Distributed consensus using Raft, Node.js, and fuzz testing
A talk on distributed consensus, with a high-level overview of Raft, some of the challenges with implementing Raft in Node.js, and how to properly test a distributed system using fuzz testing.
Mark Wubben novemberborn.net @novemberborn Hi! My name’s Mark Wubben. I’m a humanist & technologist who loves working with the web. Occasionally I speak Dutch, but no Dutch comprehension skills will be necessary for this presentation. I’m currently based here in London, mixing open source development with contracting. Ideally I’d do contracting on open source projects I’m part of the core team for the AVA test runner, as well as a contributor to nyc, the new command line tool for the Istanbul code coverage project. AVA: https://github.com/avajs/ava nyc: https://github.com/istanbuljs/nyc Photo by Agberto Guimaraes: https://unsplash.com/photos/qK_muh-pAcg
by including reliable, distributed primitives in our applications, rather than by writing against external, third-party tools. Since I like JavaScript and Node.js I’ve written an implementation of such a primitive, called Buoyant. Buoyant solves the problem of making servers agree on their state, by providing an implementation of the Raft algorithm. I’ll talk about what that means and give a high- level overview of Raft. I’ll then look at some of the challenges with implementing Raft in Node.js. Finally I’ll show how to properly test a distributed system using fuzz testing. Photo by Jesse Bowser: https://unsplash.com/photos/Z1W0A7t3kMo
or more servers. They should be resilient: if a server goes down the system should remain functional and not lose data. For some use cases requests can be sent to any server, for others there is a primary server which handles client requests. Databases are a good example of this. Writes tend to be against a primary, which replicates them to secondaries. Depending on your requirements you can read from secondaries, thus spreading load