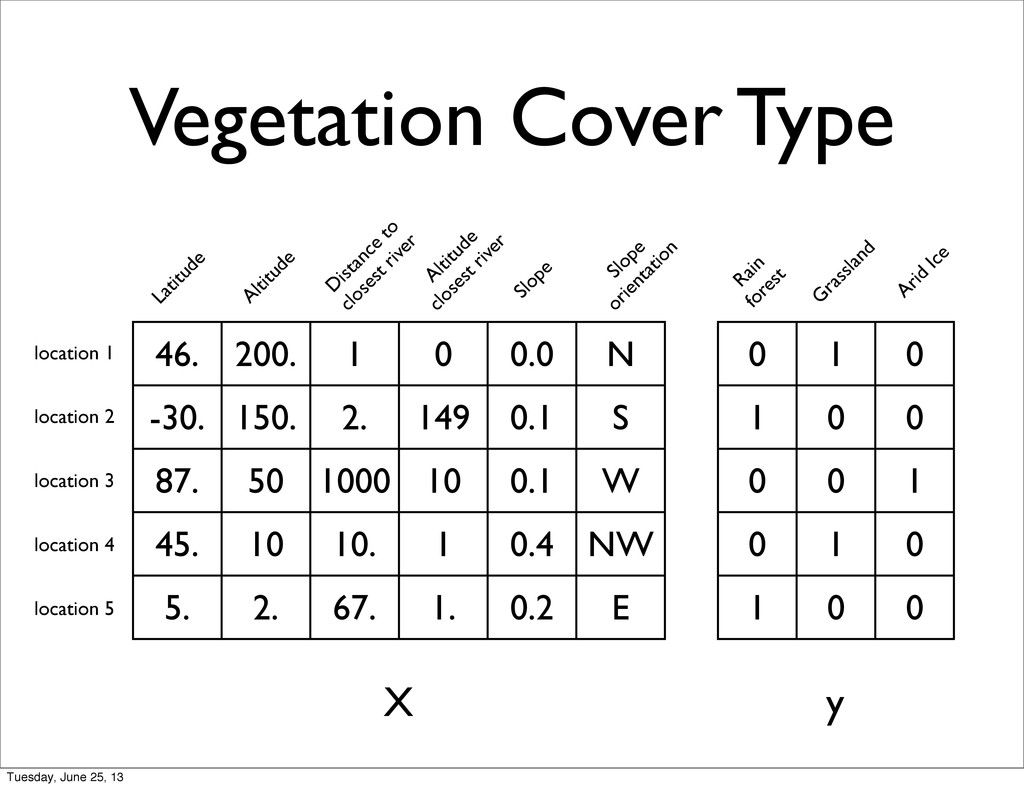
of all users • Ad-Placement / bidding in Web Pages Given user browsing history / keywords • Fraud detection Given features derived from behavior Tuesday, June 25, 13
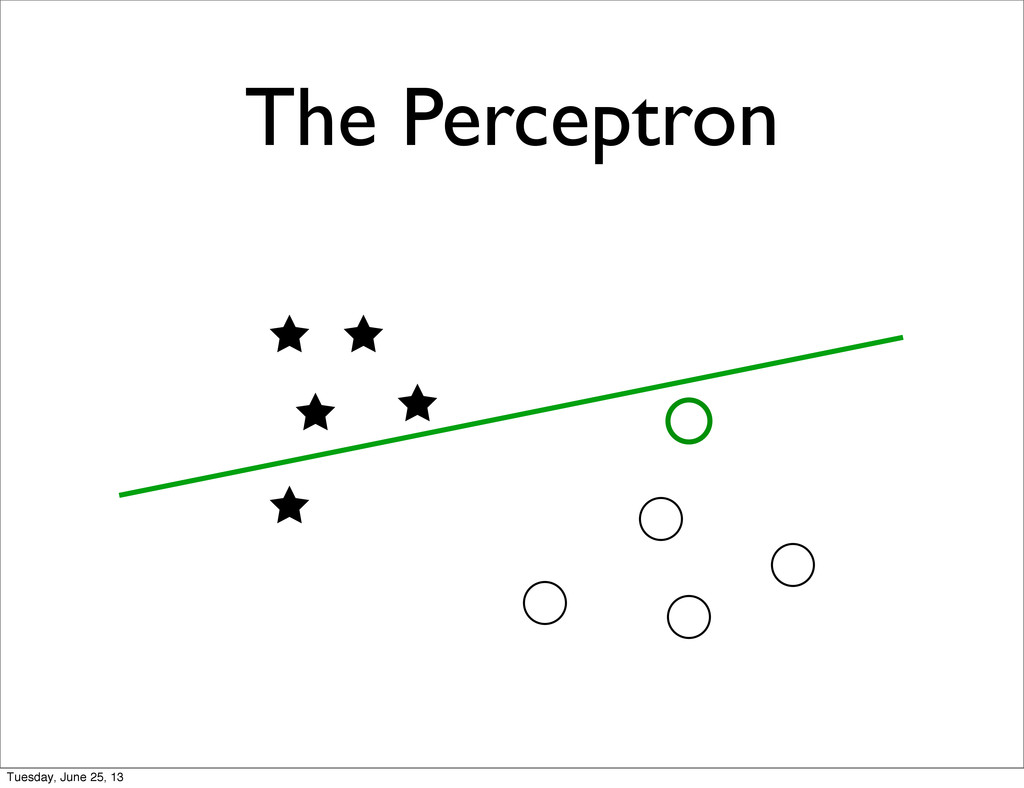
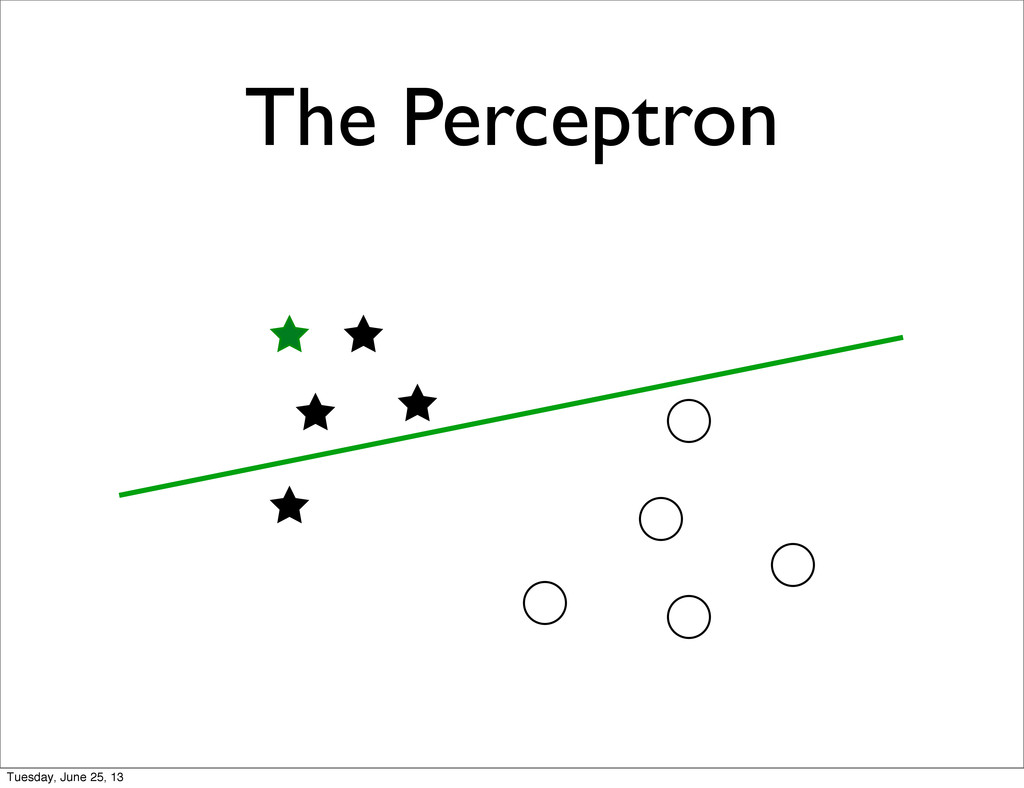
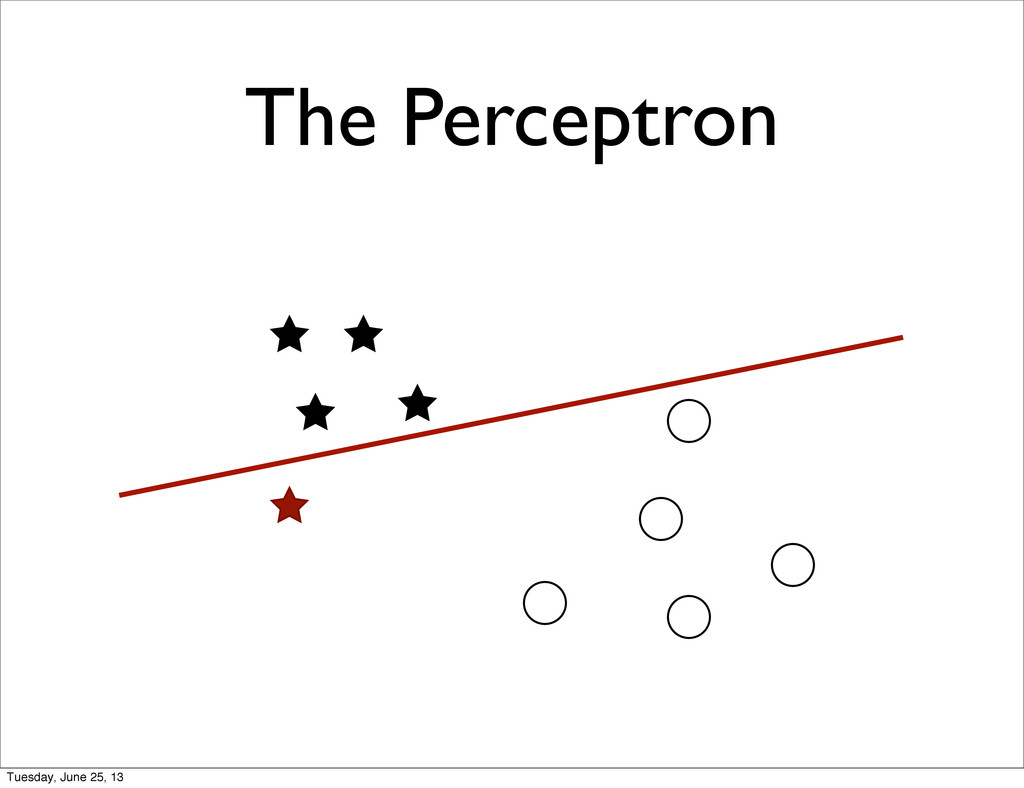
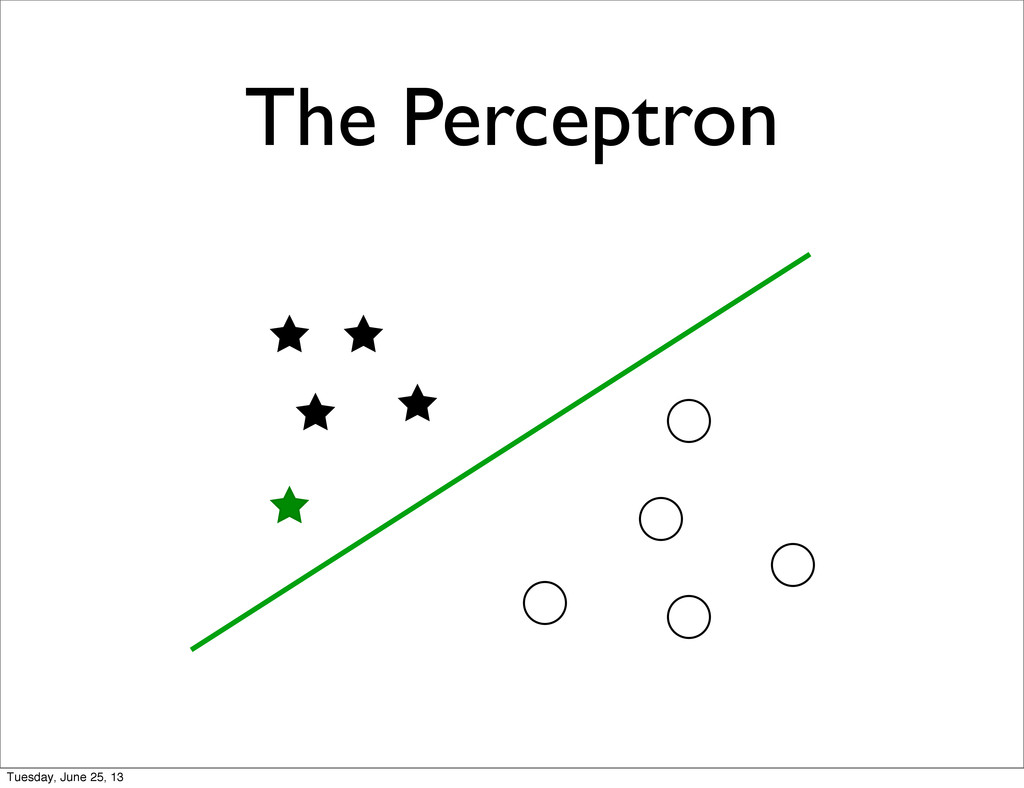
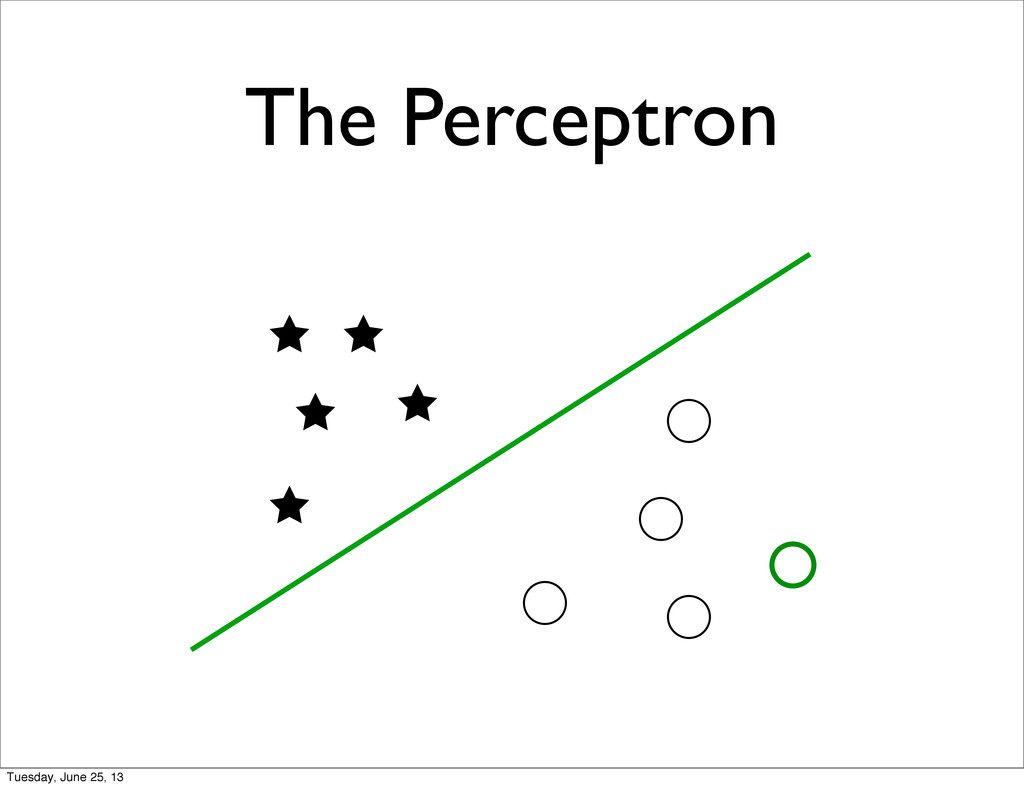
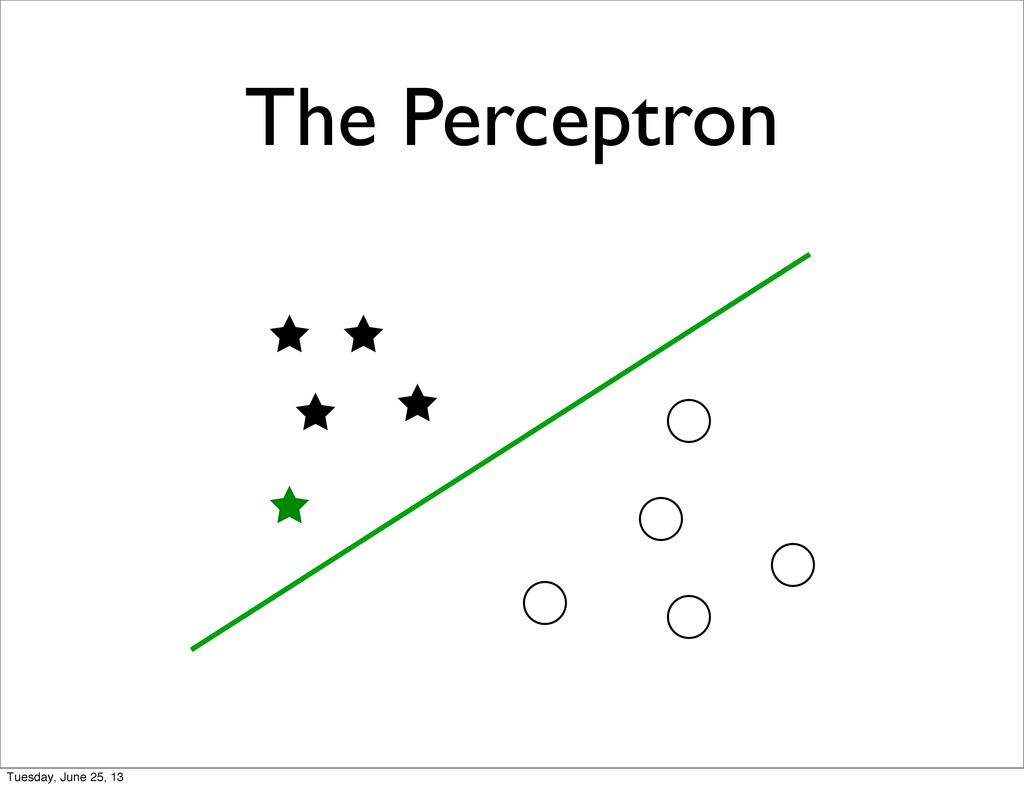
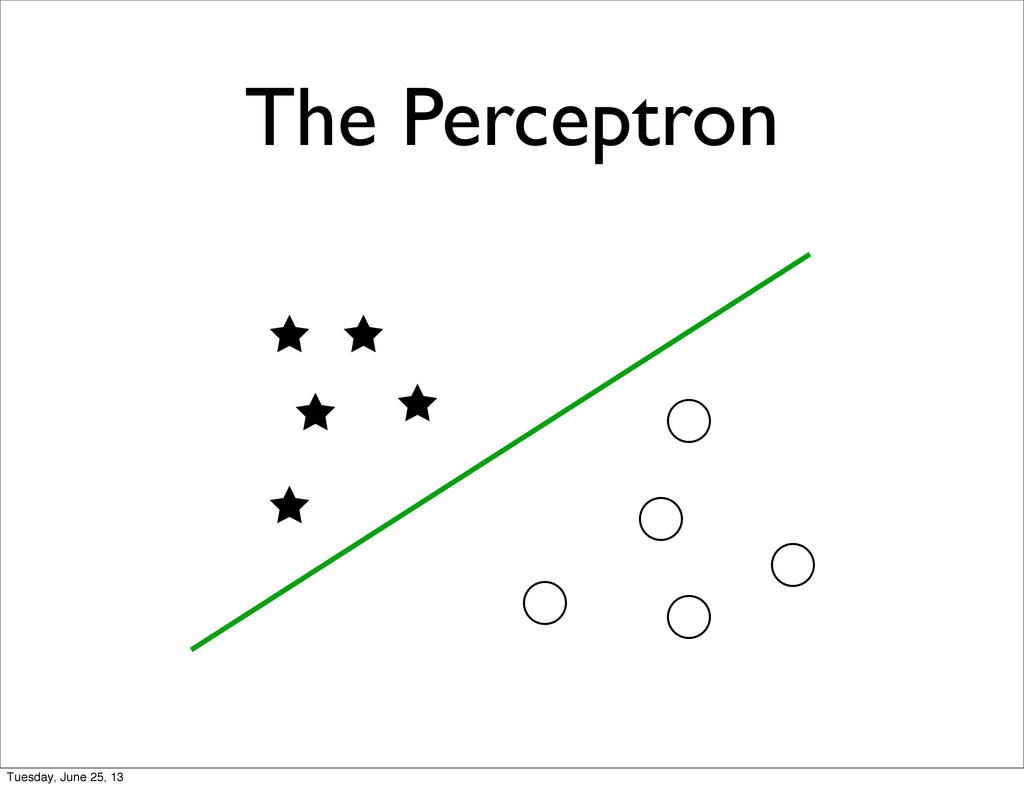
specific • + Feature Normalization / Transformation • Unmet Statistical Assumptions • Linear Separability of the target classes • Correlations between features • Natural metric to for the features Tuesday, June 25, 13
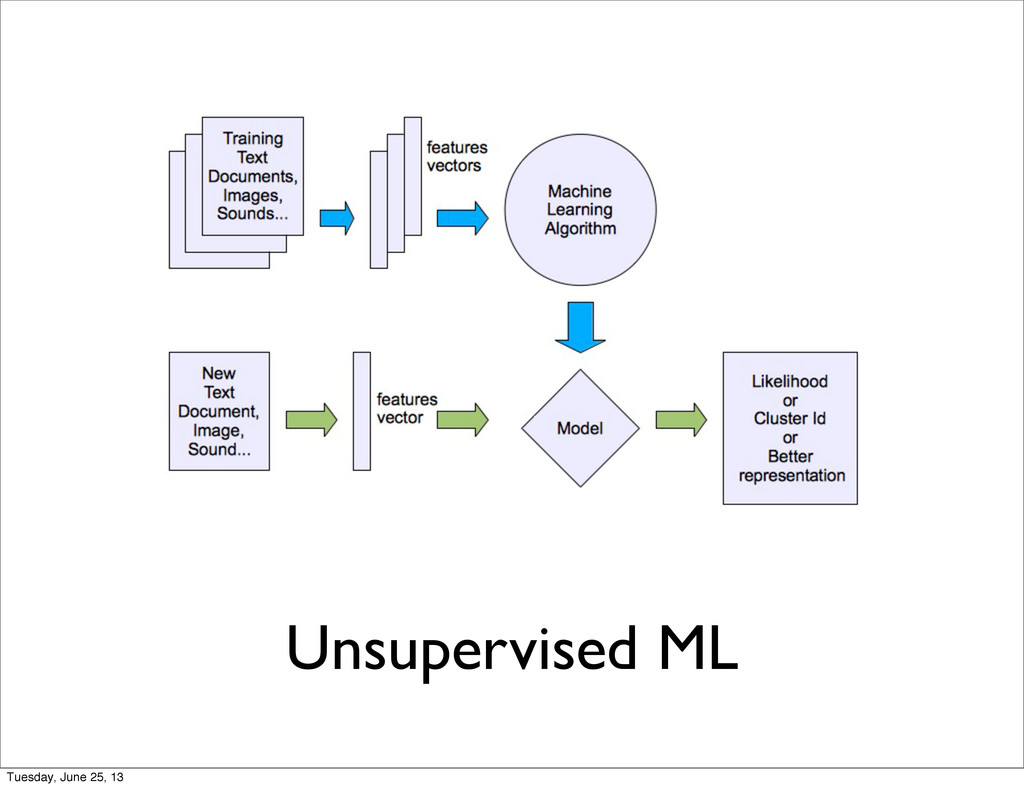
what they learned. Expert knowledge required to understand the model behavior and gain deeper insight on the data: this is model specific. Tuesday, June 25, 13
