は UMVU である N (μ, σ 2 ) T1 = n ∑ i=1 Xi , T2 = n ∑ i=1 X 2 i ¯ X s 2 T = (T1 , T2 ) ¯ X = T1 n , s 2 = T2 − T 2 1 /n n − 1 ¯ X s 2 E[ ¯ X] = μ, E[s 2 ] = σ 2 ¯ X s 2 22 / 37
自身である のとき、各要素を以下のようにした推定量の方が平均二乗 誤差が常に小さいことが示されている Xi ∼ N (μi , 1) i = 1, … , n (μ1 , … , μn ) (X1 , … , Xn ) n ≥ 3 ^ μ i = (1 − n − 2 ∑ n j=1 X 2 j )X i 26 / 37
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
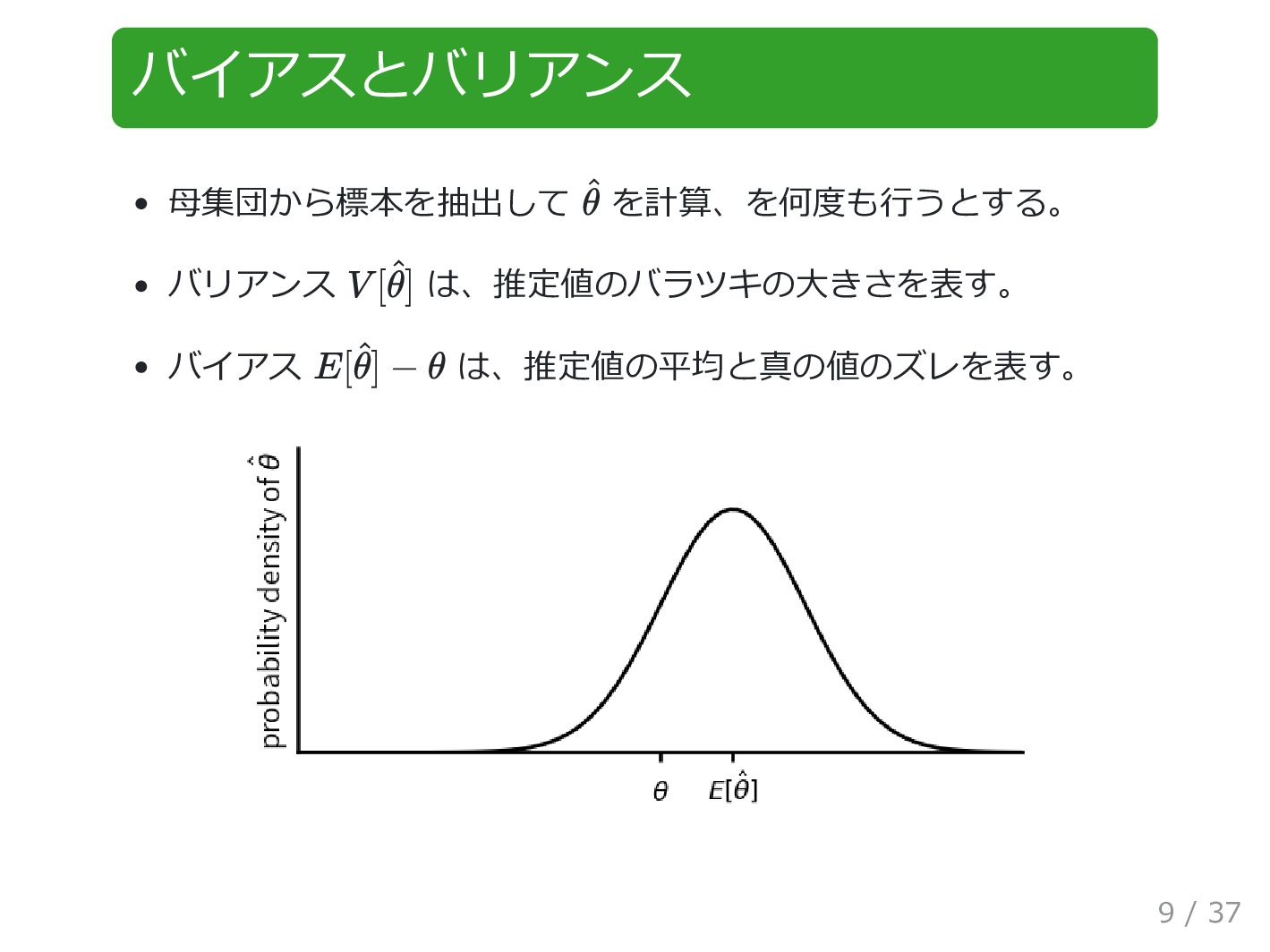
![不偏推定量 が不偏推定量であるとは、以下が成り立つこと 例、不偏分散 (参考) 最尤推定の場合 ^ θ E[ ^ θ]](https://files.speakerdeck.com/presentations/91df50a6324b4cc2b6d8d7e83beaf7da/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![クラメル・ラオの不等式 クラメル・ラオの不等式 ( は不偏推定量) ただし、 と、微分と積分が交換可能なこと (正則条件) を仮定 [定理] クラメル・ラオの不等式が成り立つ場合、不偏推定量](https://files.speakerdeck.com/presentations/91df50a6324b4cc2b6d8d7e83beaf7da/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![完備十分統計量とUMVU [定理] 完備十分統計量 の関数である不偏推定量 は一意に定ま り UMVU となる。 また、任意の不偏推定量を とするとき](https://files.speakerdeck.com/presentations/91df50a6324b4cc2b6d8d7e83beaf7da/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}