across your database servers. It is critical for all parts of a distributed system to agree on their state. This is what we call consensus. Without it systems will behave in inconsistent and unexpected ways. This may be fine for you when it comes to withdrawals from your bank account, but I’m sure you’d really rather deposits don’t go missing! Photo by Maarten van den Heuvel: https://unsplash.com/photos/s9XMNEm-M9c
distributed system to ensure it stays up even if a server dies. We do it so data lives in multiple places, making it less likely for data to be lost. We do it to spread load among multiple servers, leading to better response times and preventing the service from coming to a halt. Photo by Evan Dennis: https://unsplash.com/photos/i--IN3cvEjg
will fail. How? Let’s count the ways: * The hardware your server runs on may die * The virtual machine that is your server may die * Your Docker container may die * The Docker daemon may die * Another process may eat up all CPU and swap space * Another virtual machine, on the same underlying hardware, may steal all CPU * Your application may crash * Your network may split * Your network may become saturated * Clocks may go out of sync * … and I’m sure there’s many more ways your distributed system will fail Because it will fail. Photo by Radek Grzybowski: https://unsplash.com/photos/8tem2WpFPhM
systems achieve consensus must deal with these failure scenarios. Clearly they shouldn’t allow data to be lost. They must ensure that each server, eventually, has the same state as all other servers. They must allow progress to be made, by allowing new data to be written into the system. No bad things should happen when networks split. And if the primary server goes away the algorithm should ensure a replacement. Photo by Jay Mantri: https://unsplash.com/photos/qKFxQ3X-YbI
algorithm is Paxos, first published in 1989 by Turing award winner Leslie Lamport. Google uses Paxos in its Chubby service, which helps power Google File System, Bigtable and MapReduce. Photo by Frédérique Voisin-Demery, CC BY 2.0, https://www.flickr.com/photos/vialbost/4924670672/