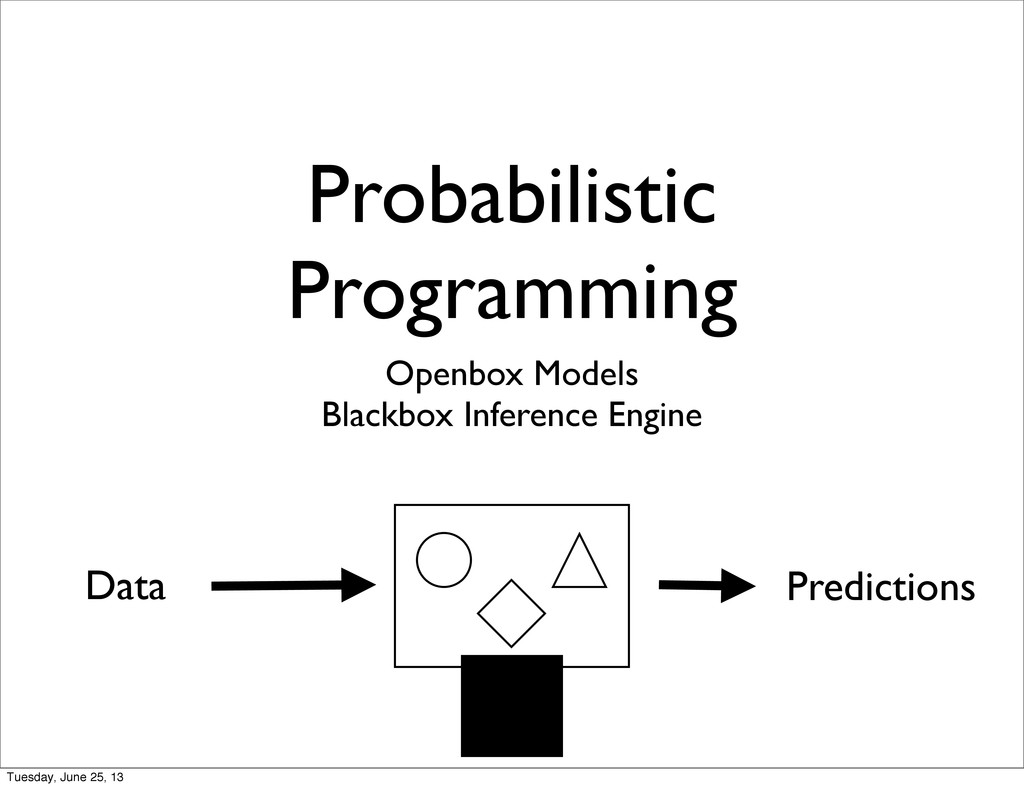
feature extraction with Deep Learning • Problem #2: Lack of Explainability • Probabilistic Programming with generic inference engines Tuesday, June 25, 13
phenomenon with random variables • Write a programmatic story to derive observables from unknown variables • Plug data into observed variables • Use engine to invert the story and assign prob. distributions to unknown params. Tuesday, June 25, 13
Start from a Random Point • Move variable values randomly • Reject with new sample randomly depending on a likelihood test • Accumulate non-rejected samples and call it the trace Tuesday, June 25, 13
Deterministic Approximations: ‣ Mean Field Approximation ‣ Variational Bayes and VMP Only is VMP seems as generic as MCMC for Prob. Programming Tuesday, June 25, 13
