下記教科書を基にした推薦システム概論の講義スライドです。 奥 健太:基礎から学ぶ推薦システム - 情報技術で嗜好を予測する -, コロナ社 (2022)
当スライドの利用については下記サポートサイトをご参照ください。 推薦システム概論 | recsys-text
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
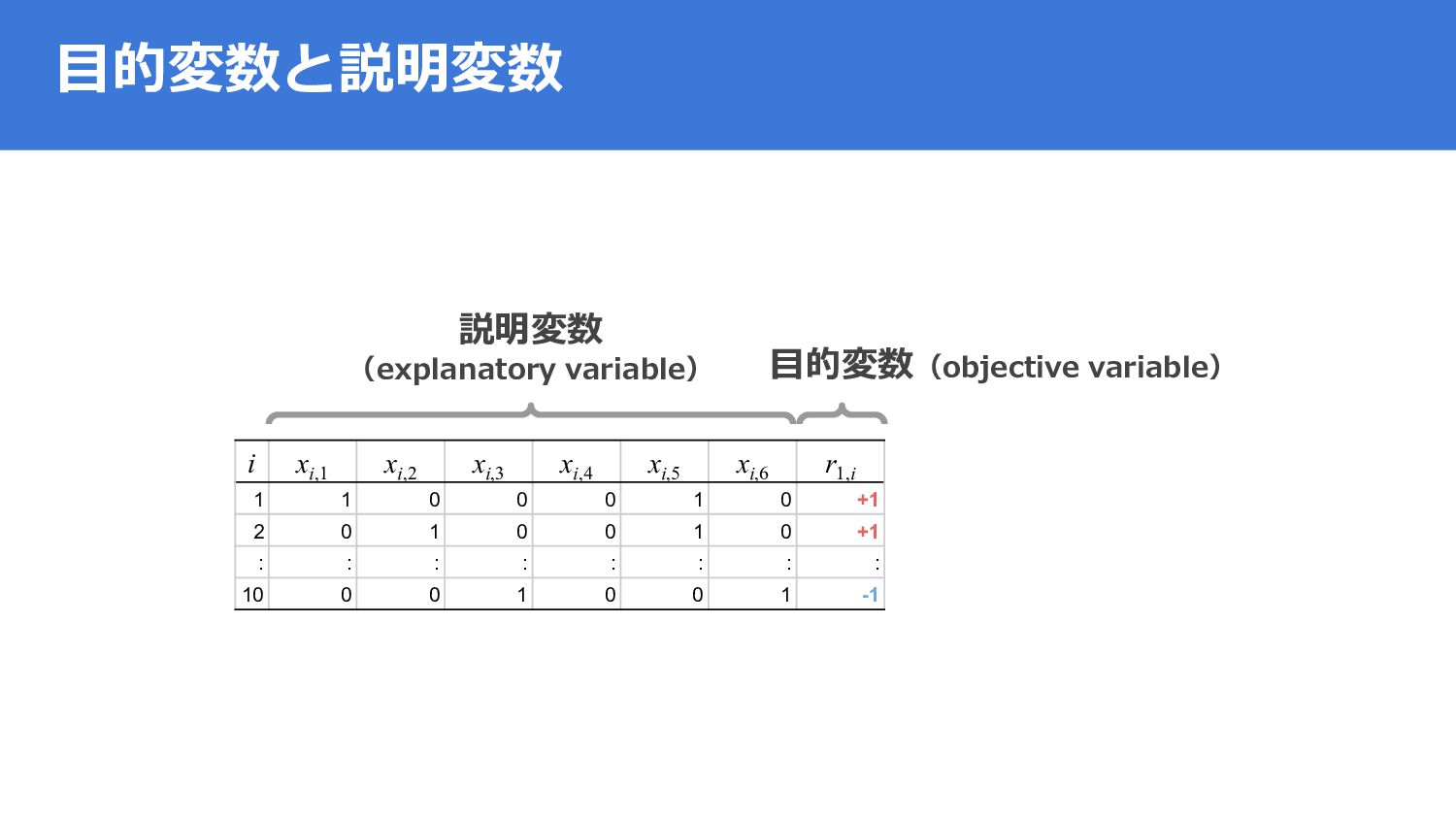