Atomic Broadcast protocol, used in Apache ZooKeeper, of Hadoop and Kafka fame. See https://zookeeper.apache.org/ Photo by Mathias Appel, CC0: https://www.flickr.com/photos/mathiasappel/27710132206/
published in 2013 by Stanford PhD student Diego Ongaro and professor John Ousterhout (of Tcl fame). It’s expressly designed to be easy to understand, in contrast to the Paxos algorithm. It is backed by mathematical proof. One of the highest visible users of the Raft algorithm is CoreOS’ etcd, a distributed key-value store used by Google’s Kubernetes. HashiCorp’s Consul, a similar service, is also built on Raft. See: https://raft.github.io/, https://coreos.com/etcd/docs/latest/, https://www.consul.io/ Photo by Kevin Poh, CC BY 2.0: https://www.flickr.com/photos/kevinpoh/8269486049/
a good test of how easy to understand it really is. I’ll focus on the higher-level interactions inside a Raft cluster. Feel free to talk to me afterwards for details, or read the paper yourself Paper: https://raft.github.io/raft.pdf Photo by John-Mark Kuznietsov: https://unsplash.com/photos/V0zxMzW_-e0
It doesn’t care what that state is, though. Instead it assumes your application has a state machine, which can change from one state to another in response to commands. A key-value store such as Etcd can be modelled by a state machine, as can a bank balance. What’s important is that the state is changed one command at a time. If the same commands are applied in the same order the result will be the same. Photo by Andrew Branch: https://unsplash.com/photos/FX__egbD0zE
the commands used to modify the state machine. These go into a log. Each server has its own log. Eventually the logs on all servers must converge and become equivalent to each other. Once a command, or log entry as we’ll call it from now on, has replicated to enough servers it can be applied to each server’s state machine. Photo by Joshua Stannard: https://unsplash.com/photos/zGqVUL30hF0
