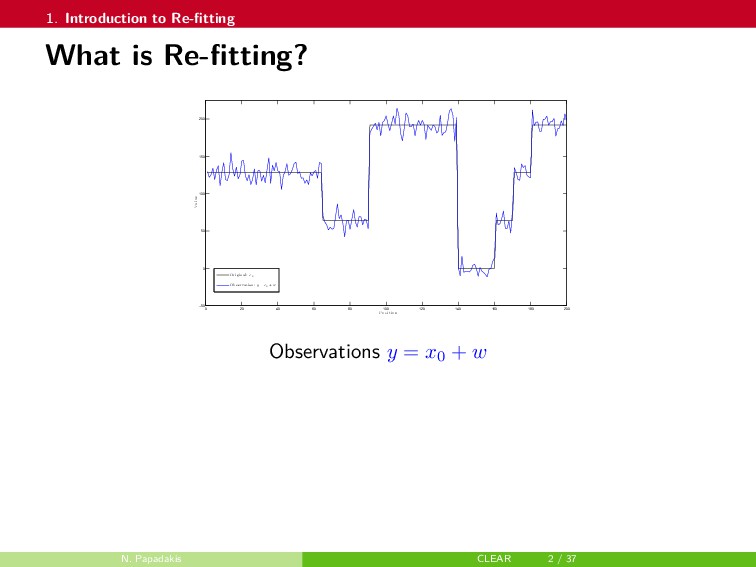
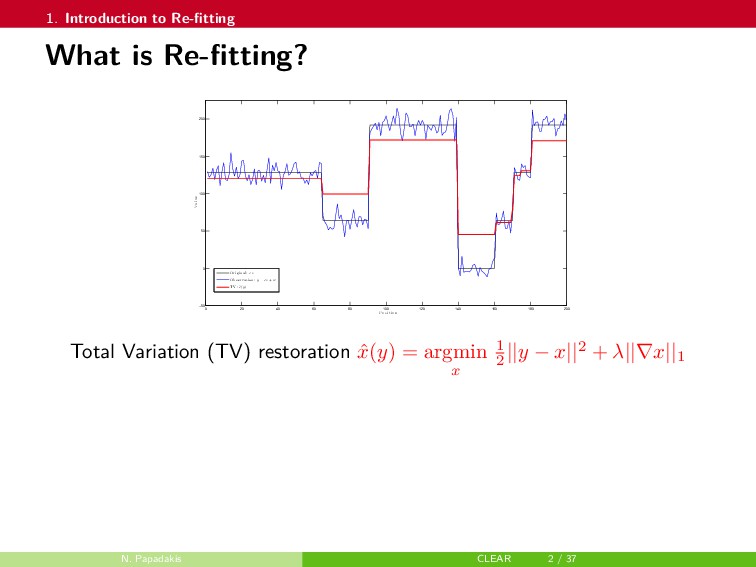
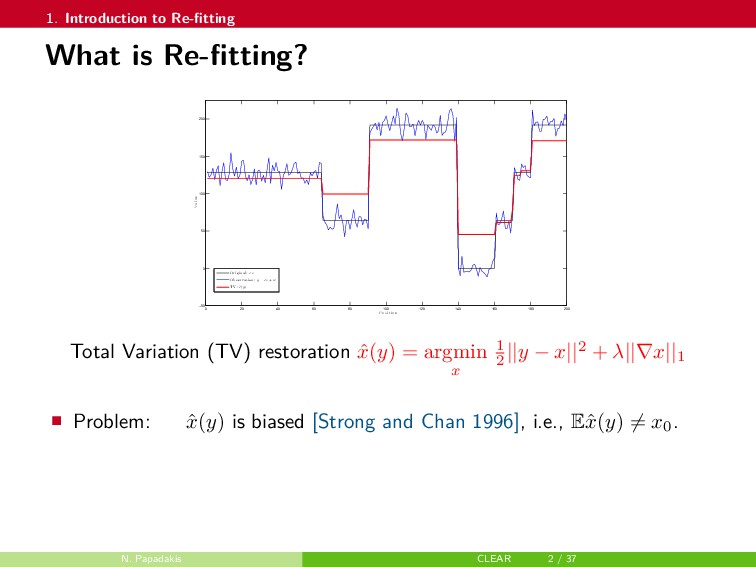
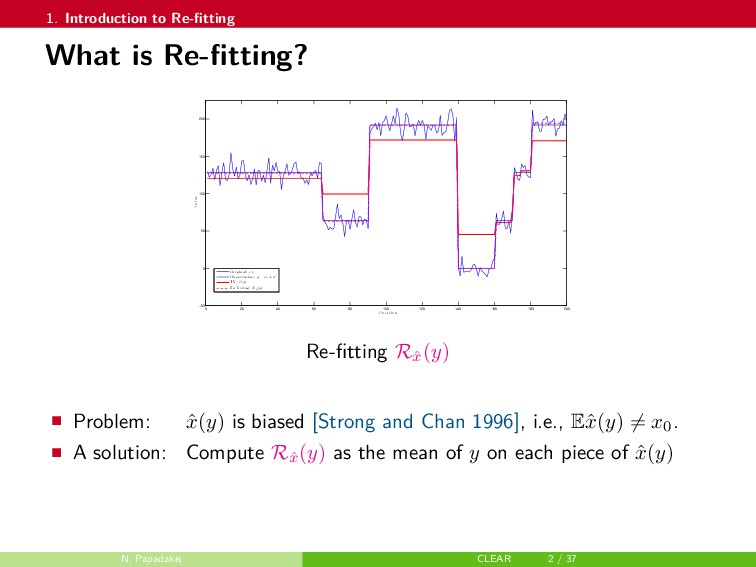
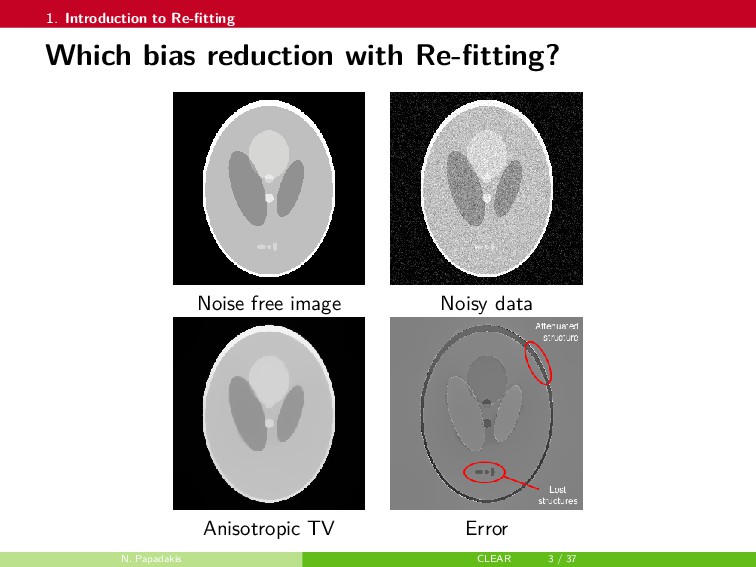
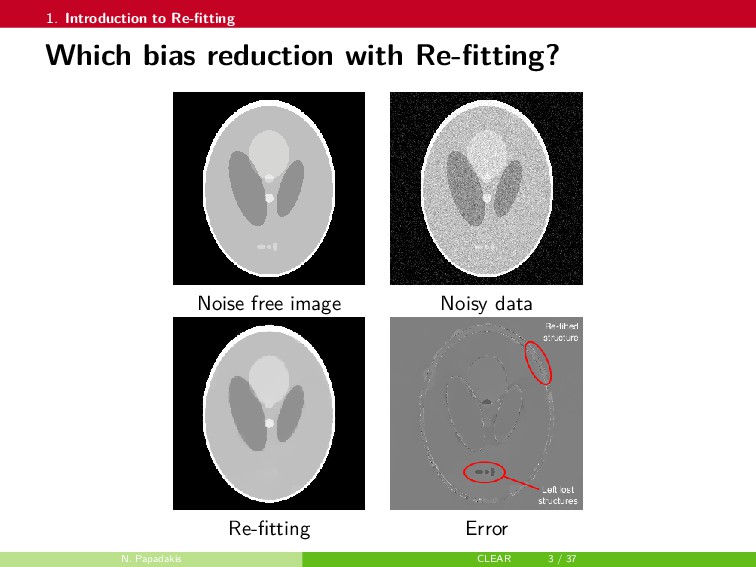
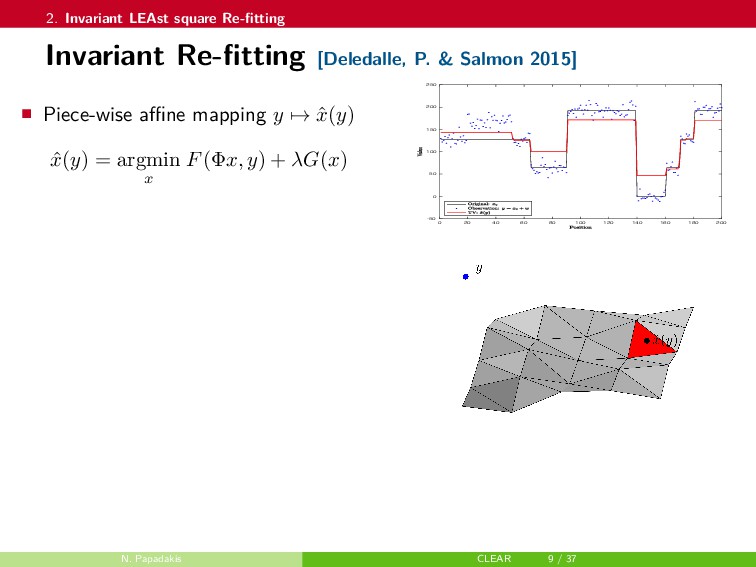
In this talk, a framework to remove parts of the systematic errors affecting popular restoration algorithms is presented, with a special focus on image processing tasks. Generalizing ideas that emerged for ℓ1 regularization, an approach re-fitting the results of standard methods towards the input data is developed. Total variation regularization and non-local means are special cases of interest. Important covariant information that should be preserved by the re-fitting method are identified, and the importance of preserving