with R bindings • PyMC: in Python / NumPy / Theano • Prob. Programming with VMP • Infer.NET (C#, F#..., academic use only) • Infer.py (pythonnet bindings, very alpha) Tuesday, June 25, 13
tells a Generative Story • Story Telling is good for Human Understanding and Persuasion • Grounded in Quantitative Analysis and the sound theory of Bayesian Inference • Black Box inference Engine (e.g. MCMC): ‣ can be treated as Compiler Optimization Tuesday, June 25, 13
Highly nonlinear dependencies lead to highly multi-modals posterior • Hard to mix between posterior modes: slow convergence • How to best build models? How to choose priors? Tuesday, June 25, 13
for scalability of MCMC for some model classes (in Stan and PyMC3 with Theano) • VMP (orig. paper 2005, generalized in 2011) in Infer.NET • New DARPA Program (2013-2017) to fund research on Prob. Programming. Tuesday, June 25, 13
Hackers • Creative Commons Book on Github • Uses PyMC & IPython notebook • Doing Bayesian Data Analysis • Book with example in R and BUGS Tuesday, June 25, 13
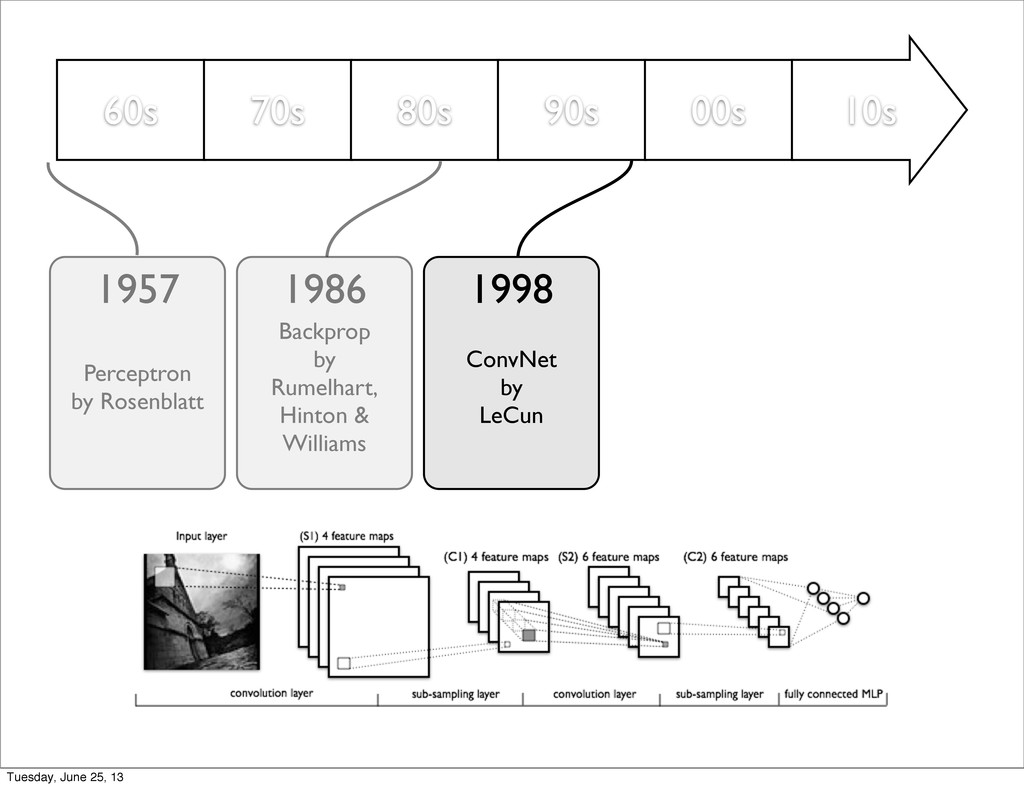
deep hierarchies • Shared weights in convolution kernel reduce the total number of parameters hence limit the over-fitting problem of nets • On works if task in translation invariant in original feature space Tuesday, June 25, 13
trees depth • Number of non-linearities between the unobserved “True”, “Real-World” factors of variations (causes) and the observed data (e.g. pixels in a robot’s camera) • A decision tree prediction function can be factored as a sum of products: depth = 1 Tuesday, June 25, 13
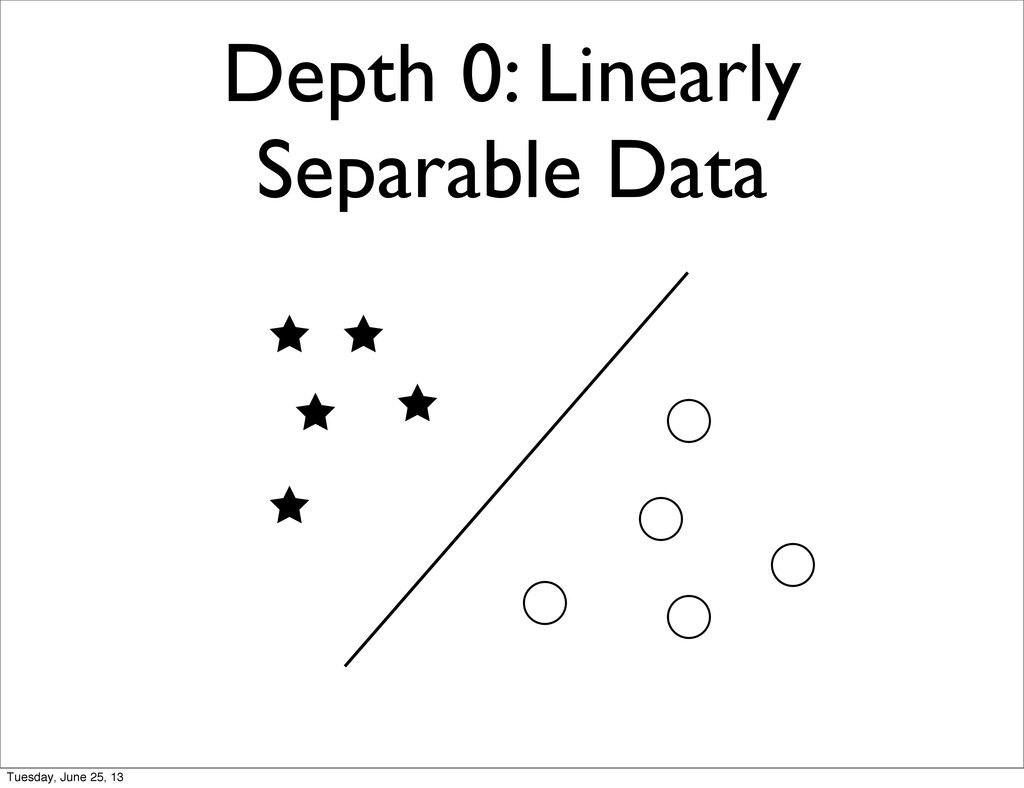
Logistic Regression, Multinomial Naive Bayes Depth 1: NN with 1 hidden Layer, Non-linear SVM, Decision Trees Depth 2: NN with 2 hidden Layers, Ensembles of Trees Tuesday, June 25, 13