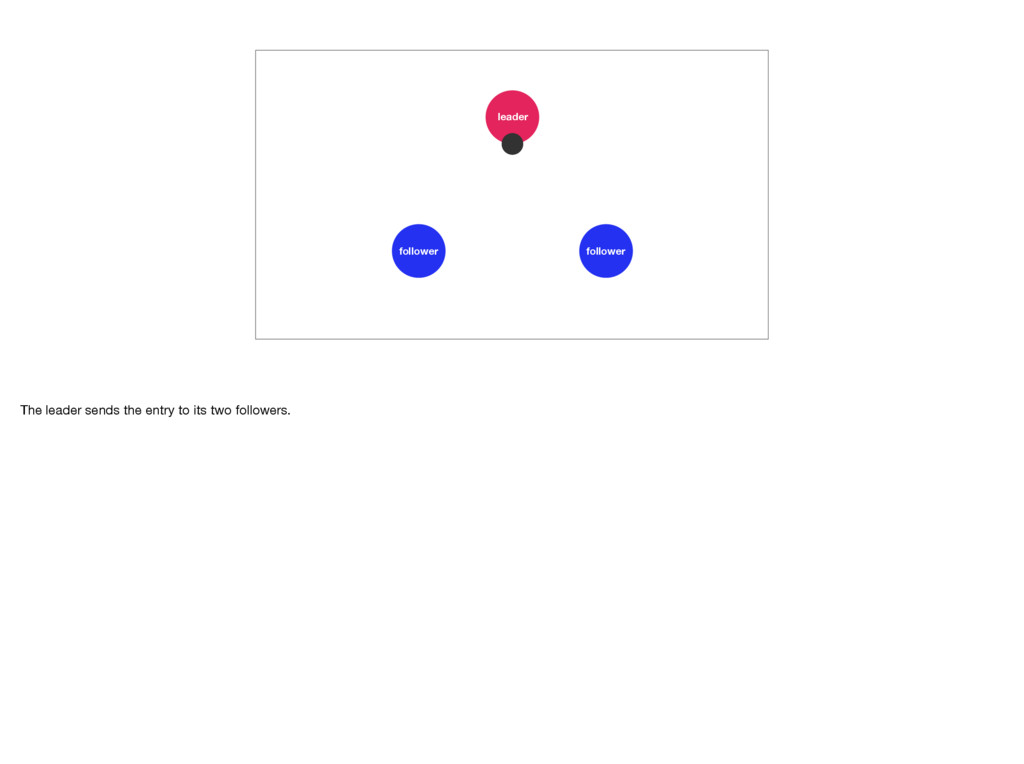
leader can append new commands to the log. It’s responsible for replicating them throughout the cluster. The leader will be the most up-to-date server. Photo by William Hook: https://unsplash.com/photos/pa0rr3rVB-U
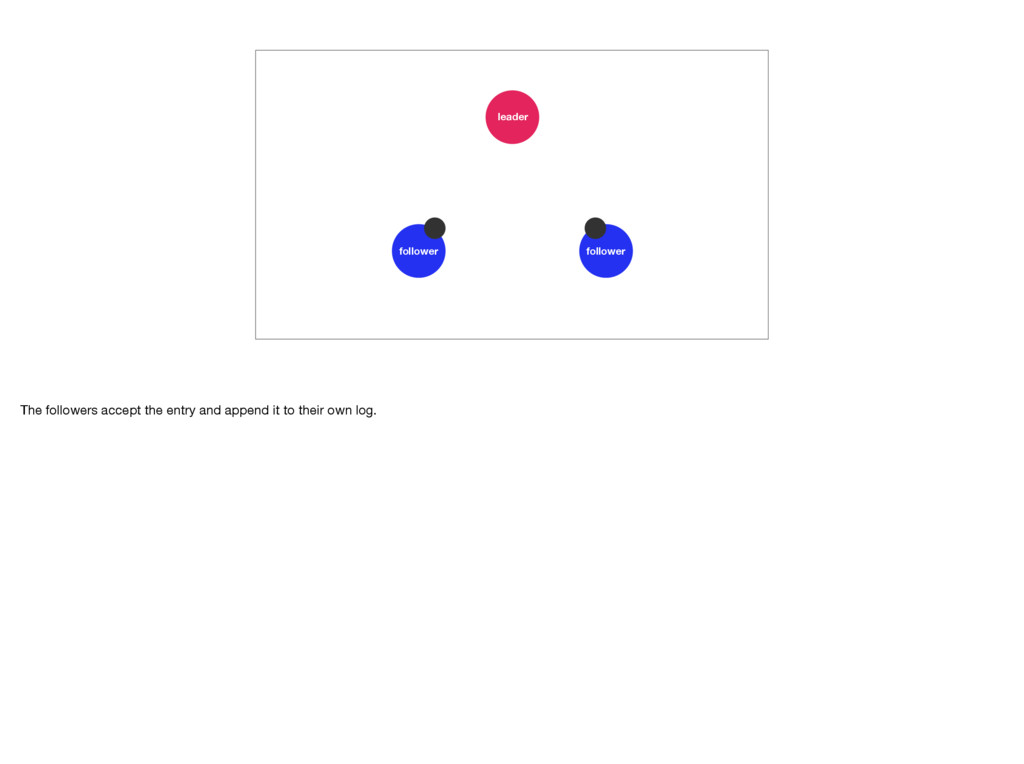
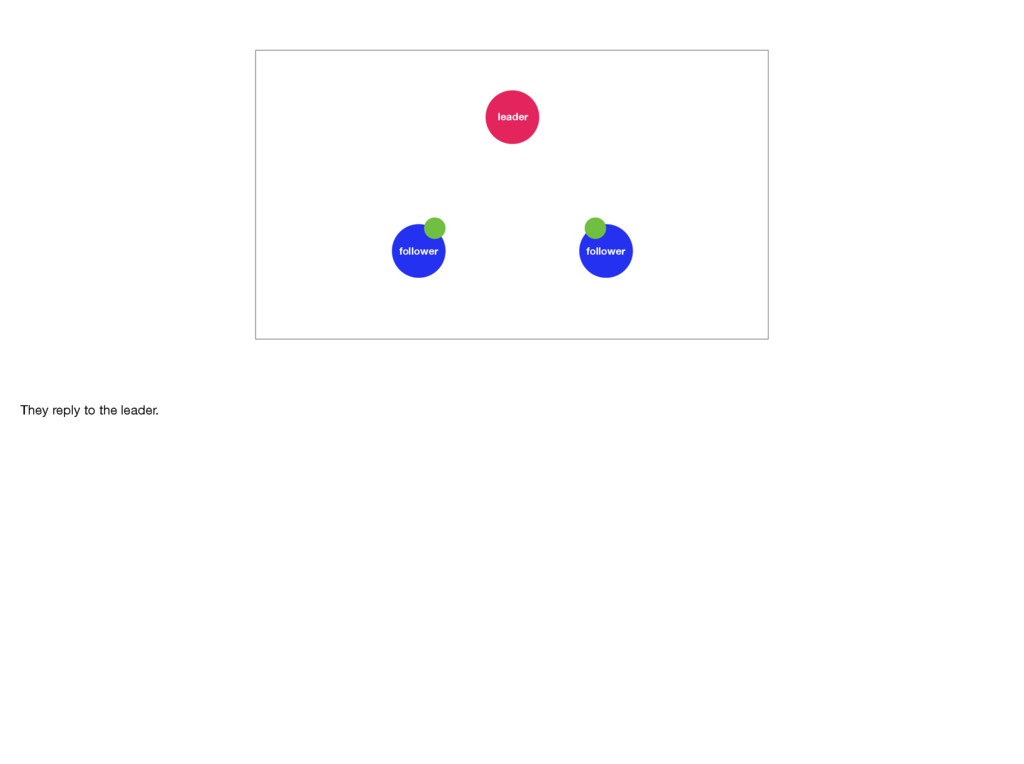
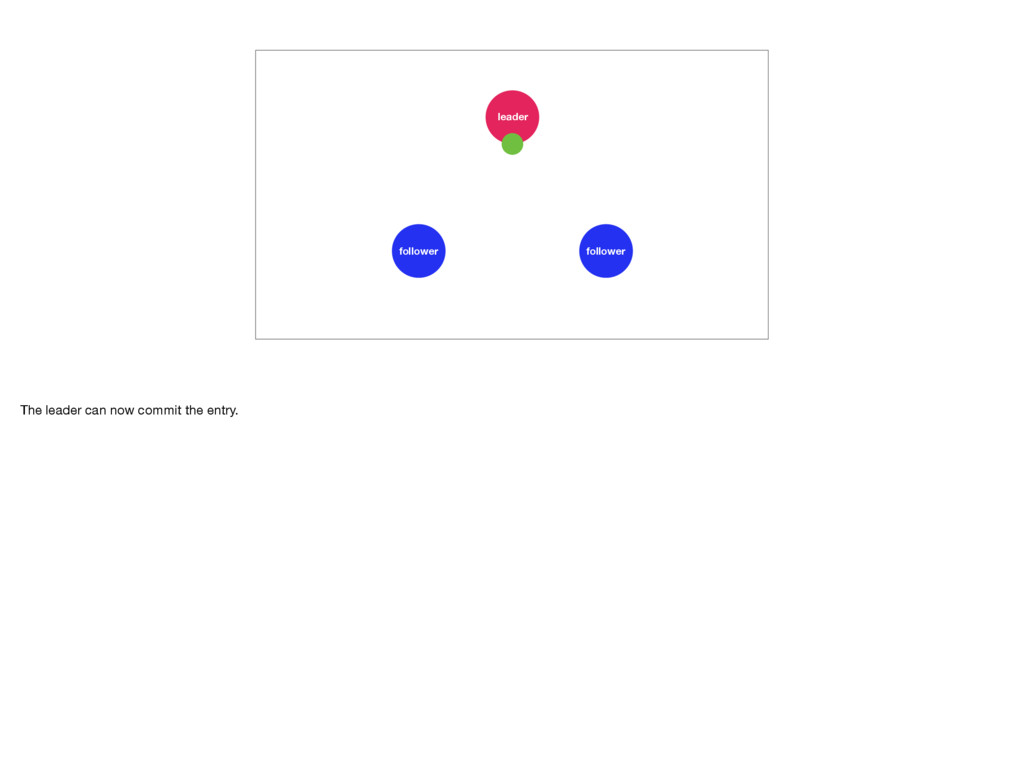
They receive new commands or log entries from the leader and append them to their own logs, before letting the leader know that the entries have been accepted. If enough followers accept the entries, the leader will apply them to its state machine. We say the leader commits the log entry. Afterwards the followers will too. This means the followers are always a little behind the leader. Log entries are only committed once they have been accepted by the majority of the servers. This is what allows a Raft cluster to reach consensus. Photo by Troy Oldham: https://unsplash.com/photos/UWw9OD3pIMo
be replicated to the majority of the cluster before it can be committed. Let’s say you’re running a cluster of three servers. In such a cluster the leader must wait for at least one follower to accept the entry before committing it. The third follower can be lost without preventing the cluster from making progress. This is known as fault tolerance. The number of servers in your cluster is known as the replication factor, so a cluster of three machines has a replication factor of three. With a replication factor of four you can still only tolerate one failure, but now two followers must accept a log entry before it can be committed. When the cluster is comprised of five servers you can afford to lose two. and you still need two followers to accept log entries. The right replication factor will depend on your requirements and budget. Note though that as you create larger clusters it takes longer to replicate to a majority of servers, and there is more chatter between all servers. Photo by Zach Betten: https://unsplash.com/photos/KYTT8L5JLDs
