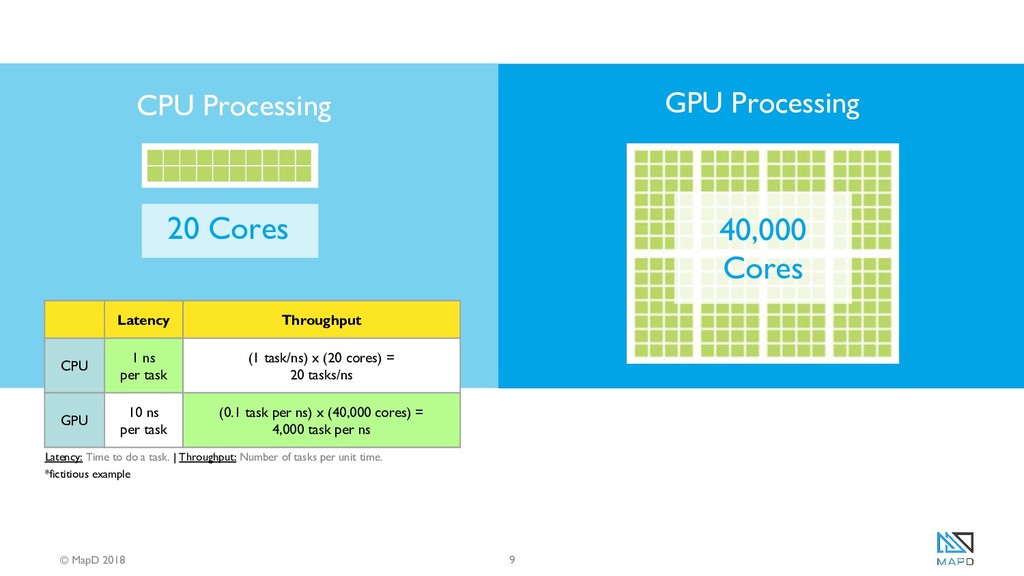
Nearly a decade ago, disk-based data analytics platforms began to be superseded by in-memory systems, which offered orders-of-magnitude more bandwidth than their predecessors. This technological sea change was driven in large part by memory prices falling to the point where it became viable to hold large working sets of data entirely in RAM. Today we are witness to a similar paradigm shift as analytics workloads are increasingly shifted from CPUs to GPUs, which possess much higher compute and memory bandwidth than CPUs. 8 GPUs and 256GB of GPU VRAM can be fit into a single server, and while CPUs have seen relatively minimal memory bandwidth increases over the last several years, GPUs are rapidly moving to stacked DRAM (High-Bandwidth Memory), meaning that by next year a single GPU will possess over a terabyte per second of bandwidth.
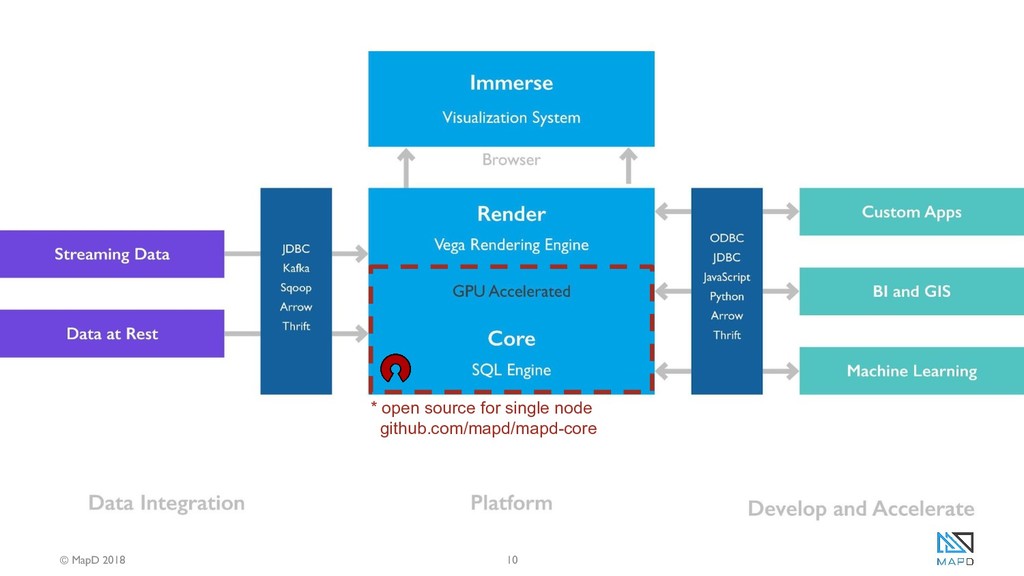
Using the MapD data analytics platform as an example, Aaron Williams will explain why data scientists and analysts leveraging GPUs will have an immense advantage over CPU alternatives. He will show how MapD's open source GPU database and Immerse visualization platform leverage the massive parallelism and memory bandwidth of multiple GPUs to execute SQL queries and render complex visualizations with billions of rows in milliseconds, literally orders of magnitude faster than CPU systems. Aaron will also explain and demonstrate the 3 APIs available to developers who want to build their own custom applications that take advantage of the speed of the GPUs.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}