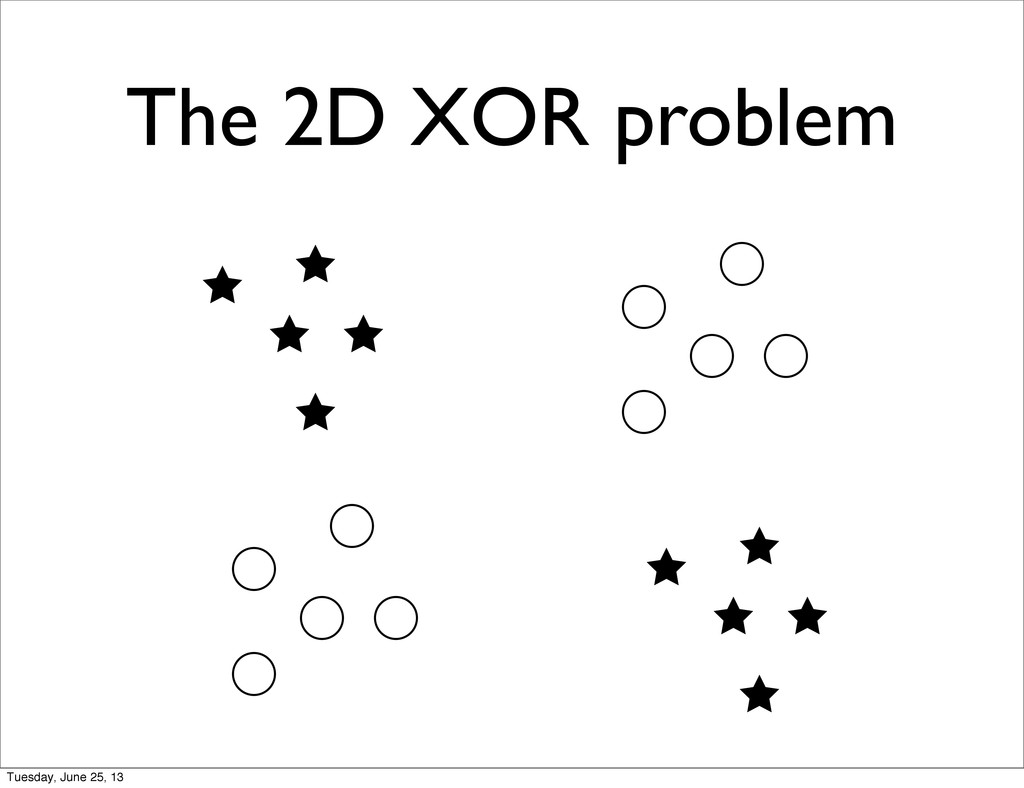
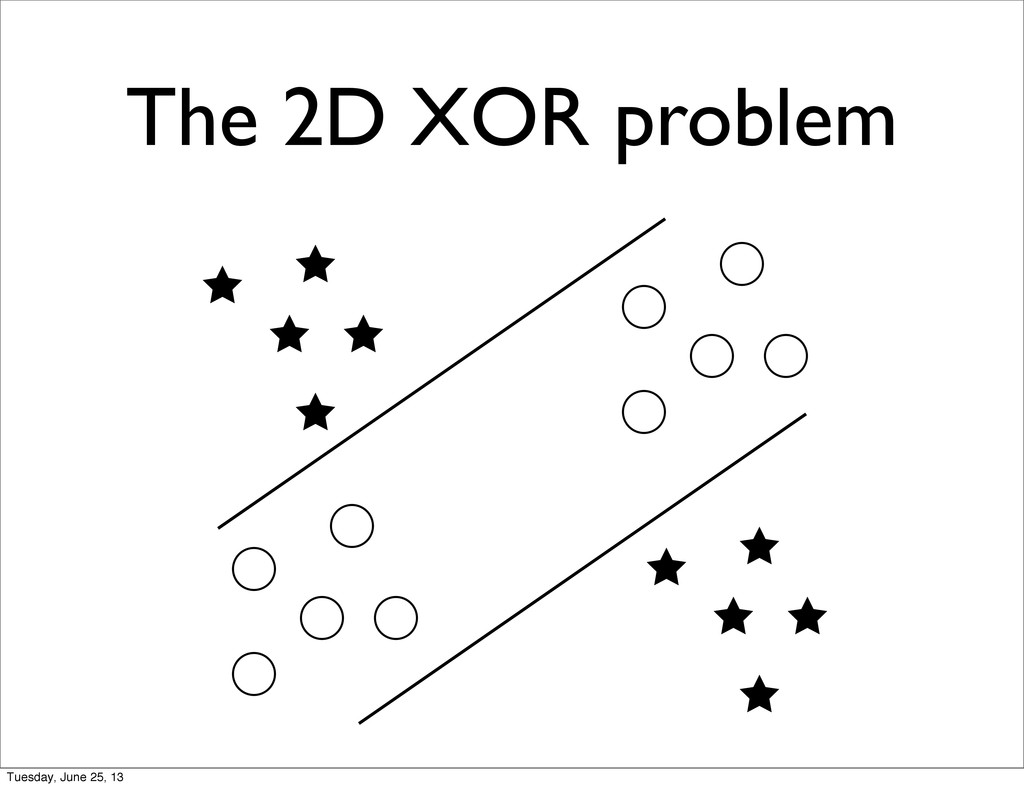
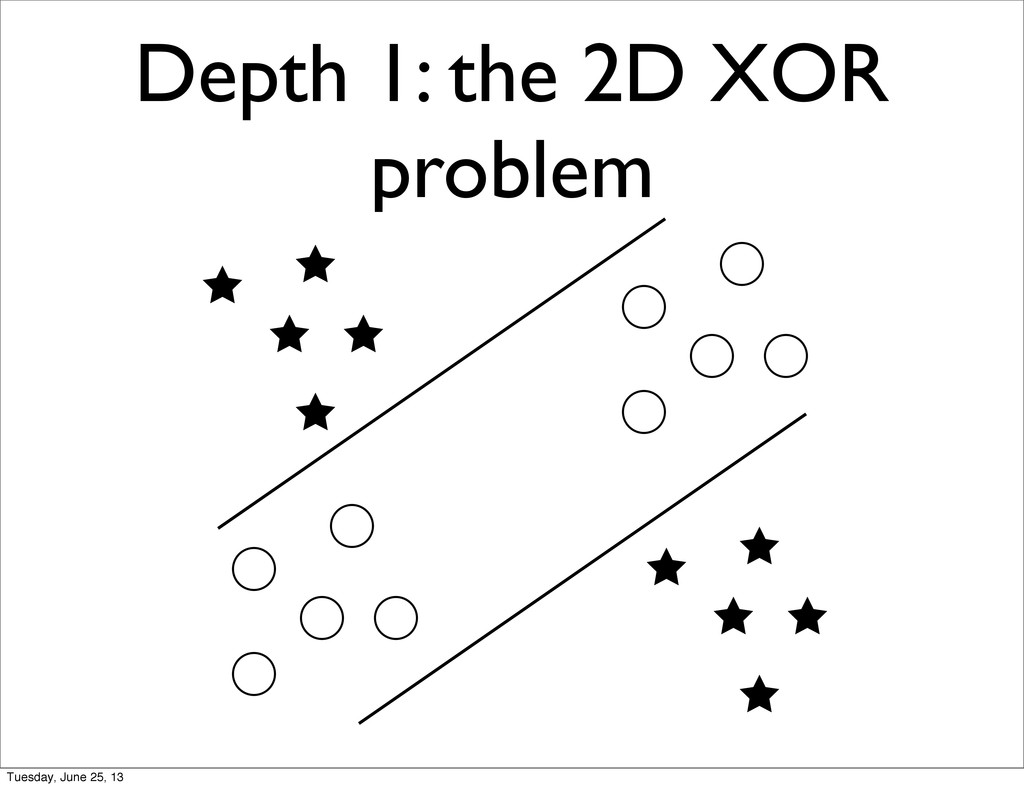
Function: given N boolean variables, return 1 if number of positive values is even, 0 otherwise • Depth 1 models can learn the parity function but: • Need ~ 2^N hidden nodes / SVs • Require 1 example per local variation Tuesday, June 25, 13
function can be learned by depth-2 NN with a number of hidden unit that grows linearly with the dimensionality of the problem • Similar results for the Checker Board learning task Tuesday, June 25, 13
moved away from NN • SVM with kernel: less hyper-parameters • Random Forests / Boosted Trees often beat all other models when enough labeled data and CPU time • The majority of kaggle winners use ensemble of trees (up until recently...) Tuesday, June 25, 13
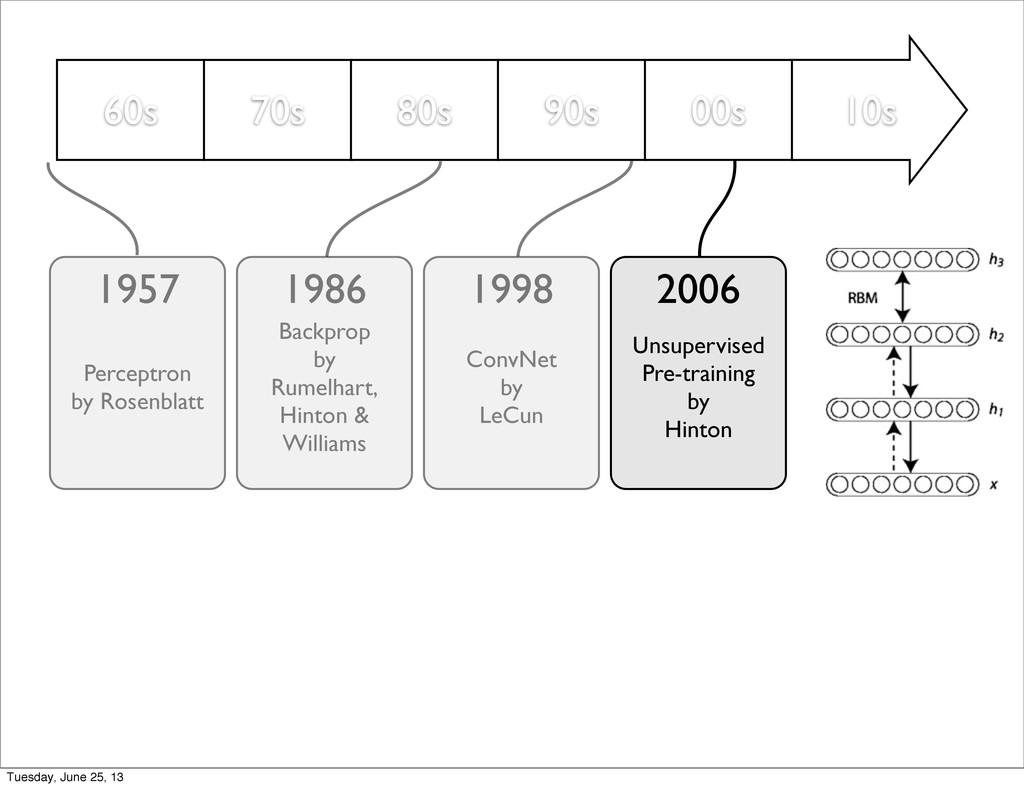
