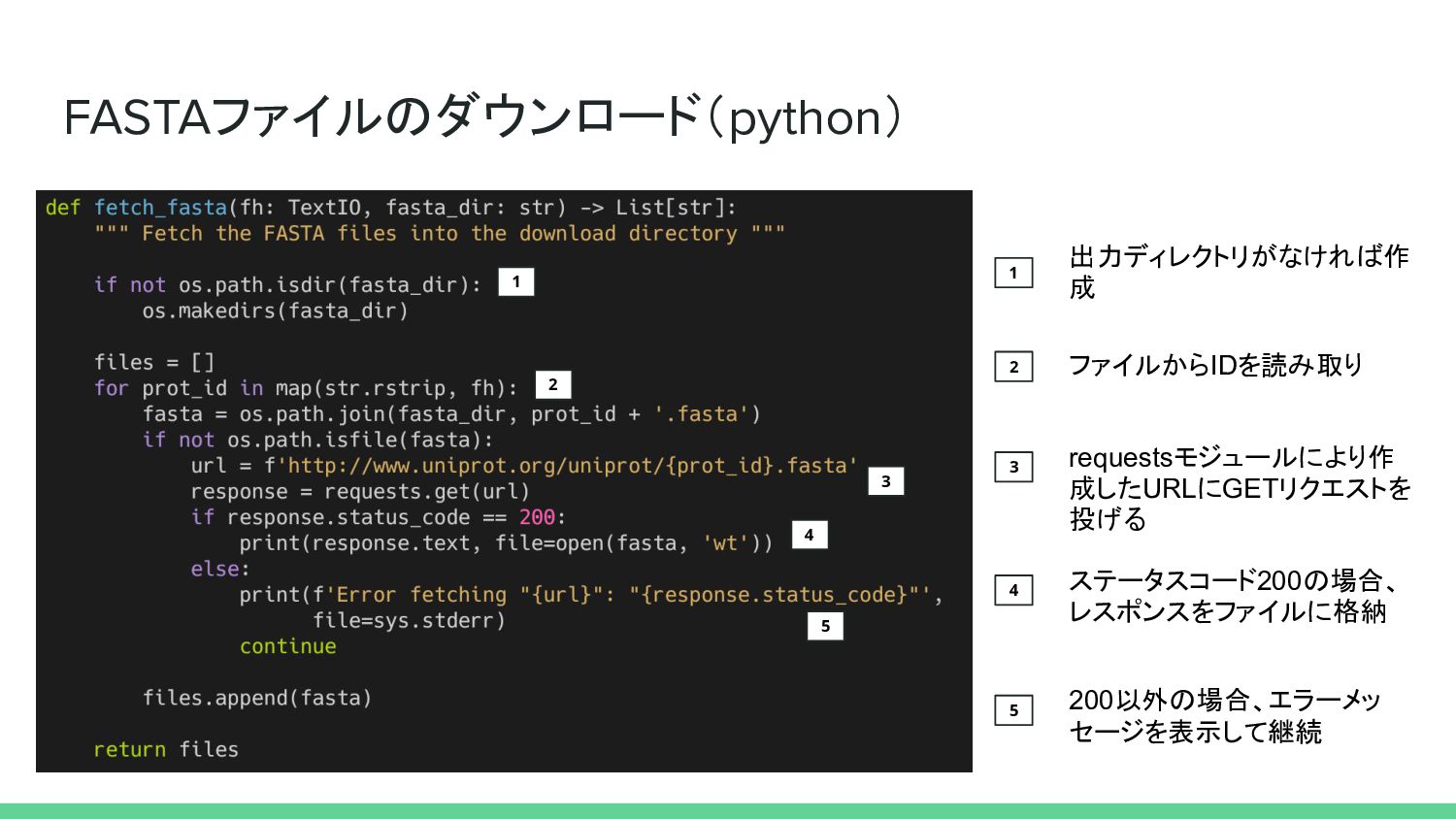
FASTAファイルのダウンロード(python) 1 2 4 1 出力ディレクトリがなければ作 成 2 ファイルからIDを読み取り 5
3 requestsモジュールにより作 成したURLにGETリクエストを 投げる 3 4 ステータスコード200の場合、 レスポンスをファイルに格納 5 200以外の場合、エラーメッ セージを表示して継続
N-glycosylation モチーフの構造 正規表現を用いて N [^P] [ST] [^P] で表される P以外 P以外
SorT https://prosite.expasy.org/PDOC00001
正規表現でN-glycosylationモチーフを表現 2つのN-glycosylationモチーフを持つ配列からN-glycosylationモチーフを取得 >>> seq = 'NNTSYS' >>> regex = re.compile('(?=(N[^P][ST][^P]))')
>>> regex.findall(seq) ['NNTS', 'NTSY'] >>> [match.start() + 1 for match in regex.finditer(seq)] [1, 2] マッチしたポジションを出力