their internal state, even if they crash. Typically this is done by writing to disk. A server cannot rejoin a cluster if it’s lost its internal state. Photo by Henry Hustava: https://unsplash.com/photos/j_Ch0mwBNds
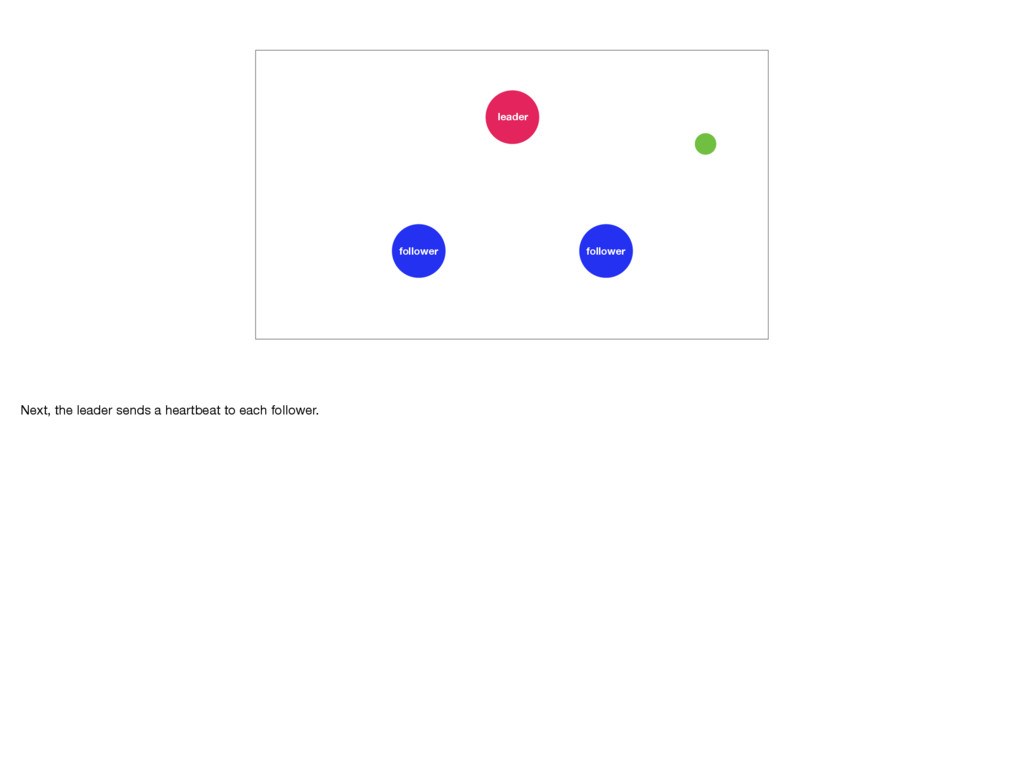
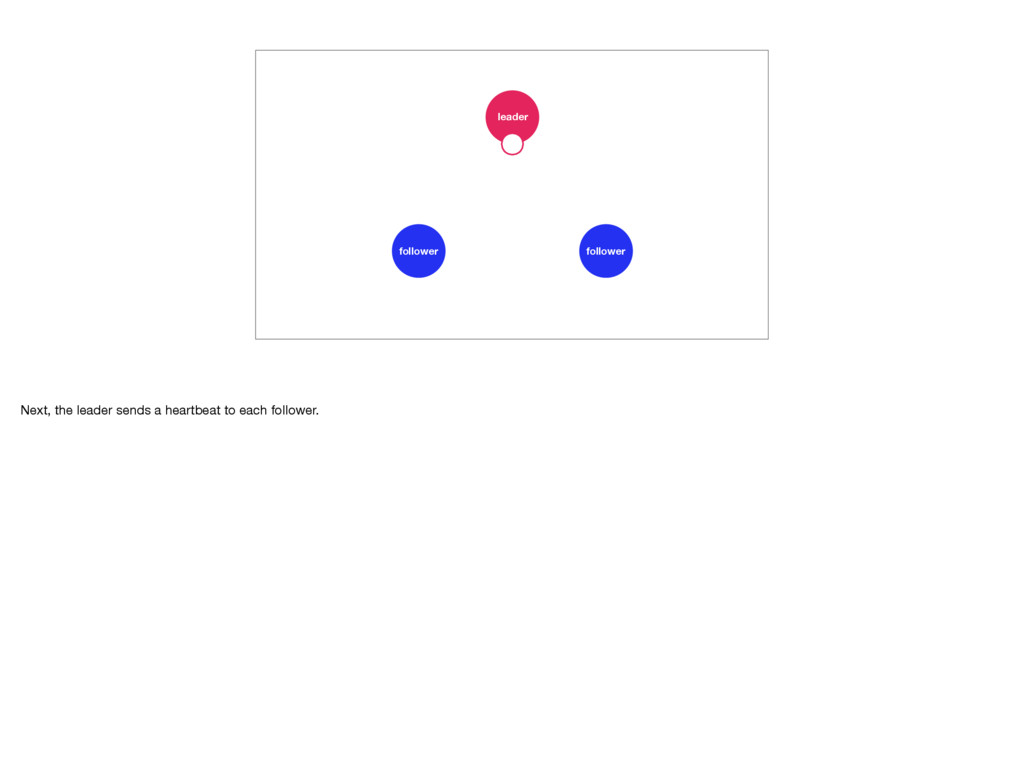
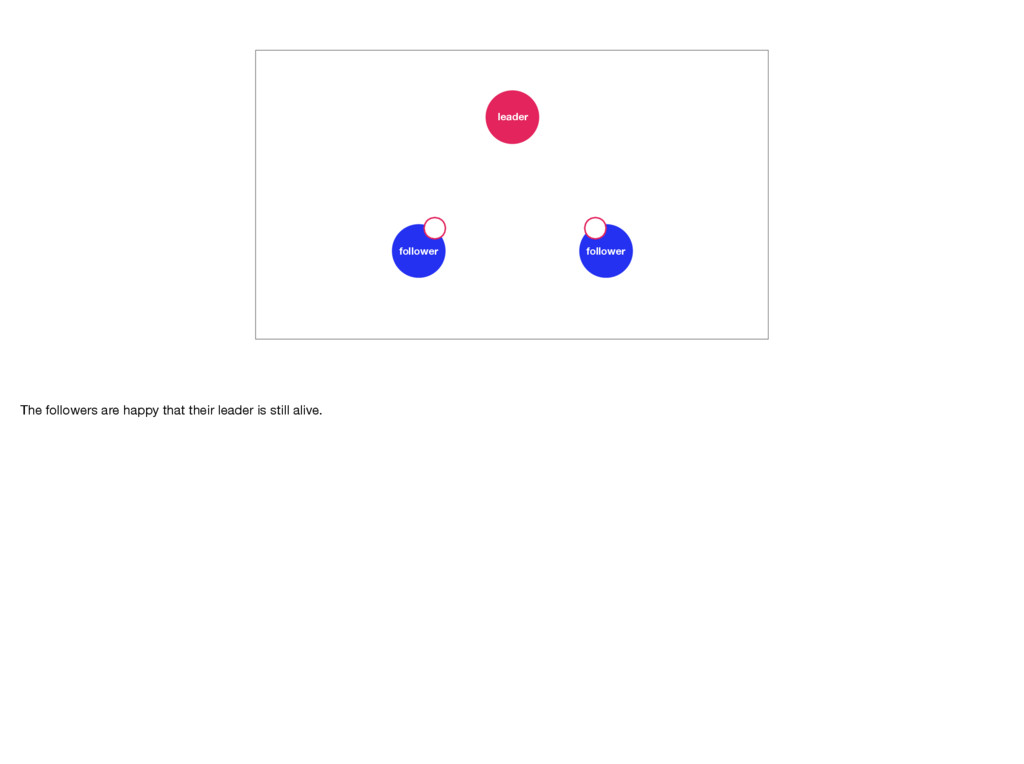
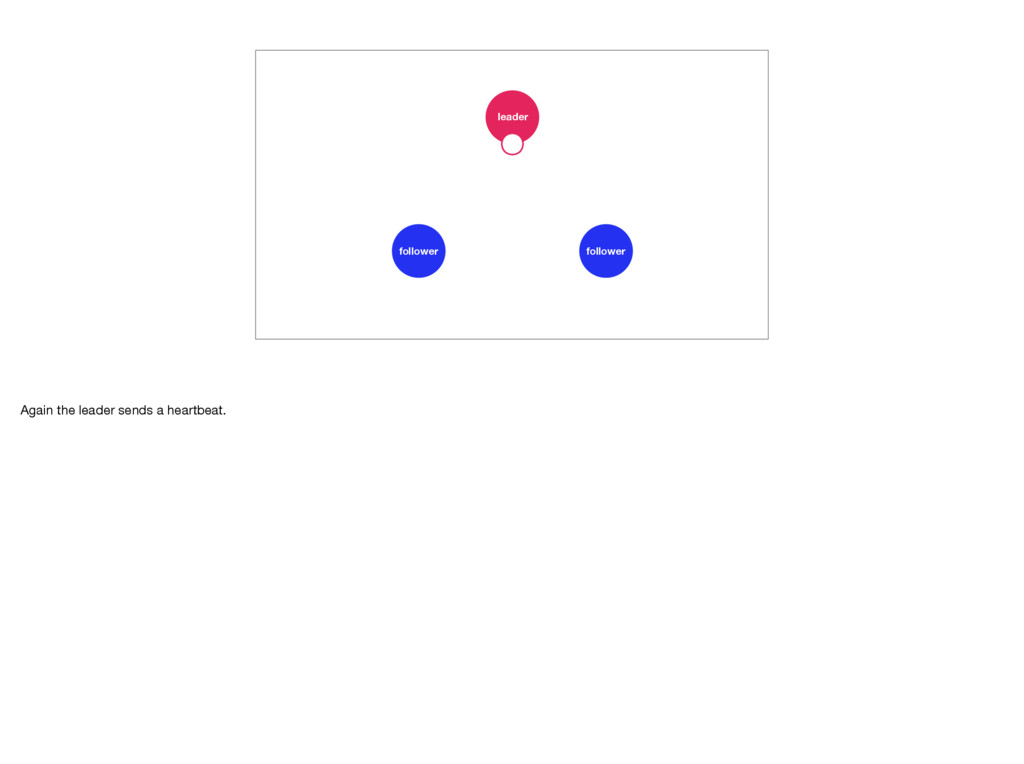
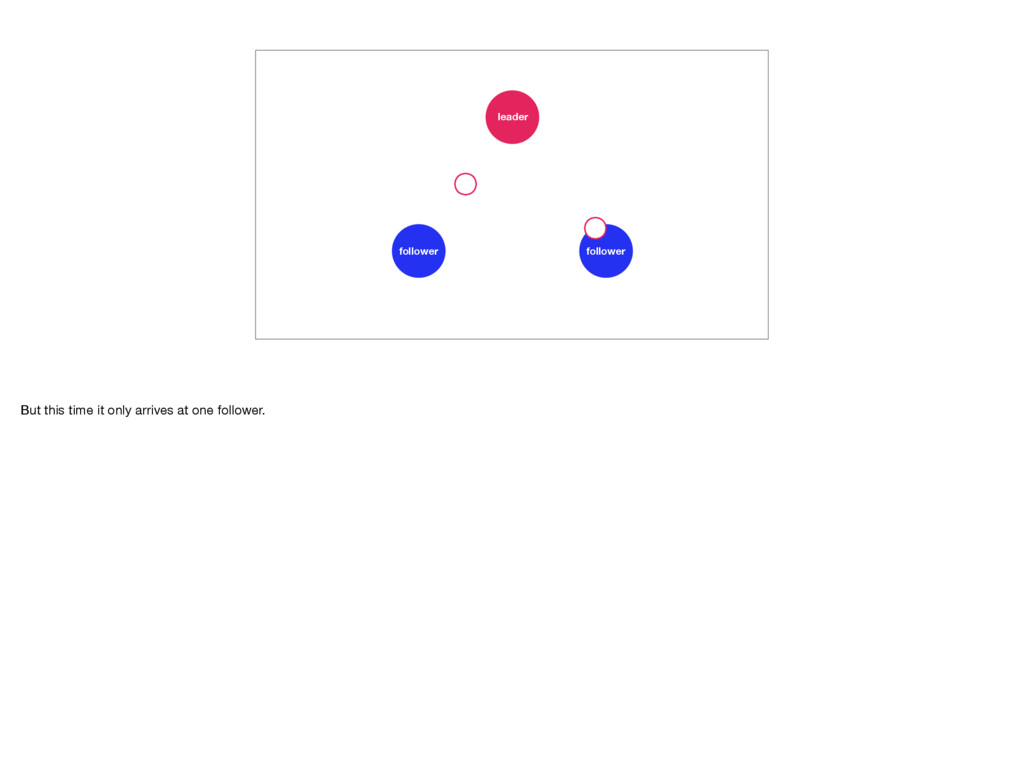
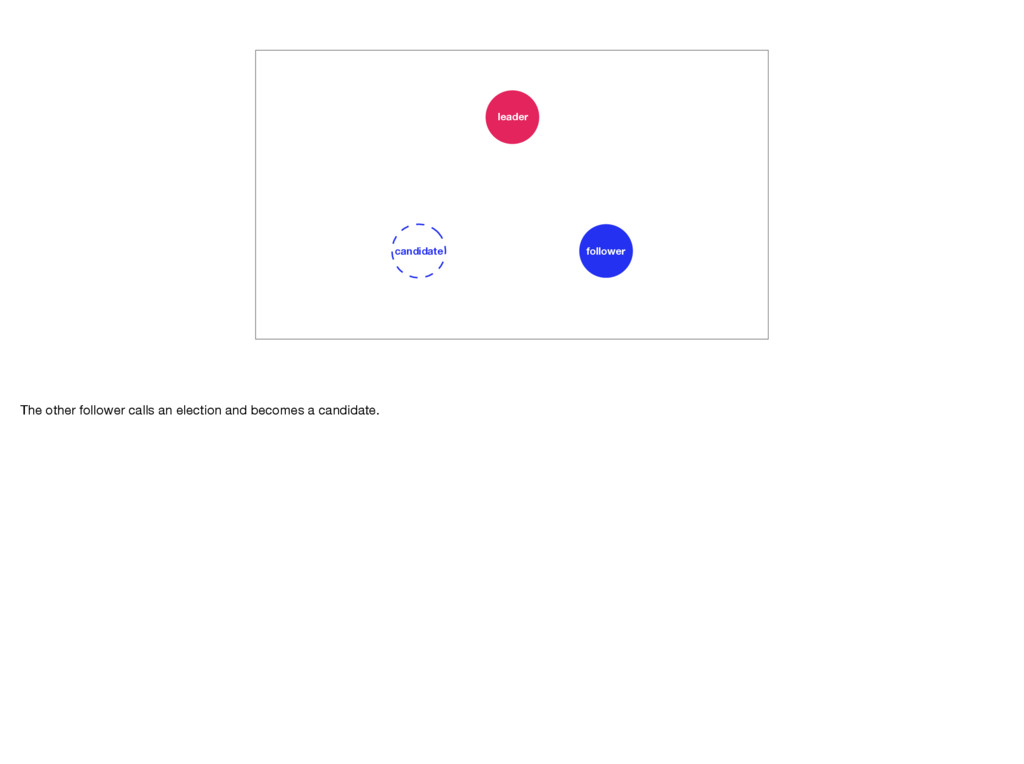
distributed system to fail. And remember, it will fail. In Raft the followers keep an eye on their leader. If they don’t hear from it for a while they’ll call for an election. To prevent this the leader will send out heartbeat messages to each of its followers. But, if the leader were to crash, or slows down, or loses connectivity, an election becomes inevitable. Elections are quick, but during one there is no leader. This means the Raft cluster is temporarily unable to make progress. Photo by Elliott Stallion: https://unsplash.com/photos/1UY8UuUkids
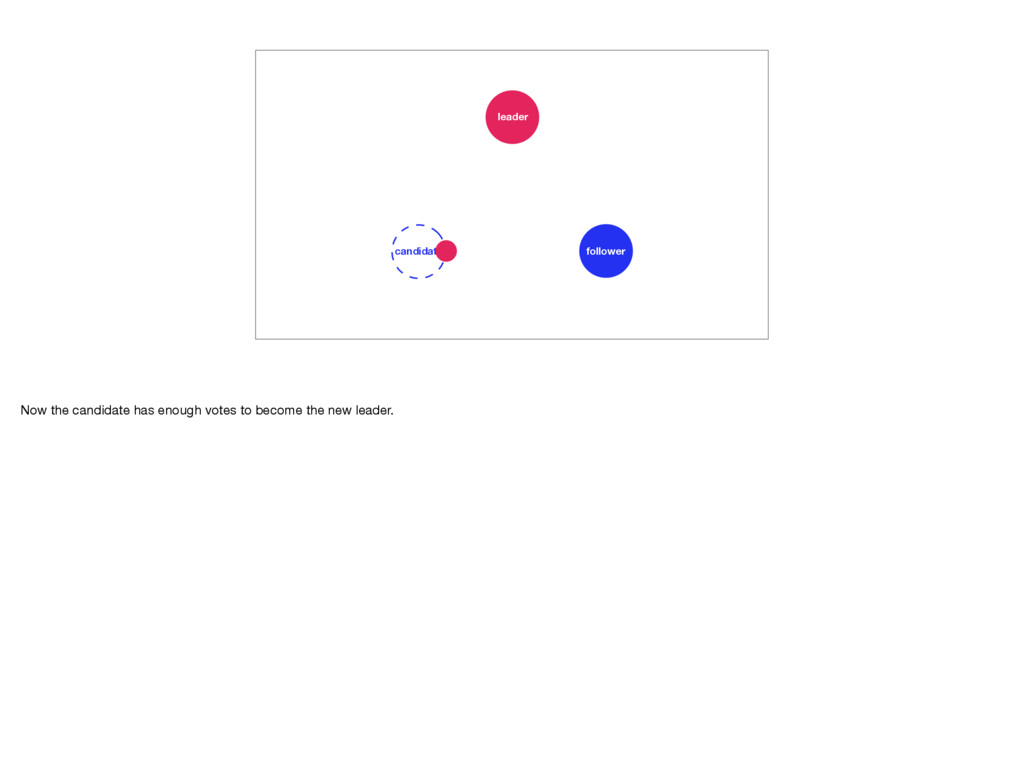
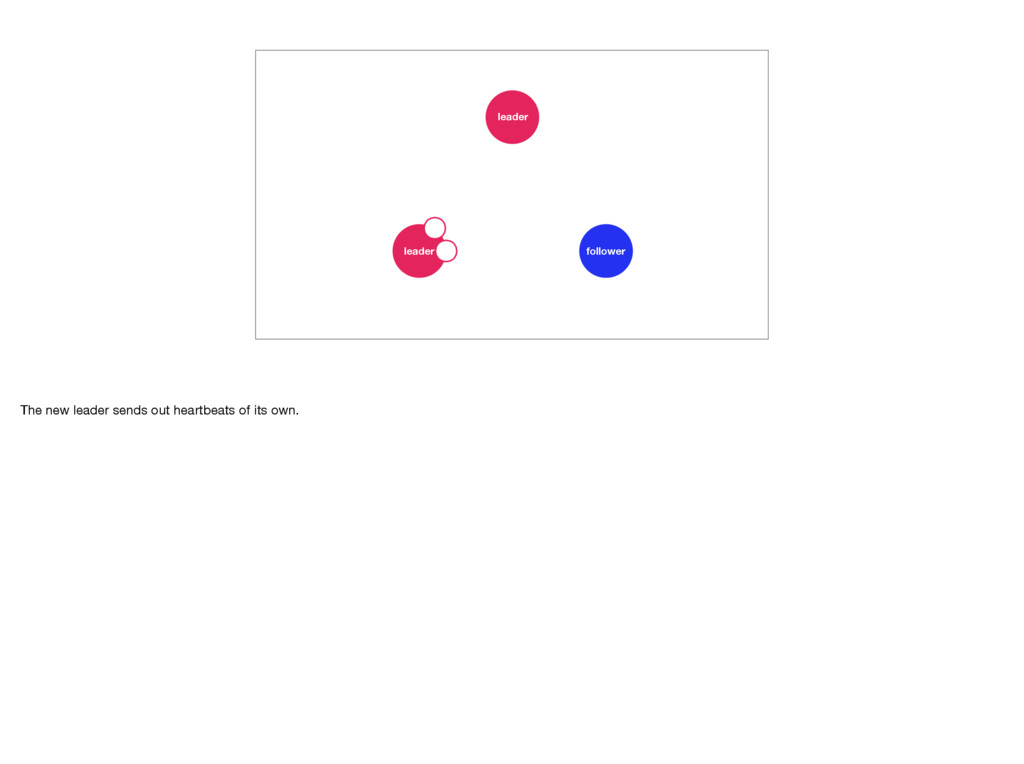
away it becomes a candidate. It requests votes from all other servers in the cluster. The other servers only vote for a candidate whose log is at least as complete as their own. This ensures no data is lost. Servers can only vote once in each election. A candidate requires votes from a majority of the cluster. Once it has that many votes it sends out heartbeat messages, cementing its place as the leader. And that’s how Raft works! Photo by Staat der Nederlanden, CC BY 2.0: https://www.flickr.com/photos/minister-president/13376935014/
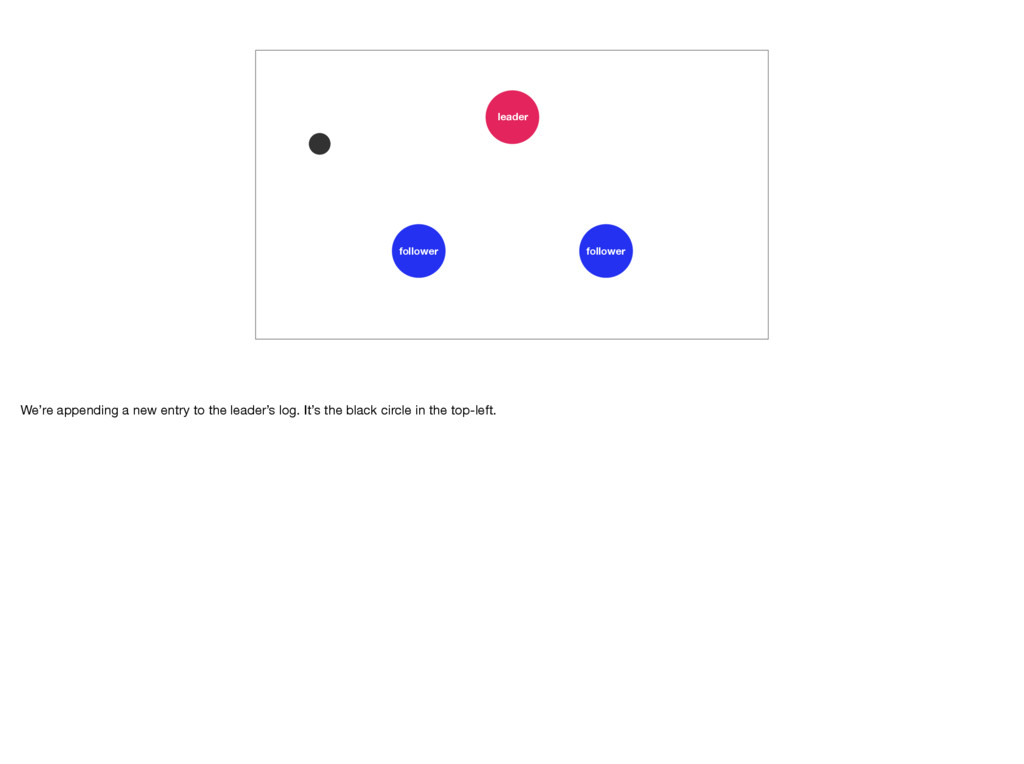
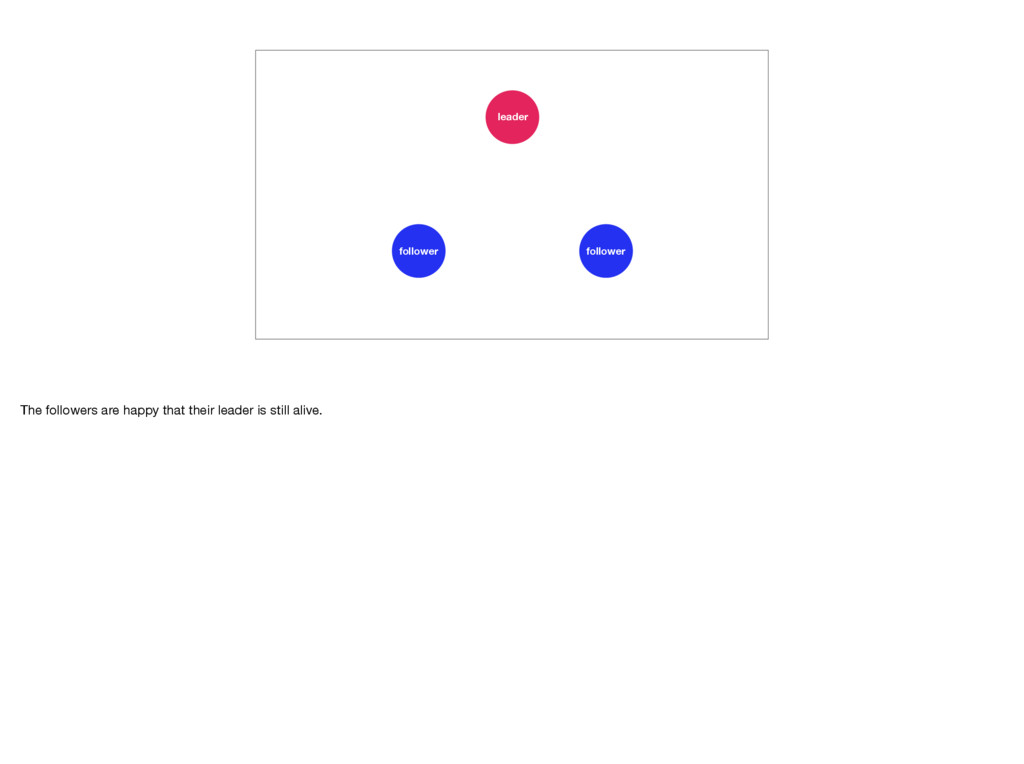
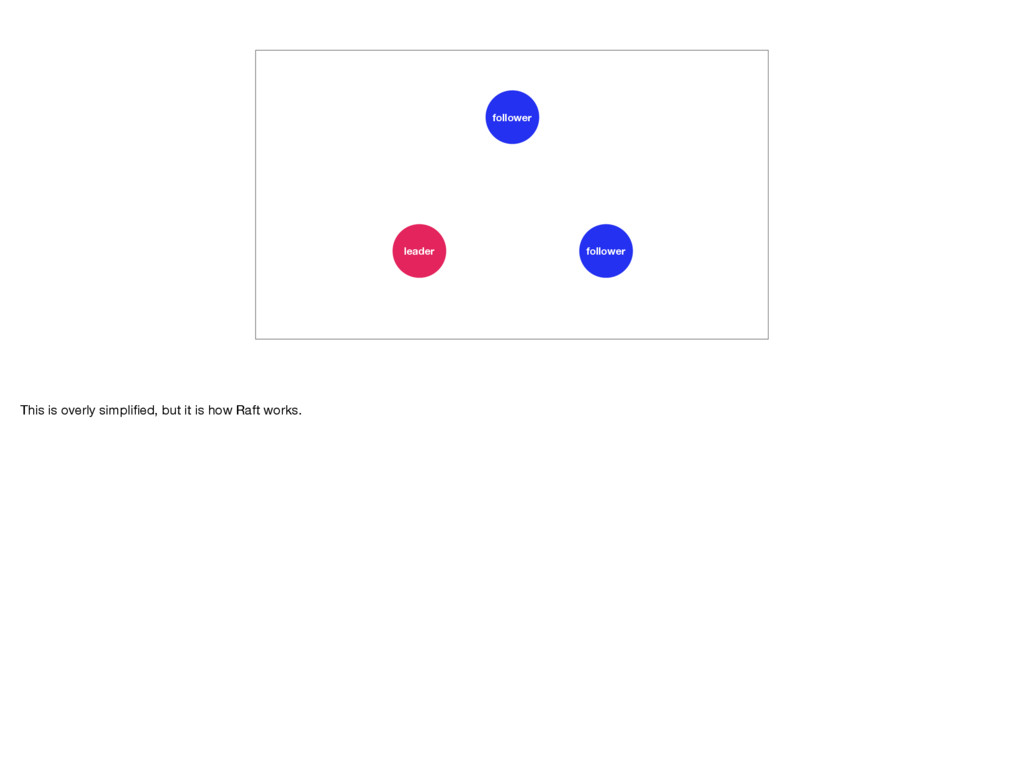
with a small visualization. Let’s imagine we have a cluster consisting of one leader and two followers. For a more detailed visualisation of Raft see https://raft.github.io/ and http://thesecretlivesofdata.com/raft/.