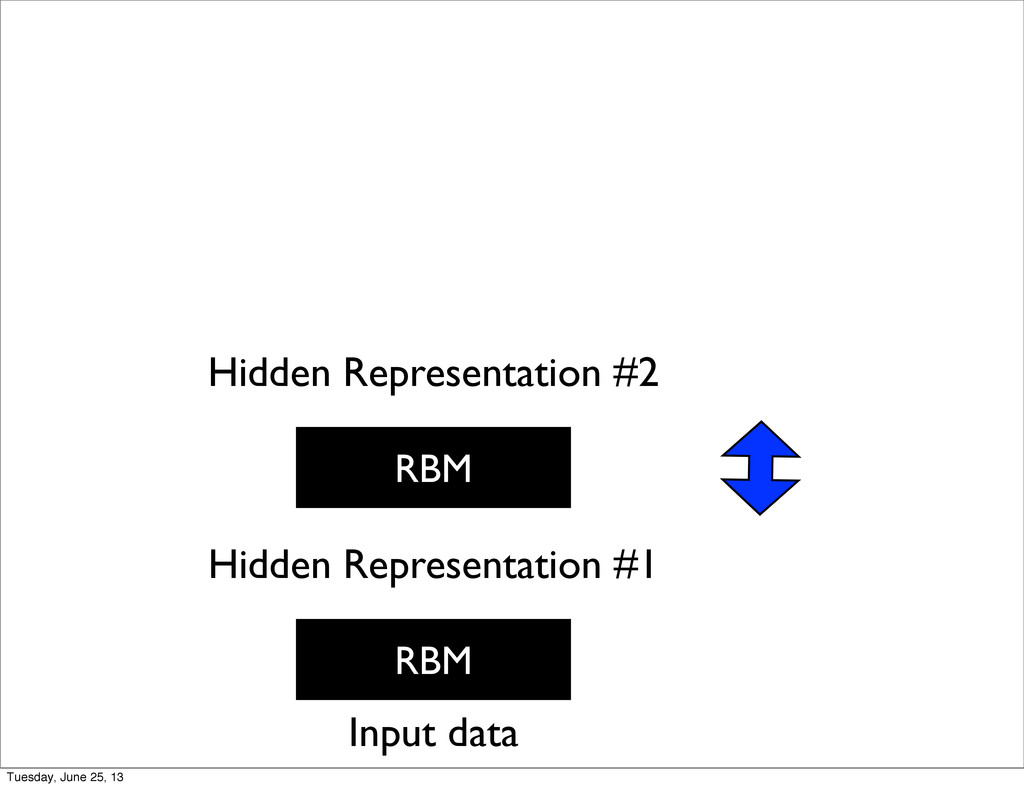
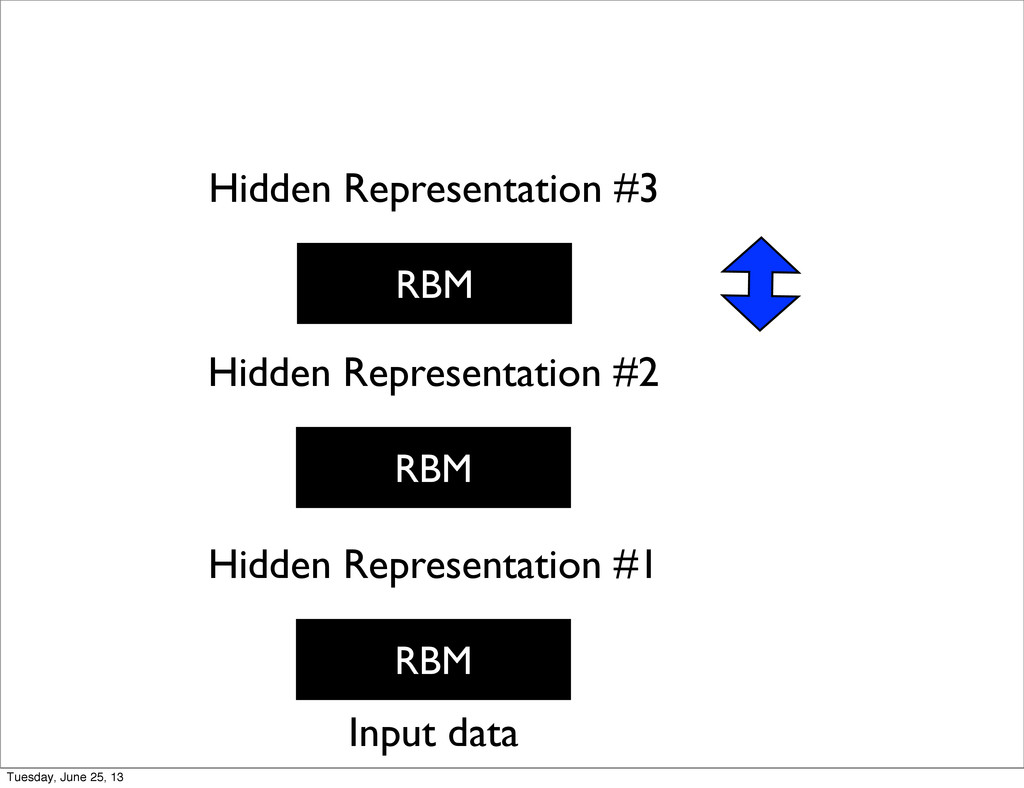
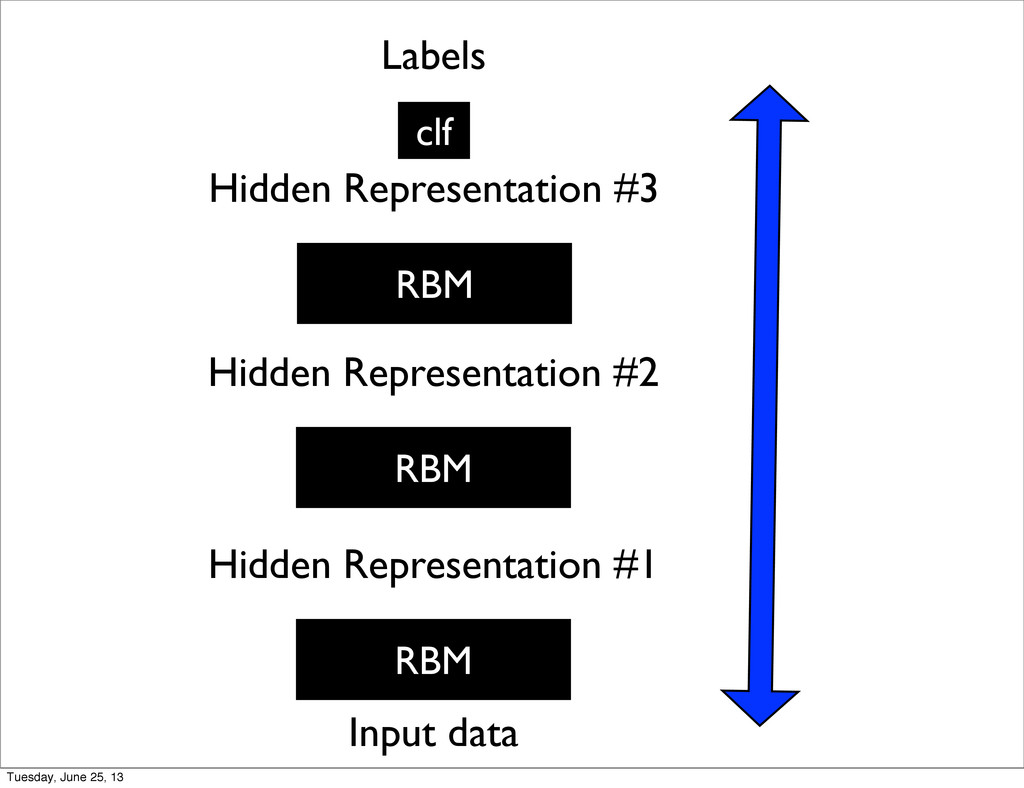
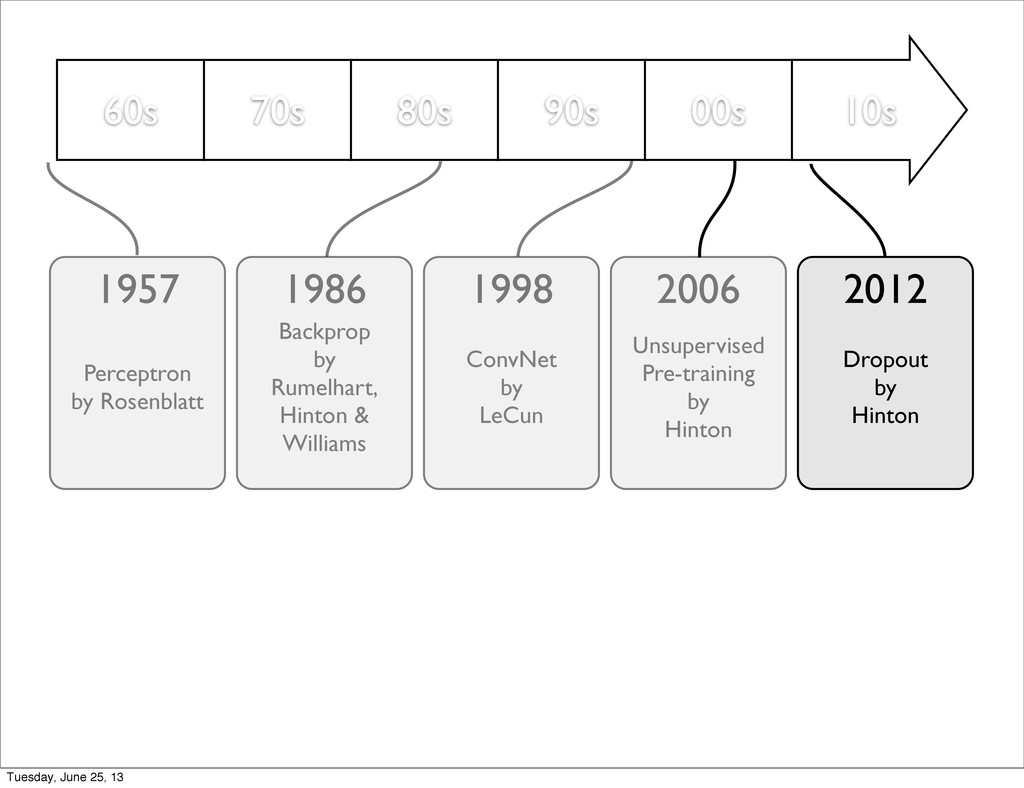
U. of Toronto • Unsupervised Pre-training of Deep Architectures (Deep Belief Networks) • Can be unfolded into a traditional NN for fine tuning Tuesday, June 25, 13
of Montreal • Ng et al. in Stanford • Replaced RBM with various other models such as Auto-Encoders in a denoising setting or with a sparsity penalty • Started to reach state of the art in speech recognition Tuesday, June 25, 13
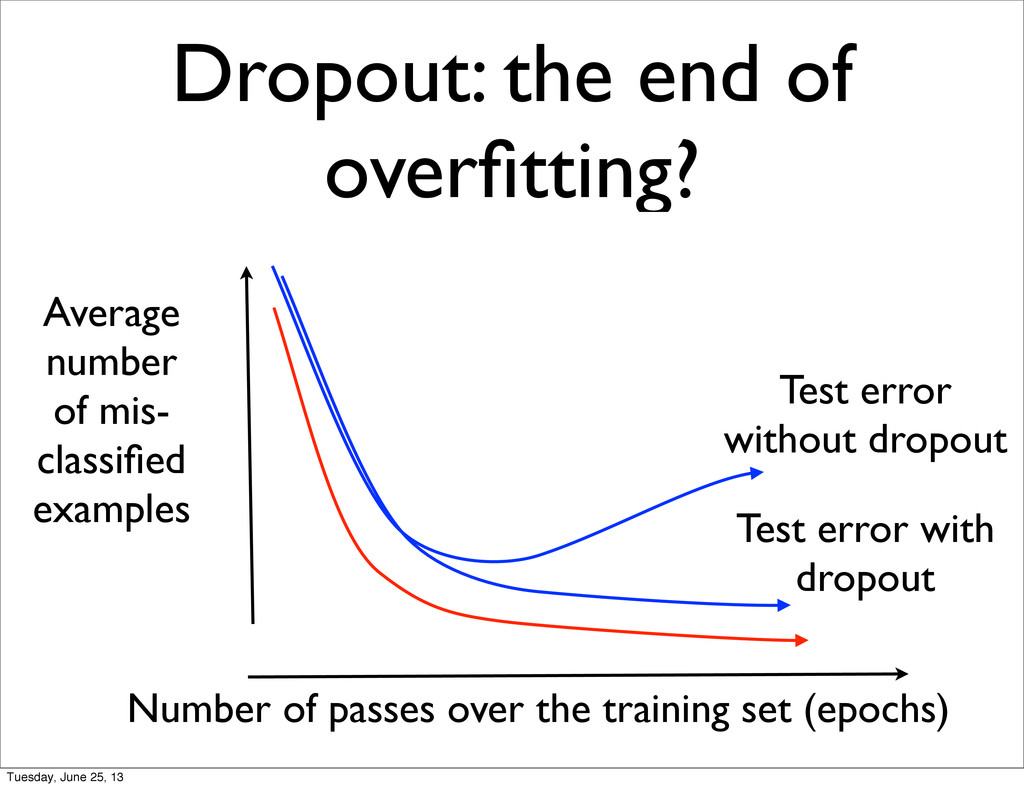
with much less overfitting and without unsupervised pre-training • Allows NN to beat state of the art approaches on ImageNet (object classification in images) Tuesday, June 25, 13
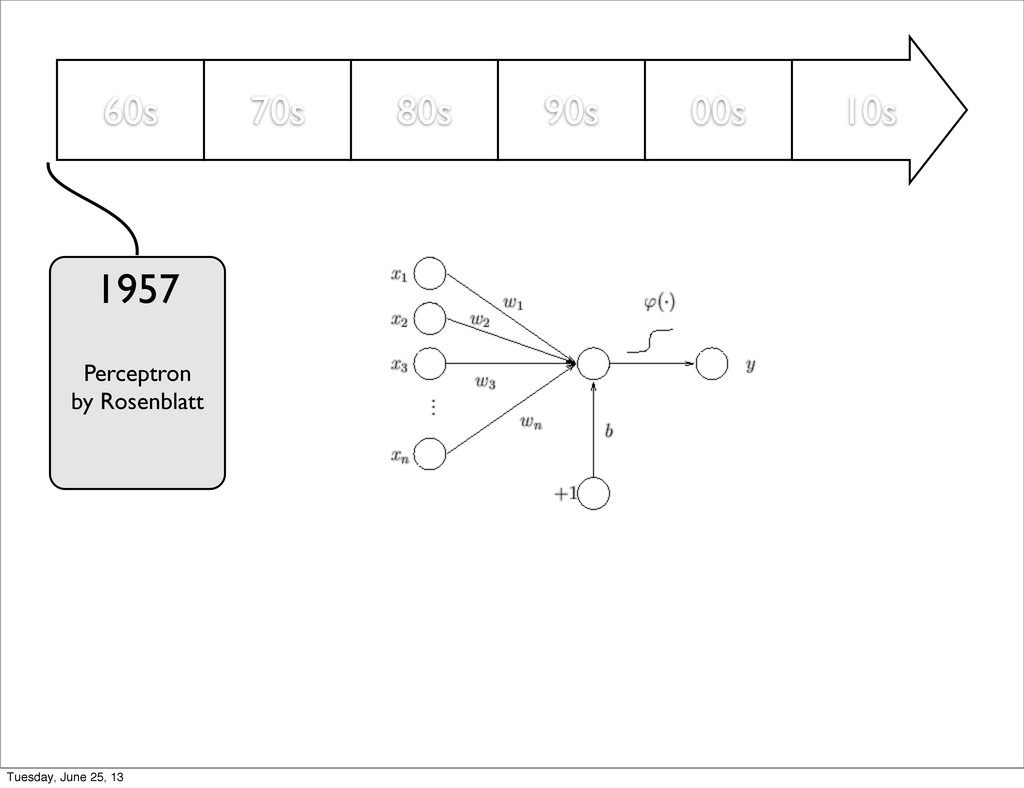
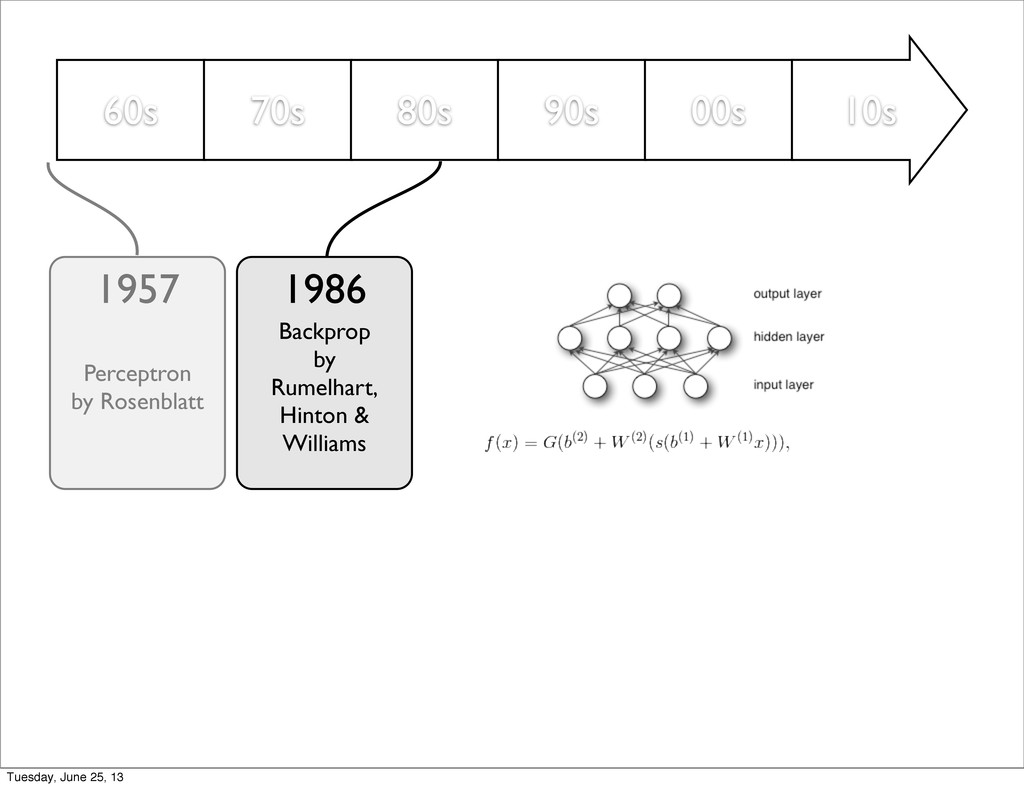