解法編
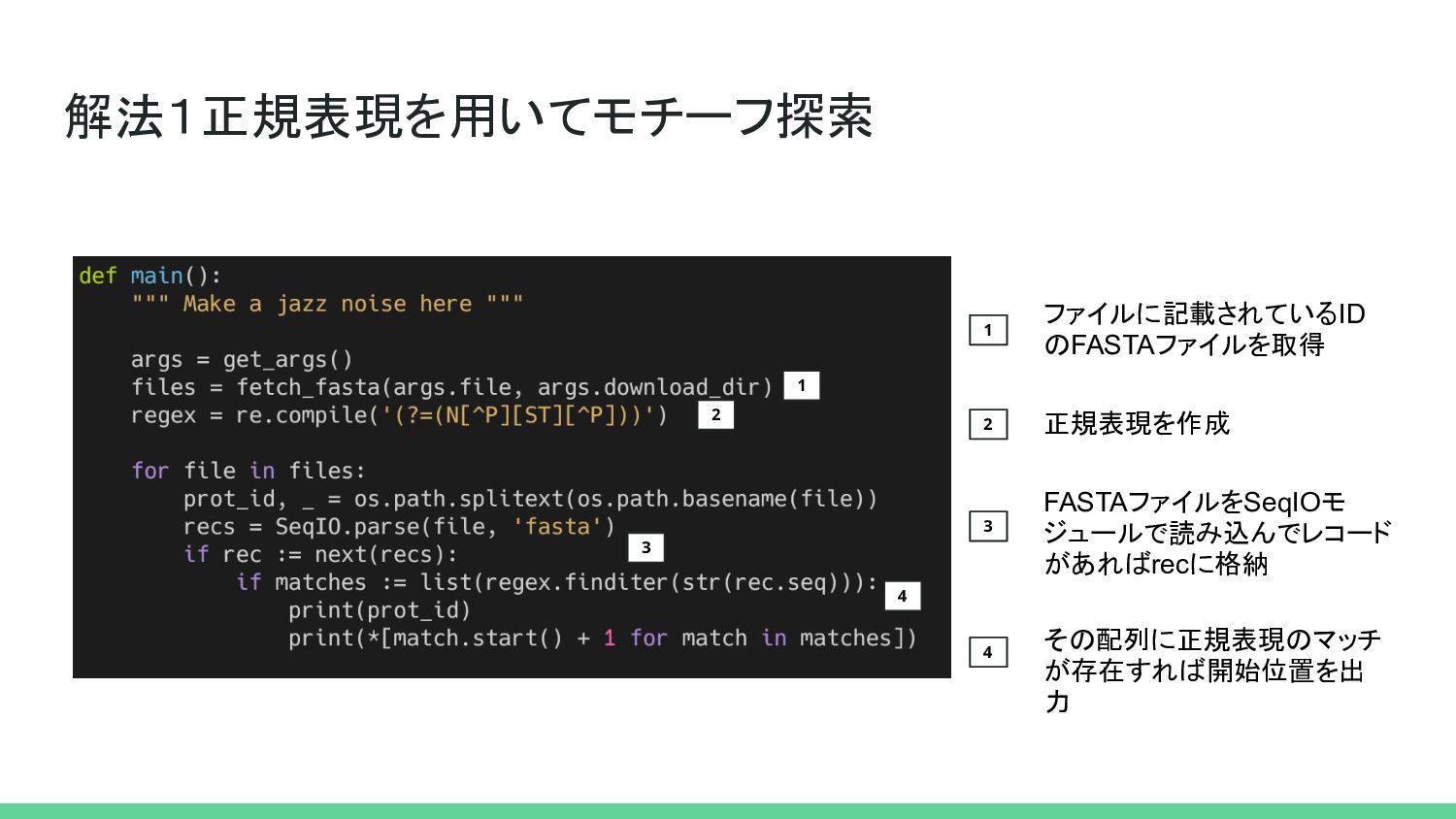
解法1正規表現を用いてモチーフ探索 1 ファイルに記載されているID のFASTAファイルを取得 1 2 正規表現を作成 2 3 FASTAファイルをSeqIOモ
ジュールで読み込んでレコード があればrecに格納 3 4 その配列に正規表現のマッチ が存在すれば開始位置を出 力 4
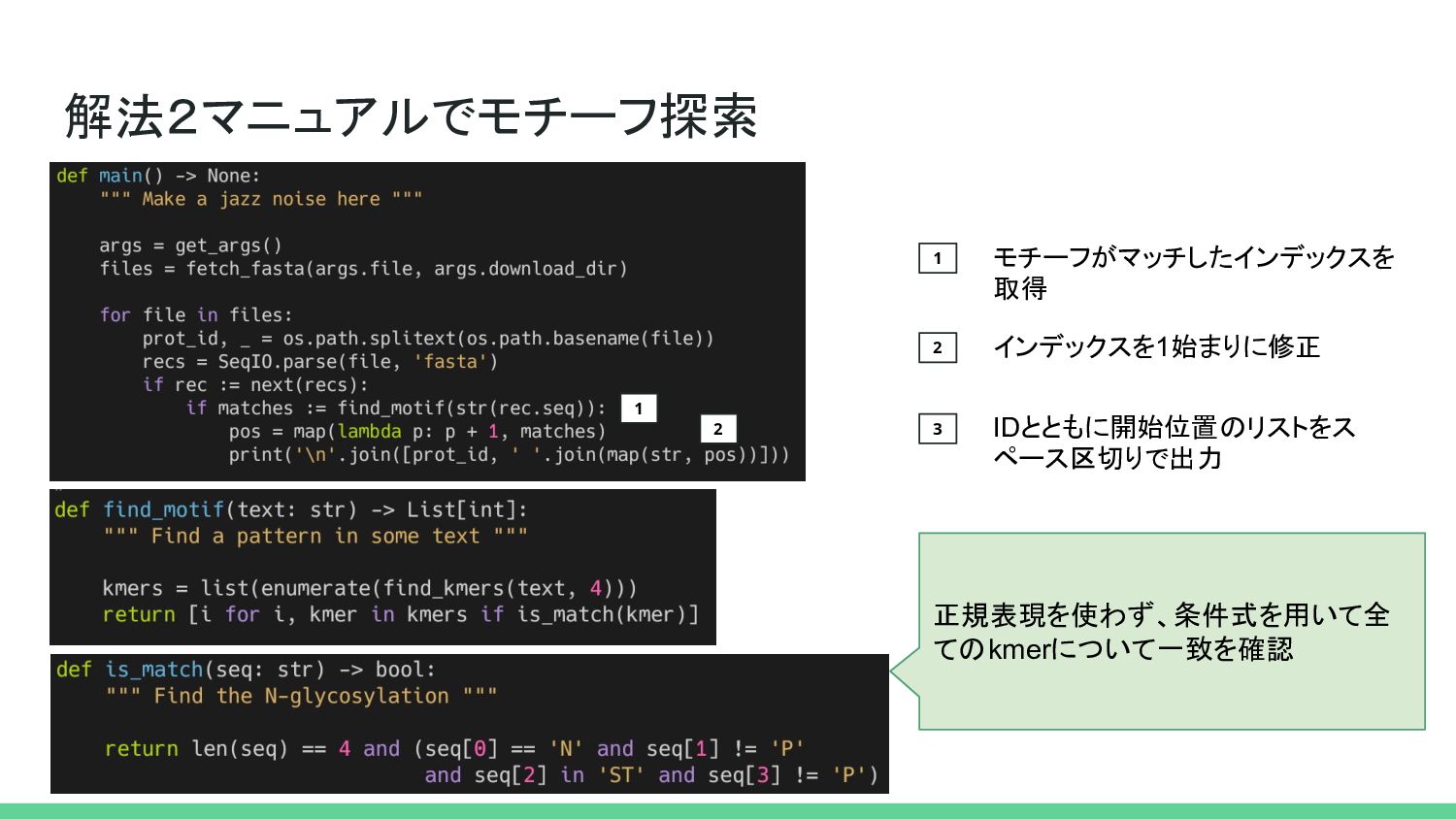
解法2マニュアルでモチーフ探索 1 2 1 モチーフがマッチしたインデックスを 取得 正規表現を使わず、条件式を用いて全 てのkmerについて一致を確認 2 インデックスを1始まりに修正
3 IDとともに開始位置のリストをス ペース区切りで出力
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![FASTAファイルのダウンロード(bash) bashスクリプトによりファイルのダウンロードを自動化 #!/usr/bin/env bash if [[ $# -ne 1 ]];](https://files.speakerdeck.com/presentations/9403186ac8294239b98971e142d97d3f/slide_10.jpg){kind=link}
{kind=link}
![N-glycosylation モチーフの構造 正規表現を用いて N [^P] [ST] [^P] で表される P以外 P以外](https://files.speakerdeck.com/presentations/9403186ac8294239b98971e142d97d3f/slide_12.jpg){kind=link}
![正規表現でN-glycosylationモチーフを表現 2つのN-glycosylationモチーフを持つ配列からN-glycosylationモチーフを取得 >>> seq = 'NNTSYS' >>> regex = re.compile('(?=(N[^P][ST][^P]))')](https://files.speakerdeck.com/presentations/9403186ac8294239b98971e142d97d3f/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}