the Jacobian (w.r.t. the observed signal) of the original estimator is emphasized. Then, a numerical approach is proposed. It has a twicing flavor and allows re-fitting the restored signal by adding back a local affine transformation of the residual term. The benefits of the method are illustrated on numerical simulations for image restoration tasks.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![1. Introduction to Re-fitting Related works Twicing [Tukey, 1977], Bregman](https://files.speakerdeck.com/presentations/870e923c5ed04d3891ad9b7a75a04b0e/slide_10.jpg){kind=link}
![1. Introduction to Re-fitting Related works Twicing [Tukey, 1977], Bregman](https://files.speakerdeck.com/presentations/870e923c5ed04d3891ad9b7a75a04b0e/slide_11.jpg){kind=link}
![1. Introduction to Re-fitting Related works Twicing [Tukey, 1977], Bregman](https://files.speakerdeck.com/presentations/870e923c5ed04d3891ad9b7a75a04b0e/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
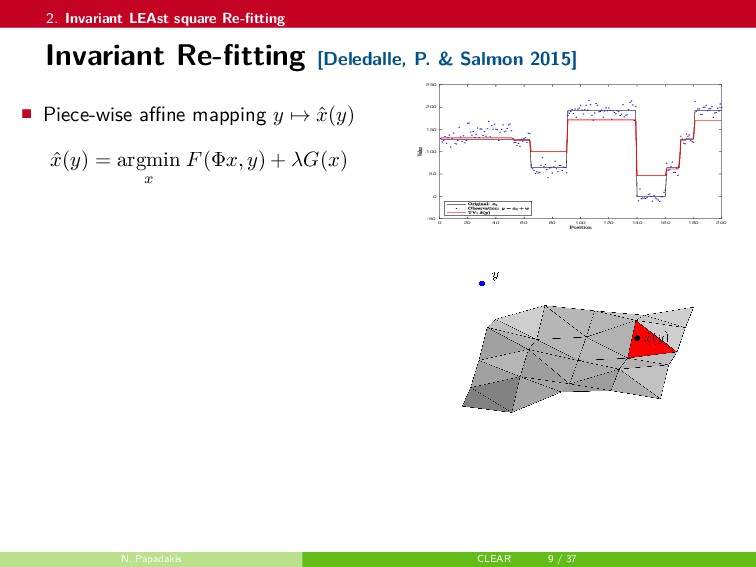{kind=link}
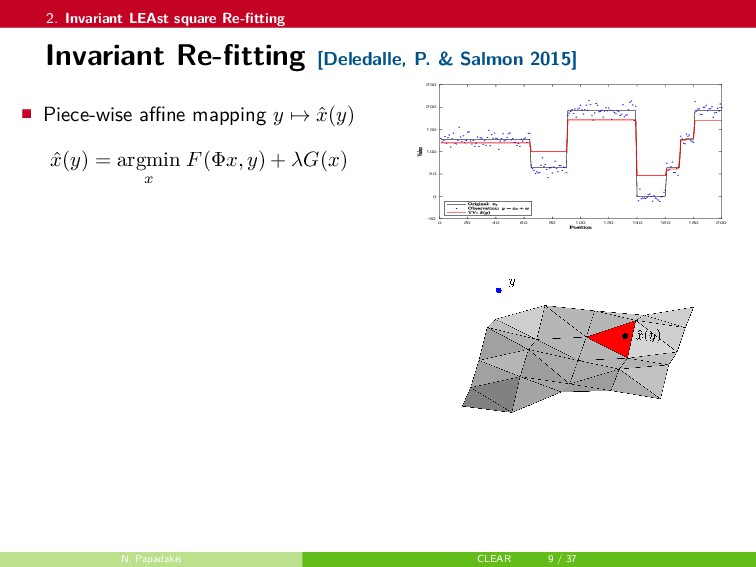{kind=link}
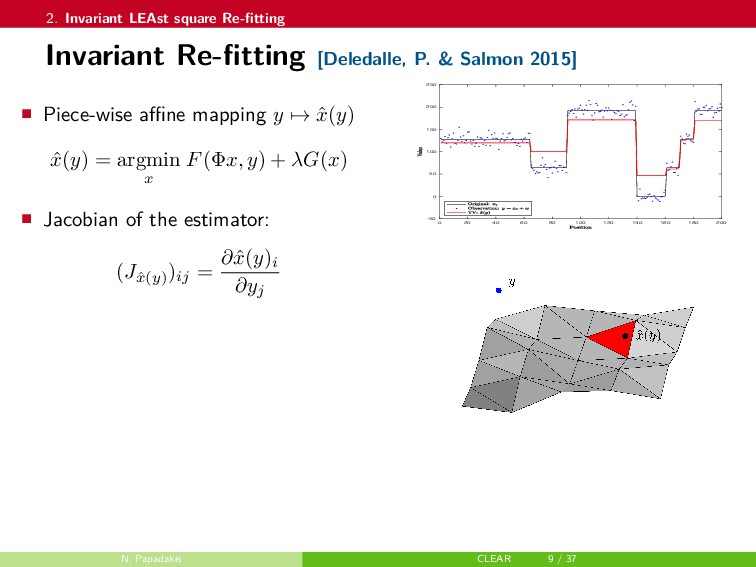{kind=link}
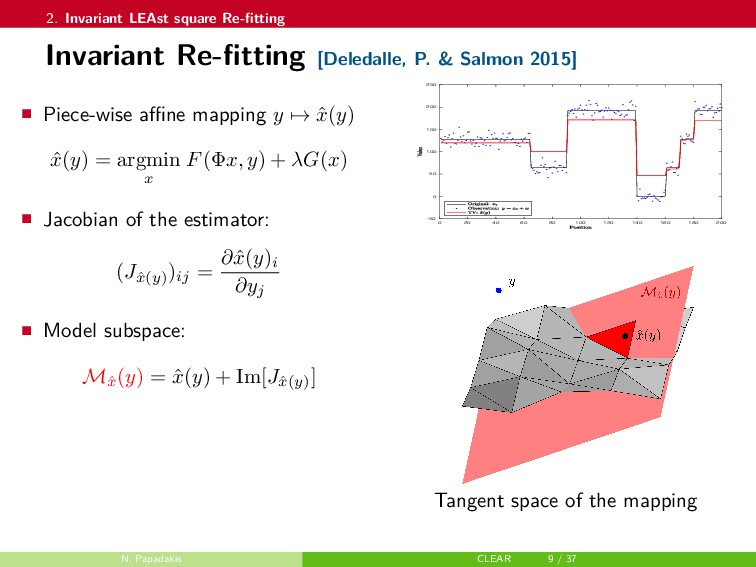{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
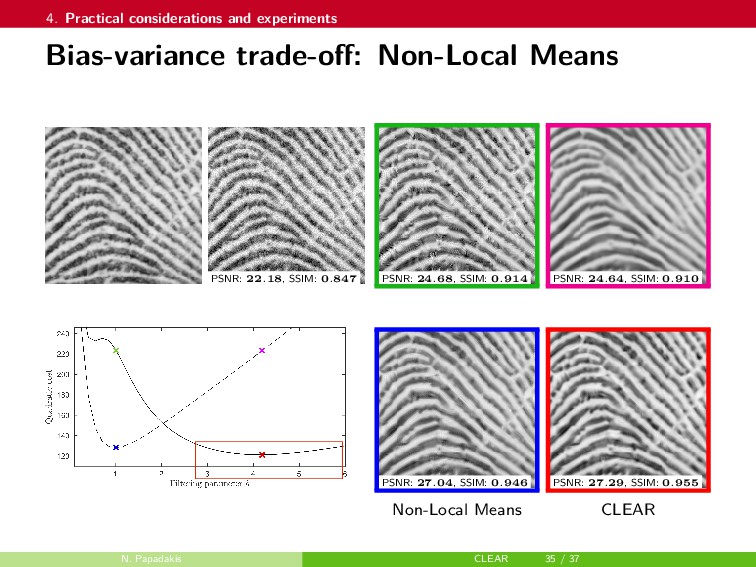
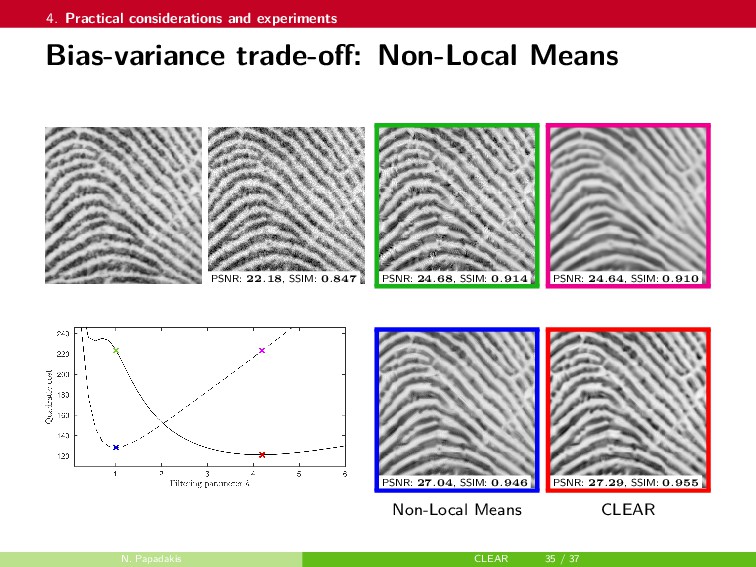{kind=link}
{kind=link}
{kind=link}
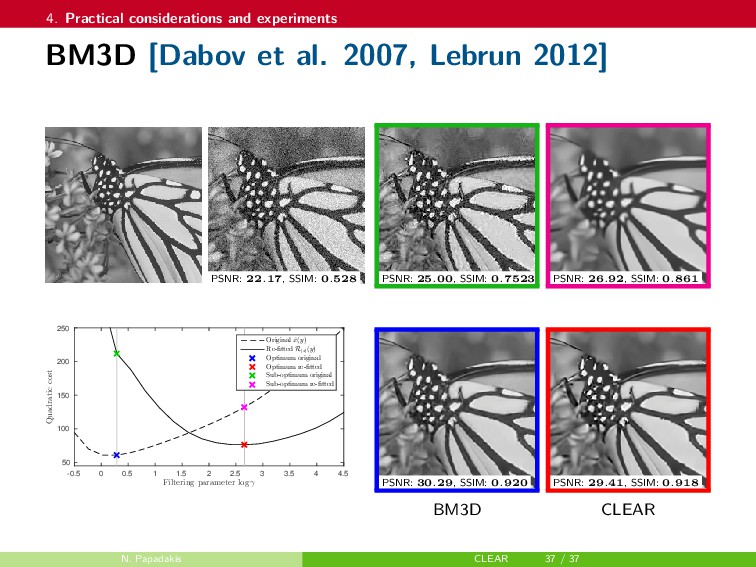{kind=link}
![4. Practical considerations and experiments DDID [Knaus & Zwicker 2013]](https://files.speakerdeck.com/presentations/870e923c5ed04d3891ad9b7a75a04b0e/slide_79.jpg){kind=link}