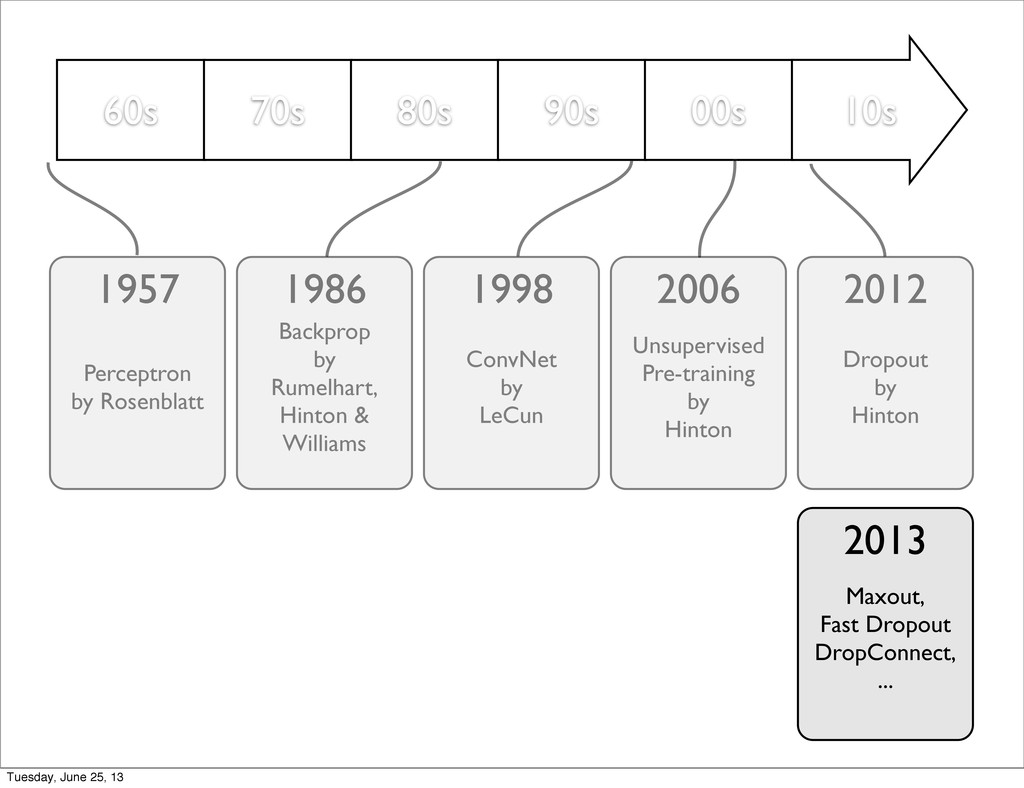
by Rumelhart, Hinton & Williams Unsupervised Pre-training by Hinton 1957 1986 2006 Dropout by Hinton 2012 Maxout, Fast Dropout DropConnect, ... 2013 ConvNet by LeCun 1998 Tuesday, June 25, 13
high level, invariant, discriminative features from raw data (pixels, sound frequencies...) • Starting to reach or beat State of the Art in several Speech Understanding and Computer Vision tasks • Stacked Abstractions and Composability might be a path to build a real AI Tuesday, June 25, 13
lots of (labeled) training data • Typically requires running a GPU for days to fit a model + many hyperparameters • Not yet that useful with high level abstract input (e.g. text data): shallow models can already do very well for text classification Tuesday, June 25, 13
(Google, Microsoft, IBM...) investing in DL for speech understanding and computer vision • Many top ML researchers are starting to look at DL & some on the theory side Tuesday, June 25, 13