{kind=link}
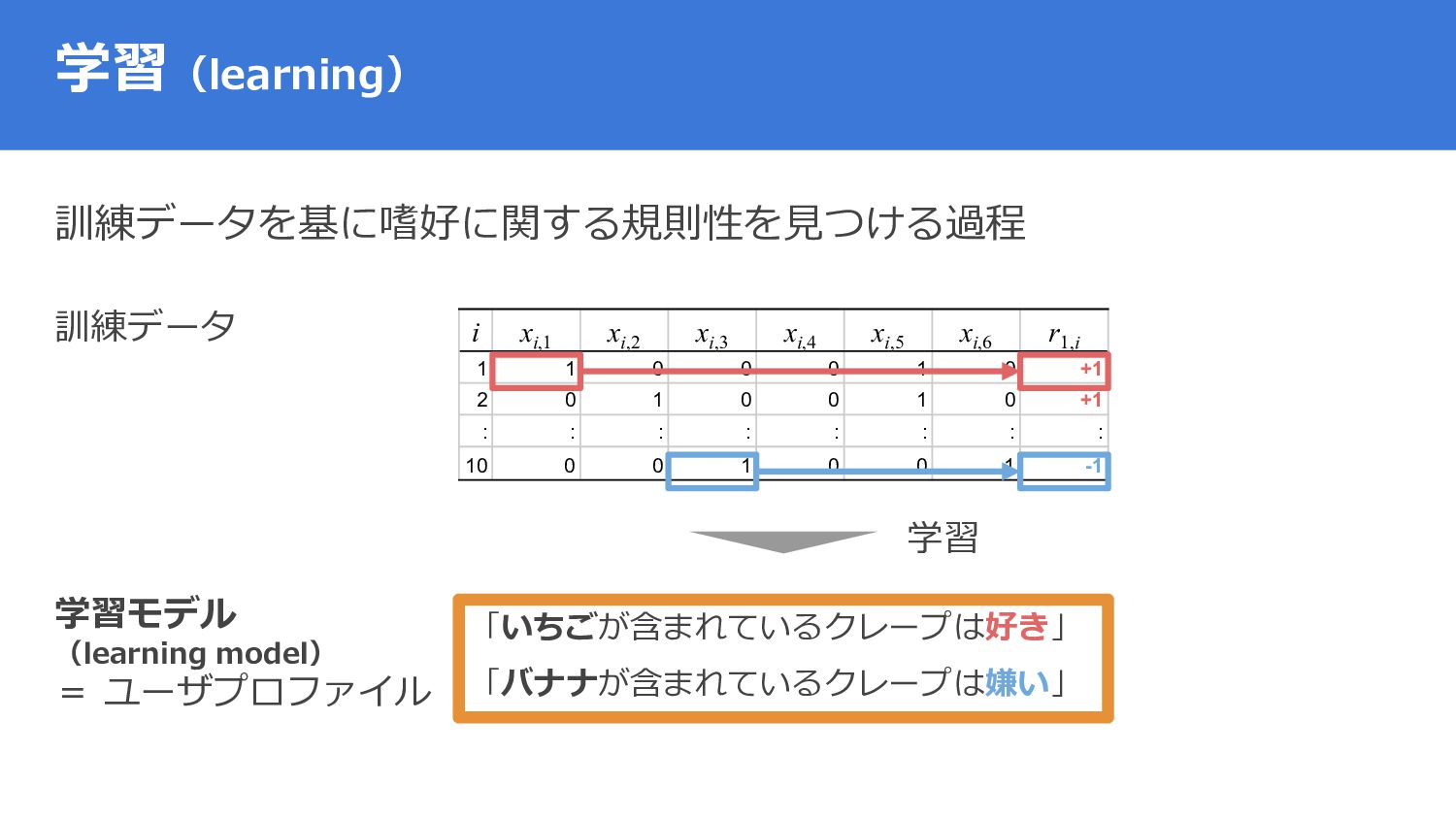{kind=link}
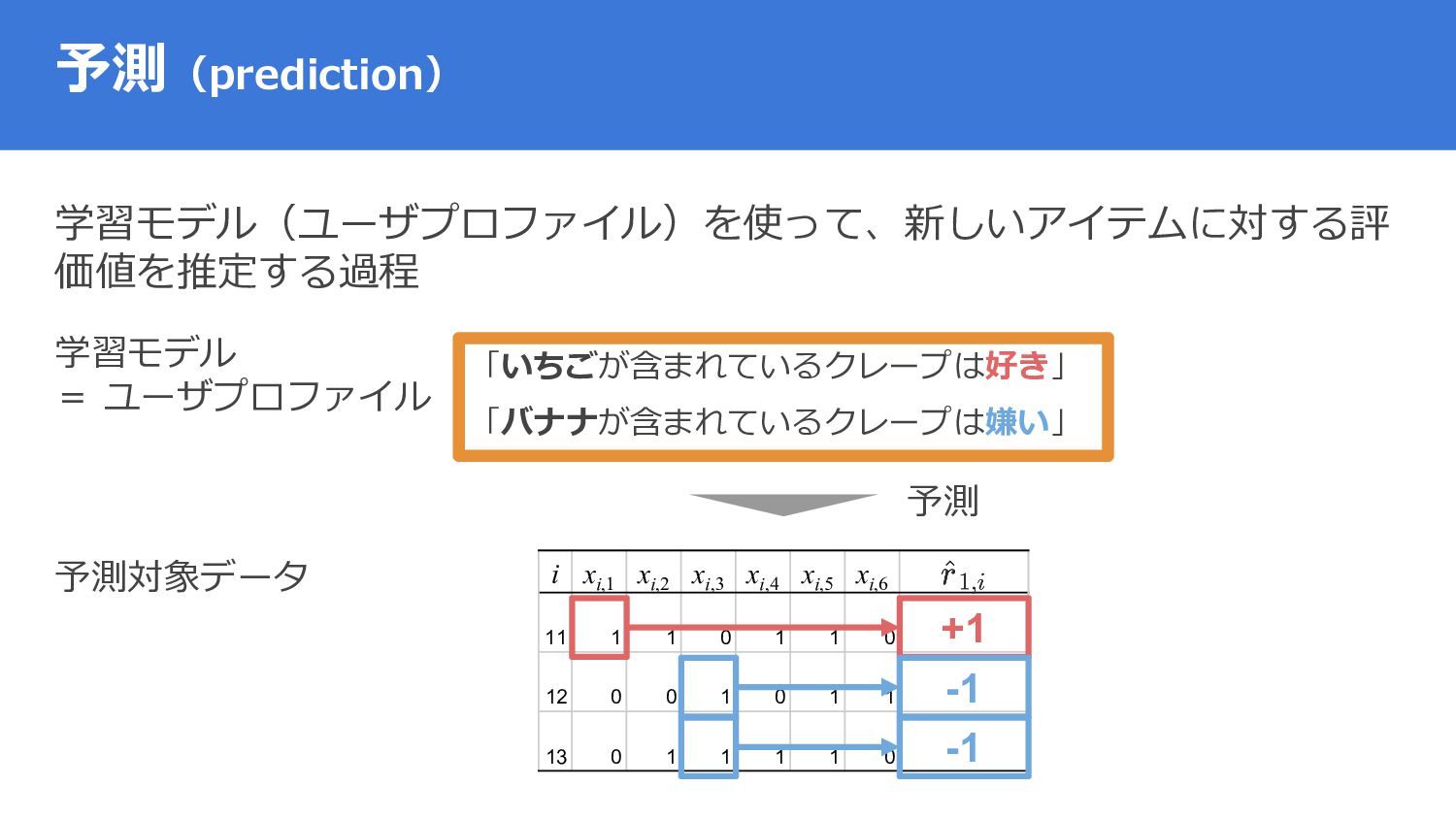{kind=link}