for Node.js. You can use it to build a distributed system that utilises Raft for achieving consensus. Like Raft, Buoyant does not care what kind of state you’re managing. Nor does it care how your servers talk to each other. It uses dependency injection, requiring applications to provide the methods to persist the log and internal state, connect to other servers and apply entries to a state machine. Rather than taking you through Buoyant’s API I figured it’d be more interesting to discuss some of the challenges of implementing Raft on a non-blocking platform like Node.js. Photo by Matthew Clark: https://unsplash.com/photos/_IMinUHfUs0
operations are blocking. For example, during an election a follower must store who its voting for, before telling the candidate it’s voted for them. The follower likely persists that state to disk, and since we’re using Node.js that operation pretty much has to be asynchronous. What would happen if the follower learns a second candidate has become the leader? This too would invoke a state change that has to be persisted to disk. There may now be a race condition between the two persistence operations. In Buoyant this problem may occur in many more scenarios. The solution I arrived at is to implement a scheduler which ensures only a single operation is active at any given time. New messages won’t be handled until Buoyant finishes handling the previous message. Heartbeats and election timeouts, while triggered using setInterval(), also use the scheduler to prevent interleaving with message handling. If you’re interested in the code you can find it on GitHub. I’ll make sure to share the URL later. (For those reading along with the notes, the current version is at https://github.com/novemberborn/buoyant/blob/fa0d5c8020f7e8b9952d1b8278b598c752c679dc/src/ lib/Scheduler.js) Photo by Robert Larsson: https://unsplash.com/photos/UsET4S0ginw