analysis with a priori knowledge on the data generation process from hidden causes • If you want to model uncertainty of hidden causes using probability distribution • But don’t expect high predictive accuracy • PyMC is a good place to start in Python Tuesday, June 25, 13
• If you are researcher in Speech Recognition or Computer Vision (or NLP) • If you are ready to invest time in learning the latest tricks • If you are ready to mess with GPUs • http://deeplearning.net Tuesday, June 25, 13
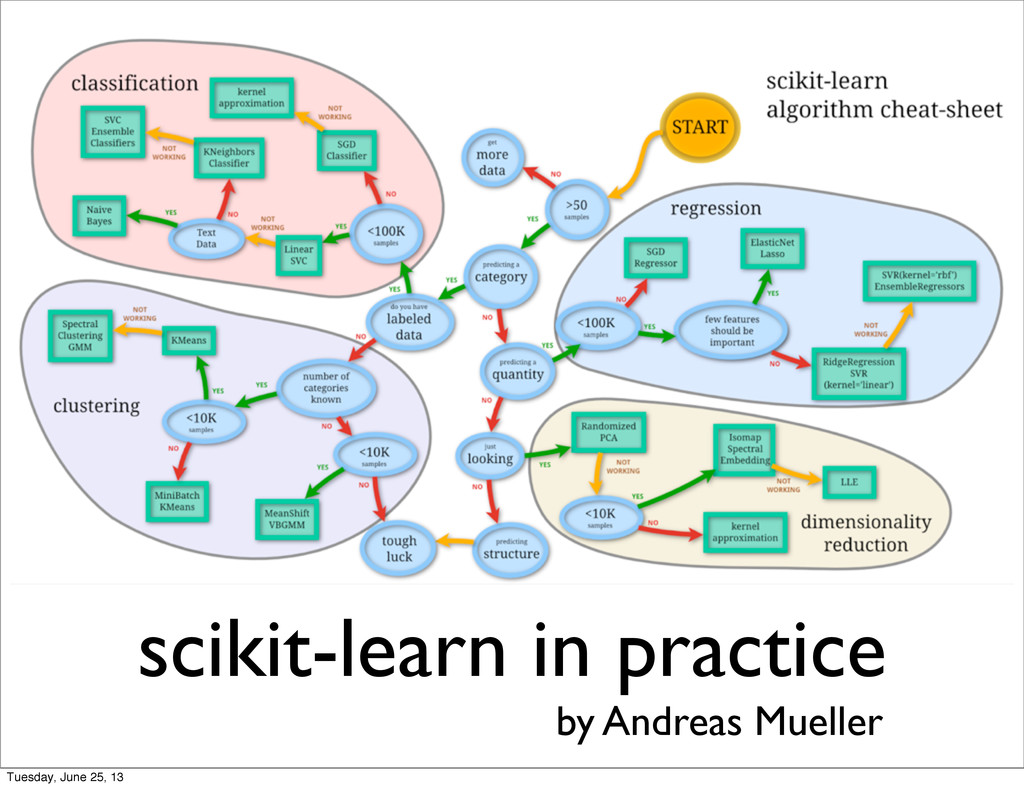
Models and Ensemble of Trees can get you pretty far • Less parameters to tune • Faster to train on CPUs • http://scikit-learn.org http://kaggle.com https://www.coursera.org/course/ml Tuesday, June 25, 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}