![4. Practical considerations and experiments DnCNN [Zhang et al., 2017]](https://files.speakerdeck.com/presentations/870e923c5ed04d3891ad9b7a75a04b0e/slide_80.jpg){kind=link}
![4. Practical considerations and experiments DnCNN [Zhang et al., 2017]](https://files.speakerdeck.com/presentations/870e923c5ed04d3891ad9b7a75a04b0e/slide_81.jpg){kind=link}
![4. Practical considerations and experiments DnCNN [Zhang et al., 2017]](https://files.speakerdeck.com/presentations/870e923c5ed04d3891ad9b7a75a04b0e/slide_82.jpg){kind=link}
![4. Practical considerations and experiments DnCNN [Zhang et al., 2017]](https://files.speakerdeck.com/presentations/870e923c5ed04d3891ad9b7a75a04b0e/slide_83.jpg){kind=link}
![4. Practical considerations and experiments DnCNN [Zhang et al., 2017]](https://files.speakerdeck.com/presentations/870e923c5ed04d3891ad9b7a75a04b0e/slide_84.jpg){kind=link}
![4. Practical considerations and experiments DnCNN [Zhang et al., 2017]](https://files.speakerdeck.com/presentations/870e923c5ed04d3891ad9b7a75a04b0e/slide_85.jpg){kind=link}
![4. Practical considerations and experiments DnCNN [Zhang et al., 2017]](https://files.speakerdeck.com/presentations/870e923c5ed04d3891ad9b7a75a04b0e/slide_86.jpg){kind=link}
![4. Practical considerations and experiments FFDNet [Zhang et al., 2018]](https://files.speakerdeck.com/presentations/870e923c5ed04d3891ad9b7a75a04b0e/slide_87.jpg){kind=link}
![4. Practical considerations and experiments FFDNet [Zhang et al., 2018]](https://files.speakerdeck.com/presentations/870e923c5ed04d3891ad9b7a75a04b0e/slide_88.jpg){kind=link}
![4. Practical considerations and experiments FFDNet [Zhang et al., 2018]](https://files.speakerdeck.com/presentations/870e923c5ed04d3891ad9b7a75a04b0e/slide_89.jpg){kind=link}
![4. Practical considerations and experiments FFDNet [Zhang et al., 2018]](https://files.speakerdeck.com/presentations/870e923c5ed04d3891ad9b7a75a04b0e/slide_90.jpg){kind=link}
![4. Practical considerations and experiments FFDNet [Zhang et al., 2018]](https://files.speakerdeck.com/presentations/870e923c5ed04d3891ad9b7a75a04b0e/slide_91.jpg){kind=link}
![4. Practical considerations and experiments FFDNet [Zhang et al., 2018]](https://files.speakerdeck.com/presentations/870e923c5ed04d3891ad9b7a75a04b0e/slide_92.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![5. Conclusions Main related references [Brinkmann, Burger, Rasch and Sutour]](https://files.speakerdeck.com/presentations/870e923c5ed04d3891ad9b7a75a04b0e/slide_96.jpg){kind=link}