most one message at a time, it doesn’t make sense to read messages from the network streams if the scheduler is still blocked. This would prevent the network layer from applying back-pressure, and increases the amount of memory used by Buoyant itself. To solve this problem I wrote a simplistic message buffer. At most it reads one message from the underlying stream, and if no message is available it listens for the readable event. Messages are only taken from the stream when the scheduler decides they can be handled. (For those reading along with the notes, the current version of the message buffer is at https://github.com/novemberborn/buoyant/blob/ fa0d5c8020f7e8b9952d1b8278b598c752c679dc/src/lib/MessageBuffer.js, and the input consumer that schedules their handling at https://github.com/novemberborn/ buoyant/blob/fa0d5c8020f7e8b9952d1b8278b598c752c679dc/src/lib/InputConsumer.js) Photo by Dan Chung: https://unsplash.com/photos/F_IqJEZZGvo
wrong. It can then be restarted given the state that was persisted to disk. It’s always bad form though to just forcefully exit a process. Buoyant servers must be created with a crash handler callback. If something goes wrong the scheduler will hang, preventing any further operations from occurring. The callback is invoked with the error, allowing the application to decide whether to restart just Buoyant or indeed exit the process. Care is taken to ensure various operations propagate errors to the crash handler. Photo by Blair Fraser: https://unsplash.com/photos/d7CNJOlEY4Y Backstory: http://travel.aol.co.uk/2014/05/30/US-Navy-plane-wreck-black-sand-beach-iceland-pictures/ (all survived)
is a photo of the code coverage report for Buoyant. Are there any bugs in the implementation? For those who said no, you’re correct! But only because I took this photo after fixing a whole raft of bugs (no pun intended (OK that was intentional)). For those who said yes, you’re probably correct as well. The coverage report was exactly the same before I fixed these bugs.