{kind=link}
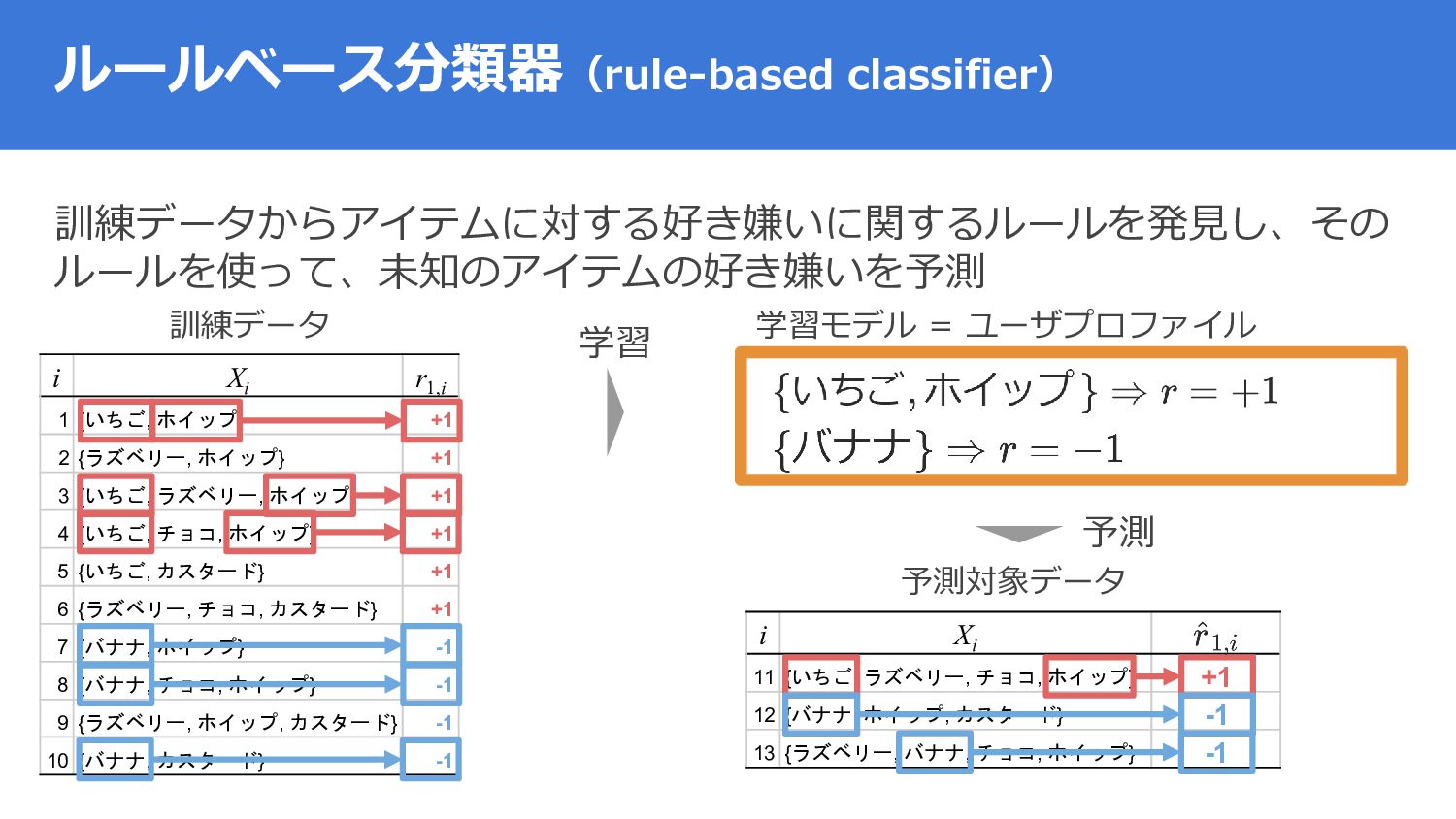{kind=link}
{kind=link}
{kind=link}
{kind=link}