== maybe bugs 100% code coverage does not guarantee your code has no bugs. Less than 100% code coverage means that there are parts of your code that are not tested, so there definitely may be bugs. Code coverage cannot tell you whether you’ve tested all code paths. Nor does it tell you whether you’re implementation is correct.
a viable option. You’re not smart enough either to come up with all the ways your distributed system will fail. Instead you should simulate your system, randomly introducing error scenarios. This is known as fuzz testing. To fuzz Buoyant we want to simulate an entire cluster, managing all network connections and even clocks. We then control which messages are delivered or dropped, and in what order. We control which persistence operations succeed or fail. We control when each server’s clock advances, triggering elections or the sending of heartbeats. We can create network partitions and kill servers, as well as restart them. We can send new commands to the leader. By generating these behaviours randomly, and within a single Node.js process, we can quickly expose our system to the worst of conditions. Photo by Chan Swan: https://unsplash.com/photos/hV67XIAzc4c
behaviour of the Raft cluster. Raft makes five guarantees, each of which needs to hold for a Raft cluster to behave correctly: Photo by Glenn Carstens-Peters: https://unsplash.com/photos/rTO4hjAgbDU
the same index in their logs, then all preceding entries must also be the same. Photo by Glenn Carstens-Peters: https://unsplash.com/photos/rTO4hjAgbDU
the same order. At the right moments the fuzzer verifies that these predicates hold. If they don’t the fuzzer exits with an error. Photo by Glenn Carstens-Peters: https://unsplash.com/photos/rTO4hjAgbDU
implement a network layer or persist state. This means the fuzzer can inject its own network layer. Photo by Julia Caesar: https://unsplash.com/photos/asct7UP3YDE
timers are stubbed using lolex, allowing a Buoyant server to be fully simulated. You may need to add more code to your own applications for them to be tested like this. For instance Buoyant doesn’t use setInterval() directly. Instead it uses an object which wraps these timer methods, allowing lolex to stub each server’s timers independently. lolex: https://www.npmjs.com/package/lolex Photo by Julia Caesar: https://unsplash.com/photos/asct7UP3YDE
listen for uncaught exceptions, which of course shouldn’t occur during the fuzz test. Similarly you should listen for unhandled promise rejections. This is how I found a bug that was hiding inside a promise chain. Photo by Julia Caesar: https://unsplash.com/photos/asct7UP3YDE
made three other improvements, all due to the fuzzer. Fuzz testing lets you exercise your code in the worst of conditions, before deploying to production. It’s not necessarily easy though. You have to be able to control network traffic and clocks, simulate crashes, and so on. You’ll generate a lot of log data that is hard to sift through. It’s hard to balance the probabilities of various fuzz events such that the desired failure scenarios do occur. I know I haven’t yet gotten this right, and it’ll probably require statistical analysis for proper fine tuning. Other scenarios you might trigger aren’t necessarily failures, but they’re just really inefficient. You need to look at the logs to spot these. Debugging is hard when it can take hundreds or thousands of iterations before a bug is triggered. This is where setting conditional breakpoints helps, as does the new Chrome Inspector support in Node.js v6.3.0. I was inspired to write a fuzzer for my Raft implementation due to a blog post by Colin Scott, titled Fuzzing Raft for Fun and Publication. In his research paper he also describes ways of minimising fuzzer logs in order to find the shortest number of steps required to produce an error. I didn’t quite go that far but it’s surely interesting. Blog post: http://colin-scott.github.io/blog/2015/10/07/fuzzing-raft-for-fun-and-profit/ Photo by Jordan Whitt: https://unsplash.com/photos/EerxztHCjM8
better uptime, avoiding data loss and distributing load. We’ve also seen how distributed systems can fail and how Raft provides an algorithm that deals with those failures in order to deliver the benefits of distributed systems. We’ve discussed ways of implementing a blocking algorithm in Node.js using a custom scheduler, as well as ways to fairly and carefully read from multiple streams. We’ve seen how unit tests and impressive code coverage numbers are no guarantees for a faultless system. And finally we’ve seen how fuzz testing can be used to expose your code to the worst case scenarios, without requiring you to explicitly design such scenarios. I hope you can apply some of these techniques to your own projects. Photo by Clem Onojeghuo: https://unsplash.com/photos/r8lDTtSWGUc
it easier to build distributed systems that fit your needs. I want applications to embrace distributedness, not obscure it behind other technologies. And sure, such new frameworks may not be faster than Etcd or Kafka but they can make you more productive. And that’s what’s most important to get a project going. You can find Buoyant’s source code on my GitHub: https://github.com/novemberborn/buoyant. If you have questions about certain implementation details feel free to open an issue. And if you want to help out there’s plenty of FIXME’s and TODO’s left Photo by Andrew Knechel: https://unsplash.com/photos/gG6yehL64fo
listening (and you for reading)! If you have any questions please get in touch by email or on Twitter. See https://novemberborn.net/ and http://twitter.com/ novemberborn. I’ll also be available for contracting later this summer. Photo by Lance Anderson: https://unsplash.com/photos/2Q8zDWkj0Yw
Clem Onojeghuo Dan Chung Denys Nevozhai Elliott Stallion Evan Dennis Frédérique Voisin-Demery Gláuber Sampaio Glenn Carstens-Peters Henry Hustava Jay Mantri Jesse Bowser John-Mark Kuznietsov Jordan Whitt Joshua Stannard Julia Caesar Kevin Poh Lance Anderson Maarten van den Heuvel Mathias Appel Matthew Clark Radek Grzybowski Robert Larsson Staat der Nederlanden Troy Oldham William Hook Zach Betten Photos by these wonderful people, and my country of birth. Photo by Denys Nevozhai: https://unsplash.com/photos/RRNbMiPmTZY
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}